4 正则化
4.1 概述
-
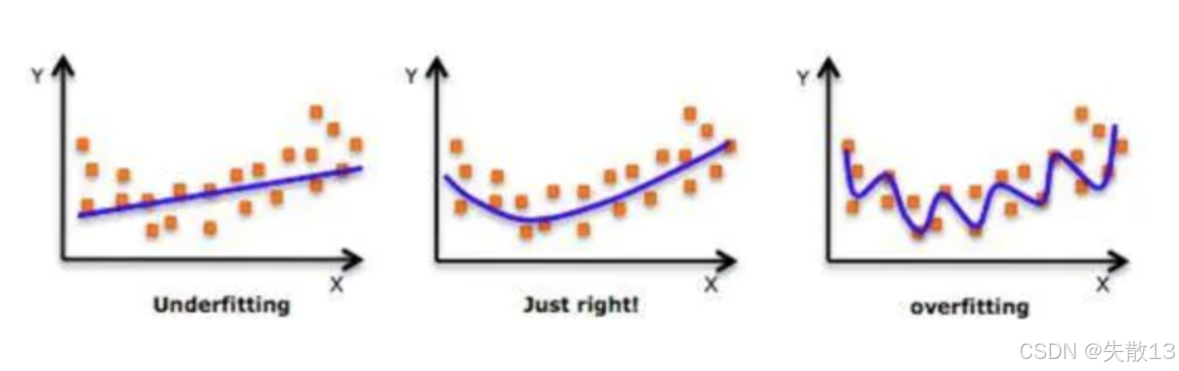
模型拟合的3种状态
-
左边(Underfitting 欠拟合):模型太简单,没抓住数据规律。比如用直线硬套弯曲的数据,预测效果差,训练误差和测试误差都大;
-
中间(Just right 拟合合适):模型复杂度刚好,能捕捉数据趋势,在训练和新数据(测试)上表现都不错,泛化能力强;
-
右边(Overfitting 过拟合):模型太复杂,把训练数据的“噪声”都学进去了(比如个别点的随机波动),看似训练时误差很小,但遇到新数据(测试)就“翻车”,泛化能力差;
-
-
正则化的核心目的:
- “泛化能力”是机器学习的命门——模型不能只在训练数据上表现好,得在没见过的新数据上也准;
- 正则化就是一系列“限制模型过度复杂、避免过拟合”的策略,让模型更“稳健”;
-
**为什么神经网络特别需要正则化?**神经网络(比如深度学习)的结构很灵活(多层、多参数),“表示能力”极强(能学超复杂规律),但也容易因为学太细(连噪声都学)导致过拟合,所以必须用正则化“约束”它,平衡模型复杂度;
-
常见正则化策略
-
范数惩罚(比如L1、L2正则):给模型参数加“惩罚项”,让参数不能太大/太极端,逼着模型简化,避免“死记硬背”训练数据;
-
Dropout:训练时随机“关掉”一部分神经元,让模型不能过度依赖某些参数,相当于强制模型学更通用的规律;
-
特殊网络层(比如Batch Normalization,批量归一化):通过标准化等操作,让每层输入更稳定,间接限制模型复杂度,提升泛化能力。
-
4.2 Dropout正则化
-
Dropout正则化的作用:
- 神经网络参数多、结构深,一旦训练数据不够,特别容易“过拟合”——模型死记硬背训练数据的细节(甚至噪声),但遇到新数据就完蛋;
- Dropout 就是专门“治这个病”的:随机让部分神经元“失效”,逼着模型学更通用的规律,避免过拟合;
-
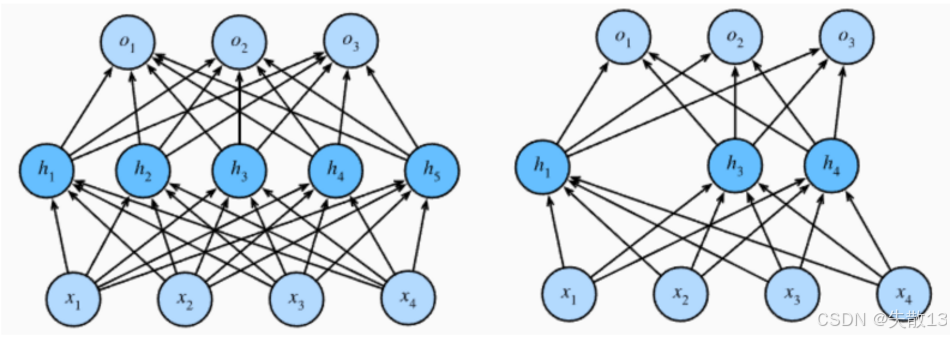
经过Dropout正则化的前后对比:
-
左边:原始神经网络。所有神经元(h1h_1h1到h5h_5h5等)都工作,连接密密麻麻,模型复杂度高,容易过拟合;
-
右边:Dropout 生效后。随机“关掉”了h2h_2h2、h5h_5h5等神经元(比如图里浅色/消失的节点),相当于 临时简化网络结构,每次训练只用“子网络”干活;
-
-
Dropout 的具体操作(训练时)
-
随机失活:训练时,每个神经元有概率ppp(超参数,比如 0.5)被“关掉”(输出置为 0),幸存的神经元要 按1/(1−p)1/(1-p)1/(1−p)缩放(保证整体输出的期望不变);
-
子网络训练:每次训练只用部分神经元(子网络),参数只更新这部分。因为每次“关哪些神经元”是随机的,模型被迫学更通用的特征,没法死记硬背;
-
-
在测试时就不使用 Dropout。原因:
- 测试是为了“稳定预测”,不能再随机关神经元;
- 所以测试时所有神经元都工作,但因为训练时已经通过缩放补偿,直接用完整网络就能输出可靠结果;
-
代码:
import torch import torch.nn as nndef test():# 初始化 Dropout 层,参数 p=0.4 表示每次训练时,有 40% 的神经元会被随机置零# Dropout 是正则化手段,通过随机失活神经元,避免模型过拟合,提升泛化能力dropout = nn.Dropout(p=0.4) # 生成输入数据:# torch.randint(0, 10, size=[1, 4]) 生成一个形状为 [1, 4] 的张量,元素是 0-9 的随机整数# .float() 将整数张量转换为浮点型,因为神经网络计算通常使用浮点数inputs = torch.randint(0, 10, size=[1, 4]).float() # 定义一个线性层(全连接层):输入维度 4,输出维度 5# 线性层会做矩阵运算:y = Wx + b ,其中 W 是权重矩阵(4x5),b 是偏置(长度为5)layer = nn.Linear(4, 5) # 让输入数据通过线性层,得到未经过 Dropout 的输出# 此时输出是线性层对输入的直接变换结果,包含 5 个元素(因输出维度是5)y = layer(inputs) print("未失活FC层的输出结果:\n", y)# 将线性层的输出传入 Dropout 层# 训练模式下(默认),Dropout 会随机把 40% 的输出值置为 0,剩余 60% 的值会按 1/(1-0.4) 缩放(保证期望不变)# 测试/推理时一般会关闭 Dropout(通过 model.eval() 切换模式),避免结果随机波动y = dropout(y) print("失活后FC层的输出结果:\n", y)test()
