文章目录
- 1.什么是Shuffle?
- 2.Shuffle解决什么问题?
- 3.Shuffle Write与Shuffle Read
- 4.Shuffle的计算需求
- 4.1 计算需求表
- 4.2 partitionby
- 4.3 groupByKey
- 4.4 reduceByKey
- 4.5 sortByKey
- 5.Shuffle Write框架设计与实现
- 5.1 Shuffle Write框架实现的功能
- 5.2 Shuffle Write的多种情况
- 5.2.1 不需要combine和sort
- 5.2.1.1 操作流程
- 5.2.1.2 优缺点
- 5.2.1.3 适用性
- 5.2.2 不需要combine,需要sort
- 5.2.2.1 操作流程
- 5.2.2.2 优缺点
- 5.2.2.3 适用性
- 5.2.3 需要combile,需要/不需要sort
- 5.2.3.1 操作流程
- 5.2.3.2 优缺点
- 5.2.3.3 适用性
- 6.Shuffle Read框架设计与实现
- 6.1 Shuffle Read框架实现的功能
- 6.2 Shuffle Read的不同情况
- 6.2.1 不需要combine和sort
- 6.2.1.1 操作流程
- 6.2.1.2 优缺点
- 6.2.1.3 适用性
- 6.2.2 不需要combine,需要sort
- 6.2.2.1 操作流程
- 6.2.2.2 优缺点
- 6.2.2.3 适用性
- 6.2.3 需要combine,需要/不需要sort
- 6.2.3.1 操作流程
- 6.2.3.2 优缺点
- 6.2.3.3 适用性
阅读本篇文章前,需要阅读 Spark执行计划与UI分析
1.什么是Shuffle?
运行在不同stage、不同节点上的task间如何进行数据传递。这个数据传递过程通常被称为Shuffle机制。
2.Shuffle解决什么问题?
