SIFThinker: Spatially-Aware Image Focus for Visual Reasoning
Authors: Zhangquan Chen, Ruihui Zhao, Chuwei Luo, Mingze Sun, Xinlei Yu, Yangyang Kang, Ruqi Huang
相关工作总结
视觉思维链推理
最近的研究表明,通过上下文学习逐步推理可以显著提升大型语言模型(LLMs)的性能。因此,出现了几种方法,旨在通过引入思维链策略来增强多模态大型语言模型的视觉推理能力。这些方法可以分为以下三种类型:
- 纯文本思维方法(T1):如 Chen 等人(2025a)、Thawakar 等人(2025)、Ji 等人(2024)和 Hu 等人(2024)的研究,受到 Guo 等人(2025b)的启发,在多模态大型语言模型(MLLMs)中引入纯文本推理用于视觉推理任务。这些方法使用强化学习引导生成过程走向最终答案,而不明确纳入中间视觉信号。
- 中间思维方法(T2):如 Liu 等人(2025a)、Shao 等人(2024b)、Chen、Luo 和 Li(2025)以及 Wang 等人(2024)的研究,首先生成细粒度的视觉线索(例如边界框、空间坐标或分割掩码),然后基于这些视觉线索进行思维链推理。
- 多模态思维方法(T3):一些最近的方法致力于将视觉-文本推理更紧密地整合到模型的思维过程中。例如,专有系统如 ChatGPT-o3(OpenAI 2025)展示了通过动态调用外部图像工具实现“与图像一起思考”的能力。类似地,Li 等人(2025)通过生成推理的视觉轨迹实现视觉思维。Su 等人(2025)、Wu 等人(2025)和 Zheng 等人(2025)通过强化学习优化工具使用能力。此外,Zhang 等人(2025)基于生成的边界框迭代裁剪图像,并通过生成交织自然语言和明确边界框的推理链采取更直接的方法。
然而,现有方法仍存在一些局限性:(T1)过于依赖文本推理,忽视推理过程中动态的视觉注意力转移;(T2)缺乏连贯的推理链;(T3)一些方法依赖外部工具、专门的检测模型或不稳定的图像生成,而其他方法则忽略中间视觉信号,仅依赖基于结果的监督。因此,需要一种自适应且连贯的内在方法,使视觉基础推理成为可能——不仅让 MLLMs “思考”图像,还要动态聚焦并以类似人类的方式在图像区域间调整视觉注意力。
空间智能
现有的多模态大型语言模型(MLLMs)(如 Wu 等人 2024、Driess 等人 2023、Li 等人 2023b、Chen 等人 2022)主要基于 RGB 图像和文本数据进行训练,缺乏 3D 空间信息。因此,它们在需要空间推理的任务上表现有限。为解决这一局限性,最近的努力如 SpatialRGPT(Cheng 等人)通过构建专门的空间导向问答数据集并相应地微调模型,增强了 MLLMs 的空间推理能力。为了进一步强调综合推理能力,SSR(Liu 等人 2025b)将深度图像作为额外输入,而 SpatialBot(Cai 等人 2024)则利用深度估计工具获取关键感知区域的空间先验。然而,这些空间感知方法仅关注推理,未能与视觉基础实现深度整合——这两个过程在人类视觉感知中是根本上相互依存的。
如图 1 所示,SIFThinker 将深度增强的图像焦点区域纳入思维过程,使空间基础的视觉焦点成为可能。SIFThinker 可以迭代分析和优化感兴趣区域,最终提供更准确的最终响应。在接下来的章节中,我们将详细描述数据生成流程、空间感知图像焦点训练范式以及 GRPO-SIF。
数据生成
为了模拟人类观察空间场景的方式,我们设计了一个结合深度的焦点机制来进行数据生成。具体而言,我们构建了 SIF-50K 数据集,该数据集包含两个部分:(1)一个定制的细粒度推理子集,来源于 Flickr30k(Plummer 等人,2015)、Visual7W(Zhu 等人,2016)、GQA(Hudson 和 Manning,2019)、Open Images(Kuznetsova 等人,2020)、VSR(Liu, Emerson 和 Collier,2023)以及 Birds-200-2021(Wah 等人,2011)中的空间场景,基于 VisCoT(Shao 等人,2024b);(2)一个从 TallyQA(Acharya, Kafle 和 Kanan,2019)中重新采样的多实例子集。所有源数据集都包含真实的边界框(b-boxes)标注。如算法 1 所示,对于每一组问题-图像-边界框-答案对 (Q,I,Bgt,R)(Q, I, B_{gt}, R)(Q,I,Bgt,R),我们首先应用逆向扩展程序,然后基于 DepthAnythingV2(Yang 等人,2024)和 Doubao-1.5-vision-pro(Guo 等人,2025a)对扩展区域进行前向推理。这个过程最终生成了 SIF-50K 数据集,表示为 P={(Q,I,D1,Bgt,R,Rcot)}P = \{(Q, I, D_1, B_{gt}, R, R_{cot})\}P={(Q,I,D1,Bgt,R,Rcot)}。

