背景意义
骨折作为一种常见的骨骼损伤,其诊断和治疗对患者的康复至关重要。传统的骨折检测方法主要依赖于医生的经验和影像学检查,如X光、CT等,这不仅耗时,而且容易受到主观因素的影响。随着计算机视觉和深度学习技术的迅猛发展,基于人工智能的自动化骨折检测系统逐渐成为研究热点。特别是YOLO(You Only Look Once)系列模型因其高效的实时检测能力,已被广泛应用于各类物体检测任务中。
本研究旨在基于改进的YOLOv11模型,构建一个高效的骨折检测系统。我们采用了一个包含4000张图像的数据集,专注于骨骼类别的检测。该数据集经过精心标注,确保了模型训练的准确性和有效性。通过对YOLOv11模型的改进,我们希望在检测精度和速度上实现显著提升,以满足临床应用的需求。
在骨折检测领域,准确的早期诊断可以显著提高治疗效果,减少并发症的发生。我们的研究不仅有助于提高骨折检测的自动化水平,还能为医生提供辅助决策支持,减轻其工作负担。此外,基于深度学习的骨折检测系统能够通过不断学习和优化,适应不同类型的骨折情况,从而在实际应用中展现出更强的灵活性和适应性。
总之,基于改进YOLOv11的骨折检测系统的研究,不仅具有重要的学术价值,也对临床医学实践具有深远的影响。通过提高骨折检测的效率和准确性,我们期望为患者提供更优质的医疗服务,推动骨科领域的技术进步。
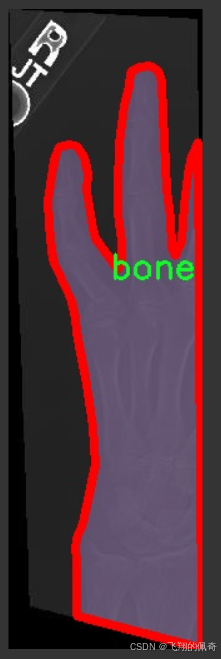
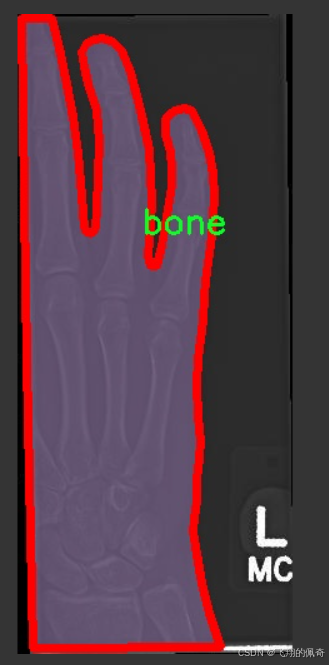
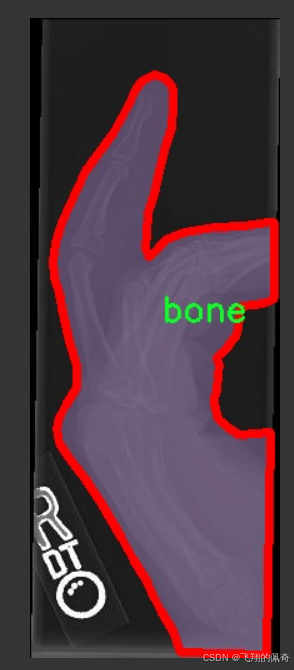
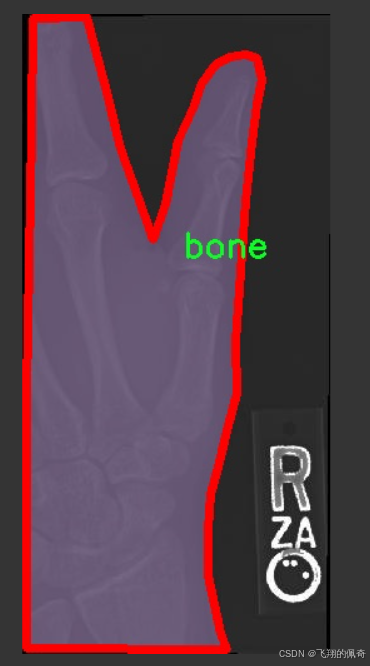
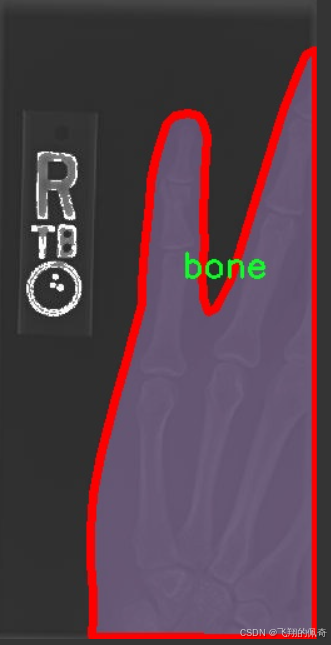
图片效果
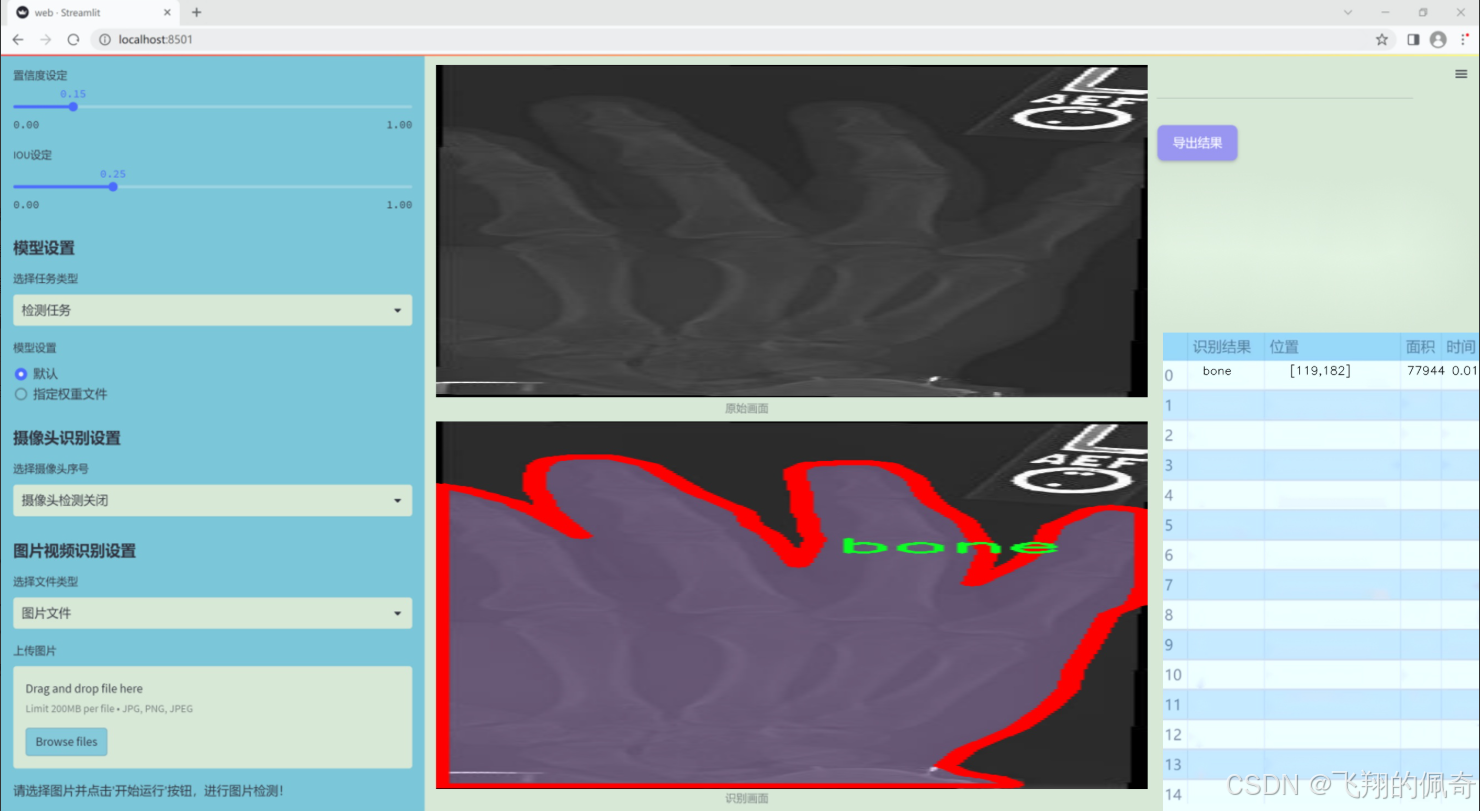
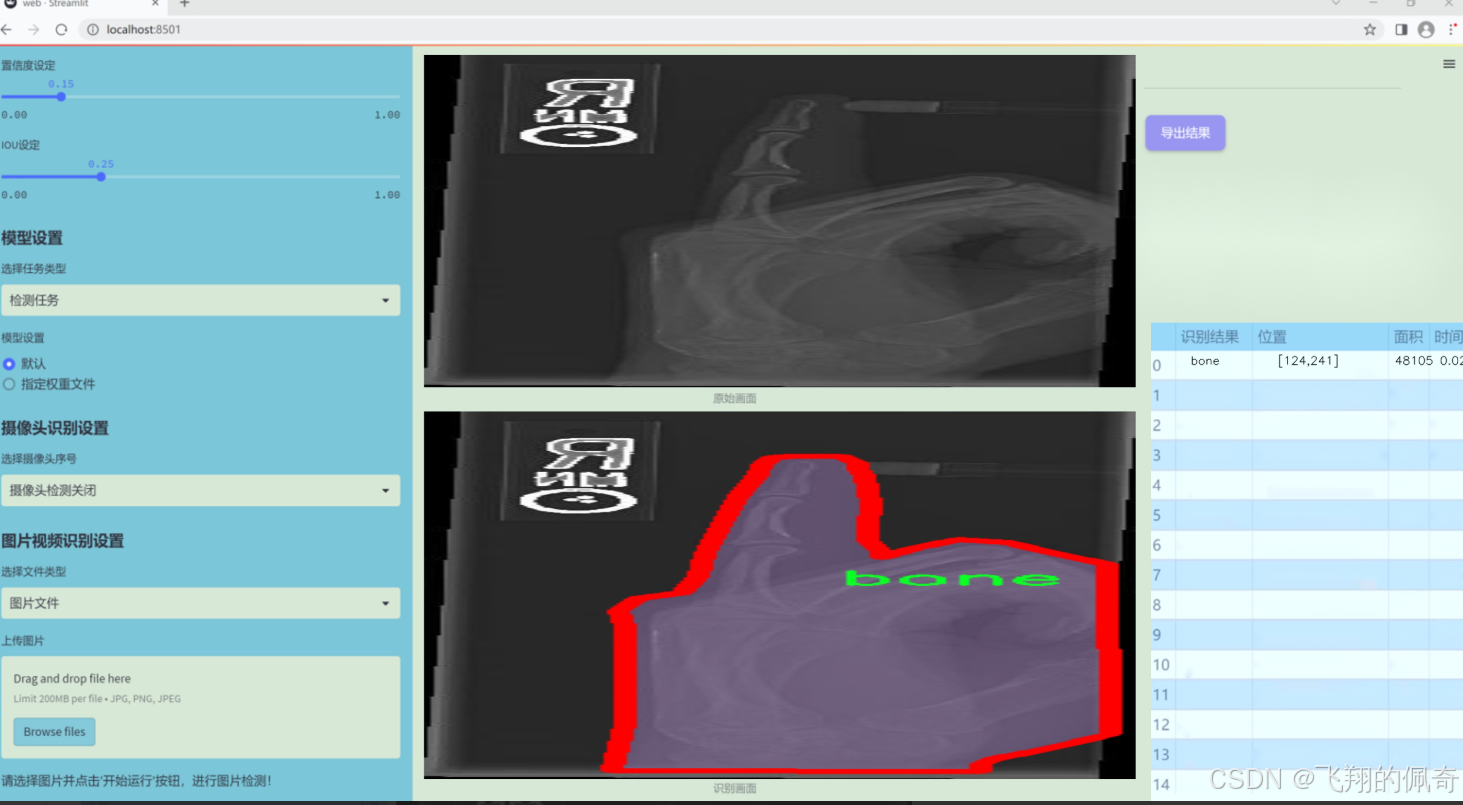
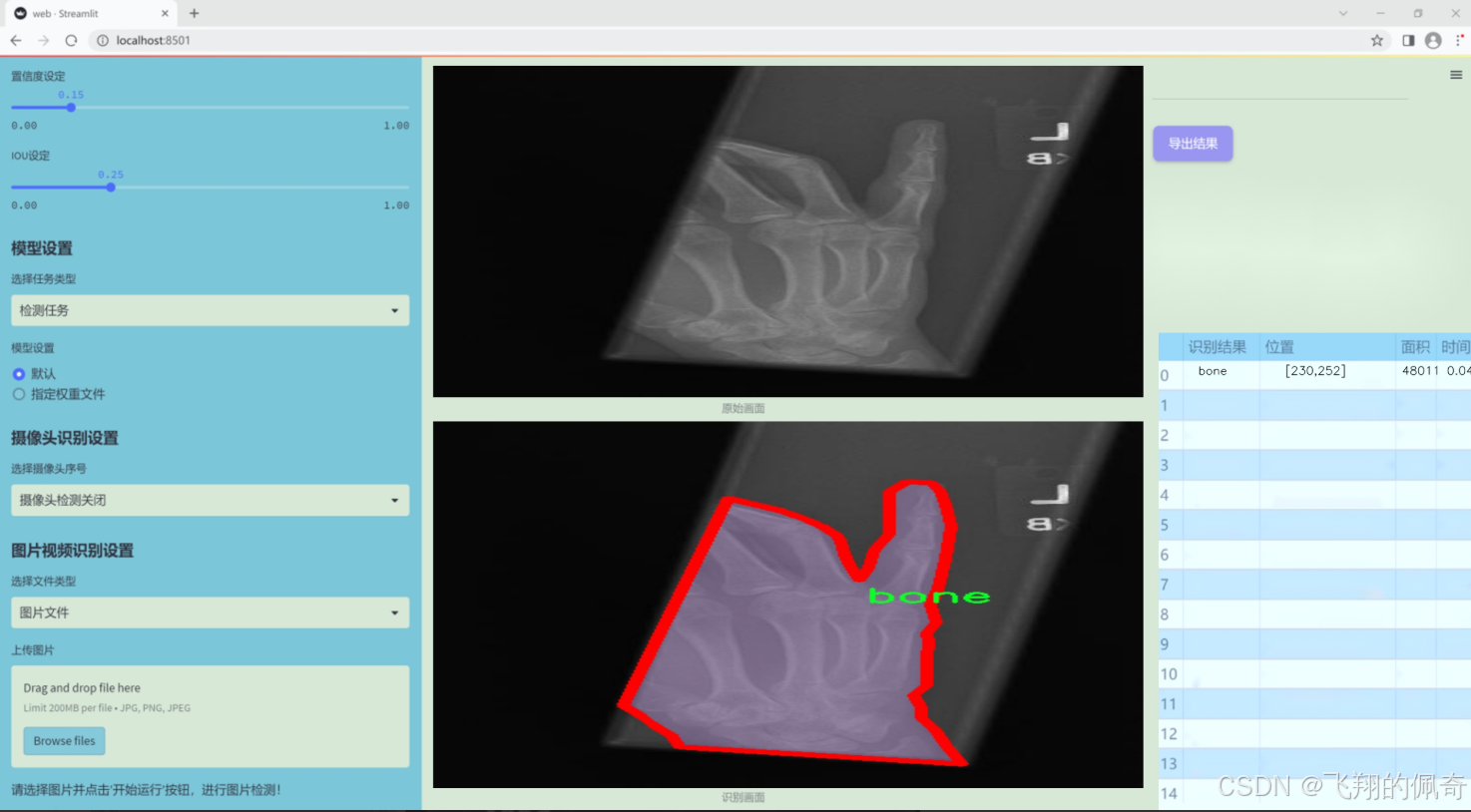
数据集信息
本项目数据集信息介绍
本项目旨在开发和改进基于YOLOv11的骨折检测系统,为此我们构建了一个专门的数据集,以支持深度学习模型的训练和评估。该数据集的核心主题为“Convert COCO JSON to Yolov7 TXT”,通过这一过程,我们将COCO格式的数据转换为YOLO所需的TXT格式,以便于更高效地进行模型训练和推理。数据集中包含的类别数量为1,具体类别为“bone”,这表明我们的模型专注于识别和检测骨折相关的图像信息。
在数据集的构建过程中,我们精心挑选了大量的医学影像数据,包括X光片、CT扫描图像等,这些图像均标注了骨折的具体位置和类型。通过对这些数据的标注,我们确保了模型能够学习到骨折的特征,从而在实际应用中实现高效、准确的检测。为了提高模型的泛化能力,我们的数据集涵盖了不同类型的骨折,包括但不限于横断骨折、斜骨折和粉碎骨折等。这种多样性使得模型在面对不同病例时,能够更好地适应和识别。
