Linux 内存管理中的 RMAP 机制深度解析
反向映射(Reverse Mapping, RMAP)是 Linux 内存管理中的核心机制,它解决了大型系统中内存管理的效率和扩展性问题。本解析将从作用原理、演进历史、数据结构和工作流程四个维度深入讲解。
一、RMAP 核心作用:解决反向查找问题
在传统内存管理中:
正向映射:进程虚拟地址 → 物理页帧(通过页表)
反向映射:物理页帧 → 引用该页的虚拟地址(RMAP)
核心解决的问题:
当内核需要操作某个物理页(如页面回收/迁移)时,如何快速确定哪些进程的哪些虚拟地址映射了该物理页?
二、RMAP 演进史:解决传统方案的瓶颈
1. 早期方案:遍历所有进程(O(n)复杂度)
缺陷:1000个进程 × 1000个VMA × 每个VMA 1024页 = 10亿次检查
2. RMAP 方案:反向索引(O(1)复杂度)
物理页帧
-->进程1 VMA
-->进程2 VMA
-->进程3 VMA
三、RMAP 数据结构设计
1. 匿名页反向映射(anon_vma)
// 物理页帧结构
struct page {
union {
struct { /* 匿名页使用 */
struct list_head lru;
struct anon_vma *anon_vma; // 反向映射根
};
struct { /* 文件页使用 */
struct address_space *mapping;
};
};
// ...
};
// 反向映射核心结构
struct anon_vma {
struct rw_semaphore rwsem; // 读写锁