如果是单纯的数据传递,则只需要将数据进行分区、通过网络传输即可,没有太大难度,但Shuffle机制还需要进行各种类型的计算(如聚合、排序),而且数据量一般会很大。如何支持这些不同类型的计算,如何提高Shuffle的性能都是Shuffle机制设计的难点问题。
3.Shuffle Write与Shuffle Read
- Shuffle Write:上游stage预先将输出数据进行划分,按照分区存放,分区个数与下游task个数一致,这个过程被称为"Shuffle Write"。
- Shuffle Read:上游数据按照分区存放完成后,下游的task将属于自己分区的数据通过网络传输获取,然后将来自上游不同分区的数据聚合再一起处理,这个过程称为"Shuffle Read"。
4.Shuffle的计算需求
4.1 计算需求表
所谓计算需求,也就是Shuffle要解决具体算子的哪些计算需求:
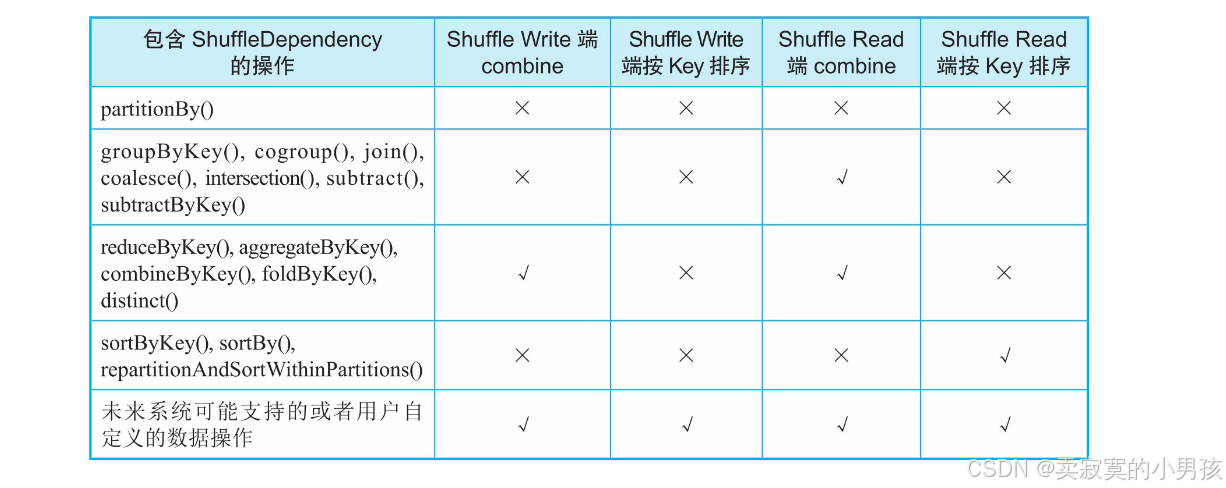
这里我来分析几个例子:
4.2 partitionby
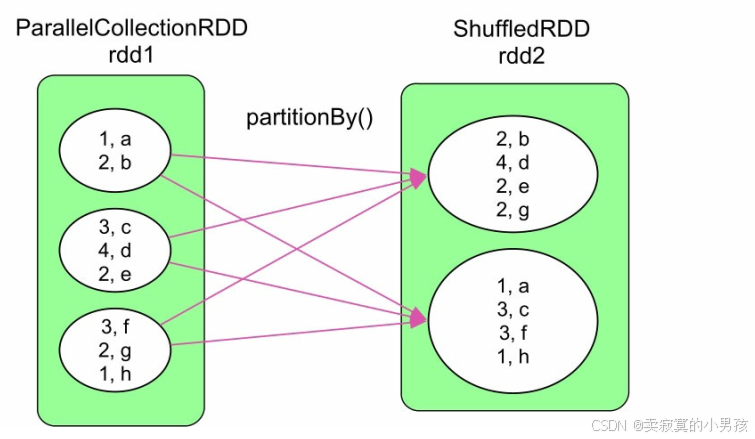
可以看到partitionby操作只进行了数据分区操作,并没有涉及到数据的聚合和排序操作。
4.3 groupByKey
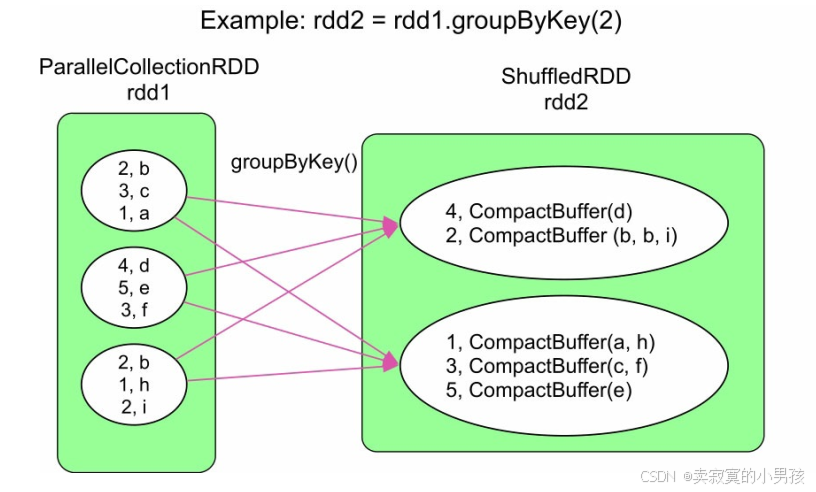
可以看到groupByKey的操作既需要分区,又需要做聚合,并且在Shuffle Read阶段做的聚合。
4.4 reduceByKey
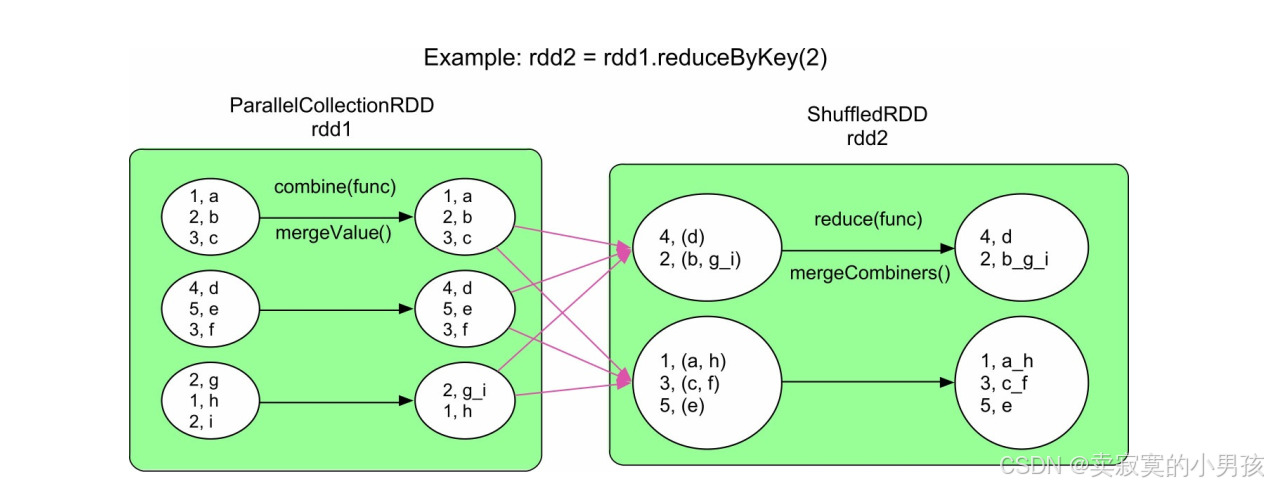
可以看到reduceByKey做了两步聚合,在Shuffle Write中先执行func聚合一次(由spark内部执行,不生成新的rdd),然后进行分区数据传输,最后再在每个分区聚合一次,执行相同的func函数。同时func需要满足交换律和结合律。两次聚合(多了Shuffle Write端聚合)的优点是优化Shuffle的性能,一是传输的数据量大大减少,二是降低Shuffle Read端的内存消耗。