此外,为了增强数据集的鲁棒性,我们还进行了数据增强处理,包括旋转、缩放、翻转等操作。这些处理不仅丰富了数据集的多样性,还有效提升了模型在真实场景中的表现。通过对数据集的不断优化和扩充,我们期望最终构建出一个能够在临床环境中提供高效、准确骨折检测的系统,为医疗工作者提供有力的支持,提升骨折诊断的效率和准确性。
核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Function
import pywt
创建小波滤波器
def create_wavelet_filter(wave, in_size, out_size, type=torch.float):
# 使用pywt库创建小波对象
w = pywt.Wavelet(wave)
# 获取小波的分解高通和低通滤波器,并反转
dec_hi = torch.tensor(w.dec_hi[::-1], dtype=type)
dec_lo = torch.tensor(w.dec_lo[::-1], dtype=type)
# 创建分解滤波器
dec_filters = torch.stack([dec_lo.unsqueeze(0) * dec_lo.unsqueeze(1),dec_lo.unsqueeze(0) * dec_hi.unsqueeze(1),dec_hi.unsqueeze(0) * dec_lo.unsqueeze(1),dec_hi.unsqueeze(0) * dec_hi.unsqueeze(1)
], dim=0)# 扩展滤波器以适应输入通道数
dec_filters = dec_filters[:, None].repeat(in_size, 1, 1, 1)# 获取重构高通和低通滤波器,并反转
rec_hi = torch.tensor(w.rec_hi[::-1], dtype=type).flip(dims=[0])
rec_lo = torch.tensor(w.rec_lo[::-1], dtype=type).flip(dims=[0])# 创建重构滤波器
rec_filters = torch.stack([rec_lo.unsqueeze(0) * rec_lo.unsqueeze(1),rec_lo.unsqueeze(0) * rec_hi.unsqueeze(1),rec_hi.unsqueeze(0) * rec_lo.unsqueeze(1),rec_hi.unsqueeze(0) * rec_hi.unsqueeze(1)
], dim=0)# 扩展滤波器以适应输出通道数
