概述
微调,Fine-Tuning,简称FT,可理解为对LLM的定制,目的是增强专业领域知识,并优化特定任务的性能。通过在特定数据集上微调一个预训练模型,可实现:
- 更新知识:引入新的领域专属信息;
- 定制行为:调整模型的语气、个性或响应风格;
- 优化任务:提升针对特定任务场景的准确性和相关性;
- 降低成本:避免从头训练模型。
可将微调后的模型视为一个专门优化的Agent,更高效地执行特定任务。
优势:通过修改模型参数,永久地提高模型能力。
劣势:若处理不当,很可能造成模型原始能力的灾难性遗忘,即导致模型原始能力丢失,对于复杂模型尤其如此。因此需小心谨慎地设计模型微调数据集和微调训练流程,并经过反复多次训练验证,得到最佳模型。
应用场景:
- 风格微调:适用于客服系统、虚拟助理等场景,微调得到不同语气、情感表达、礼貌程度、回答方式、对话策略等。
- 知识灌注:微调可将外部知识或领域特定的信息快速集成到已有的预训练模型中。
- 多轮推理:微调能更高效地理解长文本、推理隐含信息,或从数据中提取逻辑关系。
- 能力提升:在MAS系统或工具调用(Function Call,FC)场景中,微调能显著提升Agent能力,使得模型能够学会更精准的功能调用策略、参数解析和操作指令,进而有效地与其他系统进行交互、调用外部API或执行特定任务。
策略
Supervised FT,SFT,有监督微调,指使用带标签的目标任务数据集对预训练模型进行训练,通过模型预测结果与真实标签的误差反向传播,更新模型参数的过程。
核心特点:依赖高质量标注数据;训练过程有明确监督信号,模型收敛方向更明确。
全量微调(Full FT,FFT)和参数高效微调(Parameter-Efficient FT,PEFT)
| 维度 | FFT | PEFT |
|---|---|---|
| 定义 | 对预训练模型所有参数进行更新,无参数冻结 | 仅更新模型一小部分参数,通常<1%,其余参数冻结 |
| 参数更新范围 | 100%模型参数 | 0.1%~1%参数,依方法不同略有差异 |
| 计算/存储成本 | 极高,需支持全量参数反向传播,千亿级模型需多卡集群 | 极低,仅更新小部分参数,单卡GPU即可支持 |
| 数据依赖 | 需大量标注数据,通常数万~十万条,否则易过拟合 | 数据需求低,数千~万条即可,抗过拟合能力更强 |
| 性能上限 | 理论性能最高,可充分适配任务 | 性能接近全量微调,多数场景下差距<5%,部分任务可持平 |
| 适用场景 | 数据量充足、计算资源雄厚 | 资源有限、数据量少、多任务快速适配 |
FFT优势:无参数冻结,模型可充分学习任务特性,在数据量充足时能达到最优性能。
劣势
- 成本极高:以千亿参数模型为例,全量微调需数十张H100,单日训练成本可达数万元;
- 数据需求高:若标注数据不足,易导致过拟合,模型记住训练数据,泛化能力差;
- 存储压力大:训练过程中需保存大量中间参数(如梯度、优化器状态),对存储容量要求极高。
主流PEFT方法:
- LoRA:Low-Rank Adaptation:低秩适应。一个超大话题,需另起一篇。
- Instruction Tuning:指令微调
- Prompt Tuning:提示词微调
- Prefix Tuning:前缀微调
- Adapter Tuning:适配器微调
| 数据量/资源 | 推荐方法 | 适用场景 |
|---|---|---|
| 数据量充足>10万条、计算资源雄厚 | FFT | 大厂核心业务,如电商平台情感分析、机器翻译 |
| 数据量中等1~万条、资源有限 | LoRA | 中小企业领域适配,如医疗对话、法律文档问答 |
| 数据量少<1万条、资源有限 | 其他 | 小样本任务,如特定领域NER、少量标注分类任务 |
LoRA凭借低成本+高性能的平衡,已成为当前LLM微调的主流选择。