空间感知图像焦点训练范式
方法概述。我们提出了一种两阶段的流程来整合空间感知的接地推理。第一阶段是预热监督微调阶段,该阶段使模型倾向于生成具有明确焦点区域的结构化推理链,从而得到模型 MsFTM_{sFT}MsFT。随后是强化学习阶段,进一步优化和细化这些接地行为,生成最终模型 MRLM_{RL}MRL。对于监督微调(SFT),我们使用 SIF-50K 的完整数据集,得到 PsFT=(Q,I,D1,Rcot)P_{sFT} = (Q, I, D_1, R_{cot})PsFT=(Q,I,D1,Rcot)。对于强化学习(RL,详见下一节),为了在最小监督下促进渐进式学习,我们从 SIF-50K 中抽取 200 个实例,形成一个较小的集合 PrL=(Q,I,D1,Bgt,R)P_{rL} = (Q, I, D_1, B_{gt}, R)PrL=(Q,I,D1,Bgt,R)。
强化学习与 GRPO-SIF 的总结 (中文)
RL 公式化
基于 Group-Relative Policy Optimisation (GRPO) 方法(Shao 等人,2024c),MsFT 模型被框架化为一个策略 TeT_eTe,该策略根据输入 (Q,I,D1)(Q, I, D_1)(Q,I,D1) 生成输出序列。在训练过程中,对于每个问题-图像-深度图像对 (Q,I,D1)(Q, I, D_1)(Q,I,D1),GRPO-SIF 通过策略 ToT_oTo 采样一组 NNN 个候选完成 {o1,...,oN}\{o_1, ..., o_N\}{o1,...,oN},并通过最大化以下目标函数进行优化:
T(θ)=1N∑i=1N1∣σi∣∑t=1∣σi∣{min[clip(ri,t,1−ϵ,1+ϵ)A^i,t,\mathcal{T}(\theta)=\frac{1}{N}\sum_{i=1}^{N}\frac{1}{|\sigma_{i}|}\sum_{t=1}^{|\sigma_{i}|}\left\{\operatorname*{min}\left[\mathrm{clip}(r_{i,t},1-\epsilon,1+\epsilon)\hat{A}_{i,t},\right.\right. T(θ)=N1i=1∑N∣σi∣1t=1∑∣σi∣{min[clip(ri,t,1−ϵ,1+ϵ)A^i,t,
其中 ri,t=πθ(O,t∣q,Oi,<t)r_{i,t} = \pi_\theta(O,t|q,O_{i,<t})ri,t=πθ(O,t∣q,Oi,<t) 表示在步骤 ttt 时新旧策略之间的比率,ϵ\epsilonϵ 和 β\betaβ 是超参数。DKL[To∣∣Tref]D_{KL}[T_o || T_{ref}]DKL[To∣∣Tref] 使用无偏估计器(Schulman 2020)估计当前策略模型与参考模型之间的 KL 散度。对于每个完成 OrO_rOr,基于奖励组件的组合(详见下文)计算特定任务的奖励 ri,t=R(Q,I,D1,Bgt,R,o)r_{i,t} = R(Q, I, D_1, B_{gt}, R, o)ri,t=R(Q,I,D1,Bgt,R,o),并用这些奖励计算组归一化的优势值 A^i,t\hat{A}_{i,t}A^i,t。
任务奖励 ri,tr_{i,t}ri,t 是一个复合信号,包括四个组成部分:空间感知的推理格式奖励 (rformatr_{format}rformat)、渐进式回答准确性奖励 (rans,tr_{ans,t}rans,t)、校正增强的接地奖励 (rbboxr_{bbox}rbbox)、深度一致性奖励 (rdepthr_{depth}rdepth)。这些组件旨在共同促进空间感知的接地推理,从而提供精确的答案。
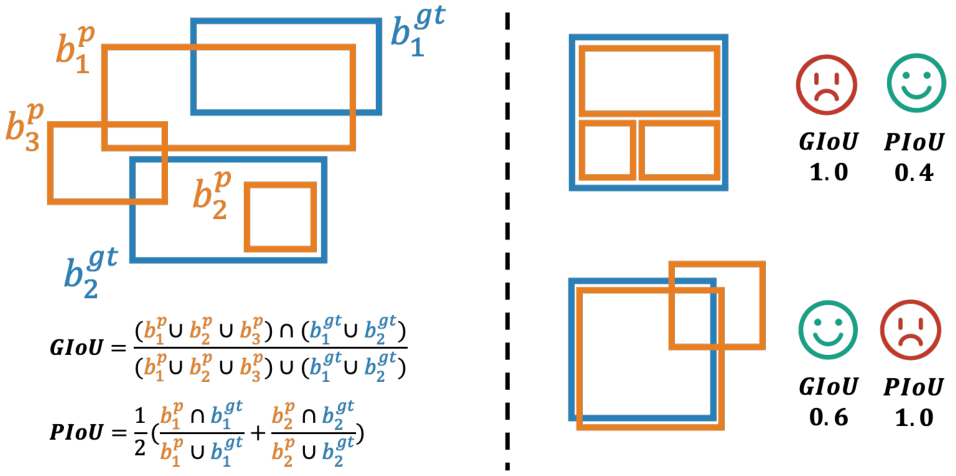
层次交并比 (HIoU)
为了全面评估预测边界框 Bp={b1,b2,...,bn}B_p = \{b_1, b_2, ..., b_n\}Bp={b1,b2,...,bn} 与真实边界框 BgtB_{gt}Bgt 之间的接地质量,提出了一种层次交并比 (HIoU) 计算方法,如图 2 所示。该设计通过结合全局和实例级别的补充组件,缓解了奖励欺骗问题(如人为提高 AP 奖励分数)。具体步骤如下:
- 首先计算全局 IoU (GIoU),量化预测边界框与真实边界框整体的空间一致性:
KaTeX parse error: Expected '}', got '\right' at position 405: …phi}_{1}^{g\,t}\̲r̲i̲g̲h̲t̲|}}.
