引言:为什么需要限流?
在现代分布式系统中,服务的稳定性是至关重要的。在遇到突发的请求量激增,恶意的用户访问,亦或是请求频率过高给下游服务带来较大压力时,我们常常需要通过缓存、限流、熔断降级、负载均衡等多种方式保证服务的稳定性。其中限流是不可或缺的一环,这篇文章介绍限流相关知识。
限流(Rate Limiting) 正是为了解决这一问题而生的关键技术。它通过控制请求的速率,将流量限制在系统所能处理的合理范围内,从而:
保障服务可用性:防止系统被过量请求拖垮。
实现公平使用:保护资源不被少数用户或恶意请求独占。
应对突发流量:通过平滑处理请求,避免后端服务被冲垮。
四种常见的限流算法
| 限流方式 | 核心原理 | 实现复杂度 |
|---|---|---|
| 固定窗口限流算法 | 将时间划分为固定窗口(如 1 秒),统计窗口内请求数,超过阈值则限流 | 低 |
| 滑动窗口限流算法 | 将固定窗口划分为多个小时间片,随时间滑动计算窗口内请求数 | 中 |
| 漏桶算法 | 请求像水一样进入固定容量的桶,桶以固定速率出水,溢出则限流 | 中 |
| 令牌桶算法 | 系统以固定速率向桶中放令牌,请求需获取令牌才能通过,桶可累积令牌 | 中 |
1.固定窗口限流算法
1.1 什么是固定窗口算法
固定窗口算法又叫计数器算法,是一种简单方便的限流算法。他的原理是:维护一个计数器,将固定单位时间段当作一个窗口,计数器会记录这个窗口接收请求的次数。
当一个新的请求到达时,系统会检查当前窗口内的计数器值。
1.如果计数器未达到预设的阈值,允许请求访问,计数器自增。
2.当计数器已达到或大于限流阈值,拒绝该请求,触发限流规则。
3.直到进入下一个时间窗口,此时计数器会被重置为零,重新开始计数
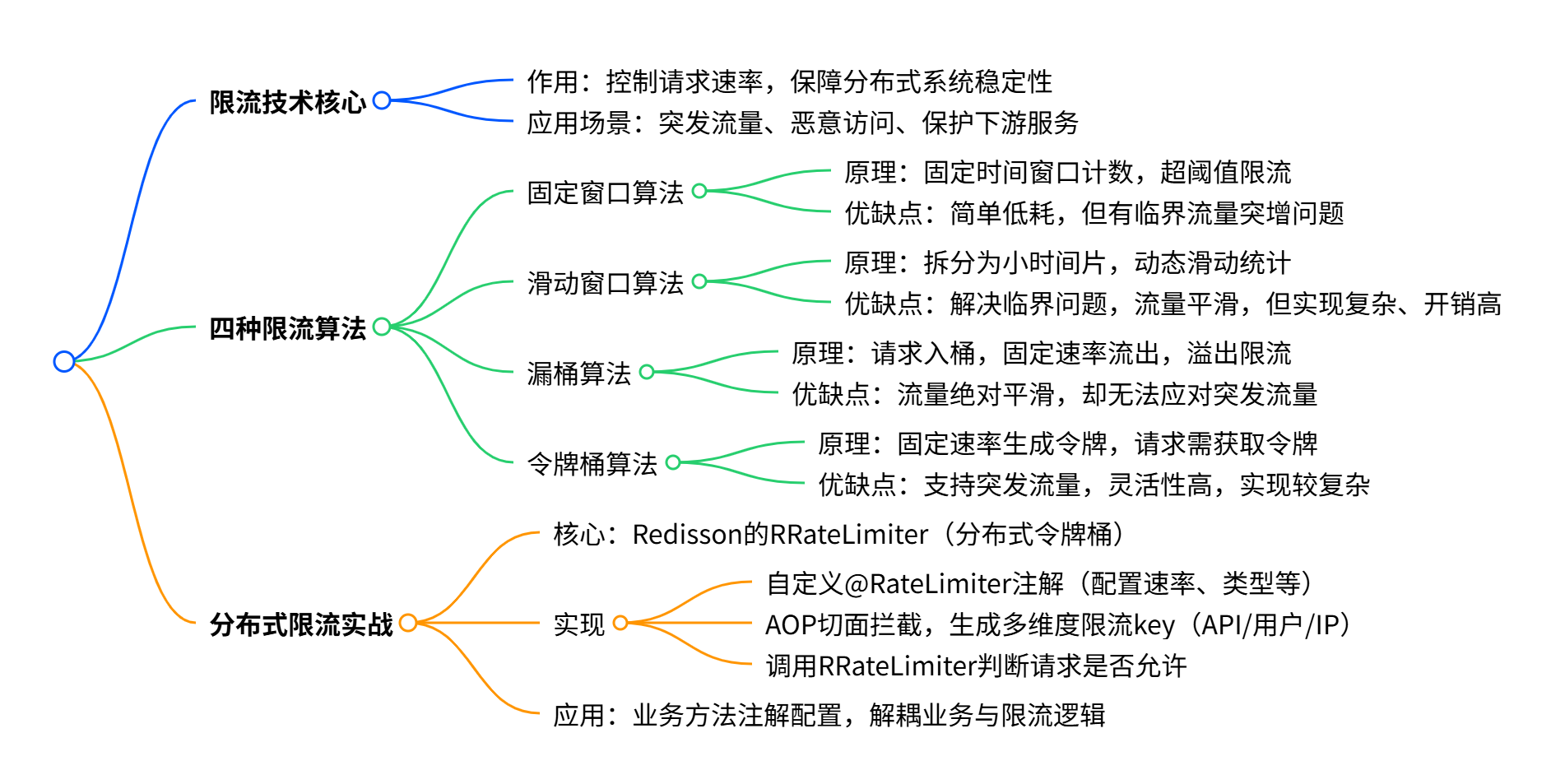
假设单位时间是60秒,限流阀值为10。在单位时间60秒内,每来一个请求,计数器就加1,如果计数器累加的次数超过限流阀值10,后续的请求全部会被拒绝。直到进入下一个时间窗口,此时计数器会被重置为零,重新开始计数。
1.2 伪代码实现
public static Integer counter = 0; //统计请求数public static long lastAcquireTime = 0L;public static final Long windowUnit = 1000L ; //假设固定时间窗口是1000mspublic static final Integer threshold = 10; // 窗口阀值是10public synchronized boolean fixedWindowsTryAcquire() {long currentTime = System.currentTimeMillis(); //获取系统当前时间if (currentTime - lastAcquireTime > windowUnit) { //检查是否在时间窗口内counter = 0; // 计数器清0lastAcquireTime = currentTime; //开启新的时间窗口}if (counter < threshold) { // 小于阀值counter++; //计数统计器加1return true;}return false;}1.2 固定窗口算法的优缺点
