Transformer 作为 NLP 领域的里程碑模型,彻底改变了序列建模的方式。它基于自注意力机制,摆脱了 RNN 的序列依赖,实现了并行计算,在机器翻译、文本生成等任务中表现卓越。本文将从零开始,手写一个简化版 Transformer,并详细讲解其核心模块的实现原理。

一、Transformer 整体架构回顾
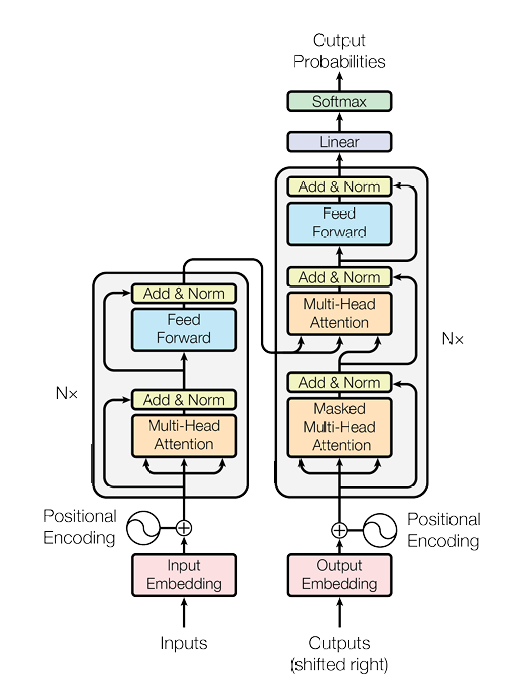
Transformer 由编码器(Encoder) 和解码器(Decoder) 两部分组成:
编码器:将输入序列(如源语言句子)编码为上下文向量,也就是图片中的左半
解码器:根据编码器输出和已生成的目标序列,预测下一个词,也就是图片中的右半
核心模块包括:词嵌入、位置编码、多头注意力、前馈网络、掩码机制等。我们将逐一实现这些模块,并最终组合成完整的 Transformer。
二、环境与数据准备
2.1 依赖环境
需要依赖的下载:
pip install torch torchvision torchaudio numpy2.2 数据处理(data_deal.py)
我们使用简单的德英翻译数据集作为示例,先实现数据预处理逻辑:
这段代码实现了一个 Transformer 模型的基础数据处理部分,原理是将德语 - 英语平行语料转换为模型可处理的索引序列,构建数据集和数据加载器,为后续模型训练做准备:定义了词汇表将文本映射为索引,通过自定义数据集类和 DataLoader 实现批量加载德语输入、英语解码器输入(带起始符)和解码器输出(带结束符)的索引数据。
# data_deal.py
# 定义样本数据(德语->英语)
sentences = [# enc_input dec_input dec_output['ich mochte ein bier P', 'S i want a beer .', 'i want a beer . E'],['ich mochte ein cola P', 'S i want a coke .', 'i want a coke . E']
]# 源语言(德语)词汇表
src_vocab = {'P': 0, 'ich': 1, 'mochte': 2, 'ein': 3, 'bier': 4, 'cola': 5}
src_vocab_size = len(src_vocab)
src_idx2word = {i: w for i, w in enumerate(src_vocab)}# 目标语言(英语)词汇表
tgt_vocab = {'P': 0, 'i': 1, 'want': 2, 'a': 3, 'beer': 4, 'coke': 5, 'S': 6, 'E': 7, '.': 8}
idx2word = {i: w for i, w in enumerate(tgt_vocab)}
tgt_vocab_size = len(tgt_vocab)# 序列长度配置
src_len = 5 # 源序列最大长度
tgt_len = 6 # 目标序列最大长度# Transformer超参数
d_model = 512 # 嵌入维度
d_ff = 2048 # 前馈网络维度
n_heads = 8 # 多头注意力头数
n_layers = 6 # 编码器/解码器层数# 文本转索引序列
def make_data(sentences):enc_inputs, dec_inputs, dec_outputs = [], [], []for i in range(len(sentences)):# 编码器输入:德语句子转索引enc_input = [src_vocab[n] for n in sentences[i][0].split()]# 解码器输入:英语句子(带起始符S)dec_input = [tgt_vocab[n] for n in sentences[i][1].split()]# 解码器输出:英语句子(带结束符E)dec_output = [tgt_vocab[n] for n in sentences[i][2].split()]enc_inputs.append(enc_input)dec_inputs.append(dec_input)dec_outputs.append(dec_output)return torch.LongTensor(enc_inputs), torch.LongTensor(dec_inputs), torch.LongTensor(dec_outputs)# 构建数据集
class MyDataSet(Data.Dataset):def __init__(self, enc_inputs, dec_inputs, dec_outputs):super().__init__()self.enc_inputs = enc_inputsself.dec_inputs = dec_inputsself.dec_outputs = dec_outputsdef __len__(self):return self.enc_inputs.shape[0]def __getitem__(self, idx):return self.enc_inputs[idx], self.dec_inputs[idx], self.dec_outputs[idx]# 生成数据加载器
enc_inputs, dec_inputs, dec_outputs = make_data(sentences)
loader = Data.DataLoader(MyDataSet(enc_inputs, dec_inputs, dec_outputs),batch_size=2,shuffle=True
)数据处理说明:
词汇表:将源语言和目标语言的单词映射为整数索引(P 为填充符,S 为起始符,E 为结束符)
数据集:自定义
Dataset类,将输入序列、解码器输入、解码器输出打包数据加载器:用于批量加载数据,方便训练
三、核心模块实现
3.1 位置编码(position.py)
Transformer 没有循环结构,需要通过位置编码注入序列的位置信息。采用正弦余弦函数实现:
这段代码实现了Transformer中的位置编码,原理是通过正弦和余弦函数生成与输入序列长度、嵌入维度匹配的位置信息,注入到词嵌入中以体现序列顺序:偶数维度用正弦函数、奇数维度用余弦函数计算不同位置的编码值,作为非参数缓冲区存储,前向传播时将其与输入嵌入相加并应用dropout。
