在日常工作中,多模态模型的 “幻觉” 问题已成为影响效率的关键痛点 —— 当我们需要模型基于文档生成建议性内容(如行业报告分析、论文数据解读等)时,模型常因无法准确理解文档信息,输出包含 “虚构内容” 的结果,尤其是文档中存在复杂表格、数据公式时,问题更为突出。
这种 “幻觉” 的根源,在于多模态模型对文档的识别与理解存在局限性:面对含复杂表格(如合并单元格、跨页表、框线残缺表)、手写批注、印章覆盖,或融合文本、图表、公式等多元素的文档时,模型难以精准提取图像中的关键信息,无法完成基础的 “信息读懂” 环节,最终只能通过 “脑补” 生成内容,导致输出与文档实际信息脱节。
而 “幻觉” 带来的连锁反应,直接打破了工作效率提升的预期:用户需额外增加校对环节,逐一核对模型输出与文档原文的一致性,不仅消耗大量时间成本,还可能因人工校对疏漏,导致错误信息流入后续工作(如数据核对、合规审核),引发更高的风险。
TextIn 文档解析工具 —— 从 “源头”解决模型 “幻觉”
要修正多模态模型对表格 “虚构描述” 的问题,核心在于解决模型 “读不懂文档” 的源头矛盾 —— 通过专业的文档解析工具,提前将文档中的复杂信息转化为模型可理解的结构化数据,为模型提供精准、完整的输入。
TextIn 文档解析工具正是针对这一需求设计,其核心功能是将文档按逻辑与元素分离识别,精准提取文本、表格、图表、公式等各类信息,让多模态模型能 “清晰读懂” 文档中的每一个细节,从根本上减少 “脑补式幻觉” 的产生。
操作步骤
- 文档上传与初始识别:将含复杂表格、多元素的目标文档(如行业报告、论文、合规文件等)上传至 TextIn 平台,工具会自动启动多模态元素扫描,快速定位文档中的表格、文本、手写体、印章、图表、公式等核心元素,完成初步元素分类。
- 针对性元素解析与数据抽取:针对不同元素启动专项解析能力 —— 对复杂表格,工具会精准切割单元格边界、还原表格结构,将数据抽取为 Markdown、JSON 等结构化格式;对手写体或印章覆盖的文字,自动分离背景干扰,清晰识别覆盖内容;对多元素组合文档,额外分析元素间的上下文关联(如图表标题与图表、表格数据与正文论点的对应关系)。