4.5 sortByKey
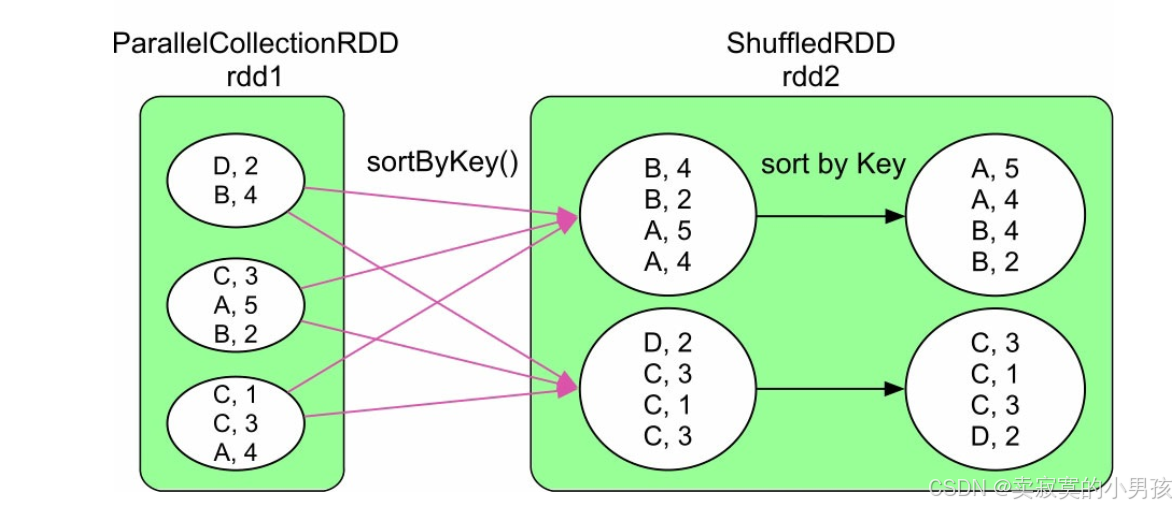
分区后,在ShuffleRead端进行排序。sortByKey() 为了保证生成的RDD中的数据是全局有序(按照Key排序) 的, 采用Range划分来分发数据。 Range划分可以保证在生成的RDD中, partition 1中的所有record的Key小于(或大于) partition 2中所有的record的Key。
可以看到当前并没有算子需要在Shuffle Write端进行排序的,但不能保证用户实现的算子不会在Shuffle Write端进行排序,因此在spark实现Shuffle框架的时候保留了在Shuffle Write端进行排序的功能。
5.Shuffle Write框架设计与实现
5.1 Shuffle Write框架实现的功能
如第四节中的图所示,每个数据操作只需要其中的一个或两个功能。Spark为了支持所有的情况,设计了一个通用的Shuffle Write框架,框架的计算顺序为“map()输出→数据聚合→排序→分区”输出。
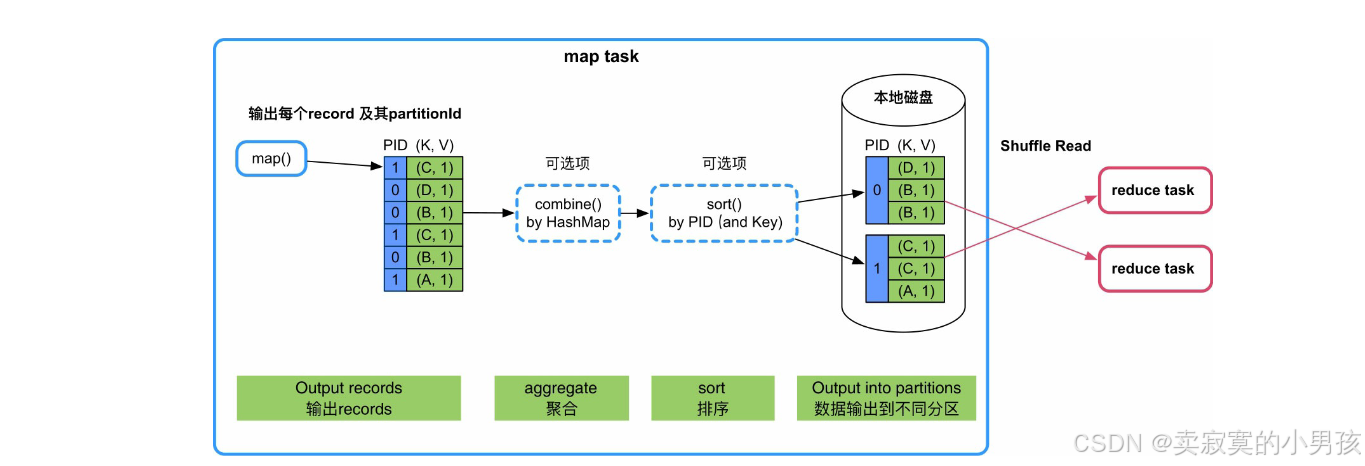
map task每计算出一个record及其partitionId,就将record放入类似HashMap的数据结构中进行聚合;聚合完成后,再将HashMap中的数据放入类似Array的数据结构中进行排序,既可按照partitionId,也可以按照partitionId+Key进行排序;最后根据partitionId将数据写入不同的数据分区中,存放到本地磁盘上。partitionId=Hash(Key)% 下游分区数。
5.2 Shuffle Write的多种情况
5.2.1 不需要combine和sort
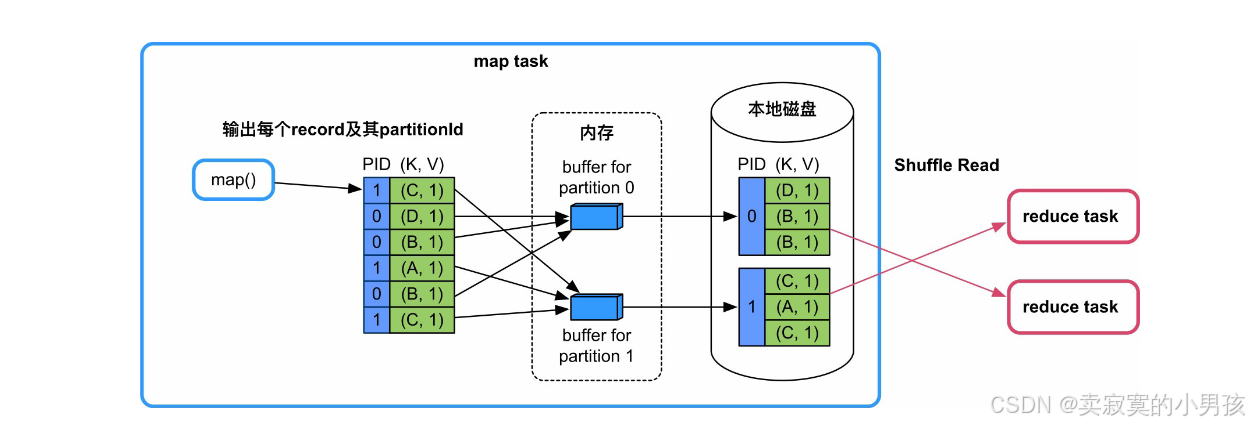
这种Shuffle Write方式称为:BypassMergeSortShuffleWriter