- 接着,通过 Kuhn-Munkres 算法(Kuhn 1955)对预测边界框与真实边界框进行一对一的双向匹配,计算成对 IoU (PIoU)。令 M⊆Bp×BgtM \subseteq B_p \times B_{gt}M⊆Bp×Bgt 表示最大化总 IoU 的最优匹配集:
KaTeX parse error: Undefined control sequence: \L at position 83: …w}^{\mathrm{g}}\̲L̲_{\downarrow}^{…
然后,成对 IoU (PIoU) 得分为匹配对的平均值:
KaTeX parse error: Undefined control sequence: \slash at position 74: …t|\Lambda\!\!\!\̲s̲l̲a̲s̲h̲\Lambda\right|}…
最终 HIoU 得分为全局 IoU 和成对 IoU 准确性的平均值:
HIoU=GIoU+PIoU2.H I o U={\frac{G I o U+P I o U}{2}}. HIoU=2GIoU+PIoU.
推理格式奖励 (rformatr_{format}rformat)
该奖励鼓励模型生成符合指定特殊标记结构的推理输出,具体格式为:<think><area> </area><text></text></think><answer> </answer>。其中 <area>...</area> 必须包含带有深度信息的边界框的 JSON 格式表示,而 <text> 提供基于指定空间区域的合理解释。对于严格遵守此格式的响应,奖励值为 1.0。
渐进式回答准确性奖励 (rans,tr_{ans,t}rans,t)
该奖励结合最终答案的正确性与答案质量随时间的变化,提供比纯规则评估更稳健的信号。具体使用外部视觉语言模型(Doubao-1.5-vision-pro)作为评判者评估响应质量,奖励定义为:
rans,t=st+(st−mean{s1,t−1,⋅⋅⋅,sN,t−1})r_{\mathrm{ans},t}=s_{t}+(s_{t}-\mathrm{mean}\{s_{1,t-1},\cdot\cdot\cdot,s_{N,t-1}\}) rans,t=st+(st−mean{s1,t−1,⋅⋅⋅,sN,t−1})
其中 sts_tst 表示 Doubao 评判者在步骤 ttt 时基于问题、预测答案和真实答案给出的连续分数。项 (st−mean{s1,t−1,...,sN,t−1})(s_t - \mathrm{mean}\{s_{1,t-1},...,s_{N,t-1}\})(st−mean{s1,t−1,...,sN,t−1}) 捕捉连续步骤之间的改进,鼓励模型响应的渐进式优化。
校正增强的接地奖励 (rbboxr_{bbox}rbbox)
鉴于输出格式的结构化特性,可明确提取推理过程中生成的边界框序列,从而实现对逐步接地的细粒度跟踪。令 BiniB_{ini}Bini 表示推理轨迹中首个不覆盖整个图像的边界框,BendB_{end}Bend 表示最终边界框。奖励由最终接地准确性 send=HIoU(Bend,Bgt)s_{end} = HIoU(B_{end}, B_{gt})send=HIoU(Bend,Bgt) 和校正感知的改进项 send−sinits_{end} - s_{init}send−sinit 组成:
rbbox=send+(send−sinit).r_{\mathrm{bbox}}\ =\,s_{\mathrm{end}}+(s_{\mathrm{end}}-s_{\mathrm{init}}). rbbox =send+(send−sinit).