- 结构化数据输出与模型对接:解析完成后,工具输出语义清晰、格式规范的结构化数据,用户可直接将该数据作为输入,传递给多模态模型。此时模型基于精准的结构化信息生成内容,无需再 “脑补” 表格数据,从源头避免 “虚构描述” 的出现。
优势亮点
- 复杂表格精准解析,杜绝数据 “失真”:针对行业报告、论文中常见的特殊表格(合并单元格、跨页表、框线残缺表),工具通过先进深度学习模型,实现表格结构的完整还原与数据的高保真抽取,输出的结构化数据(如 Markdown、JSON)可直接用于模型输入,避免传统人工录入效率低、简单 OCR 识别错误率高的问题,为模型提供 “无偏差” 的表格数据基础。
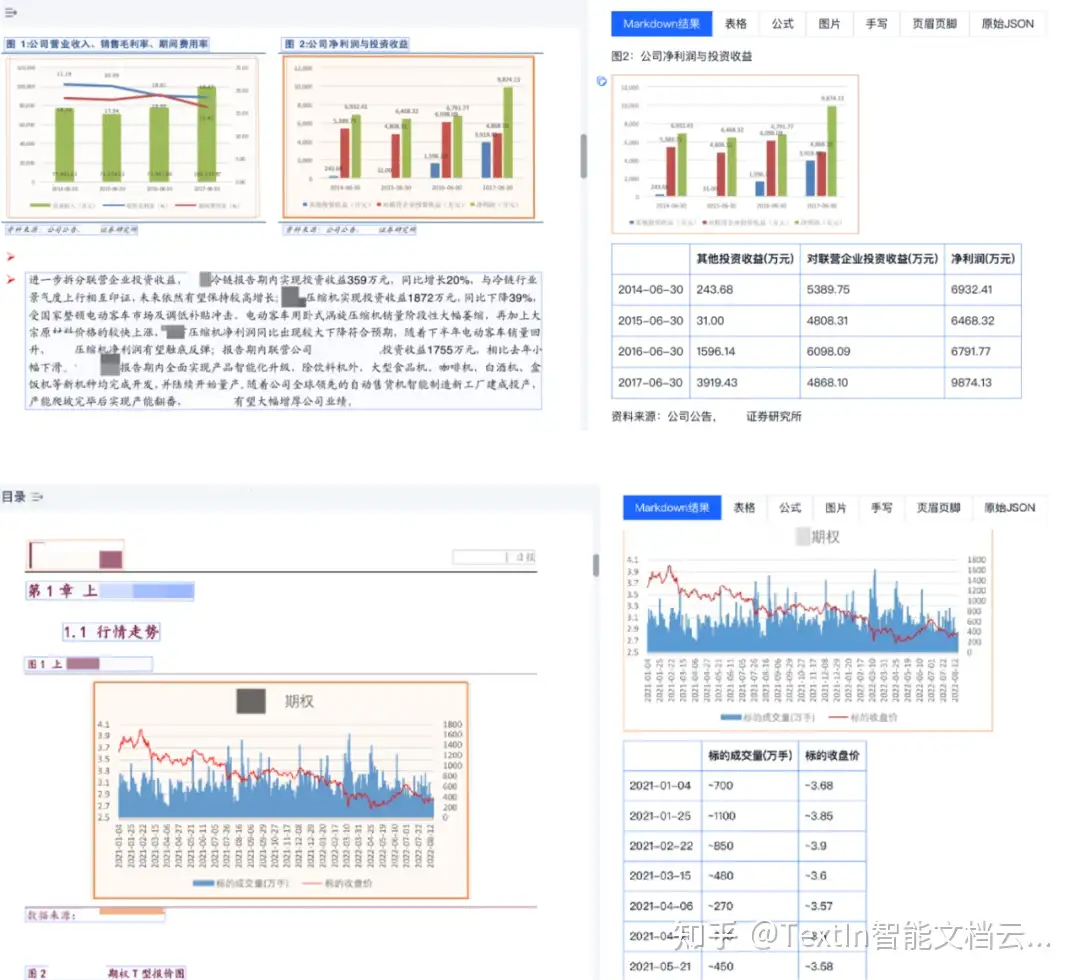
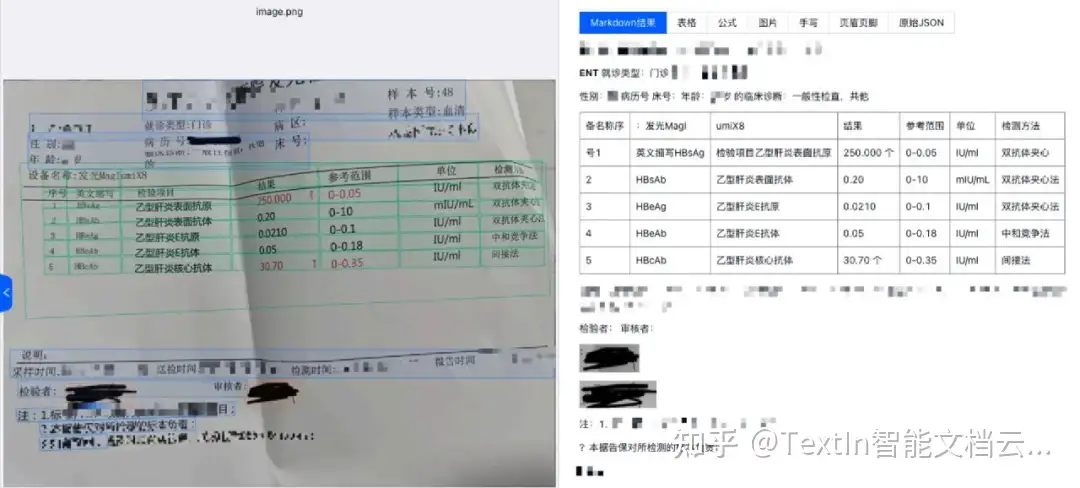
- 抗干扰识别,保障关键信息完整:面对日常文档中常见的手写签名、批注、印章覆盖等干扰,工具通过强大的图像处理与文字识别能力,可有效分离背景印章、清晰辨识覆盖文字,即使是潦草连笔的手写体也能保持高识别准确率。这确保了签字页、手写备注等关键信息不遗漏、不误读,满足监管对文件 “清晰、准确” 的要求,也避免模型因关键信息缺失产生 “幻觉”。
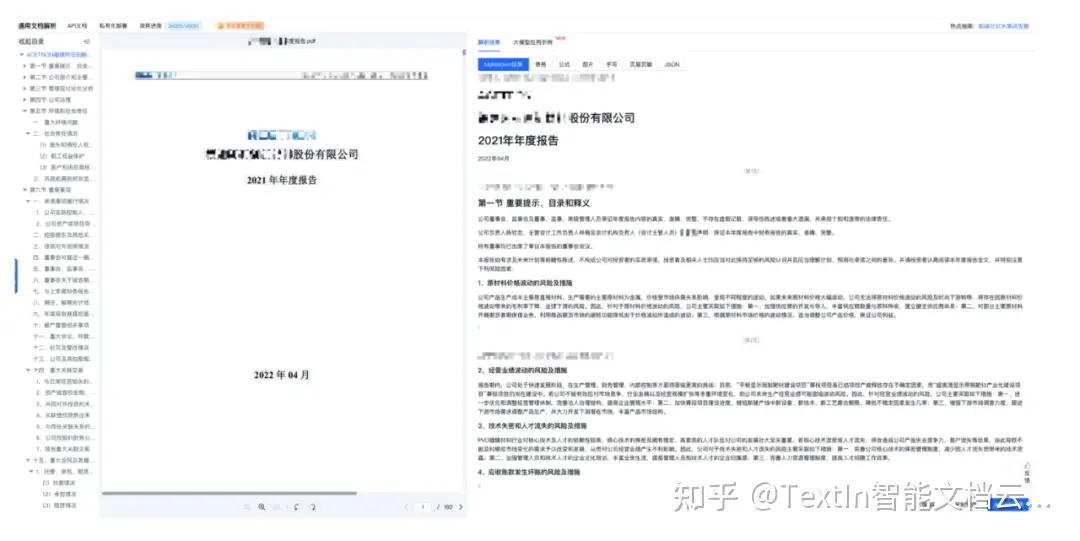
- 多元素语义关联,实现深度结构化:不同于仅能识别单个元素的工具,TextIn 可理解文档中文本、表格、图表、公式等元素间的上下文关系(如识别图表标题与对应图表、理解表格数据支撑的正文论点)。这种深度结构化解析能力,为模型后续的智能审核(如数据一致性校验、关键条款比对)提供语义清晰的输入,让模型能 “理解” 而非 “猜测” 元素间的逻辑,进一步减少 “虚构内容”的生成。
立即体验 Textin文档解析![]() https://cc.co/16YSWm
https://cc.co/16YSWm














)


)