优点:实现简单,资源消耗低
缺点:存在临界问题,可能在窗口切换时出现双倍流量峰值。
举例:窗口大小为 1 秒,阈值为 10 次请求。第 1 个窗口的最后 100ms 内涌入 10 次请求(未超限)。第 2 个窗口的前 100ms 内又涌入 10 次请求(未超限)。实际 200ms 内总请求数达到 20 次,远超 “1 秒 10 次” 的限制,可能瞬间压垮系统。
2. 滑动窗口限流算法
2.1 什么是滑动窗口限流算法
滑动窗口算法可以看作是固定窗口算法的一种改进和优化。它不再将时间划分为离散的、独立的窗口,而是将时间视为一个连续的整体。它将单位时间周期分为n个小周期,分别记录每个小周期内接口的访问次数,并且根据时间滑动删除过期的小周期。
2.2 滑动窗口解决边界问题
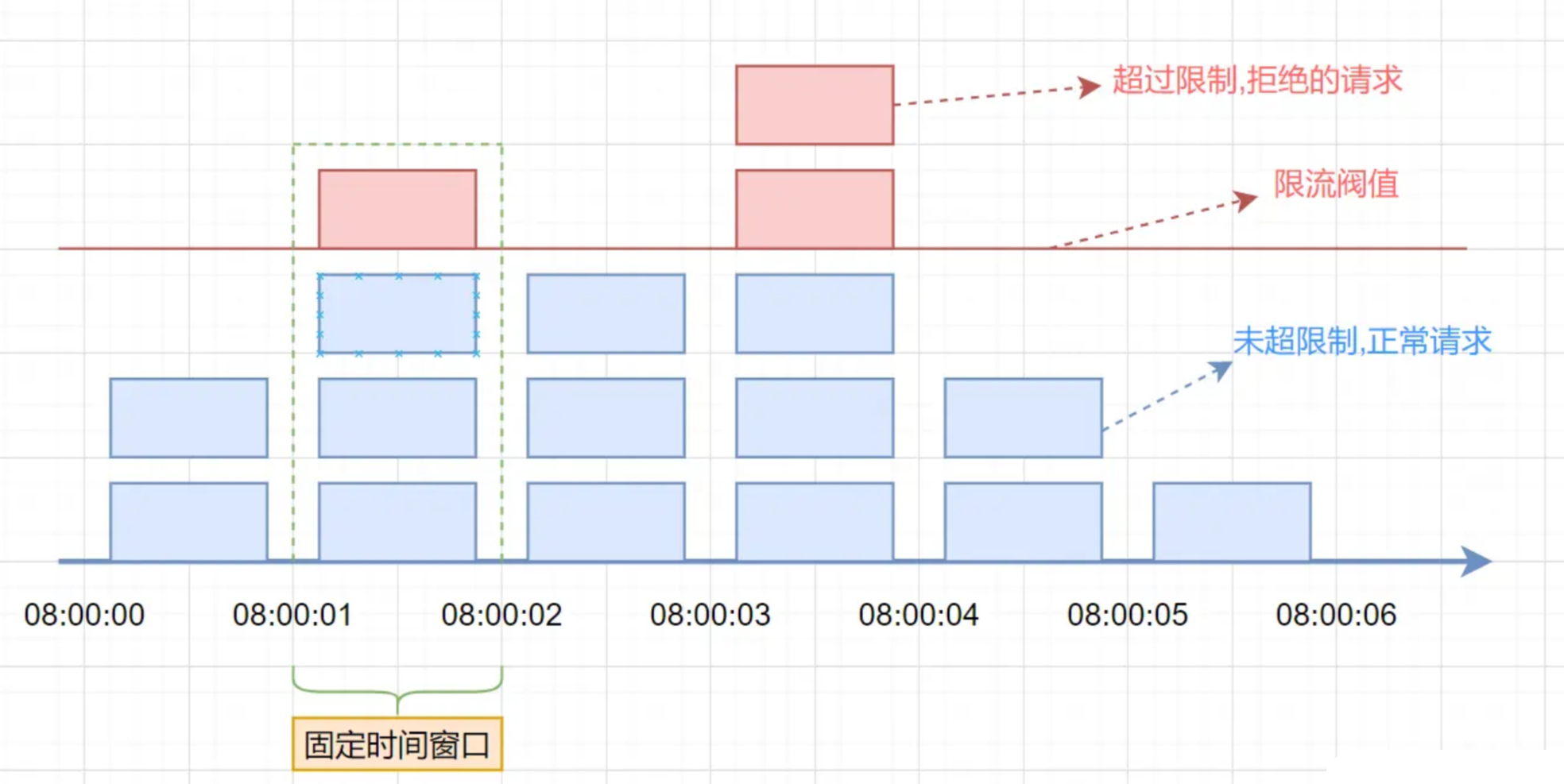
如图:在 0.8-1.0 秒来了 5 个请求后,1.0-1.2 秒再发 5 个请求,固定窗口会认为是两个窗口而全部允许,滑动窗口则因这 10 个请求都在 0.2-1.2 秒的滑动区间内而限流后 5 个,解决了边界流量突增问题。
| 场景 | 固定窗口处理逻辑 | 滑动窗口处理逻辑 |
|---|---|---|
| 边界点前后请求 | 分属两个窗口,分别计数 | 同属 “最近 1 秒” 窗口,合并计数 |
| 1000~1200ms 请求数 | 允许 5 个(总 10 个) | 全部限流(总请求数超 5) |
| 核心原因 | 窗口固定,边界点前后割裂 | 窗口动态滑动,覆盖边界点前后区间 |
2.3 伪代码实现
public class SimpleSlidingWindow {// 窗口配置private static final long WINDOW_MS = 1000; // 总窗口1秒private static final int SUB_WINDOWS = 5; // 5个小窗口private static final long SUB_WINDOW_MS = WINDOW_MS / SUB_WINDOWS; // 每个200msprivate static final int THRESHOLD = 5; // 限流阈值// 存储每个小窗口的请求数private final int[] counts = new int[SUB_WINDOWS];private int totalRequests; // 当前窗口总请求数private final Lock lock = new ReentrantLock();public boolean tryAcquire() {long now = System.currentTimeMillis();lock.lock();try {// 1. 计算当前小窗口索引int currentIdx = (int) (now / SUB_WINDOW_MS % SUB_WINDOWS);// 2. 