Prompt Tuning
思想:不改变模型原始权重,仅通过优化输入提示词本身来引导模型输出期望结果;提示词可以是离散的(人工设计模板)或连续的(可训练的向量,如P-Tuning)。
微调对象:只微调与输入提示相关的少量参数(如Prompt Embedding),不改变语言模型主体参数。
典型方法:P-Tuning、P-Tuning v2。
Instruction Tuning
思想:通过在大量指令-输入-输出对数据上微调整个模型(或部分参数),让模型学会理解和执行各种自然语言指令。
微调对象:模型参数本身(全参数微调,或部分参数微调)。
特点:
- 目标是增强模型对自然语言指令的泛化能力,使其能直接按照用户指令执行任务。
- 微调后模型对提示工程依赖较低,输出更自然、一致。
- 需大量标注数据,计算成本相对较高。
Prefix Tuning
思想:与Prompt Tuning类似,在输入序列前添加一段可训练的连续向量(即前缀Token,会参与模型的注意力计算),仅优化这些前缀参数,其余模型参数冻结。
微调对象:仅前缀参数(通常占模型总参数的0.1%)。
特点:
- 适用于生成类任务;
- 前缀长度可调,长度越长效果通常越好,但推理速度几乎不受影响。
Adapter Tuning
论文,
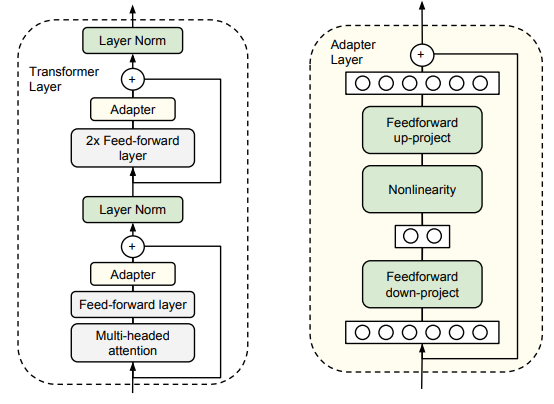
思想:在预训练模型的每一层(或部分层)插入小型适配器模块(通常由两层MLP构成,如BottleNeck结构:降维→激活→升维),仅训练这些适配器参数,模型主体冻结。
微调对象:适配器模块参数(通常占模型总参数的3~5%)。
特点:
- 几乎不影响原模型结构,推理时只需额外计算适配器部分;
- 适配器模块可针对不同任务分别训练,灵活性强;
- 参数量比Prefix Tuning大,但通常效果更稳定。
其他微调方法对比
| 方法 | 微调对象 | 是否改模型权重 | 参数占比 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|---|---|
| Prompt Tuning | 输入提示(连续/离散) | 否 | 极低 | 资源受限、快速适配 | 高效、极低计算开销 | 依赖提示工程,效果有限 |
| Instruction Tuning | 模型参数(全/部分) | 是 | 较高 | 通用指令执行、多任务 | 输出自然、泛化强 | 需大量标注数据、开销大 |
| Prefix Tuning | 输入前缀(连续向量) | 否 | 极低 | 生成任务 | 参数极省、推理快 | 仅适合生成类任务 |
| Adapter Tuning | 插入适配器模块 | 否 | 低 | 理解+生成任务 | 灵活、稳定、可插拔 | 参数略多,训练略复杂 |
对比RAG
参考RAG概述。
- 针对特定任务的专业性
微调让模型深入理解某个特定领域或任务,使其能精准处理结构化、重复性高或具有复杂背景的查询,这是RAG无法独立完成的 - 推理速度更快
微调后的模型直接生成答案,无需额外的检索步骤,适用于对响应速度要求极高的场景。 - 个性化行为与风格
微调可精准控制模型的表达方式,确保其符合品牌风格、行业规范或特定约束。 - 为模型添加新知识
微调的核心目标之一,让模型掌握全新的概念或知识,只要数据集中包含相关信息。
RAG+微调:结合两者,以发挥最大优势:
- RAG让系统具备动态获取最新外部知识的能力;
- 微调让模型掌握核心专业知识,即使没有外部检索也能稳定发挥作用;还能帮助模型更好地理解和整合检索回来的信息;
- 任务专业性:微调擅长特定任务,RAG提供最新外部知识,两者互补;
- 适应性:当检索失败时,微调后的模型依然能维持高水平的性能,RAG让系统无需频繁重新训练也能保持知识更新;