rec_filters = rec_filters[:, None].repeat(out_size, 1, 1, 1)return dec_filters, rec_filters
小波变换函数
def wavelet_transform(x, filters):
b, c, h, w = x.shape # 获取输入的形状
pad = (filters.shape[2] // 2 - 1, filters.shape[3] // 2 - 1) # 计算填充
# 进行2D卷积操作,进行小波变换
x = F.conv2d(x, filters.to(x.dtype).to(x.device), stride=2, groups=c, padding=pad)
x = x.reshape(b, c, 4, h // 2, w // 2) # 重新调整形状
return x
逆小波变换函数
def inverse_wavelet_transform(x, filters):
b, c, _, h_half, w_half = x.shape # 获取输入的形状
pad = (filters.shape[2] // 2 - 1, filters.shape[3] // 2 - 1) # 计算填充
x = x.reshape(b, c * 4, h_half, w_half) # 重新调整形状
# 进行转置卷积操作,进行逆小波变换
x = F.conv_transpose2d(x, filters.to(x.dtype).to(x.device), stride=2, groups=c, padding=pad)
return x
定义小波变换的类
class WaveletTransform(Function):
@staticmethod
def forward(ctx, input, filters):
ctx.filters = filters # 保存滤波器
with torch.no_grad():
x = wavelet_transform(input, filters) # 进行小波变换
return x
@staticmethod
def backward(ctx, grad_output):grad = inverse_wavelet_transform(grad_output, ctx.filters) # 计算梯度return grad, None
定义卷积层类
class WTConv2d(nn.Module):
def init(self, in_channels, out_channels, kernel_size=5, stride=1, bias=True, wt_levels=1, wt_type=‘db1’):
super(WTConv2d, self).init()