清理过期的小窗口long windowStart = now - WINDOW_MS;for (int i = 0; i < SUB_WINDOWS; i++) {long subWindowStart = (i * SUB_WINDOW_MS);if (subWindowStart < windowStart) {totalRequests -= counts[i];counts[i] = 0;}}// 3. 判断是否超过阈值if (totalRequests >= THRESHOLD) {return false;}// 4. 记录当前请求counts[currentIdx]++;totalRequests++;return true;} finally {lock.unlock();}}2.4 滑动窗口算法的优缺点
优点:能平滑流量,解决固定窗口临界问题,避免窗口切换时流量翻倍。
缺点:实现复杂度高,需维护动态数据结构,增加内存和计算开销。
3. 漏桶限流算法
3.1 什么是漏桶限流算法
漏桶限流算法的核心思想是将请求视为水滴,进入一个固定容量的桶(队列)中。桶的底部有一个小孔,水会以一个恒定的速率从桶中流出,这个速率代表了系统能够稳定处理请求的速率。当请求(水滴)的流入速率小于或等于桶的流出速率时,请求可以被及时处理,不会发生积压。
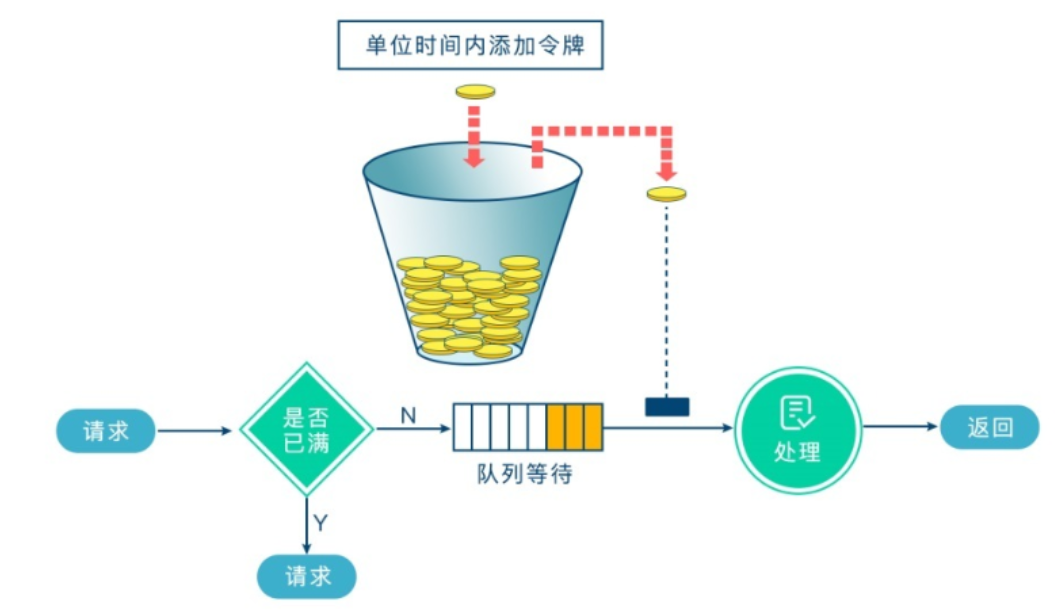
当请求的流入速率小于或等于桶的流出速率时,请求可以被及时处理,不会发生积压。
当请求的流入速率超过流出速率时,桶中的水会逐渐增多,桶中的未处理请求会增加。
如果桶被装满,那么后续新进入的请求就会被直接丢弃或拒绝,直到桶中有足够的空间为止。
3.2 伪代码实现
public class LeakyBucketRateLimiter {private final long capacity; // 桶的容量private long water; // 当前桶中的水量(请求数)private final long rate; // 漏出速率 (请求/秒)private long lastLeakTimestamp; // 上次漏水时间戳public LeakyBucketRateLimiter(long capacity, long rate) {this.capacity = capacity;this.rate = rate;this.water = 0;this.lastLeakTimestamp = System.currentTimeMillis();}public synchronized boolean tryAcquire() {long now = System.currentTimeMillis();// 计算这段时间内应该漏掉的水量long leakedWater = (now - lastLeakTimestamp) * rate / 1000;// 更新桶中的水量,但不能小于0water = Math.max(0, water - leakedWater);lastLeakTimestamp = now;// 判断桶是否还有空间if (water < capacity) {water++; // 新请求加入桶中return true; // 请求被接受} else {return false; // 桶满了,拒绝请求}}