- 效率:微调建立稳定的基础,RAG则减少对大规模训练的需求,仅在必要时提供额外信息。
实战
一些建议:
- 微调没有单一的最佳方式,只有适用于不同场景的最佳实践;
- 使用Unsloth等易入门的开源框架;
- 从4比特QLoRA量化入手;
- 使用免费云服务器资源如Google Colab和Kaggle Notebook。
数据集
微调流程中,数据集质量直接决定微调效果,尤其是当模型需具备复杂功能(如FC、混合推理)或应用于特定领域任务时。
模型通过特殊字符标记识别输入类型、系统提示和输出边界,数据集需遵循模型的格式规范。以Qwen3为例:
<|im_start|>:标记文本开始,后跟角色,如user/assistant/system;<|im_end|>:标记文本结束。
标记可在模型的tokenizer_config.json文件中查看完整定义。
常见微调数据集格式
- 基础问答:Alpaca风格,适用于简单指令微调,包含instruction、input和output三个核心字段。示例:
{"instruction": "识别并解释给定的科学理论","input": "细胞理论","output": "细胞理论是生物科学的基础理论,认为所有生命体由细胞构成,细胞是生物的基本结构和功能单位。"
}
微调时,脚本会自动将其转换为Qwen3等模型兼容的标记格式:
<|im_start|>user
识别并解释给定的科学理论:细胞理论<|im_end|>
<|im_start|>assistant
细胞理论是生物科学的基础理论...<|im_end|>
- 带系统提示和FC:若需提升模型的FC能力,数据集需包含系统提示、工具定义和调用示例。系统提示:明确FC规则;工具定义:通过
<tools>描述函数参数。对话示例:
<|im_start|>system
你是天气助手,查询天气时需调用get_weather函数。
<tools>[{"name":"get_weather","parameters":{"location":"城市名称"}}]</tools><|im_end|>
<|im_start|>user
北京天气如何?<|im_end|>
<|im_start|>assistant
<tool_call>{"name":"get_weather","arguments":{"location":"北京"}}</tool_call><|im_end|>
高效微调仅能优化现有FC能力,无法让模型从无到有学会该功能。
- 带思考过程:为提升模型推理能力,数据集需包含中间思考步骤,用特殊标记分隔思考过程与最终输出。例如:
<|im_start|>system
你是数学助手,需展示解题步骤。<|im_end|>
<|im_start|>user
计算3+5×2的结果。<|im_end|>
<|im_start|>assistant
<think>用户问的是3加5乘2,先算乘法再算加法,5乘2等于10,再加3就是13。/think>3+5×2=3+10=13<|im_end|>
作为示例和思路,为混合推理模型构造微调数据集,采用多数据集拼接策略,核心步骤:
- 选择基础数据集
- 普通对话数据:如FineTome-100k(含10万条多轮对话,ShareGPT风格),用于保留模型的自然交互能力。
- 推理类数据:如OpenMathReasoning(含54万道数学题及详细解题步骤),用于强化逻辑推理能力。
- 数据集配比调整:需根据微调目标平衡不同类型数据的比例:
- 若侧重数学推理:可按7:3比例混合;
- 若需均衡能力:可按5:5比例混合,避免模型过度偏向单一任务。
- 格式统一与清洗:确保所有数据转换为Qwen3兼容的标记格式;过滤重复样本、错误标注和低质量内容,避免模型学习噪声数据。
数据集下载渠道:HF、ModelScope(魔搭社区,简称MS)