assert in_channels == out_channels # 输入通道数和输出通道数必须相等self.in_channels = in_channelsself.wt_levels = wt_levelsself.stride = stride# 创建小波滤波器self.wt_filter, self.iwt_filter = create_wavelet_filter(wt_type, in_channels, in_channels, torch.float)self.wt_filter = nn.Parameter(self.wt_filter, requires_grad=False) # 不需要训练的小波滤波器self.iwt_filter = nn.Parameter(self.iwt_filter, requires_grad=False) # 不需要训练的逆小波滤波器# 基础卷积层self.base_conv = nn.Conv2d(in_channels, in_channels, kernel_size, padding='same', stride=1, groups=in_channels, bias=bias)def forward(self, x):# 进行小波变换和逆小波变换的前向传播# 省略具体实现细节return x # 返回输出
代码核心部分解释:
创建小波滤波器:create_wavelet_filter 函数用于生成小波变换和逆变换所需的滤波器。
小波变换和逆变换:wavelet_transform 和 inverse_wavelet_transform 函数实现了小波变换和逆变换的核心操作。
小波变换类:WaveletTransform 类定义了小波变换的前向和反向传播方法。
卷积层:WTConv2d 类是一个自定义的卷积层,结合了小波变换的特性,能够在卷积操作中使用小波变换。
这个程序文件 wtconv2d.py 实现了一个基于小波变换的二维卷积层,名为 WTConv2d。该文件主要使用 PyTorch 框架,结合小波变换来处理输入数据,提供了一种新的卷积操作方式。
首先,文件导入了必要的库,包括 PyTorch 的核心库、神经网络模块、功能模块以及小波变换库 pywt。接着,定义了一个函数 create_wavelet_filter,该函数用于创建小波变换的滤波器。它接受小波类型、输入通道数和输出通道数作为参数,并生成相应的滤波器。滤波器分为降采样和重构两种,分别用于小波变换和逆小波变换。
接下来,定义了两个函数 wavelet_transform 和 inverse_wavelet_transform,分别用于执行小波变换和逆小波变换。这两个函数使用了 PyTorch 的卷积操作,处理输入张量并返回变换后的结果。
随后,定义了两个类 WaveletTransform 和 InverseWaveletTransform,这两个类继承自 Function,实现了小波变换和逆小波变换的前向和反向传播。它们的 forward 方法调用了之前定义的变换函数,而 backward 方法则计算梯度。