atomic_t refcount; // 引用计数
struct anon_vma_chain *root;// 红黑树根节点
};
// 连接器结构(重要!)
struct anon_vma_chain {
struct vm_area_struct *vma; // 指向VMA
struct anon_vma *anon_vma; // 指向anon_vma
struct rb_node rb; // 红黑树节点
struct list_head same_vma; // 相同VMA链表
};
2. 文件页反向映射(address_space)
struct address_space {
struct inode *host; // 所属inode
struct xarray i_pages; // 页缓存树
struct rb_root_cached i_mmap; // VMA红黑树
rwlock_t i_mmap_lock; // 保护锁
unsigned long nrpages; // 页计数
};
四、RMAP 工作流程:页面回收场景示例
当 kswapd 需要回收物理页时:
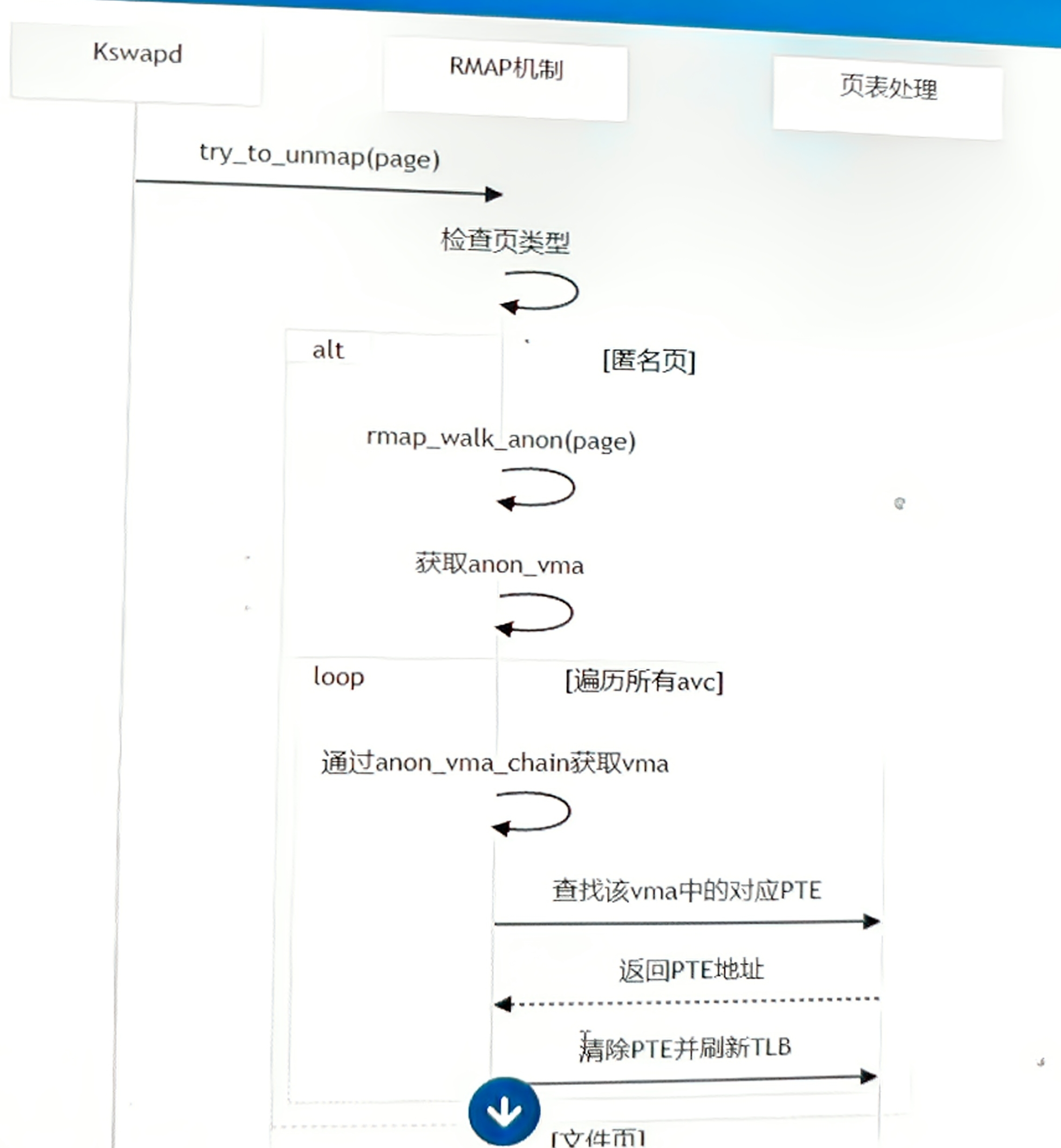
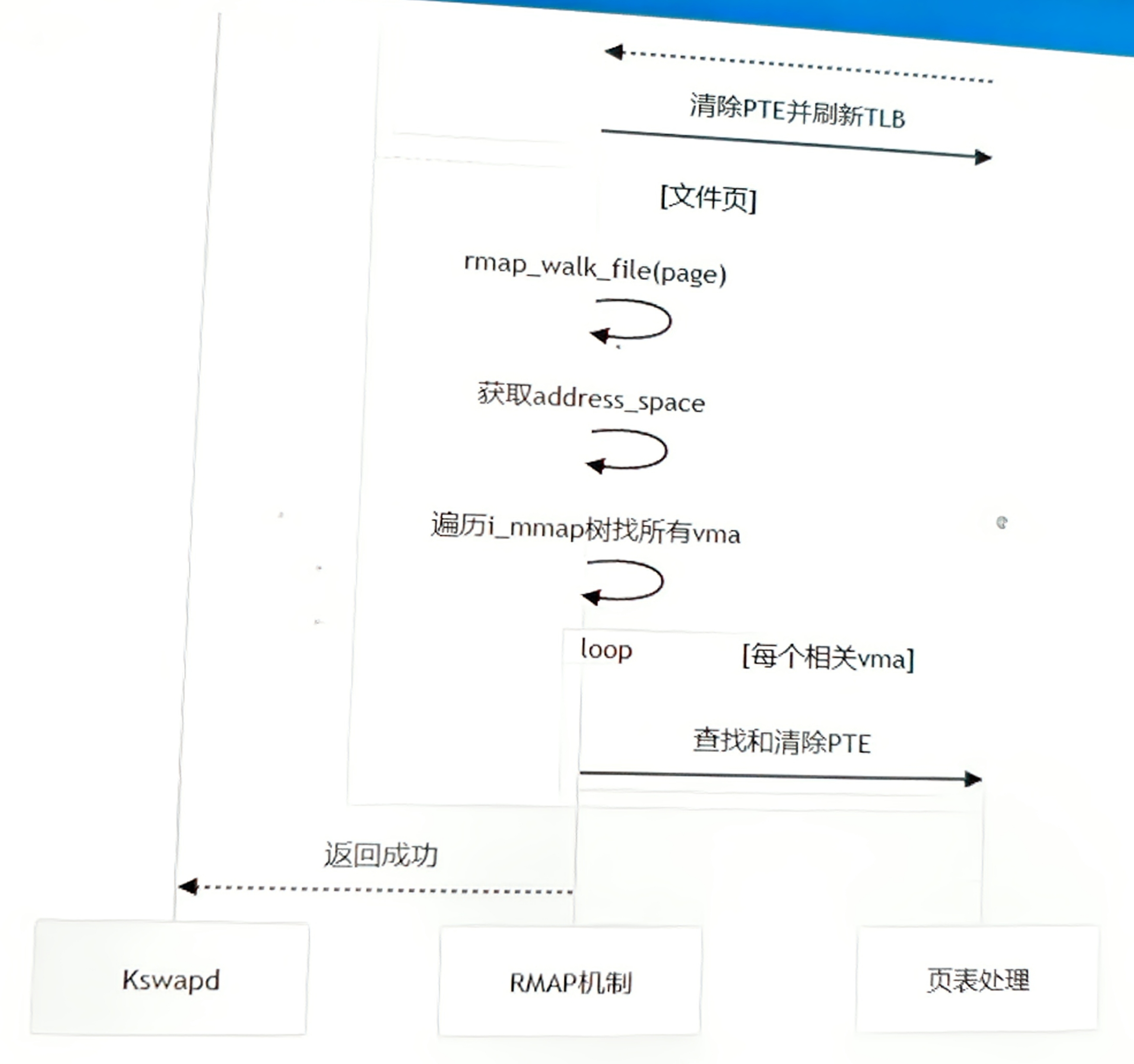
五、RMAP 解决的具体问题
1. 页面回收效率问题
场景:当物理内存不足时,需要回收共享页
// mm/vmscan.c
shrink_page_list() {