框架
LLaMA-Factory
57.5K Star,7K Fork。参考LLaMA-Factory。
Unsloth
参考Unsloth实战。45.1K Star,3.6K Fork。
ColossalAI
GitHub,41.1K Star,4.5K Fork。一个高效的分布式人工智能训练系统,旨在最大化提升AI训练效率,最小化训练成本。作为DL框架内核,提供自动超高维并行、大规模优化库等前沿技术。
优势表现:与英伟达Megatron-LM相比,仅需一半数量的GPU即可完成GPT-3训练,半小时内预训练ViT-Base/32,并在两天内训练完15亿参数的GPT模型。提供多种并行技术,如数据并行、流水线并行和张量并行,以加速模型训练。
强化学习训练,则推荐veRL和OpenRLHF等框架。
MS-Swift
MS社区推出,GitHub,9.7K Star,851 Fork。
XTuner
上海AI实验室的InternLM团队推出的开源(4.7K Star,354 Fork)轻量化LLM微调工具库,支持LLM多模态图文模型的预训练及轻量级微调。
特点:
- 高效:仅需8GB显存即可微调7B模型,支持多节点跨设备微调70B+ LLM。通过自动分发FlashAttention、Triton kernels等高性能算子加速训练,兼容DeepSpeed,能轻松应用ZeRO优化策略提升训练效率;
- 灵活:兼容InternLM等多种主流LLMs和LLaVA多模态图文模型,支持预训练与微调。数据管道设计灵活,兼容任意数据格式,支持QLoRA、LoRA及全量参数微调等多种算法;
- 全能:支持增量预训练、指令微调与Agent微调,提供丰富的开源对话模板便于与模型交互。训练所得模型可无缝接入部署工具库LMDeploy、评测工具库OpenCompass及VLMEvalKit,实现从训练到部署的全流程支持。
安装
# 环境准备
conda create --name xtuner-env python=3.10 -y
conda activate xtuner-env
# 源码安装
git clone https://github.com/InternLM/xtuner.git
cd xtuner
pip install -e '.[deepspeed]'
# 验证
xtuner list-cfg
XTuner支持增量预训练、单轮对话、多轮对话三种数据集格式:
- 增量预训练数据集用于提升模型在特定领域或任务的能力;
- 单轮对话和多轮对话数据集则经常用于指令微调阶段,以提升模型回复特定指令的能力。
MindSpeed LLM
GitHub。
对比选型
| 维度 | LLaMA-Factory | Unsloth | MS-Swift | MindSpeed LLM |
|---|---|---|---|---|
| 定位 | 微调,主打模块化与多场景适配 | 微调+加速,聚焦性能与效率优化,显存优化型训练加速引擎 | 多模态全栈工具链 | 昇腾硬件深度优化框架 |
| 社区生态 | 中文社区活跃,提供Web UI工具 | HF生态兼容,开发者论坛活跃 | MS框架,整合天池/魔搭社区资源 | 华为昇腾社区双轨支持,兼容MindSpore/PyTorch双后端 |
| 优势 | 模块化设计、多硬件自适应、量化技术 | 高速微调、低内存占用、主流模型兼容、显存效率极致优化 | 多模态DPO训练,推理吞吐量提升20倍 | 昇腾910B训练速度超A100 2.3倍,支持千亿参数模型分布式训练 |
| 局限 | 全参微调速度较慢,存在历史安全漏洞 | 社区较新文档不完善,依赖Triton内核经验 | 生态依赖性强,脱离MS扩展性受限 | 硬件适配单一,非昇腾环境支持有限 |