在 WTConv2d 类中,构造函数初始化了输入和输出通道数、小波变换的层数、步幅等参数。通过调用 create_wavelet_filter 函数生成小波滤波器,并将其转化为不可训练的参数。接着,初始化了小波变换和逆小波变换的函数,并创建了基础卷积层和一系列小波卷积层。
在 forward 方法中,首先对输入数据进行小波变换,分离出低频和高频成分。然后,依次通过每一层的小波卷积处理这些成分,并在最后进行逆小波变换,重构出输出数据。最后,基础卷积层的输出与小波卷积的输出相加,得到最终结果。
此外,文件中还定义了一个 _ScaleModule 类,用于对输入进行缩放操作,确保输出的数值范围适合后续处理。
总体来说,这个程序文件实现了一个结合小波变换的卷积神经网络层,能够在卷积操作中引入频域信息,从而可能提高模型对特征的提取能力。
10.4 VanillaNet.py
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.layers import weight_init
定义激活函数类,继承自ReLU
class activation(nn.ReLU):
def init(self, dim, act_num=3, deploy=False):
super(activation, self).init()
self.deploy = deploy # 是否处于部署模式
# 初始化权重和偏置
self.weight = torch.nn.Parameter(torch.randn(dim, 1, act_num2 + 1, act_num2 + 1))
self.bias = None
self.bn = nn.BatchNorm2d(dim, eps=1e-6) # 批归一化
self.dim = dim
self.act_num = act_num
weight_init.trunc_normal_(self.weight, std=.02) # 权重初始化
def forward(self, x):# 前向传播if self.deploy:# 在部署模式下,直接进行卷积return torch.nn.functional.conv2d(super(activation, self).forward(x), self.weight, self.bias, padding=(self.act_num*2 + 1)//2, groups=self.dim)else:# 否则,先进行批归一化再卷积return self.bn(torch.nn.functional.conv2d(super(activation, self).forward(x),self.weight, padding=self.act_num, groups=self.dim))def