tensor([[ 0.8366, -0.5336, -2.7561, -1.7934, -2.0321]], grad_fn=<AddmmBackward0>)- 这是全连接层(
nn.Linear)的直接输出,5 个数值对应线性变换(y = Wx + b)的结果; grad_fn=<AddmmBackward0>表示这是由矩阵乘法(全连接层运算)产生的张量,支持自动求导;
- 这是全连接层(
tensor([[ 1.3944, -0.8893, -0.0000, -2.9890, -0.0000]], grad_fn=<MulBackward0>)- Dropout 生效:
- 原始输出中 40% 的元素被置为 0(这里
p=0.4,所以 5 个元素里大约 2 个被置零,对应-0.0000)。 - 未被置零的元素会被缩放:因为
p=0.4,缩放系数是1/(1-0.4) ≈ 1.6667。比如:- 第一个元素
0.8366 × 1.6667 ≈ 1.3944(和输出一致); - 第二个元素
-0.5336 × 1.6667 ≈ -0.8893(和输出一致);
- 第一个元素
- 原始输出中 40% 的元素被置为 0(这里
grad_fn=<MulBackward0>表示这是由 “乘法操作(缩放)” 产生的张量,依然支持自动求导;
- Dropout 生效:
-
从结果能直观看到:
- Dropout 随机让部分输出失效(置零),强制网络不依赖特定神经元;
- 缩放操作保证了 “失活前后的期望一致”(比如原始输出的平均值,和失活后缩放的平均值近似),不破坏数值分布。
4.3 批量归一化(BN层)
-
批量归一化(Batch Normalization,简称 BN 层) 的核心原理,用来解决“内部协变量偏移”问题,让模型训练更稳定、更快;
-
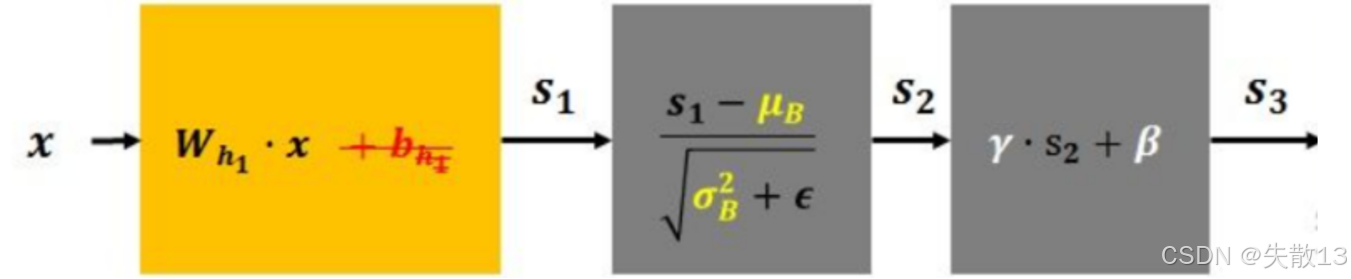
流程:
- 线性变换。输入
x先经过全连接层(或卷积层):s₁ = W·x + b。这一步是神经网络的常规操作,没 BN 时,s₁的分布会因为参数更新不断变化,给训练带来麻烦;
- 线性变换。输入
-
标准化。对
s₁做“标准化”,公式:
s2=s1−μBσB2+ϵs_2=\frac{s_1 - \mu_B}{\sqrt{\sigma_B^2 + \epsilon}}s2=σB2+ϵs1−μB-
μBμ_BμB是 当前 batch 数据的均值,σB2σ_B²σB2是 当前 batch 数据的方差;
-
减均值、除标准差,让
s₂变成 均值为 0、方差为 1 的分布; -
εεε(比如 1e-5)是为了避免分母为 0(数值稳定性);
-
这一步的核心:强行让数据分布更稳定,缓解“随着训练,每层输入分布总变(内部协变量偏移)”的问题,让后续训练更顺畅;
-
重构变换。对标准化后的
s₂做“缩放 + 平移”,公式:
s3=γ⋅s2+β s_3 = γ·s_2 + β s3=γ⋅s2+β- γγγ(缩放系数)和βββ(平移系数)是 可学习的参数(模型自己调);
- 作用:标准化会“抹掉”数据原本的分布特征,这一步让模型有能力恢复对当前任务有用的分布(比如不想让数据严格均值 0、方差 1 时,用γγγ和βββ调整);
-
-
完整公式:
f(x)=λ⋅x−E(x)Var(x)+ϵ+β f(x) = \lambda \cdot \frac{x - \text{E}(x)}{\sqrt{\text{Var}(x)} + \epsilon} + \beta f(x)=λ⋅Var(x)+ϵx−E(x)+β-