| 硬件支持 | NVIDIA/AMD/Ascend GPU、Mac M系列芯片 | 主要支持NVIDIA GPU | NVIDIA GPU 为主,部分支持Ascend NPU(算子兼容问题) | 昇腾910B/910C NPU,支持训推共卡 |
| 模型支持 | 支持主流 | 支持主流,兼容HuggingFace格式 | 支持主流,500+纯文本模型、200+多模态模型 | 支持主流,新增MindSpore后端 |
| 训练效率 | 全参微调速度较Unsloth慢30%,支持DeepSpeed分布式 | 40GB可处理70B模型,GRPO流程优化 | 多卡训练效率提升40%(DDP+FSDP),集成vLLM加速 | 千亿参数模型分布式训练效率领先,GRPO训练速度提升显著 |
| 显存优化 | 动态量化(2-8bit)+梯度检查点,8B模型微调显存10GB | 动态4bit量化+Triton内核重写,显存占用减少80% | PEFT技术+混合精度训练,显存占用降低70% | 算子融合+内存复用,70B模型训练显存32GB(GRPO优化后) |
| 微调策略 | 全参微调、LoRA、QLoRA,支持DPO、SimPO对齐 | LoRA、QLoRA、动态量化训练,GRPO强化学习 | LoRA+、GaLore、Q-GaLore,多模态DPO训练 | QLoRA、DPO、PPO,支持训推共卡模式 |
| 易用性 | 低代码Web UI,数据标注-训练-部署一键式操作 | API简洁,5分钟上手,提供Colab一键启动脚本 | 依赖MS数据工具,多模态任务配置模板化 | 需熟悉Ascend-CANN工具链,昇腾专用SDK |
| 典型场景 | 多模态内容生成、行业LLM私有化部署 | 资源受限环境快速迭代、学术研究原型开发 | 多模态对话系统、长文本生成(16K Token) | 昇腾集群部署的千亿参数模型训练、金融风控/政务合规场景 |
其他框架
| 框架 | 优势 | 适用场景 |
|---|---|---|
| Hugging Face | 高度兼容,易用,文档丰富 | 一般NLP任务,模型选择丰富 |
| LoRA | 显存节省,减少微调计算量 | 显存有限的设备,微调大规模模型 |
| PEFT | 高效微调,低计算开销 | 资源有限的环境,适合大规模预测级模型的微调 |
| DeepSpeed | 大规模分布式训练,显存优化 | 超大规模训练,多卡分布式训练 |
| AdapterHub | 低资源消耗,快速微调 | 多任务微调,资源有限的环境 |
| Alpaca-LoRA | 生成任务优化,LoRA技术结合 | 对话生成、文本生成 |
| FastChat | 对话系统微调,快速集成 | 对话生成任务,尤其是对ChatGPT等模型微调 |
| FairScale | 大规模分布式训练优化,自动化优化 | 多卡分布式训练,大规模微调 |
资料
Notebook
Unsloth AI开源Notebook,涵盖:
- BERT、TTS、视觉等多模态;
- GRPO、DPO、SFT、CPT等方法论;
- 数据准备、评估、保存等微调阶段;
- Llama、Gemma、Phi等模型;
- 其他:工具调用、分类、合成数据;
![【LCA 树上倍增】P9245 [蓝桥杯 2023 省 B] 景区导游|普及+](http://pic.xiahunao.cn/【LCA 树上倍增】P9245 [蓝桥杯 2023 省 B] 景区导游|普及+)


:面向链接预测的知识图谱表示学习方法综述)
,规则(Rules))

![前沿重器[74] | 淘宝RecGPT:大模型推荐框架,打破信息茧房](http://pic.xiahunao.cn/前沿重器[74] | 淘宝RecGPT:大模型推荐框架,打破信息茧房)

的崛起——为什么“会写Prompt”成了新技能?)

)


)





