文章摘要
- LevelDB的日志管理系统是怎么通过双链表来进行数据管理
- 为什么LevelDB能够在不锁表的情况下进行日志新增
适用人群:
- 对版本管理机制有开发诉求,并且希望参考LevelDB的版本开发机制。
- 数据库相关从业者的专业人士。
- 计算机狂热爱好者,对计算机的存储机制有强烈技术追求的同志。
阅读建议:
- 作者本人功底有限不太可能考虑到所有读者的阅读细节,建议读者先通盘阅读下本文,先熟悉本文中会出现哪些关键概念和关键流程,并配合上AI工具对文章中个别流程进行细致理解。
LevelDB版本管理机制
核心抽象
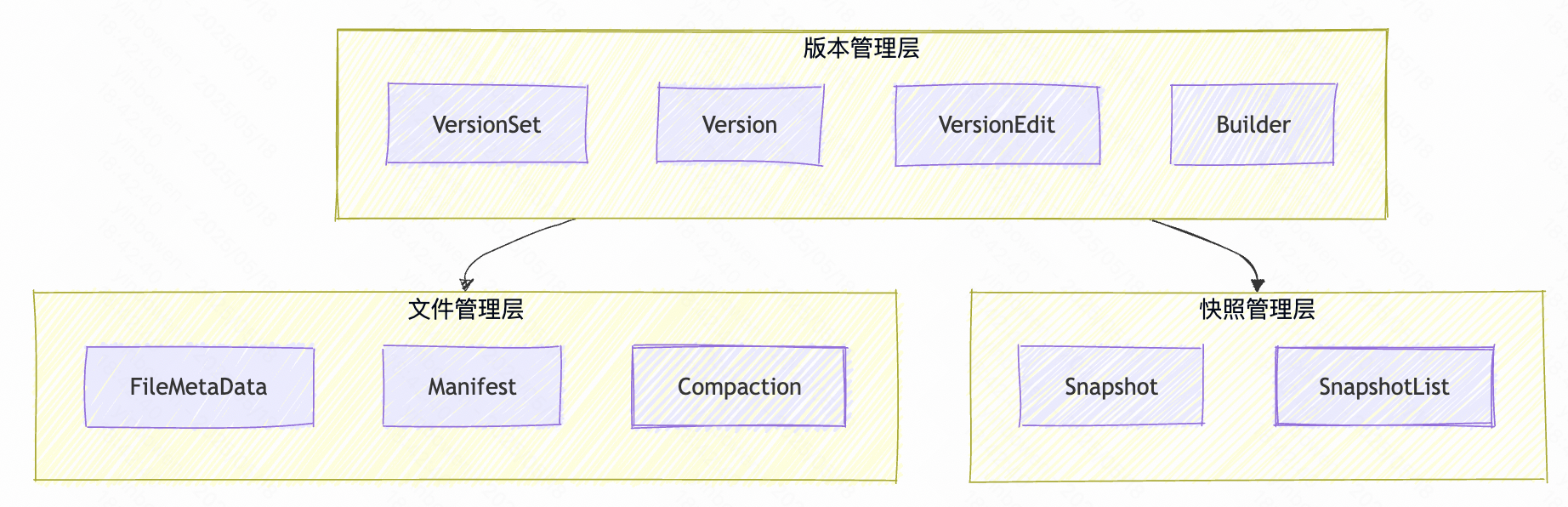
主要分为
- 版本管理层:版本抽象相关的操作和逻辑。
- 文件管理层: 主要和文件磁盘上的物化数据打交道。
- 快照管理层:依托快照对外暴露固化查询的服务。
| 抽象 | 职能 |
|---|---|
| Version | 版本管理的最小单位,维护特定时刻的数据库状态,管理文件集合 |
| VersionSet | 版本集合管理器,负责管理所有版本,维护当前版本,处理版本切换 |
| VersionEdit | 版本变更记录,记录版本间的差异,支持变更的序列化和反序列化 |
| Builder | 版本构建器,负责构建新版本,应用版本变更 |
| Compaction | 压缩任务管理,处理文件压缩,生成新的版本变更 |
| FileMetaData | 文件元数据,记录文件的基本信息(大小、范围等) |
| Manifest | 清单文件管理,持久化版本信息,支持数据库恢复 |
| Snapshot | 数据库某一时刻的快照,提供一致性读取视图,基于序列号实现 |
| SnapshotList | 快照列表管理,维护所有活跃的快照,管理快照的生命周期 |
这里面的重点是:
- Version是整个版本管理机制的最小单元抽象
- compaction 的机制非常复杂,本文不赘述,感兴趣移步: [LevelDB]揭秘LevelDB暗藏的合并秘技,Compaction内部的超神操作让工程师都惊呆了!