深度一致性奖励 (rdepthr_{depth}rdepth)
空间感知模型应准确捕捉与每个指定区域相关的深度值。为解决幻觉导致的深度不一致问题,对推理过程中生成的深度标记进行逐步验证。对于每个边界框-深度对 (B,d)(B, d)(B,d),从深度图 D1D_1D1 中提取对应的真实深度 dgtd_{gt}dgt,要求绝对误差小于阈值 T=0.1T = 0.1T=0.1。奖励仅在整个推理轨迹的深度值均满足一致性标准时分配:
rdepth=I(∀i:∣di−digt∣digt≤T),r_{\mathrm{depth}}=\mathbb{I}\left(\forall i:{\frac{|d_{i}-d_{i}^{\mathrm{gt}}|}{d_{i}^{\mathrm{gt}}}}\leq T\right), rdepth=I(∀i:digt∣di−digt∣≤T),
其中 I()\mathbb{I}()I() 为指示函数。
实验
我们对 SIFThinker 与多种最先进(SOTA)方法在不同类别上的表现进行了评估。关于数据集和评估指标的更多细节列于补充材料中。
我们将我们的方法与多种 SOTA 方法在多个空间理解基准测试上进行了比较。得益于我们空间感知的图像思考训练范式,我们的模型展示了卓越的 3D 理解能力。如表 1 所示,在相同的基础模型下,我们的方法在 SpatialBench(Cai 等人,2024)上比 SpatialBot(Cai 等人,2024)提高了 7.82%(64.3 对 59.6),比 SSR(Liu 等人,2025b)提高了 11.17%(74.5 对 67.1)。此外,我们在更大规模的基准测试 SAT(Static)(Ray 等人,2024)和 CV-Bench(Tong 等人,2024)上评估了我们的方法,分别比 Qwen2.5-VL-7B 基础模型提高了 11.15%(72.8 对 65.5)和 3.97%(75.9 对 73.0)。尽管 SpatialBot 和 SSR 都引入了深度图像以增强空间理解,但我们认为深度感知和空间 grounding 本质上是互补的。通过引入对空间 grounding 区域的推理,我们的方法取得了更显著的改进。我们进一步与代表性的 SOTA 闭源模型——ChatGPT-o3(OpenAI,2025)进行了比较。在 SpatialBench 上,SIFThinker 取得了与 o3 相当的平均分数(74.6 对 74.8)。值得注意的是,在 SAT-Static 上,我们的方法甚至以 8.01% 的显著优势超过了 o3(72.8 对 67.4),展示了 SIFThinker 在空间感知方面的卓越能力。
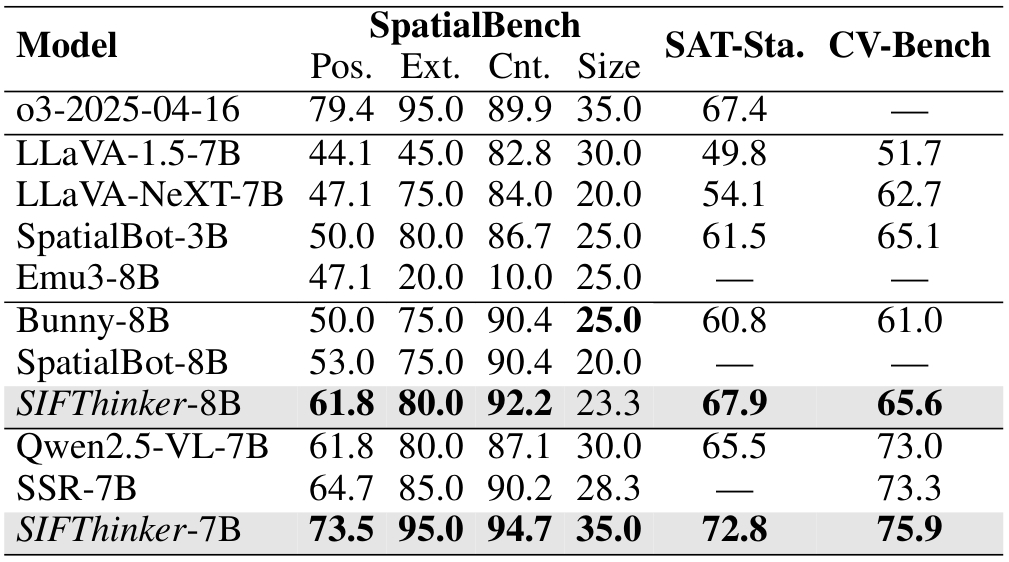
表 1:空间感知评估结果,涵盖 SpatialBench(位置、存在、计数、大小)、SAT(Static)和 CV-Bench。Bunny-LLaMA3-8B 和 Qwen2.5-VL-7B 分别作为第三和第四组的基础模型。最佳结果已高亮显示。
视觉感知
在本节中,我们全面评估了该方法在视觉理解、grounding 能力和自纠错能力方面的视觉感知能力。
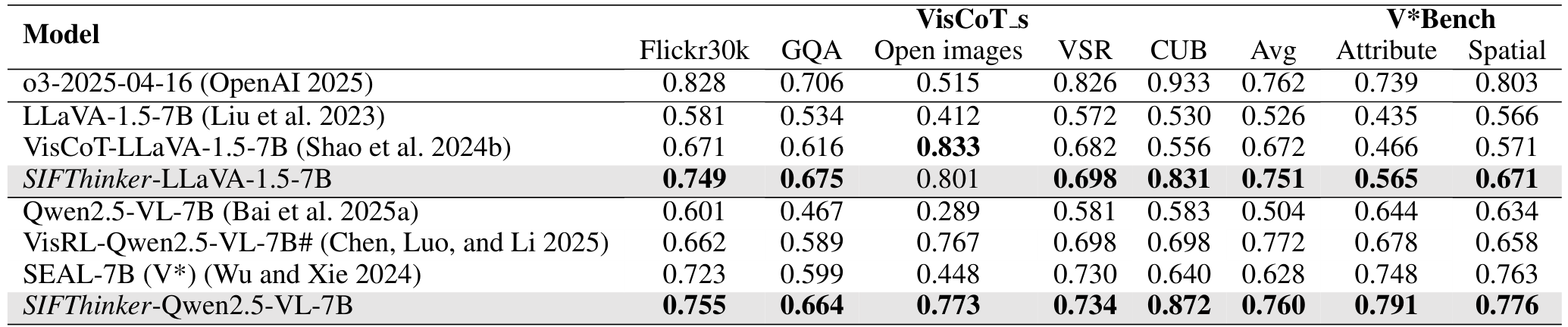
视觉理解:我们从 VisCoT 中选择了与场景相关的(例如非平面)子集作为 VisCoT-s,并从 VBench 中选择了属性和空间子集。如表 2 所示,在 VisCoT-s 数据集上,在相同的 LLaVA-1.5-7B 基础模型下,SIFThinker 比 VisCoT 提高了 11.76%(0.751 对 0.672)。以 Qwen2.5-VL-7B 作为训练的基础模型,我们比 VisRL 提高了 8.89%(0.760 对 0.698)。VBench 在高分辨率图像上的细粒度感知评估更具挑战性。值得注意的是,我们的方法在属性子集上比最先进的方法 SEAL 提高了 5.75%(0.791 对 0.748),在空间子集上提高了 1.70%(0.776 对 0.763)。与 VisCoT、VisRL 和 SEAL 不同,SIFThinker 不依赖于分阶段的裁剪图像过程。
论文摘要(中文)