}3.3 漏桶算法的优缺点
优点:漏桶算法最突出的优点是能提供绝对平滑、恒定的请求处理速率(水流稳定输出)
缺点:无法应对突发流量,即便系统有空闲资源,超出自设流出速率的请求也会被拒;当请求速率持续高于流出速率时,桶会快速填满,导致后续请求被阻或拒,增加平均延迟甚至超时。
4. 令牌桶限流算法(非常推荐)
4.1 什么是令牌桶限流算法
令牌桶算法的核心思想是,系统会以一个恒定的速率向一个固定容量的桶中放入令牌。每个请求在到达时,都需要先从桶中获取一个令牌。如果桶中有可用的令牌,请求就可以立即被处理,并消耗掉一个令牌。如果桶中没有令牌了,那么请求就会被拒绝或阻塞,直到有新的令牌被放入桶中。
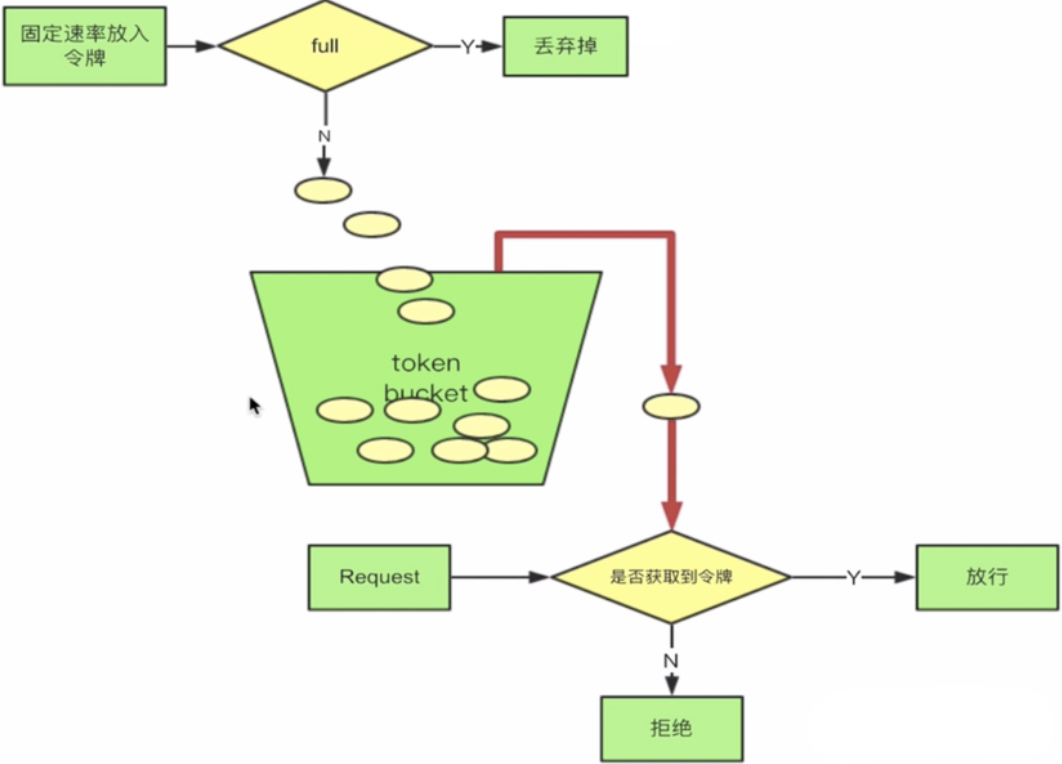
解决突发流量问题:令牌桶在应对突发流量的时候,桶内假如有 10 个令牌,那么这 10 个令牌可以马上被取走,而不像漏桶那样匀速的消费。所以在应对突发流量的时候令牌桶表现的更佳。
4.2 伪代码实现
public class TokenBucket {private final double capacity; // 令牌桶容量private final double rate; // 令牌生成速率 (令牌/毫秒)private double tokens; // 当前桶中的令牌数private long lastRefillTimestamp; // 上次填充令牌的时间戳public TokenBucket(double capacity, double rate) {this.capacity = capacity;this.rate = rate;this.tokens = capacity; // 初始时桶是满的this.lastRefillTimestamp = System.currentTimeMillis();}public synchronized boolean acquire(int numTokens) {long now = System.currentTimeMillis();// 计算这段时间内应该生成的令牌数double newTokens = (now - lastRefillTimestamp) * rate;// 更新桶中的令牌数,但不能超过容量tokens = Math.min(capacity, tokens + newTokens);lastRefillTimestamp = now;// 判断桶中是否有足够的令牌if (tokens >= numTokens) {tokens -= numTokens; // 消耗令牌return true; // 请求被允许} else {return false; // 令牌不足,请求被拒绝}}