版本管理层(Version)核心逻辑
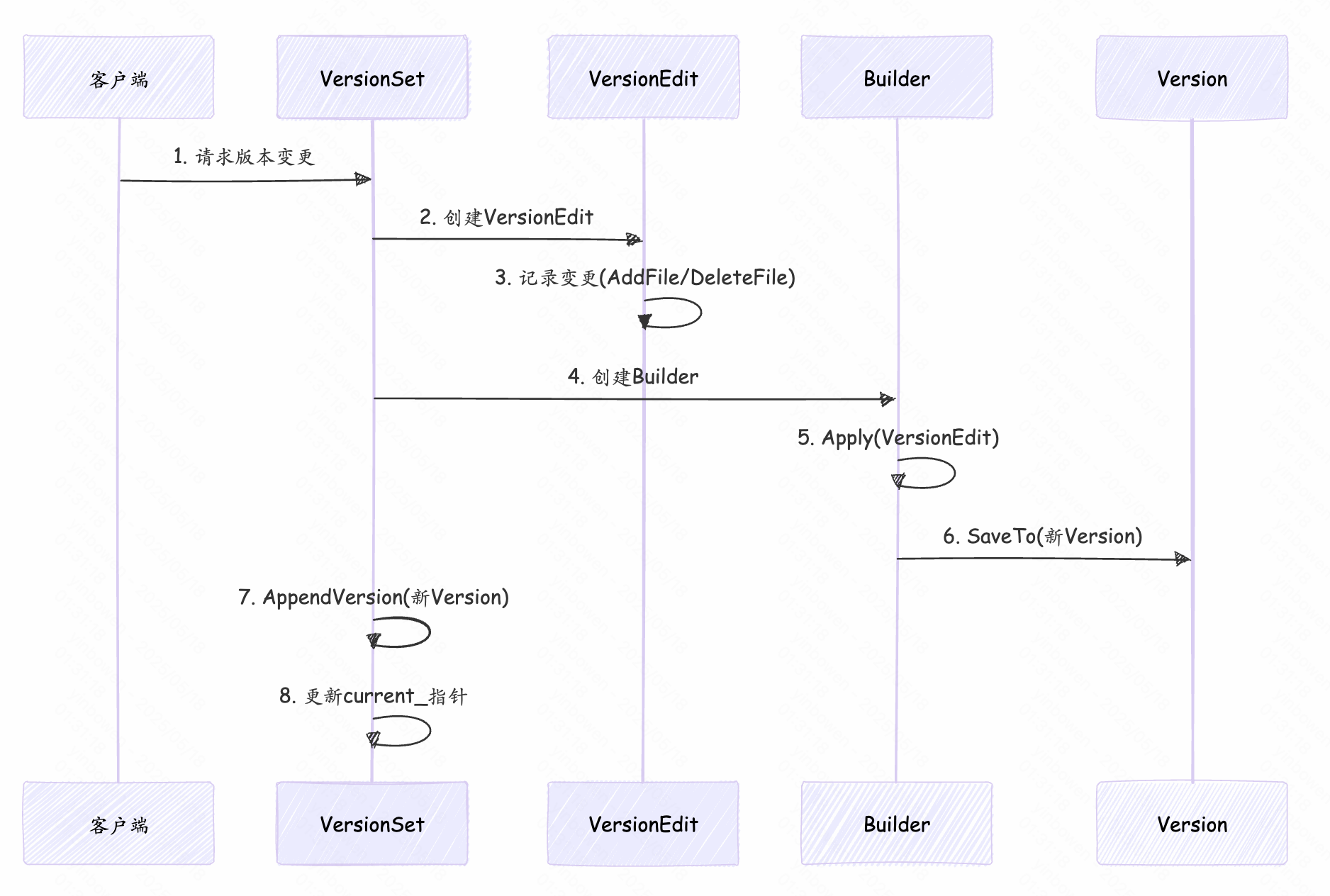
- 客户端向VersionSet抽象请求版本变更操作
- VersionSet 通过创建VersionEdit来记录一些当前操作的变更
- 使用Build模式来创建新版本并更新当前的版本
亮点设计:
- 使用新建Version的方式来实现无锁读取,简化并发控制。
- 使用Builder(构建者模式)来进行构建,对代码进行解耦。
- 使用VersionEdit进行增量更新,并且能够通过VersionEdit来进行日志记录。
源代码细节说明
客户端(通常理解是应用LevelDB的机器)调用LevelDB的LogAndApply接口来进行版本新增
// 调用入口