这种情况最简单,只需要实现分区功能:
5.2.1.1 操作流程
map()依次输出KV record,并计算其partitionId(PID),Spark根据 partitionId,将record依次输出到不同的buffer中,每当buffer填满就将record溢写到磁盘上的分区文件中。分配buffer的原因是map()输出record的速度很快,需要进行缓冲来减少磁盘I/O。
5.2.1.2 优缺点
该模式的优点是速度快,直接将record输出到不同文件中。缺点是资源消耗过高,每个分区都需要有一个buffer(默认大小为32KB,由spark.Shuffle.file.buffer进行控制),当分区数过大时,内存消耗会很高。
5.2.1.3 适用性
适用于Shuffle Write端不需要聚合和排序且分区个数较少(小于spark.Shuffle.sort.bypassMergeThreshold,默认值为200),例如groupBy(100),partitionBy(100),sortByKey(100)。
5.2.2 不需要combine,需要sort
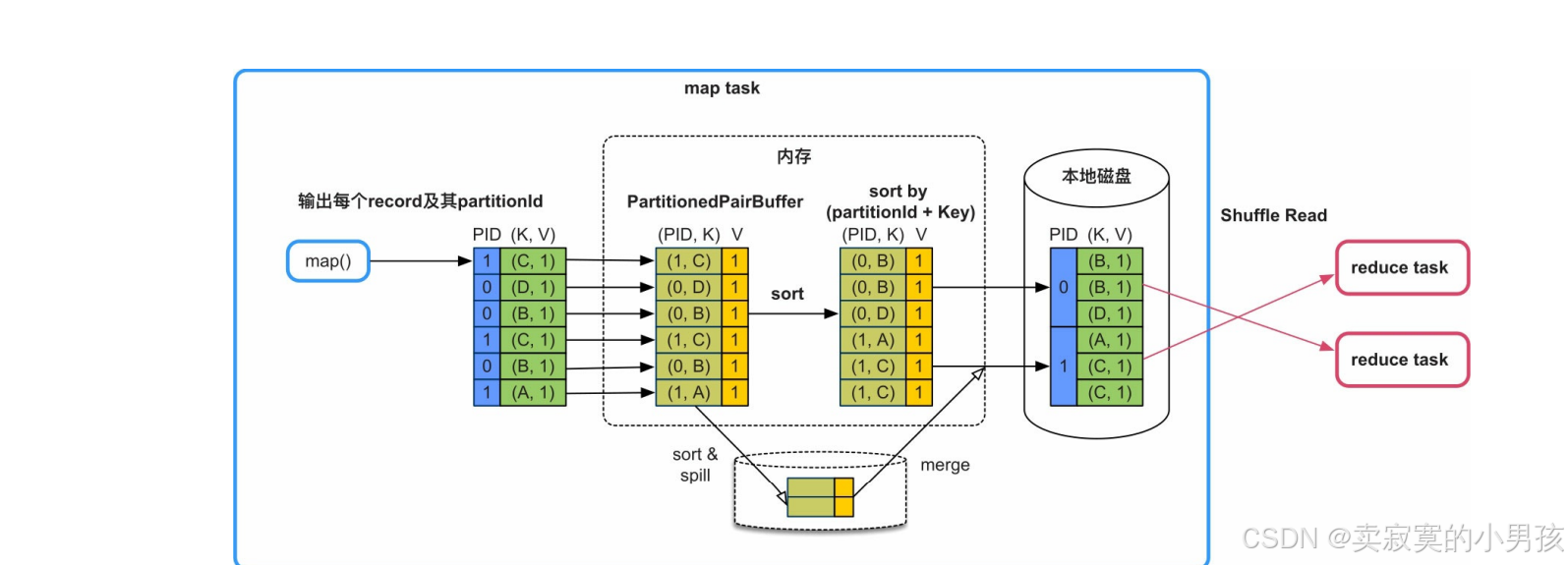
这种Shuffle模式被命名为:SortShuffleWriter(KeyOrdering=true),使用的Array被命名为PartitionedPairBuffer。
5.2.2.1 操作流程
- 这种情况需要使用partitionId+key进行排序,Spark采用的实现方法是建立一个Array:PartitionedPairBuffer,来存放map()输出的record,并将每个<K,V>record转化为<(PartitionId,K),V>record,然后按照PartitionId+Key对record进行排序,最后将所有record写入写入一个文件中,通过建立索引来标示每个分区。