以下是对所提供学术论文部分的中文总结,保留了原文中的Markdown图片部分,并将其放置在适当位置。
通用视觉语言模型基准测试
正如表4所示,我们报告了在广泛使用的通用基准测试上的结果,包括MME(Fu等人,2024)的感知部分(MMEP)、MME认知部分(MMEC)、MMBench(Liu等人,2024b)的测试和开发集(分别表示为MMBT和MMBD)、SEED-Bench(Li等人,2023a)的图像部分(SEED-I)、VQAV2(Goyal等人,2017)的测试-开发分割,以及POPE(Li等人,2023c)(以COCO验证集上三个类别的平均F1分数衡量)。在大多数这些基准测试中,SIFThinker不仅避免了性能下降,甚至取得了显著的改进,展示了我们方法的稳健性——特别是在深度信息有益的场景下。在相同的基准模型下,SIFThinker始终优于专注于细粒度视觉感知的VisCoT和强调空间推理的SpatialBot。值得注意的是,在MMBT上,SIFThinker在不同的基准模型设置下实现了约4%的改进(在LLaVA-1.5-7B上为69.3 vs. 66.5,在Bunny-Llama3-8B上为76.8 vs. 73.7,在Qwen2.5-VL-7B上为83.4 vs. 80.3)。
消融研究
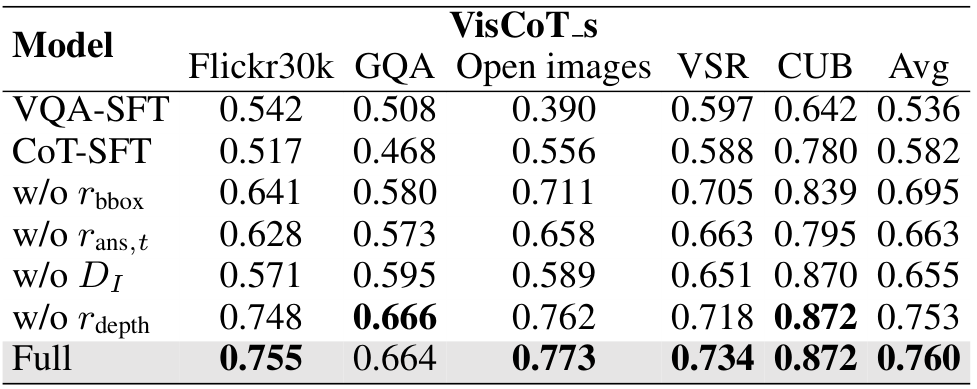
在本节中,我们在表5中展示了全面的消融研究。VQA-SFT指的是直接在原始问答对上应用SFT,这些问答对是构建SIF-50K的源数据,而CoT-SFT则利用了算法1中引入的思维链(Chain-of-Thought, CoT)构建策略。这表明引导模型通过图像进行思考可以带来显著的性能提升,达到了8.58%(0.582 vs. 0.536)。然而,仅使用SFT主要帮助模型学习输出格式,在某些情况下(例如GQA)甚至会导致性能下降。相比之下,引入强化学习(RL)带来了持续且显著的改进,相较于仅使用SFT实现了额外的30.58%的提升(0.760 vs. 0.582)。我们进一步对各种RL奖励(包括w/o rans, t, rbbox, rdepth)进行了消融实验,并评估了深度信息(w/o D1)的影响。结果表明,观察到的性能提升主要归因于三个关键因素:1)通过图像思考的推理范式,促进了空间 grounding 的认知;2)精心设计的边界框预测和响应生成的奖励函数,协同工作以鼓励迭代修正和优化;3)深度输入的加入,增强了模型在 grounding 过程中的空间智能。这些设计共同形成了一个统一且稳健的空间感知视觉 grounding 框架,赋予模型通用推理能力,从而在多样化的基准测试中提升了性能。
结论与局限性
在本文中,我们提出了SIFThinker,一个空间感知的图像-文本交错推理框架。受人类在3D环境中基于提示驱动的搜索启发,SIFThinker在提供最终响应之前执行空间感知的 grounding。具体来说,我们引入了一种新颖的管道,用于生成针对通过图像思考推理的CoT数据集,实现了过程级别的监督。基于此数据集,我们提出了GRPO-SIF,不仅纳入了区域级别的校正信号,还提出了进度学习和深度一致性奖励。广泛的实验表明SIFThinker在多样化的基准测试中是有效的。
局限性与未来工作:由于SIFThinker是在单张图像上训练的,它可能在需要跨多张图像进行推理的动态空间场景中面临挑战。我们认为将其扩展到此类设置将具有更高的实际影响,值得未来研究。
训练数据集
我们基于CoT数据生成管道提出了用于训练的SIF-50K数据集。数据来源于VisCoT训练集(Shao等人,2024b)和TallyQA(Acharya, Kafe 和 Kanan,2019),每个源样本包含一个问题、图像、答案和真实的边界框。数据集统计信息在表6中提供。
基准测试
我们对一系列基准测试进行了评估,遵循每个基准定义的指标设置。
空间智能
SpatialBench:我们使用 SpatialBench(Cai 等人,2024)评估 MLLM 的空间理解能力,该数据集包含手动标注的专注于空间理解和推理的问答对。我们使用了四个类别:位置(34 个样本)、存在性(40 个样本)、计数(20 个样本)和大小(40 个样本)。