}在这个实现中,
tryAcquire()方法首先根据时间差计算出应该“漏掉”的请求数量,并更新桶中的当前水量。然后,它检查桶是否已满。如果未满,则将新请求加入桶中(water++),并返回true;否则,返回false,表示请求被拒绝。这种实现方式确保了请求的处理速率被严格限制在rate所定义的范围内,从而实现了流量的平滑输出。
4.3 漏桶算法的优缺点
优点:支持突发流量,低负载时积累的令牌可应对突发请求,适用于秒杀、突发热点等场景;灵活性高,可通过调整令牌生成速率和桶容量平衡系统稳定性与资源利用率。
缺点:实现较复杂,需精确处理令牌生成与消费及并发一致性。(复杂度较高)
5. 基于Redisson的令牌桶限流实战

RRateLimiter+AOP:基于令牌桶算法的分布式限流器RRateLimiter,结合Spring框架的AOP(面向切面编程)技术,将限流逻辑应用到业务代码中,实现注解式的分布式限流。
5.1 自定义限流注解@RateLimiter
首先,我们需要定义一个自定义注解@RateLimiter,用于标记需要进行限流的方法。这个注解可以包含一些配置属性,如限流的key、限流速率、时间单位、限流类型(按IP、按用户ID等)以及被限流时的提示信息等
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface RateLimiter {// 限流key的前缀String key() default "";// 限流速率(单位时间内允许的请求数)int count() default 10;// 限流时间单位(秒)int time() default 60;// 限流类型(IP、用户等)LimitType limitType() default LimitType.USER;// 被限流时的提示信息String message() default "请求频繁,请稍后重试";
}enum LimitType {IP,USER,API
}5.2 定义限流切面RateLimiterAspect
接下来,我们需要定义一个AOP切面 RateLimiterAspect ,它负责拦截所有带有 @RateLimiter 注解的方法,并在方法执行前执行限流逻辑。这个切面会解析注解中的配置,生成唯一的限流key,然后调用Redisson的RRateLimiter来判断当前请求是否应该被允许。
@Aspect
@Component
@Slf4j
public class RateLimitAspect {@Resourceprivate RedissonClient redissonClient;@Resourceprivate UserService userService;@Before("@annotation(rateLimit)")public void doBefore(JoinPoint point, RateLimit rateLimit) {String key = generateRateLimitKey(point, rateLimit);// 