E(x)E(x)E(x)就是μBμ_BμB(batch 均值),Var(x)Var(x)Var(x)就是σB2σ_B²σB2(batch 方差);
-
先标准化(减均值除方差),再用γγγ和βββ重构 —— 和图里的三步完全对应;
-
-
BN层的作用:
-
加速训练:数据分布稳定了,模型参数更新更平滑,不用小心翼翼调学习率,收敛更快;
-
缓解过拟合:标准化相当于给数据加了“正则”,让模型没那么容易学死(不过不是主要目的);
-
允许更大学习率:因为分布稳定,学习率可以调大,进一步加速训练;
-
-
应用场景:计算机视觉领域用得多,因为 CV 任务(比如分类、检测)的数据分布容易波动,BN 能很好地稳定训练。
5 案例:价格分类
5.1 需求分析
-
小明创办了一家手机公司,他不知道如何估算手机产品的价格。为了解决这个问题,他收集了多家公司的手机销售数据。该数据为二手手机的各个性能的数据,最后根据这些性能得到4个价格区间,作为这些二手手机售出的价格区间。主要包括:

-
我们需要帮助小明找出手机的功能(例如:RAM等)与其售价之间的某种关系。我们可以使用机器学习的方法来解决这个问题,也可以构建一个全连接的网络;
-
需要注意的是: 在这个问题中,我们不需要预测实际价格,而是一个价格范围,它的范围使用 0、1、2、3 来表示,所以该问题也是一个分类问题。接下来我们按照下面四个步骤来完成这个任务:
- 准备训练集数据
- 构建要使用的模型
- 模型训练
- 模型预测评估
5.2 导包
# 导包
import torch
# TensorDataset 用于将张量数据包装成数据集形式,方便后续数据加载
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
import torch.nn as nn
# optim模块包含了各种优化算法(如SGD、Adam等 ),用于优化神经网络的参数
import torch.optim as optim
# 导入make_regression,用于生成回归问题的数据集
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import time
5.3 构建数据集
-
数据共有 2000 条,将其中的 1600 条数据作为训练集,400 条数据用作测试集;
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 构建数据集 def create_dataset():data = pd.read_csv('data/手机价格预测.csv')# 提取特征数据x:取所有行,除了最后一列的所有列(即所有特征列)x = data.iloc[:, :-1]# 提取目标数据y:取所有行,仅最后一列(即目标变量列,手机价格)y = data.iloc[:, -1]# 将特征数据x的数据类型转换为float32,适应PyTorch模型的数值类型要求x = x.astype(np.float32)# 将目标数据y的数据类型转换为int64(长整型),适用于分类任务的标签类型y = y.astype(np.int64)# 将数据集划分为训练集和测试集(训:测=8:2)x_train, x_valid, y_train, y_valid = train_test_split(x, y, test_size=0.2)# 构建训练数据集:使用TensorDataset将特征和标签的numpy数组转换为PyTorch张量# TensorDataset是PyTorch提供的数据集包装类,可将特征和标签关联起来train_dataset = TensorDataset(torch.from_numpy(x_train.values).to(device), torch.tensor(y_train.values).to(device))# 构建验证数据集:同样使用TensorDataset包装测试集的特征和标签valid_dataset = TensorDataset(torch.from_numpy(x_valid.values).to(device), torch.tensor(y_valid.values).to(device))return train_dataset, valid_dataset, x_train.shape[1], len(np.unique(y))train_dataset, valid_dataset, input_dim, class_num = create_dataset() print("输入特征数:", input_dim) print("分类个数:", class_num)