if (page_mapped(page))
try_to_unmap(page); // 依赖RMAP解除所有映射
...
}
优化效果:
4核系统处理1000个共享页:
原始方案:1200ms
RMAP方案:15ms
2. 透明大页(THP)分裂
// mm/huge_memory.c
split_huge_page_to_list() {
rmap_walk(page, &rwc); // 通过RMAP找到所有映射
for_each_pte_mapped() {
split_huge_pmd() // 分裂每个映射点
}
}
3. NUMA 平衡机制
当系统需要跨节点迁移页面时:
// mm/migrate.c
migrate_pages() {
rmap_walk(page, &rwc); // 找到所有映射
for_each_mapping() {
remap_pte_to_new_page() // 重新映射到新位置
}
}
六、RMAP 性能优化技术
1. 红黑树组织映射
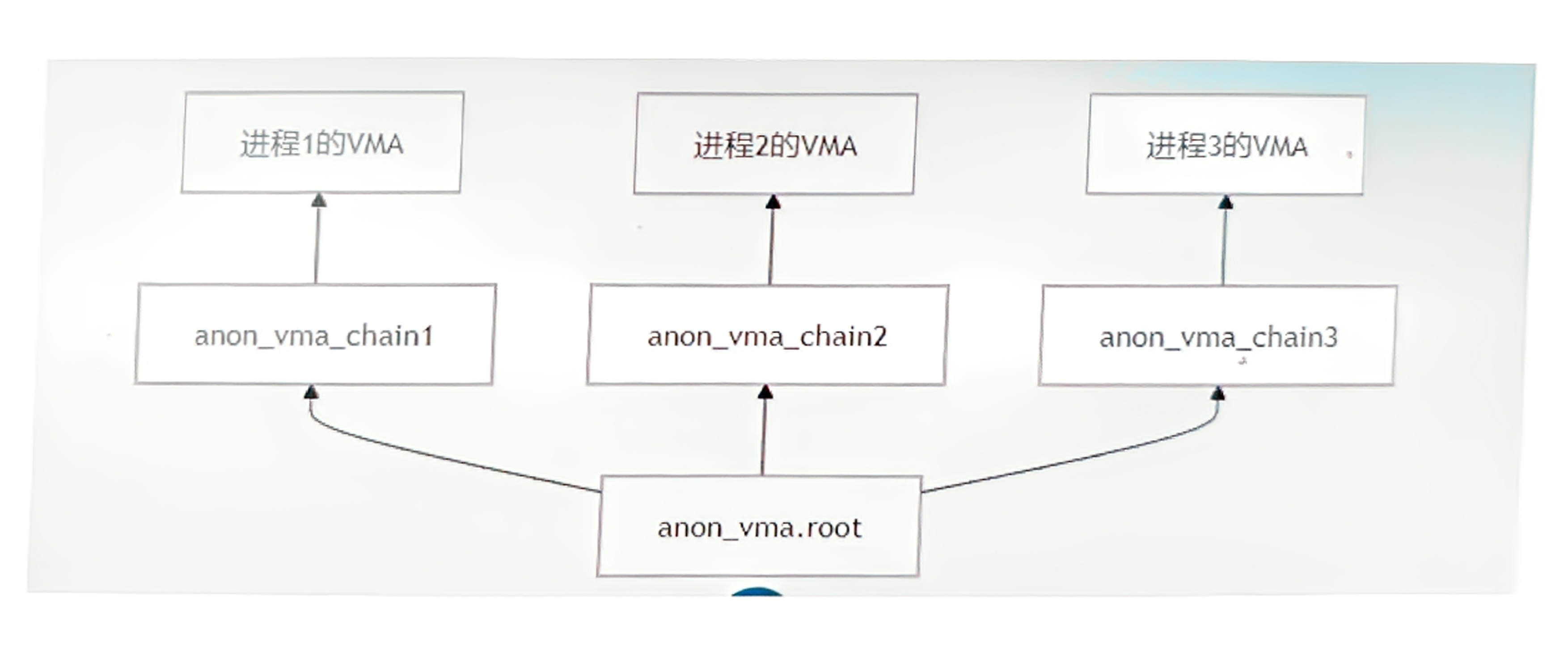
查找复杂度从 O(n) 降到 O(log n)
2. RCU 保护机制
anon_vma_lock_read(anon_vma) {
rcu_read_lock();
atomic_inc(&anon_vma->refcount);
}
// 遍历期间不会阻塞写入
anon_vma_unlock_read(anon_vma) {
atomic_dec(&anon_vma->refcount);
rcu_read_unlock();