使用Redisson的分布式限流器RRateLimiter rateLimiter = redissonClient.getRateLimiter(key);rateLimiter.expire(Duration.ofHours(1)); // 1 小时后过期// 设置限流器参数:每个时间窗口允许的请求数和时间窗口rateLimiter.trySetRate(RateType.OVERALL, rateLimit.rate(), rateLimit.rateInterval(), RateIntervalUnit.SECONDS);// 尝试获取令牌,如果获取失败则限流if (!rateLimiter.tryAcquire(1)) {throw new BusinessException(ErrorCode.TOO_MANY_REQUEST, rateLimit.message());}}private String generateRateLimitKey(JoinPoint point, RateLimit rateLimit) {StringBuilder keyBuilder = new StringBuilder();keyBuilder.append("rate_limit:");// 添加自定义前缀if (!rateLimit.key().isEmpty()) {keyBuilder.append(rateLimit.key()).append(":");}// 根据限流类型生成不同的keyswitch (rateLimit.limitType()) {case API:// 接口级别:方法名MethodSignature signature = (MethodSignature) point.getSignature();Method method = signature.getMethod();keyBuilder.append("api:").append(method.getDeclaringClass().getSimpleName()).append(".").append(method.getName());break;case USER:// 用户级别:用户IDtry {ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();if (attributes != null) {HttpServletRequest request = attributes.getRequest();User loginUser = userService.getLoginUser(request);keyBuilder.append("user:").append(loginUser.getId());} else {// 无法获取请求上下文,使用IP限流keyBuilder.append("ip:").append(getClientIP());}} catch (BusinessException e) {// 