5.4 构建分类网络模型
-
构建全连接神经网络来进行手机价格分类,该网络由三个线性层来构建,使用 ReLU 激活函数;
-
网络共有 3 个全连接层,具体信息如下:
- 第一层:输入维度为 20,输出维度为 128
- 第二层:输入为维度为 128,输出维度为:256
- 第三层:输入为维度为 256,输出维度为:4
-
构建分类网络模型:
# 构建分类网络模型 class PhonePriceModel(nn.Module):def __init__(self, input_dim, output_dim):super(PhonePriceModel, self).__init__()# 第一层:输入维度为 20,输出维度为 128self.linear1 = nn.Linear(input_dim, 128)# 第二层:输入为维度为 128,输出维度为:256self.linear2 = nn.Linear(128, 256)# 第三层:输入为维度为 256,输出维度为:4self.linear3 = nn.Linear(256, output_dim)def forward(self, x):# 向前传播x = torch.relu(self.linear1(x))x = torch.relu(self.linear2(x))output = self.linear3(x)return output# 模型实例化 model = PhonePriceModel(input_dim, class_num).to(device) summary(model, input_size=(input_dim,), batch_size=16)
5.5 模型训练
-
网络编写完成之后,需要编写训练函数;
-
所谓的训练函数,指的是输入数据读取、送入网络、计算损失、更新参数的流程,该流程较为固定;
-
使用的是多分类交叉生损失函数和 SGD 优化方法;
-
最终,将训练好的模型持久化到磁盘中;
# 模型训练 def train(train_dataset, input_dim, class_num):# 固定随机数种子,确保训练过程可复现(每次初始化的随机参数相同)torch.manual_seed(0)model = PhonePriceModel(input_dim, class_num).to(device)# 定义损失函数,CrossEntropyLoss适用于多分类任务,计算预测概率分布与真实标签的交叉熵criterion = nn.CrossEntropyLoss()# 定义优化方法,使用随机梯度下降(SGD)优化器,学习率设置为1e-3,优化模型的参数optimizer = optim.SGD(model.parameters(), lr=1e-3)# 设置训练轮数,即整个训练数据集会被遍历50次num_epoch = 50# 外层循环:遍历每个训练轮次for epoch_idx in range(num_epoch):# 初始化数据加载器,每次打乱数据(shuffle=True),按批次加载,每批8条数据dataloader = DataLoader(train_dataset, shuffle=True, batch_size=8)# 记录当前轮次训练开始时间start = time.time()# 初始化总损失,用于统计当前轮次所有批次的损失总和total_loss = 0.0# 初始化计数,用于统计批次数量(后续计算平均损失)total_num = 1# 内层循环:遍历每个batch的数据,逐个批次训练模型for x, y in dataloader:# 将 batch 数据送入模型,得到预测输出。