# position.py
class PositionalEncoding(nn.Module):def __init__(self, d_model, dropout=0.1, max_len=5000):super().__init__()self.dropout = nn.Dropout(p=dropout)# 初始化位置编码矩阵pe = torch.zeros(max_len, d_model)# 位置索引(0到max_len-1)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)# 频率项:10000^(-2i/d_model)div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))# 偶数维度用sin,奇数维度用cospe[:, 0::2] = torch.sin(position * div_term) # 0,2,4...维度pe[:, 1::2] = torch.cos(position * div_term) # 1,3,5...维度pe = pe.unsqueeze(0) # 增加批次维度:[1, max_len, d_model]self.register_buffer('pe', pe) # 注册为非参数缓冲区def forward(self, x):# x: [batch_size, seq_len, d_model]x = x + self.pe[:, :x.size(1), :] # 注入位置信息return self.dropout(x)位置编码原理:
- 公式:
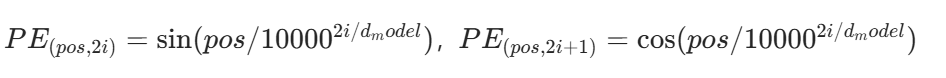
- 作用:通过不同频率的正弦余弦函数,让模型感知单词的位置关系(如相对位置)
3.2 掩码机制(mask.py)
这段代码实现了Transformer中的两种注意力掩码,原理是通过掩码矩阵遮挡不需要参与注意力计算的位置:填充掩码(att_pad_mask)将序列中值为0的填充位置标记为需遮挡,生成[batch_size, len_q, len_k]的掩码矩阵;序列掩码(att_sub_mask)用上三角矩阵标记未来位置为需遮挡,确保解码时只能关注当前及之前的词。
# mask.py
def att_pad_mask(seq_q, seq_k):"""填充掩码:遮挡padding位置(值为0的位置)"""batch_size, len_q = seq_q.size()batch_size, len_k = seq_k.size()# seq_k中值为0的位置标记为True(需要遮挡)mask = seq_k.eq(0).unsqueeze(1) # [batch_size, 1, len_k]return mask.expand(batch_size, len_q, len_k) # [batch_size, len_q, len_k]def att_sub_mask(seq):"""序列掩码:上三角矩阵,遮挡未来的词"""attn_shape = [seq.size(0), seq.size(1), seq.size(1)]# 生成上三角矩阵(k=1表示对角线以上为1)mask = np.triu(np.ones(attn_shape), k=1)return torch.from_numpy(mask).byte() # 转为byte类型掩码掩码说明:
填充掩码:确保模型不关注无意义的填充符(如句子长度不足时补的 P)
序列掩码:在解码器自注意力中,当前位置只能关注之前的位置(避免信息泄露)
3.3 多头注意力(MHA.py)
这段代码实现了Transformer中的注意力机制,原理是通过将输入映射到多个查询(Q)、键(K)、值(V)空间并行计算注意力,再合并结果以捕捉不同维度的关联:基础注意力(Attention)计算Q与K的相似度得分,经掩码和softmax得到权重后与V加权求和;多头注意力(MultiHeadAttention)通过线性变换将输入分成多个头并行计算注意力,合并后经线性变换、残差连接和层归一化输出,既支持自注意力也支持交叉注意力。
# MHA.py
class Attention(nn.Module):"""基础注意力计算"""def __init__(self, dropout=0.1):super().__init__()self.softmax = nn.Softmax(dim=-1)self.dropout = nn.Dropout(dropout)def forward(self, q, k, v, mask=None):# q: [batch_size, n_heads, len_q, d_k]# k: [batch_size, n_heads, len_k, d_k]# v: [batch_size, n_heads, len_v, d_v](len_k=len_v)scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(k.size(-1)) # 注意力得分if mask is not None:# 掩码位置置为负无穷(softmax后接近0)scores = scores.masked_fill_(mask, -1e9)att = self.softmax(scores) # 注意力权重att = self.dropout(att)output = torch.matmul(att, v) # 加权求和return outputclass MultiHeadAttention(nn.Module):"""多头注意力"""def __init__(self, d_model, num_heads):super().