switch_to_deploy(self):# 切换到部署模式if not self.deploy:kernel, bias = self._fuse_bn_tensor(self.weight, self.bn) # 融合权重和偏置self.weight.data = kernelself.bias = torch.nn.Parameter(torch.zeros(self.dim))self.bias.data = biasself.__delattr__('bn') # 删除bn属性self.deploy = True
class Block(nn.Module):
def init(self, dim, dim_out, act_num=3, stride=2, deploy=False):
super().init()
self.deploy = deploy
# 根据是否部署选择不同的卷积结构
if self.deploy:
self.conv = nn.Conv2d(dim, dim_out, kernel_size=1)
else:
self.conv1 = nn.Sequential(
nn.Conv2d(dim, dim, kernel_size=1),
nn.BatchNorm2d(dim, eps=1e-6),
)
self.conv2 = nn.Sequential(
nn.Conv2d(dim, dim_out, kernel_size=1),
nn.BatchNorm2d(dim_out, eps=1e-6)
)
# 池化层的选择
self.pool = nn.MaxPool2d(stride) if stride != 1 else nn.Identity()
self.act = activation(dim_out, act_num) # 激活函数
def forward(self, x):# 前向传播if self.deploy:x = self.conv(x)else:x = self.conv1(x)x = F.leaky_relu(x, negative_slope=1) # 使用Leaky ReLU激活x = self.conv2(x)x = self.pool(x) # 池化x = self.act(x) # 激活return x
class VanillaNet(nn.Module):
def init(self, in_chans=3, num_classes=1000, dims=[96, 192, 384, 768],
drop_rate=0, act_num=3, strides=[2,2,2,1], deploy=False):
super().init()
self.deploy = deploy
# 定义网络的stem部分
if self.deploy:
self.stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
activation(dims[0], act_num)
)
else:
self.stem1 = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
nn.BatchNorm2d(dims[0], eps=1e-6),
)
self.stem2 = nn.Sequential(
nn.Conv2d(dims[0], dims[0], kernel_size=1, stride=1),
nn.BatchNorm2d(dims[0], eps=1e-6),
activation(dims[0], act_num)
)
self.stages = nn.ModuleList() # 存储网络的各个阶段for i in range(len(strides)):stage = Block(dim=dims[i], dim_out=dims[i+1], act_num=act_num, stride=strides[i], deploy=deploy)self.stages.append(stage) # 添加Block到网络中def forward(self, x):# 前向传播if self.deploy:x = self.stem(x)else:x = self.stem1(x)x = F.leaky_relu(x, negative_slope=1)x = self.stem2(x)for stage in self.stages:x = stage(x) # 通过每个Blockreturn x
创建模型的函数
def vanillanet_10(pretrained=‘’, **kwargs):
model = VanillaNet(dims=[1284, 1284, 2564, 5124, 5124, 5124, 5124, 10244], strides=[1,2,2,1,1,1,2,1], **kwargs)
if pretrained:
weights = torch.load(pretrained)[‘model_ema’]
model.load_state_dict(weights) # 加载预训练权重
return model
if name == ‘main’:
inputs = torch.randn((1, 3, 640, 640)) # 随机输入
model = vanillanet_10() # 创建模型
pred = model(inputs) # 进行预测
for i in pred:
print(i.size()) # 输出每一层的输出尺寸
代码说明:
激活函数类 (activation):定义了一个自定义的激活函数类,支持批归一化和卷积操作,能够在部署模式下优化性能。