模型会根据输入数据,通过前向传播计算输出结果output = model(x)# 计算当前批次的损失:将模型输出与真实标签代入损失函数loss = criterion(output, y)# 梯度清零:防止梯度累积影响下一次反向传播计算,每次更新参数前要清空之前的梯度optimizer.zero_grad()# 反向传播:根据损失值,从输出层往输入层反向计算每个参数的梯度loss.backward()# 参数更新:根据计算好的梯度,使用优化器更新模型的参数(如权重、偏置等)optimizer.step()# 批次计数加1,统计当前轮次处理了多少个批次total_num += 1# 将当前批次的损失值(转为Python原生浮点数)累加到总损失中total_loss += loss.item()# 打印当前轮次的训练信息:轮次编号、平均损失(总损失/批次数量)、训练耗时print('epoch: %4s loss: %.2f, time: %.2fs' % (epoch_idx + 1, total_loss / total_num, time.time() - start))# 模型保存:训练完成后,将模型的参数(state_dict)保存到指定路径,便于后续加载复用torch.save(model.state_dict(), 'model/phone.pth') # 要提前建好 model 文件夹train(train_dataset, input_dim, class_num)
5.6 编写评估函数
-
使用训练好的模型,对未知的样本的进行预测的过程,这里使用前面单独划分出来的验证集来进行评估:
def test(valid_dataset, input_dim, class_num):"""测试函数:使用训练好的模型对验证集数据进行预测,计算预测精度:param valid_dataset: 验证集数据集(TensorDataset格式,包含特征和标签):param input_dim: 输入特征维度:param class_num: 分类类别数量"""# 加载模型和训练好的网络参数# 1. 初始化模型实例,传入输入维度和分类数量model = PhonePriceModel(input_dim, class_num).to(device)# 2. 加载预训练好的模型参数(注意路径要和训练时保存的一致# 会把训练好的权重、偏置等参数加载到模型中,让模型具备预测能力model.load_state_dict(torch.load('model/phone.pth'))# 构建加载器# 按批次加载验证集数据,每批8条,测试阶段不需要打乱数据(shuffle=False)dataLoader = DataLoader(valid_dataset, batch_size=8, shuffle=False)# 评估测试集# 初始化正确预测的样本数量correct = 0 # 遍历测试集中的每个批次数据for x, y in dataLoader: # 将特征数据送入模型,执行前向传播,得到输出(模型对当前批次的预测结果,形状一般是[batch_size, class_num] )output = model(x)# 获取类别结果:对输出结果在维度1(dim=1,即类别维度)上取最大值的索引,索引对应类别y_pred = torch.argmax(output, dim=1)# 统计当前批次中预测正确的样本数量:比较预测类别和真实类别,相同则为1,求和得到当前批次正确数,累加到totalcorrect += (y_pred == y).sum()# 求预测精度并打印# 精度 = 正确预测数 / 验证集总样本数 ,item()将张量转为Python数值,按5位小数格式输出print(f'Acc: {correct.item() / len(valid_dataset):.5f}')test(valid_dataset, input_dim, class_num)





---自动识别设备,并导出配置)
初阶绘图)
:I2C 总线数据传输方向如何确定、信号线上的串联电阻有什么作用?)



![[系统架构设计师]架构设计专业知识(二)](http://pic.xiahunao.cn/[系统架构设计师]架构设计专业知识(二))




:布局的实现——LayoutGroup的算法与实践)

六种方法对数据的填充)