__init__()self.d_model = d_modelself.num_heads = num_headsself.d_k = d_model // num_heads # 每个头的维度# Q、K、V的线性变换self.w_q = nn.Linear(d_model, d_model)self.w_k = nn.Linear(d_model, d_model)self.w_v = nn.Linear(d_model, d_model)self.attention = Attention()self.w_o = nn.Linear(d_model, d_model) # 输出线性变换self.dropout = nn.Dropout(0.1)self.layer_norm = nn.LayerNorm(d_model) # 层归一化def forward(self, enc_inputs, dec_inputs, mask=None):"""enc_inputs: 编码器输入(自注意力时为QKV的源,交叉注意力时为K/V的源)dec_inputs: 解码器输入(自注意力时为QKV的源,交叉注意力时为Q的源)"""res = dec_inputs # 残差连接的输入batch_size = enc_inputs.size(0)# 线性变换 + 分头([batch_size, seq_len, d_model] -> [batch_size, n_heads, seq_len, d_k])Q = self.w_q(dec_inputs).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)K = self.w_k(enc_inputs).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)V = self.w_v(enc_inputs).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)# 处理掩码维度(扩展到多头)if mask is not None:mask = mask.unsqueeze(1).repeat(1, self.num_heads, 1, 1) # [batch_size, n_heads, len_q, len_k]# 计算注意力att_out = self.attention(Q, K, V, mask)# 多头合并([batch_size, n_heads, seq_len, d_k] -> [batch_size, seq_len, d_model])att_out = att_out.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)att_out = self.w_o(att_out) # 输出线性变换# 残差连接 + 层归一化att_out = self.dropout(att_out)att_out = self.layer_norm(att_out + res)return att_out多头注意力原理:
将 Q、K、V 通过线性变换投影到低维(d_k = d_model /n_heads)
拆分到多个头并行计算注意力
合并多头结果,通过线性变换得到最终输出
加入残差连接和层归一化(稳定训练)
3.4 前馈网络(FFN.py)
前馈网络对每个位置进行独立的非线性变换,增强模型表达能力:
# FFN.py
class FFN(nn.Module):def __init__(self, d_model, d_ff):super().__init__()self.ffn = nn.Sequential(nn.Linear(d_model, d_ff), # 升维nn.ReLU(),nn.Dropout(0.1),nn.Linear(d_ff, d_model) # 降维)self.dropout = nn.Dropout(0.1)self.layer_norm = nn.LayerNorm(d_model)def forward(self, x):res = x # 残差连接x = self.ffn(x)x = self.dropout(x)return self.layer_norm(x + res) # 残差 + 层归一化前馈网络作用:
通过两层线性变换和 ReLU 激活,对注意力输出进行非线性映射
保持输入输出维度一致(d_model),方便残差连接
四、编码器与解码器实现
4.1 编码器(encoder.py)
编码器由 N 个编码器层堆叠而成,每个编码器层包含:多头自注意力 + 前馈网络
这段代码实现了Transformer的编码器部分,原理是通过多层叠加的编码器层对输入序列进行深度特征提取:编码器(Encoder)先将输入序列通过词嵌入和位置编码转换为向量表示,再传入n_layers个编码器层(EncoderLayer);每个编码器层包含自注意力机制(捕捉序列内部词与词的关联)和前馈网络(进行非线性变换),并通过填充掩码处理padding位置,最终输出编码后的序列特征。
# encoder.py
class EncoderLayer(nn.Module):"""编码器层"""def __init__(self, d_model, d_ff, n_heads):super().__init__()self.multi_head_attention = MultiHeadAttention(d_model, n_heads) # 自注意力self.feed_forward = FFN(d_model, d_ff) # 前馈网络def forward(self, enc_inputs, mask=None):# 自注意力(Q=K=V=enc_inputs)enc_outputs = self.multi_head_attention(enc_inputs, enc_inputs, mask)# 前馈网络enc_outputs = self.feed_forward(enc_outputs)return enc_outputsclass Encoder(nn.Module):"""编码器"""def __init__(self, vocab_size, d_model, d_ff, n_heads, n_layers, dropout=0.1):super().__init__()self.embedding = nn.Embedding(vocab_size, d_model) # 词嵌入self.position_encoding = PositionalEncoding(d_model) # 位置编码# 堆叠n_layers个编码器层self.layers = nn.ModuleList([EncoderLayer(d_model, d_ff, n_heads)for _ in range(n_layers)])def forward(self, enc_inputs):# 词嵌入 + 位置编码enc_outputs = self.embedding(enc_inputs)enc_outputs = self.position_encoding(enc_outputs)# 生成填充掩码(自注意力中,遮挡padding)mask = att_pad_mask(enc_inputs, enc_inputs)# 经过所有编码器层for layer in self.layers:enc_outputs = layer(enc_outputs, mask)return enc_outputs4.2 解码器(decoder.py)