- 如果Array存放不下,则会先扩容,如果还存放不下,就将Array中的record排序后spill到磁盘上,等待map()输出完以后,再将Array中的record与磁盘上已排序的record进行全局排序,得到最终有序的record,并写入文件中。
5.2.2.2 优缺点
- 优点是只需要一个Array结构就可以支持按照partitionId+Key进行排序,Array大小可控,而且具有扩容和spill到磁盘上的功能,支持从小规模到大规模数据的排序。同时,输出的数据已经按照partitionId进行排序,因此只需要一个分区文件存储,即可标示不同的分区数据,克服了BypassMergeSortShuffleWriter中建立文件数过多的问题,适用于分区个数很大的情况。缺点是排序增加计算时延。
5.2.2.3 适用性
- map()端不需要聚合(combine)、Key需要排序、分区个数无限制。目前,Spark本身没有提供这种排序类型的数据操作,但不排除用户会自定义,或者系统未来会提供这种类型的操作。sortByKey()操作虽然需要按Key进行排序,但这个排序过程在Shuffle Read端完成即可,不需要在Shuffle Write端进行排序。
最后,使用这种Shuffle如何解决BypassMergeSortShuffleWriter存在的buffer分配过多的问题?我们只需要将“按PartitionId+Key排序”改为“只按PartitionId排序”,就可以支持“不需要map()端combine、不需要按照Key进行排序,分区个数过大”的操作。例如,groupByKey(300)、partitionBy(300)、sortByKey(300)。
5.2.3 需要combile,需要/不需要sort
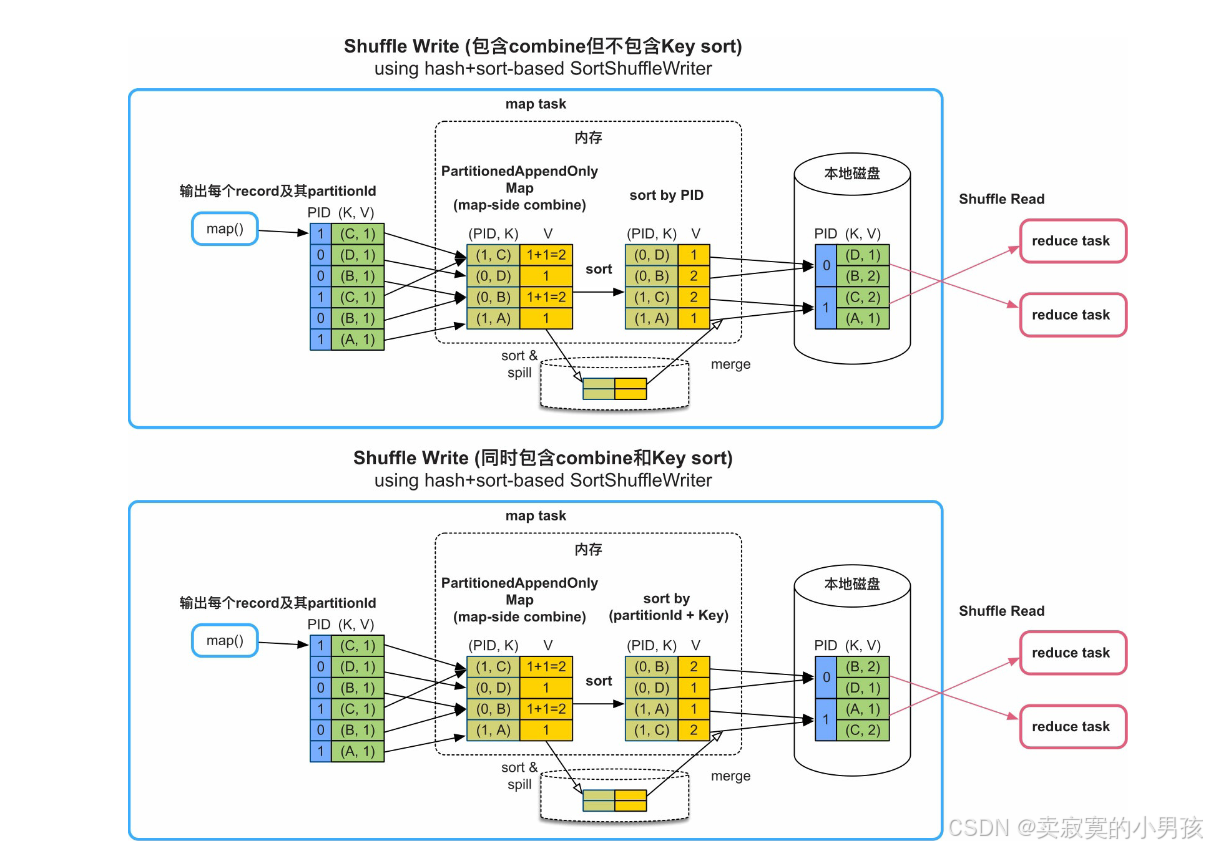
这种Shuffle模式被称为:sort-based Shuffle Write,哈希表为:PartitionedAppendOnlyMap
5.2.3.1 操作流程