SAT(静态):SAT 数据集(Ray 等人,2024)包括静态和动态空间推理任务。我们选择了静态评估子集(单张图像),包含 127405 个样本。
CV-Bench:CV-Bench(Tong 等人,2024)包含 2638 个手动检查的样本,涵盖四个任务:空间关系、对象计数、深度顺序和相对距离。
视觉感知
VisCoT-s:VisCoT-s 是 VisCoT 数据集(评估部分)的一个子集(Shao 等人,2024b),包含多个场景特定的数据集(3D 信息可能有所帮助),包括 Flickr30k(Plummer 等人,2015)、VSR(Liu, Emerson 和 Collier,2023)、GQA(Hudson 和 Manning,2019)、Open Images(Kuznetsova 等人,2020)和 CUB(Wah 等人,2011)。具体来说,Flickr30k 包含大多数参考对象的边界框标注,在此基础上,Shao 等人(2024b)进一步利用 GPT-4 生成专门针对小对象的提问。视觉空间推理(VSR)、GQA 和 Open Images 数据集在图像实体之间的空间关系信息方面非常丰富。Birds-200-2011(CUB)数据集是一个广泛采用的细粒度视觉分类基准,包含高分辨率的鸟类图像以及详细的部位标注、属性标签和边界框。为了更好地在 MLLM 背景下利用该数据集,Shao 等人(2024b)设计了需要模型识别细粒度鸟类特征的探测问题,从而评估其详细视觉识别能力。
V*Bench:为了评估 MLLM 在复杂视觉场景(高密度、高分辨率图像)中的表现,我们使用了 V*Bench(Wu 和 Xie,2024),这是一个包含 191 张图像(平均分辨率:2246x1582)的基准测试,包含两个任务:属性识别(115 个样本)和空间关系推理(76 个样本)。这些任务评估模型的细粒度视觉理解能力。
视觉 grounding
RefCOCO/RefCOCO+/RefCOCOg:指代表达式理解(REC)可以直接使用预测边界框与真实边界框之间的交并比(IoU)作为明确的评估指标。因此,我们在 REC 基准测试上评估了多种方法,包括 RefCOCO(Kazemzadeh 等人,2014)、RefCOCO+(Mao 等人,2016)和 RefCOCOg(Mao 等人,2016)。RefCOCO 和 RefCOCO+ 通过交互式游戏收集数据,遵循标准的 val/testA/testB 划分,其中 testA 关注人类,testB 关注其他对象。RefCOCO+ 的查询中排除了绝对空间术语。RefCOCOg 以非交互方式收集,特征是更长且更具描述性的查询。我们遵循 Shao 等人(2024b)将 IoU 阈值设置为 0.5 用于准确率评估,即以 Top-1 Accuracy @0.5 作为评估指标。
OVDEval:OVDEval(Yao 等人,2023)是一个针对开放词汇检测任务的基准测试,包含 9 个子任务,评估常识推理、属性和空间理解、对象关系等。与 RefCOCO/RefCOCO+/RefCOCOg 相比,OVDEval 支持多对象 grounding,包含多个边界框标注。此外,我们采用了 OVDEval(Yao 等人,2023)中的非极大值抑制平均精度(NMS-AP)指标进行评估。
通用视觉语言模型基准测试
我们进一步在五个通用基准测试上评估了模型,如正文表4中总结的那样:
- MME(Fu等人,2024):通过14个子任务评估感知和认知能力;
- MM-Bench(Liu等人,2024b):一个系统设计的基准测试,覆盖20个能力维度,用于稳健、全面的评估;
- SEED-Bench(Li等人,2023a):包含19242个多选题,拥有高质量的人工标注,涵盖图像和视频模态的12个评估维度;
- VQA(Goyal等人,来自COCO和抽象场景):需要视觉、语言和常识理解;
- POPE(Li等人,2023c):将幻觉评估框架化为二元对象存在问题。
关于评估划分的更多细节已在正文第4节中详细说明。
实现细节
实验设置
我们在配备8个NVIDIA H2096GB和Intel® Xeon® Platinum 8457C(180核)的机器上执行所有实验。
超参数设置