这段代码实现了Transformer的解码器部分,原理是通过多层叠加的解码器层结合编码器输出生成目标序列,同时确保解码时不依赖未来信息:解码器(Decoder)先将目标序列经词嵌入和位置编码转换为向量表示,再传入n_layers个解码器层(DecoderLayer);每个解码器层包含三步处理——带填充+序列合并掩码的自注意力(仅关注当前及之前的词)、以编码器输出为键值的交叉注意力(关联源序列信息)、前馈网络(非线性变换),最终输出解码后的序列特征。
# decoder.py
class DecoderLayer(nn.Module):"""解码器层"""def __init__(self, d_model, d_ff, n_heads):super().__init__()self.self_attn = MultiHeadAttention(d_model, n_heads) # 解码器自注意力(带掩码)self.cross_attn = MultiHeadAttention(d_model, n_heads) # 交叉注意力(与编码器交互)self.feed_forward = FFN(d_model, d_ff) # 前馈网络def forward(self, enc_outputs, dec_inputs, mask_self=None, mask_cross=None):# 1. 解码器自注意力(Q=K=V=dec_inputs,带掩码)dec_outputs = self.self_attn(dec_inputs, dec_inputs, mask_self)# 2. 交叉注意力(Q=dec_outputs,K=V=enc_outputs)dec_outputs = self.cross_attn(enc_outputs, dec_outputs, mask_cross)# 3. 前馈网络dec_outputs = self.feed_forward(dec_outputs)return dec_outputsclass Decoder(nn.Module):"""解码器"""def __init__(self, vocab_size, d_model, d_ff, n_heads, n_layers, dropout=0.1):super().__init__()self.embedding = nn.Embedding(vocab_size, d_model) # 词嵌入self.position_encoding = PositionalEncoding(d_model) # 位置编码# 堆叠n_layers个解码器层self.layers = nn.ModuleList([DecoderLayer(d_model, d_ff, n_heads)for _ in range(n_layers)])def forward(self, enc_inputs, enc_outputs, dec_inputs):# 词嵌入 + 位置编码dec_outputs = self.embedding(dec_inputs)dec_outputs = self.position_encoding(dec_outputs)# 1. 解码器自注意力掩码(填充掩码 + 序列掩码)mask_pad = att_pad_mask(dec_inputs, dec_inputs).to(dec_inputs.device) # 填充掩码mask_sub = att_sub_mask(dec_inputs).to(dec_inputs.device) # 序列掩码mask_self = torch.gt((mask_pad + mask_sub), 0) # 合并掩码(True表示需要遮挡)# 2. 交叉注意力掩码(目标序列对源序列的填充掩码)mask_cross = att_pad_mask(dec_inputs, enc_inputs).to(dec_inputs.device)# 经过所有解码器层for layer in self.layers:dec_outputs = layer(enc_outputs, dec_outputs, mask_self, mask_cross)return dec_outputs五、Transformer 整体组装(transformer.py)
将编码器、解码器和输出投影层组合成完整模型:
# transformer.py
class Transformer(nn.Module):def __init__(self, enc_vocab_size, dec_vocab_size, d_model, d_ff, n_heads, n_layers):super().__init__()self.encoder = Encoder(enc_vocab_size, d_model, d_ff, n_heads, n_layers)self.decoder = Decoder(dec_vocab_size, d_model, d_ff, n_heads, n_layers)self.projection = nn.Linear(d_model, dec_vocab_size) # 输出投影到目标词汇表def forward(self, enc_inputs, dec_inputs):# 编码器输出enc_outputs = self.encoder(enc_inputs)# 解码器输出dec_outputs = self.decoder(enc_inputs, enc_outputs, dec_inputs)# 投影到词汇表outputs = self.projection(dec_outputs)# 调整维度:[batch_size, tgt_len, vocab_size] -> [batch_size*tgt_len, vocab_size]return outputs.view(-1, outputs.size(2))六、模型训练(训练.py)