- 需要实现按Key进行聚合(combine)的功能,Spark采用的实现方法是建立一个类似HashMap的数据结构对map()输出的record进行聚合。HashMap中的Key是“partitionId+Key”,HashMap中的Value是经过相同combine的聚合结果。在图中,combine()是sum()函数,那么Value中存放的是多个record对应的Value相加的结果。
- 聚合完成后,Spark对HashMap中的record进行排序。如果不需要按Key进行排序,如上图所示,那么只按partitionId进行排序;如果需要按Key进行排序,如图6.7的下图所示,那么按partitionId+Key进行排序。最后,将排序后的record写入一个分区文件中。其中使用的hash表既可以实现聚合功能,也可以实现排序功能。
- 如果HashMap存放不下,则会先扩容为两倍大小,如果还存放不下,就将HashMap中的record排序后spill到磁盘上。此时,HashMap被清空,可以继续对map()输出的record进行聚合,如果内存再次不够用,那么继续spill到磁盘上,此过程可以重复多次。当map()输出完成以后,将此时HashMap中的reocrd与磁盘上已排序的record进行再次聚合(merge),得到最终的record,输出到分区文件中。
5.2.3.2 优缺点
- 优缺点同5.4.2
5.2.3.3 适用性
- 适合map()端聚合(combine)、需要或者不需要按Key进行排序、分区个数无限制的应用,如reduceByKey()、aggregateByKey()等。
6.Shuffle Read框架设计与实现
6.1 Shuffle Read框架实现的功能
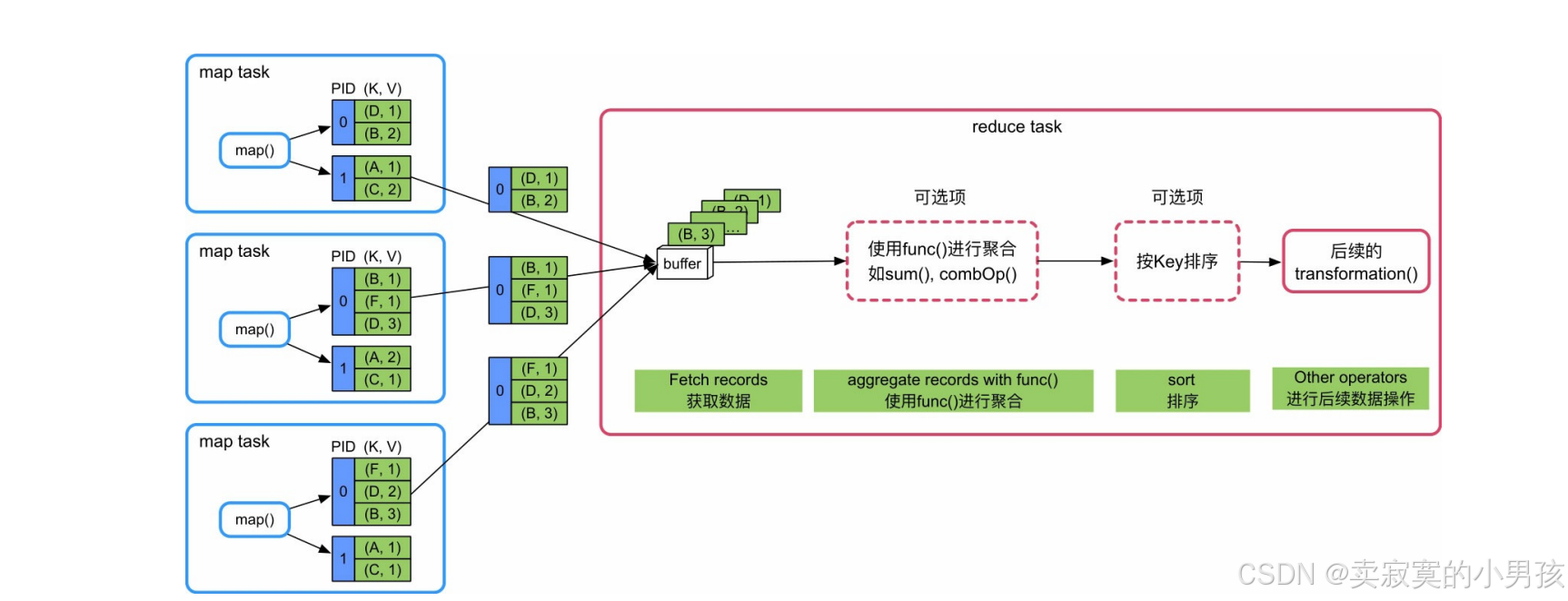
reduce task不断从各个map task的分区文件中获取数据(Fetch records),然后使用类似HashMap的结构来对数据进行聚(aggregate),该过程是边获取数据边聚合。聚合完成后,将HashMap中的数据放入类似Array的数据结构中按照Key进行排序(sort byKey),最后将排序结果输出或者传递给下一个操作。