以Qwen2.5-VL-7B为例,在SFT阶段,我们使用了完整的SIF-50k数据集,将LORA秩(即rrr)设置为8,训练3个epoch,学习率为1e−41e-41e−4。在RL阶段,我们仅从SIF-50k数据集中抽取了200个样本。我们采用了默认的GRPO超参数设置,将NNN配置为8,KL散度比(即β\betaβ)为0.04,LORA秩(即rrr)为64,并以学习率1e−51e-51e−5训练20个epoch。SFT和RL阶段的最大完成长度均设置为2028个token。
在这里,我们展示了我们方法中使用的提示设计。具体来说,为了让SIFThinker采用“与图像一起思考”的生成范式,我们使用了图5中所示的提示。在数据生成管道的最后阶段,当使用高级模型完成CoT推理时,我们应用了图6中描述的提示。
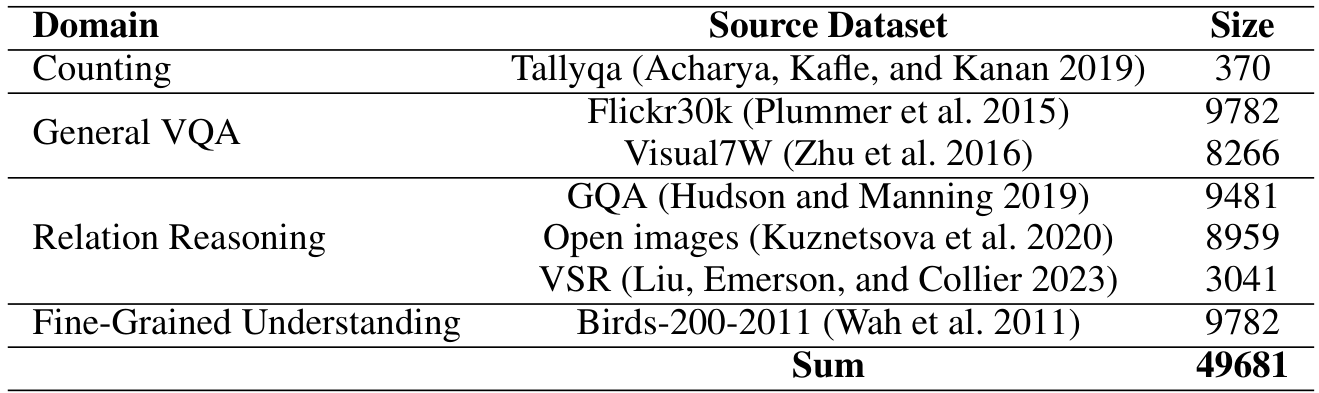
表6:SIF-50K数据集概述。该数据集涵盖四个不同领域,并包括多个来源数据集。原始图像:\n深度图像:\n {problem} 请先在 标签中输出思考过程,其中包含深度的边界框用 标签包围,文本分析用
图5:专门设计的提示,用于指导模型生成交错的图像-文本推理链,在推理过程中始终附加。
图6中描述了用于CoT生成的提示,作为我们数据生成管道中构建SIF-50K数据集的基础。对于RL阶段答案的奖励计算以及基准评估,我们使用了图7中提供的提示。最后,对于REC和OVD任务的推理,我们分别采用了图8和图9中所示的提示模板。
CoT完成提示
图6:用于CoT生成的提示,作为我们数据生成管道中构建SIF-50K数据集的基础。
判断答案准确性的提示
系统提示
您负责校对答案,需要根据给定的问题和图像,参考标准答案对模型的回答进行评分。满分为1分,最低分为0分。请直接以JSON格式提供分数,例如{“score”:0.8},无需展示中间过程。评估标准要求模型答案与标准答案越接近,分数越高。
提示
问题:{question}
标准答案:{gt_response}
模型答案:{pred_response}
图7:设计用于评估模型生成答案与真实答案准确性的提示,用于计算奖励和基准评估。
REC任务的提示模板
请提供此句子描述区域的边界框坐标:{query}
图8:为评估模型在指代表达理解(REC)任务上的表现而设计的提示。
开放词汇检测(OVD)的提示模板
论文内容摘要(中文):
本文介绍了用于评估模型在开放词汇检测(OVD)任务中表现的提示模板。提示内容为:“请仔细检查图像并检测以下对象:{targetlist}。如果图像中没有这些目标对象,请简单回复‘None’。” 通过这一提示,模型需要在图像中识别指定的目标对象,并在未发现目标时做出相应反馈。此外,文中还提到在图9中展示了为OVD任务设计的提示内容。
在图10、11、12和13中,作者进一步展示了SIFThinker的更多可视化结果。对于每个问题-图像对,展示了深度解释器生成的深度图,并突出显示了SIFThinker在交错的图像-文本推理过程中关注的区域(红色边界框)。同时,还提供了真实的标注数据以供对比。
以下是原文中包含的图像部分,保持其原始格式和位置:
Figure 9: Prompt designed for evaluating model performance on the Open-Vocabulary Detection (OVD) task
More visualization
In Fig. 10, 11, 12, and 13, we present additional visualizations of SIFThinker. For each question-image pair, we show the depth map generated by the depth interpreter, highlight the focused regions (red bounding boxes) of SIFThinker during the interleaved image-text reasoning. Ground-truth annotations are also provided for comparison.