使用交叉熵损失和 SGD 优化器训练模型:
# 训练.py
from torch import nn, optim
from transformer import Transformer
from data_deal import *# 设备选择
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 初始化模型
model = Transformer(src_vocab_size, tgt_vocab_size, d_model, d_ff, n_heads, n_layers).to(device)# 损失函数(忽略填充符0)
criterion = nn.CrossEntropyLoss(ignore_index=0)
# 优化器(SGD+动量)
optimizer = optim.SGD(model.parameters(), lr=1e-3, momentum=0.99)# 训练循环
for epoch in range(100):for idx, (enc_inputs, dec_inputs, dec_labels) in enumerate(loader):# 数据移至设备enc_inputs, dec_inputs, dec_labels = enc_inputs.to(device), dec_inputs.to(device), dec_labels.to(device)optimizer.zero_grad() # 清空梯度outputs = model(enc_inputs, dec_inputs) # 模型输出loss = criterion(outputs, dec_labels.view(-1)) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 打印每轮损失print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss.item()))# 保存模型
torch.save(model.state_dict(), 'transformer.pth')七、模型预测(预测.py)
使用贪婪解码生成目标序列:
# 预测.py
from transformer import Transformer
from data_deal import *device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 加载模型
model = Transformer(src_vocab_size, tgt_vocab_size, d_model, d_ff, n_heads, n_layers).to(device)
model.load_state_dict(torch.load('transformer.pth', weights_only=False))
model.eval() # 切换到评估模式def greedy_decoder(model, enc_input, start_symbol):"""贪婪解码:从起始符开始,每次选择概率最大的词"""enc_outputs = model.encoder(enc_input) # 编码器输出dec_input = torch.zeros(1, 0).type_as(enc_input.data) # 初始化解码器输入terminal = Falsenext_symbol = start_symbol # 起始符while not terminal:# 拼接下一个符号dec_input = torch.cat([dec_input.detach(), torch.tensor([[next_symbol]], dtype=enc_input.dtype).to(device)], -1)# 解码器输出dec_outputs = model.decoder(enc_input, enc_outputs, dec_input)# 投影到词汇表projected = model.projection(dec_outputs)# 选择概率最大的词next_symbol = projected.squeeze(0).max(dim=-1)[1][-1].item()if next_symbol == tgt_vocab["E"]: # 遇到结束符则停止terminal = Truereturn dec_input# 测试
enc_inputs, _, _ = next(iter(loader))
enc_inputs = enc_inputs.to(device)
for i in range(len(enc_inputs)):# 生成解码输入greedy_dec_input = greedy_decoder(model, enc_inputs[i].view(1, -1), start_symbol=tgt_vocab["S"])# 预测predict = model(enc_inputs[i].view(1, -1), greedy_dec_input)predict = predict.view(-1, predict.size(-1)).max(1)[1]# 打印结果print([src_idx2word[word.item()] for word in enc_inputs[i]], '->', [idx2word[n.item()] for n in predict])



复制集和分片集群)





 视频教程 - 微博舆情数据可视化分析-热词情感趋势柱状图)


 与 :where ():简化复杂选择器的 “语法糖”)


——图像本质、数字矩阵、RGB + 基本操作(实战一))