6.2 Shuffle Read的不同情况
6.2.1 不需要combine和sort
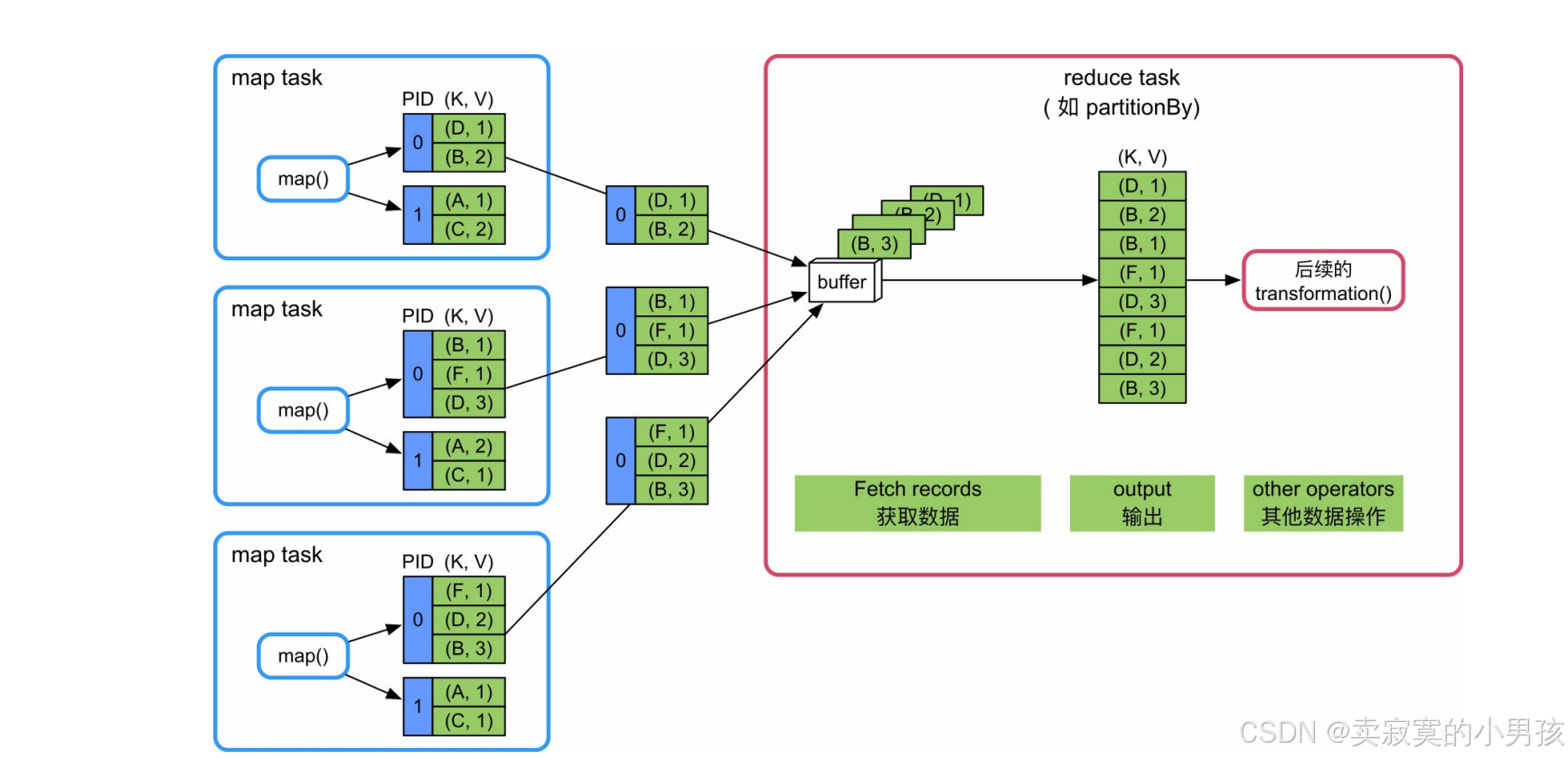
6.2.1.1 操作流程
- 这种情况最简单,只需要实现数据获取功能即可。等待所有的map task结束后,reduce task开始不断从各个map task获取<K,V>record,并将record输出到一个buffer中(大小为spark.reducer.maxSizeInFlight=48MB),下一个操作直接从buffer中获取数据即可。
6.2.1.2 优缺点
- 优点是逻辑和实现简单,内存消耗很小。缺点是不支持聚合、排序等复杂功能。
6.2.1.3 适用性
- 适合既不需要聚合也不需要排序的应用,如partitionBy()等。
6.2.2 不需要combine,需要sort
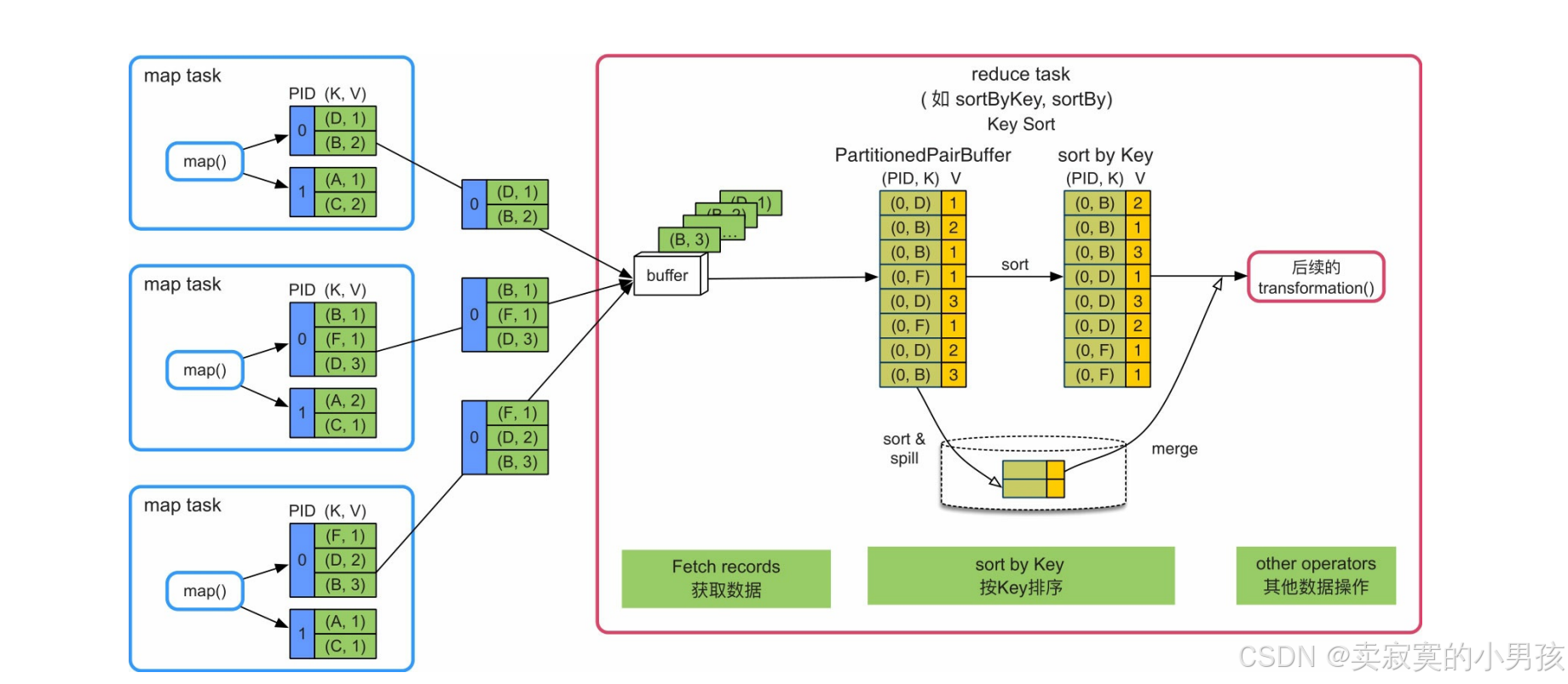
使用的Array结构:PartitionedPairBuffer
6.2.2.1 操作流程
- 获取数据后,将buffer中的record依次输出到一个Array结构(PartitionedPairBuffer)中。由于这里采用了本来用于Shuffle Write端的PartitionedPairBuffer结构,所以还保留了每个record的partitionId。然后,对Array中的record按照Key进行排序,并将排序结果输出或者传递给下一步操作。
- 当内存无法存下所有的record时,PartitionedPairBuffer将record排序后spill到磁盘上,最后将内存中和磁盘上的record进行全局排序,得到最终排序后的record。
6.2.2.2 优缺点
- 优点是只需要一个Array结构就可以支持按照Key进行排序,Array大小可控,而且具有扩容和spill到磁盘上的功能,不受数据规模限制。缺点是排序增加计算时延。