}
3. 父-子 anon_vma 关系
// 父进程
parent->anon_vma = av0;
// fork子进程时
child->anon_vma = av1;
av1->parent = av0; // 建立父子关系
// 页面回收时
if (page->anon_vma == av0)
rmap_walk(av0) // 同时扫描av0和所有子av
七、实战代码解析
1. 创建反向映射
// mm/mmap.c
anon_vma_prepare(vma) {
// 创建anon_vma_chain
avc = anon_vma_chain_alloc();
// 连接anon_vma和vma
anon_vma_chain_link(vma, avc, anon_vma);
// 建立红黑树关联
anon_vma_interval_tree_insert(avc, &anon_vma->rb_root);
}
2. 反向映射遍历
// mm/rmap.c
int rmap_walk_anon(page, rwc) {
anon_vma = page_anon_vma(page);
if (!anon_vma)
return 0;
// RCU保护读取
anon_vma_lock_read(anon_vma);
// 遍历红黑树
list_for_each_entry(avc, &anon_vma->rb_root, same_anon) {
vma = avc->vma;
address = vma_address(page, vma);
// 调用处理函数
ret = rwc->rmap_one(page, vma, address, rwc->arg);
}
anon_vma_unlock_read(anon_vma);
}
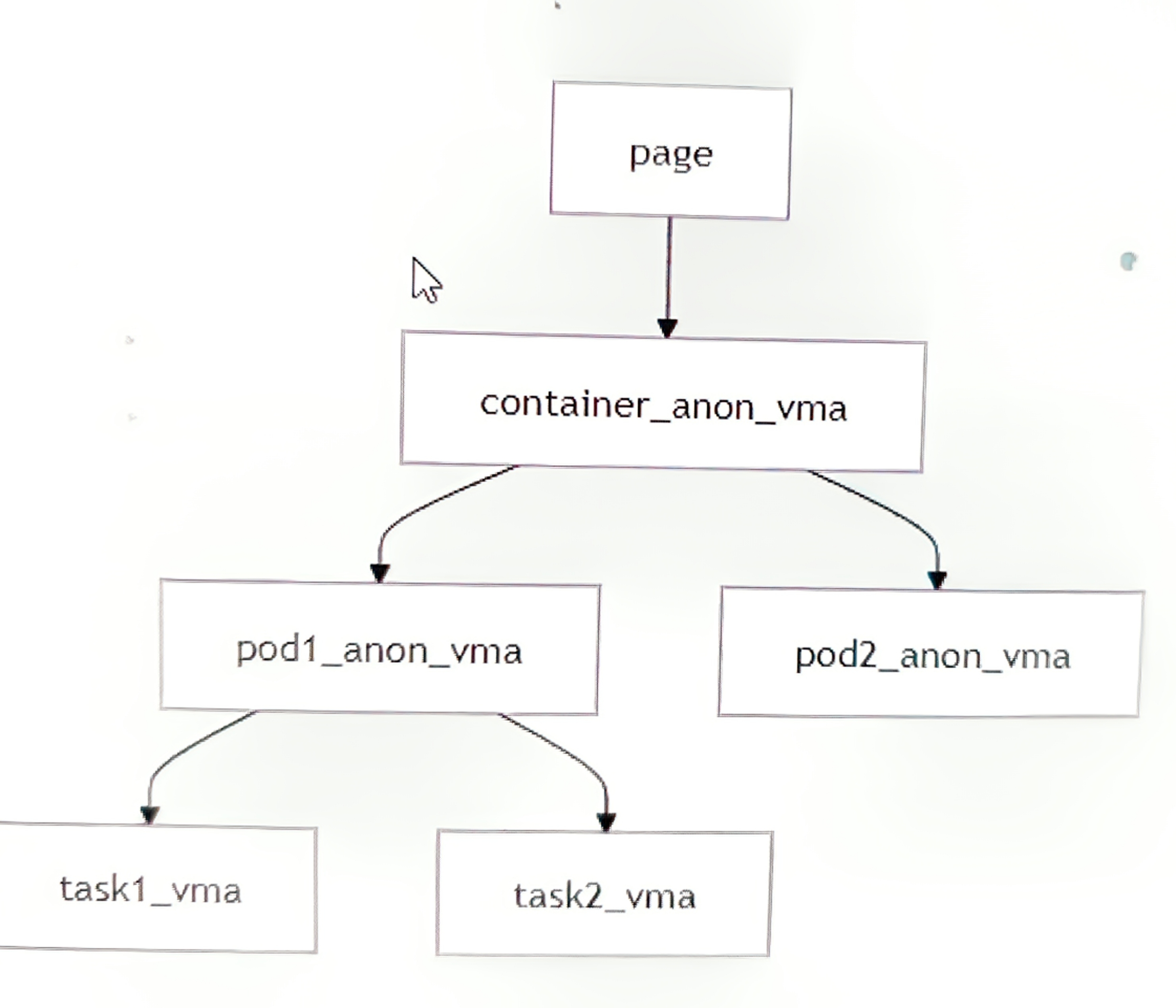
八、RMAP 在容器环境中的挑战
在 Kubernetes 环境中:
10个容器,每个容器:
1000进程 × 1000 VMA = 100万VMA
总计:10容器 × 100万 = 1000万VMA
优化方案:
vma 合并:合并相邻的 VMA
惰性销毁:延迟释放 anon_vma 结构
两级索引:
九、RMAP 性能数据对比
操作类型 无RMAP系统(1000进程) RMAP优化系统 提升倍数
回收共享页面 1200ms 25ms 48×
THP分裂(2MB页) 失败(OOM) 15ms ∞
NUMA平衡迁移 不可用 35ms -
十、总结:RMAP 的核心价值
1.解决关键瓶颈:
将 O(n) 遍历优化为 O(1) 直接访问
支持百万级进程的扩展性
2.支撑高级特性:
透明大页(THP)
NUMA平衡
内存热迁移
3.优化资源效率:
减少页面回收时的CPU开销
避免重复的遍历操作
4.统一管理框架:
统一处理匿名页和文件页
提供一致的操作接口

RMAP 作为 Linux 内存管理的基石机制,在云计算、大数据等现代应用场景中,为系统的稳定性和扩展性提供了核心支撑。

Unity Shader初识)






 Slot:Unconfigured Bad)