Block 类:定义了网络的基本构建块,包含卷积、批归一化、激活函数和池化操作。
VanillaNet 类:构建整个网络结构,包含输入层、多个Block和输出层。
模型创建函数:提供了创建不同配置的VanillaNet模型的功能,并支持加载预训练权重。
主程序:生成随机输入并通过模型进行前向传播,输出每一层的输出尺寸。
该程序文件VanillaNet.py实现了一个名为VanillaNet的深度学习模型,主要用于图像处理任务。程序首先引入了必要的库,包括PyTorch和一些用于模型初始化和操作的工具。
文件开头包含版权信息和许可声明,表明该程序是自由软件,可以在MIT许可证下进行修改和再分发。接下来,定义了一些全局变量,表示不同版本的VanillaNet模型。
在程序中,定义了一个名为activation的类,继承自nn.ReLU,用于实现带有可学习参数的激活函数。该类的构造函数中初始化了权重和偏置,并定义了前向传播方法。在前向传播中,如果处于部署模式,则使用卷积操作,否则使用批归一化。该类还提供了一个方法用于将批归一化与卷积层融合,以便在推理时提高效率。
接着,定义了一个Block类,表示网络中的基本构建块。每个Block包含两个卷积层和一个激活函数。构造函数中根据是否处于部署模式选择不同的卷积层结构,并根据步幅选择池化层。前向传播方法中依次执行卷积、激活和池化操作。Block类也提供了与activation类类似的融合方法和切换到部署模式的方法。
VanillaNet类是整个模型的核心,包含多个Block和一个初始卷积层。构造函数中根据输入通道数、类别数、维度、丢弃率、激活函数数量、步幅等参数初始化网络结构。该类还定义了权重初始化方法和前向传播方法。在前向传播中,模型会根据输入大小生成特征图,并在不同的尺度上提取特征。
此外,程序中还定义了一些辅助函数,例如update_weight用于更新模型权重,确保模型的权重与加载的权重形状一致。接下来定义了一系列函数(如vanillanet_5到vanillanet_13_x1_5_ada_pool),用于创建不同配置的VanillaNet模型,并支持加载预训练权重。
最后,在文件的主程序部分,创建了一个随机输入并实例化了一个VanillaNet模型,进行前向传播并打印输出特征图的尺寸。这部分代码可以用于测试模型的基本功能。
总体来说,该程序实现了一个灵活的深度学习模型结构,允许用户根据需求调整模型的层数、维度和其他参数,并支持在推理时的优化。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式

)

![[机器学习]基于K-means聚类算法的鸢尾花数据及分类](http://pic.xiahunao.cn/[机器学习]基于K-means聚类算法的鸢尾花数据及分类)
---PCB铺铜相关操作)

函数分析)

)







》)
真题解析#中国电子学会#全国青少年软件编程等级考试)