6.2.2.3 适用性
- 适合reduce端不需要聚合,但需要按Key进行排序的操作,如sortByKey()、sortBy()等。
6.2.3 需要combine,需要/不需要sort
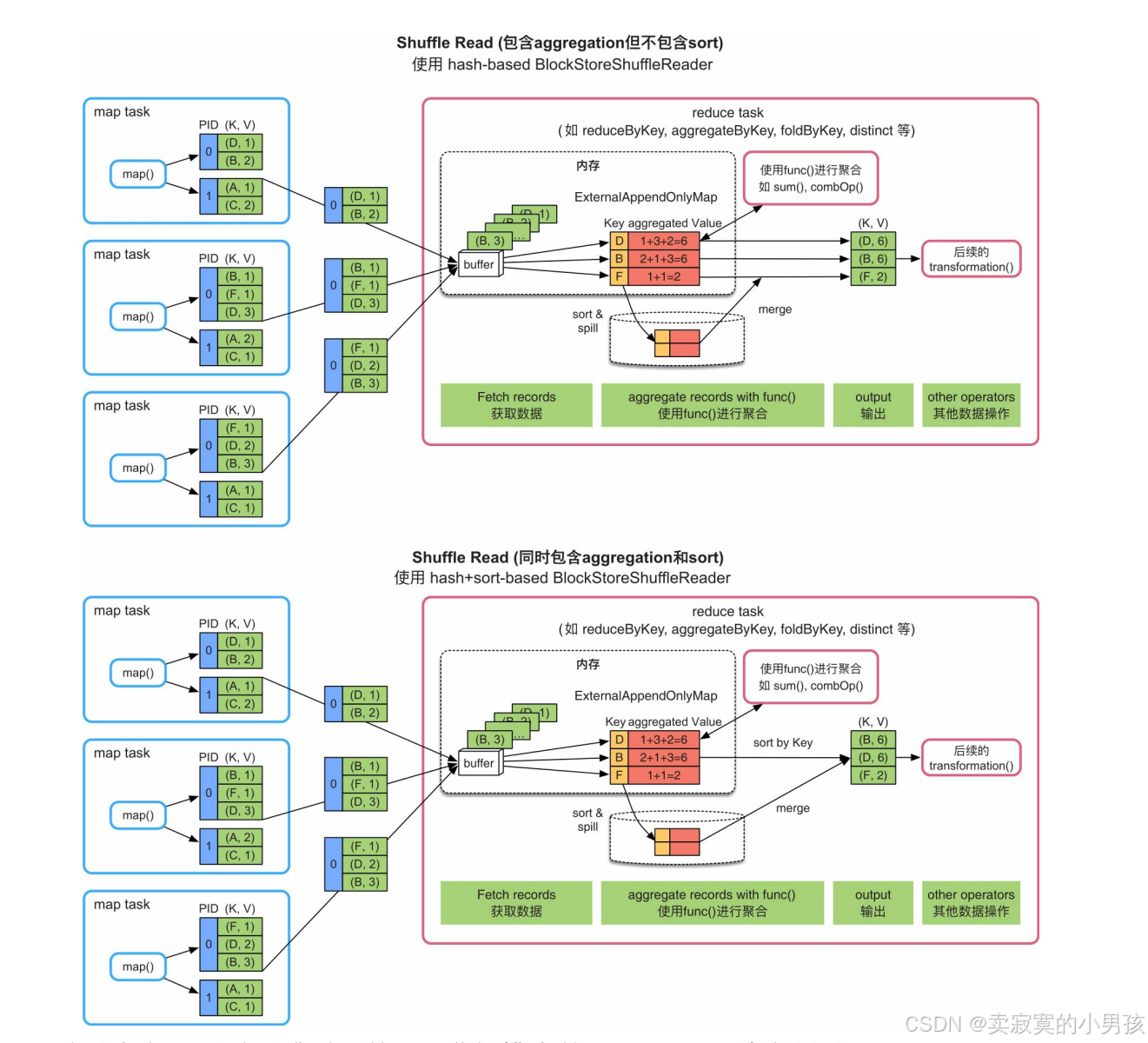
哈希表:ExternalAppendOnlyMap
6.2.3.1 操作流程
- 获取record后,Spark建立一个类似HashMap的数据结构(ExternalAppendOnlyMap)对buffer中的record进行聚合,HashMap中的Key是record中的Key,HashMap中的Value是经过相同聚合函数(func())计算后的结果。
- 聚合函数是sum()函数,那么Value中存放的是多个record对应Value相加后的结果。之后,如果需要按照Key进行排序,如下图所示,则建立一个Array结构,读取HashMap中的record,并对record按Key进行排序,排序完成后,将结果输出或者传递给下一步操作。
- 如果HashMap存放不下,则会先扩容为两倍大小,如果还存放不下,就将HashMap中的record排序后spill到磁盘上。此时,HashMap被清空,可以继续对buffer中的record进行聚合。如果内存再次不够用,那么继续spill到磁盘上,此过程可以重复多次。当聚合完成以后,将此时HashMap中的reocrd与磁盘上已排序的record进行再次聚合,得到最终的record,输出到分区文件中。
注意,这里的排序和聚合依然使用的同一个数据结构。
6.2.3.2 优缺点
- 同上一节。
6.2.3.3 适用性
- 适合reduce端需要聚合、不需要或需要按Key进行排序的操作,如reduceByKey()、aggregateByKey()等。






![[QtADS]解析ads.pro](http://pic.xiahunao.cn/[QtADS]解析ads.pro)








)