 # Ground truth: white
# Ground truth: white
 # Ground truth: blue
# Ground truth: blue


Ground truth: GUESTTEAM
Input: From the information on the black framed board, how long do we have to wait in line for this attraction?


The wait time for the attraction is 10 minutes # Ground truth: 10 minutes
Original Abstract: Current multimodal large language models (MLLMs) still face significant
challenges in complex visual tasks (e.g., spatial understanding, fine-grained
perception). Prior methods have tried to incorporate visual reasoning, however,
they fail to leverage attention correction with spatial cues to iteratively
refine their focus on prompt-relevant regions. In this paper, we introduce
SIFThinker, a spatially-aware “think-with-images” framework that mimics human
visual perception. Specifically, SIFThinker enables attention correcting and
image region focusing by interleaving depth-enhanced bounding boxes and natural
language. Our contributions are twofold: First, we introduce a
reverse-expansion-forward-inference strategy that facilitates the generation of
interleaved image-text chains of thought for process-level supervision, which
in turn leads to the construction of the SIF-50K dataset. Besides, we propose
GRPO-SIF, a reinforced training paradigm that integrates depth-informed visual
grounding into a unified reasoning pipeline, teaching the model to dynamically
correct and focus on prompt-relevant regions. Extensive experiments demonstrate
that SIFThinker outperforms state-of-the-art methods in spatial understanding
and fine-grained visual perception, while maintaining strong general
capabilities, highlighting the effectiveness of our method.
PDF Link: 2508.06259v1
部分平台可能图片显示异常,请以我的博客内容为准







)


)



![[鹧鸪云]光伏AI设计平台解锁电站开发新范式](http://pic.xiahunao.cn/[鹧鸪云]光伏AI设计平台解锁电站开发新范式)