未登录用户使用IP限流keyBuilder.append("ip:").append(getClientIP());}break;case IP:// IP级别:客户端IPkeyBuilder.append("ip:").append(getClientIP());break;default:throw new BusinessException(ErrorCode.SYSTEM_ERROR, "不支持的限流类型");}return keyBuilder.toString();}private String getClientIP() {ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();if (attributes == null) {return "unknown";}HttpServletRequest request = attributes.getRequest();String ip = request.getHeader("X-Forwarded-For");if (ip == null || ip.isEmpty() || "unknown".equalsIgnoreCase(ip)) {ip = request.getHeader("X-Real-IP");}if (ip == null || ip.isEmpty() || "unknown".equalsIgnoreCase(ip)) {ip = request.getRemoteAddr();}// 处理多级代理的情况if (ip != null && ip.contains(",")) {ip = ip.split(",")[0].trim();}return ip != null ? ip : "unknown";}}3.2.3 在业务方法上应用限流注解
只需在需要进行限流控制的方法上添加@RateLimiter注解,配置实际要求即可。
//@GetMapping(value = "/chat/gen/code", produces = MediaType.TEXT_EVENT_STREAM_VALUE)//用户限制 单个窗口请求数量 窗口时长 响应的消息
@RateLimit(limitType = RateLimitType.USER, rate = 5, rateInterval = 60, message = "AI 对话请求过于频繁,请稍后再试")
public Flux<ServerSentEvent<String>> chatToGenCode(@RequestParam Long appId,@RequestParam String message,HttpServletRequest request) {}在这个例子中,/chat/gen/code接口被配置为单个用户每分钟最多只能处理5个请求。任何超出这个频率的请求都会被AOP切面拦截并拒绝。这种方式将限流逻辑与业务逻辑完全解耦,使得代码更加清晰、易于维护。

)
 一)








初步)
)






:如何通过Federated实现跨实例访问表)