s = versions_->LogAndApply(&edit, &mutex_);
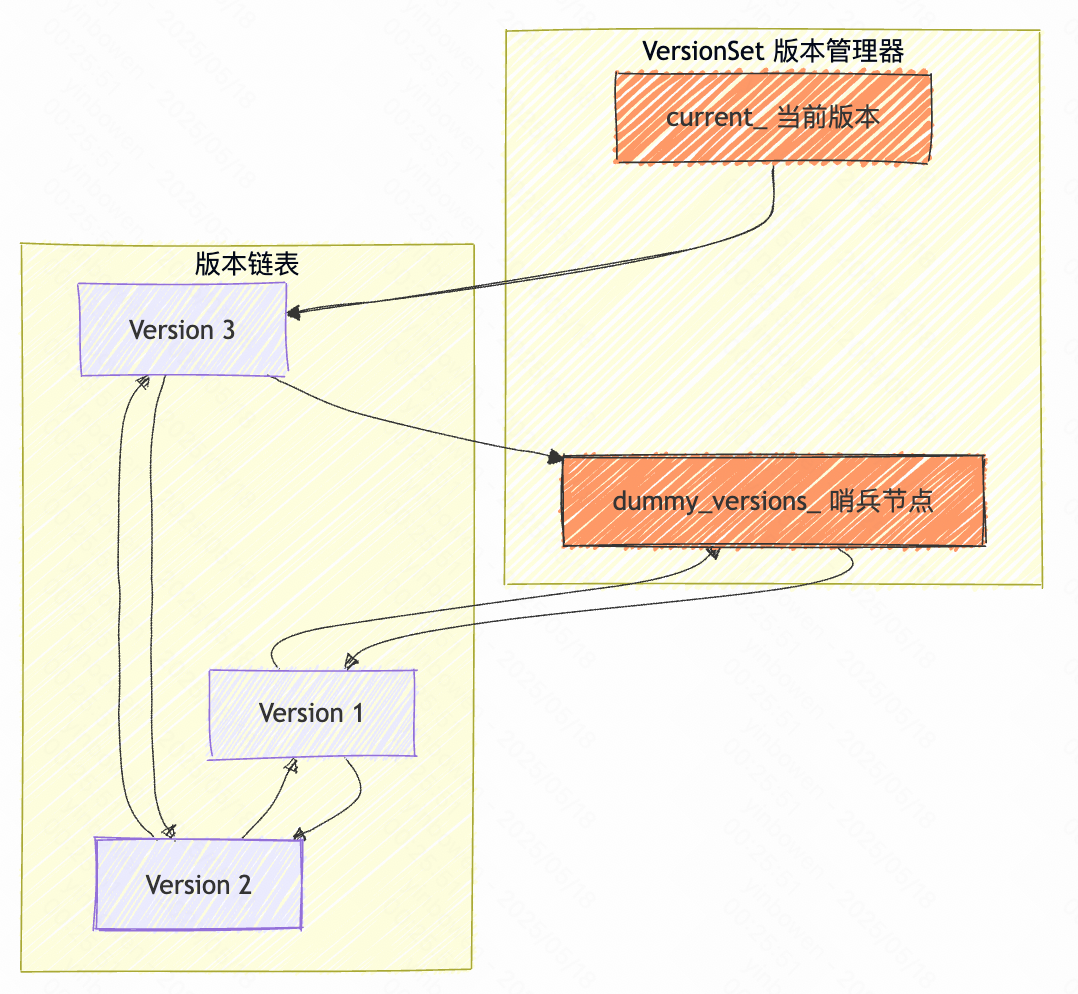
简单来说,就是生成一个新的版本Version,并添加到当前的版本管理链表中。
LogAndApply方法主要有以下的核心阶段(流程图见下文)
- 初始化一些必要参数,如log_number_(日志编号: 用于后续清理WAL无用日志), file_number(文件编号-用于实现文件的唯一性),Sequence(用于实现序列号唯一性)
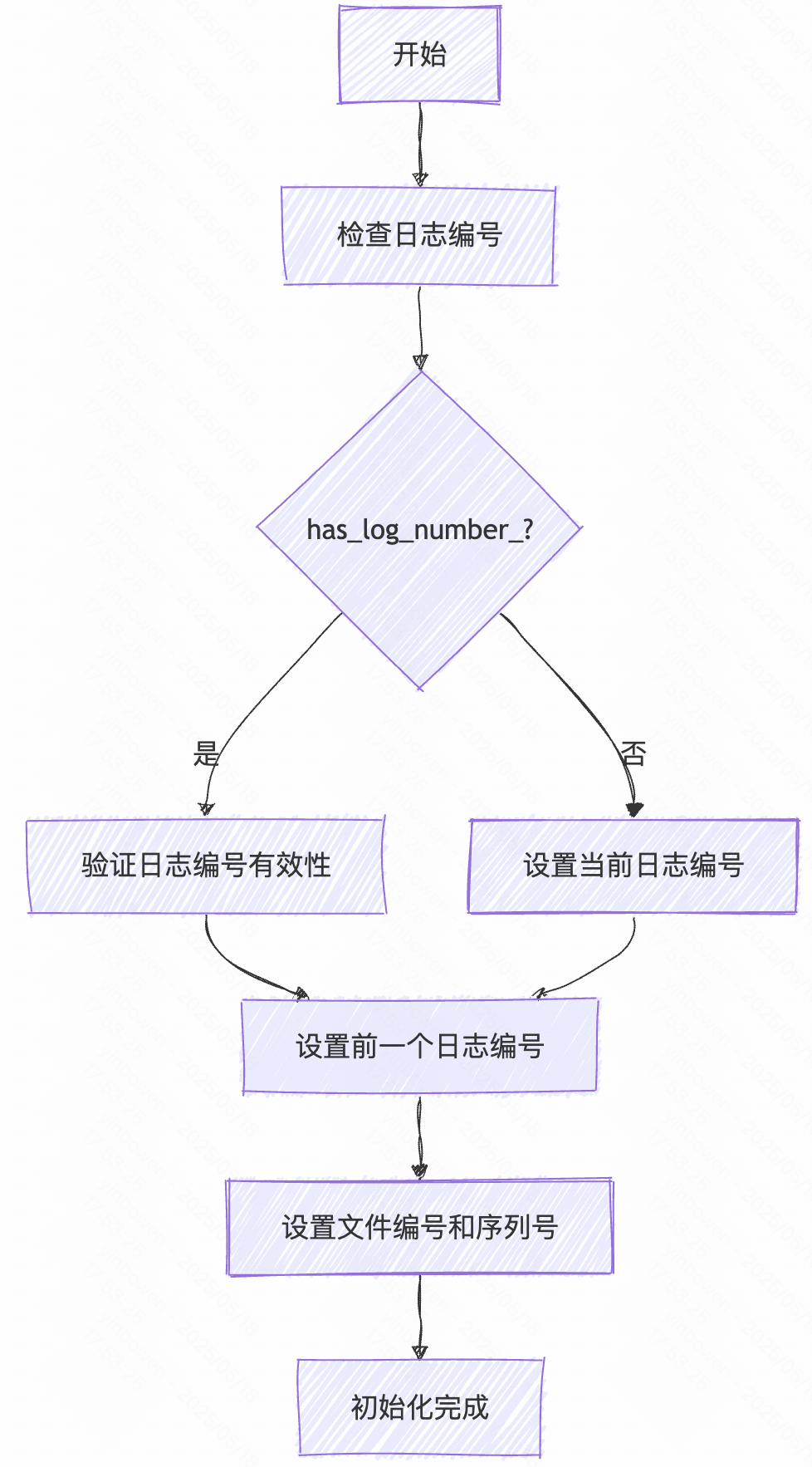
源码参考:
// 日志版本号-用于实现WAL 预写入机制-用于清理当时用不了的文件if (edit->has_log_number_) {assert(edit->log_number_ >= log_number_);assert(edit->log_number_ < next_file_number_);} else {edit->SetLogNumber(log_number_);}if (!edit->has_prev_log_number_) {edit->SetPrevLogNumber(prev_log_number_);}// file_number 文件编号-用于实现文件的唯一性 // sequence: 用于控制序列唯一性edit->SetNextFile(next_file_number_);edit->SetLastSequence(last_sequence_);
- 构建新版本(包括对版本的压缩打分)
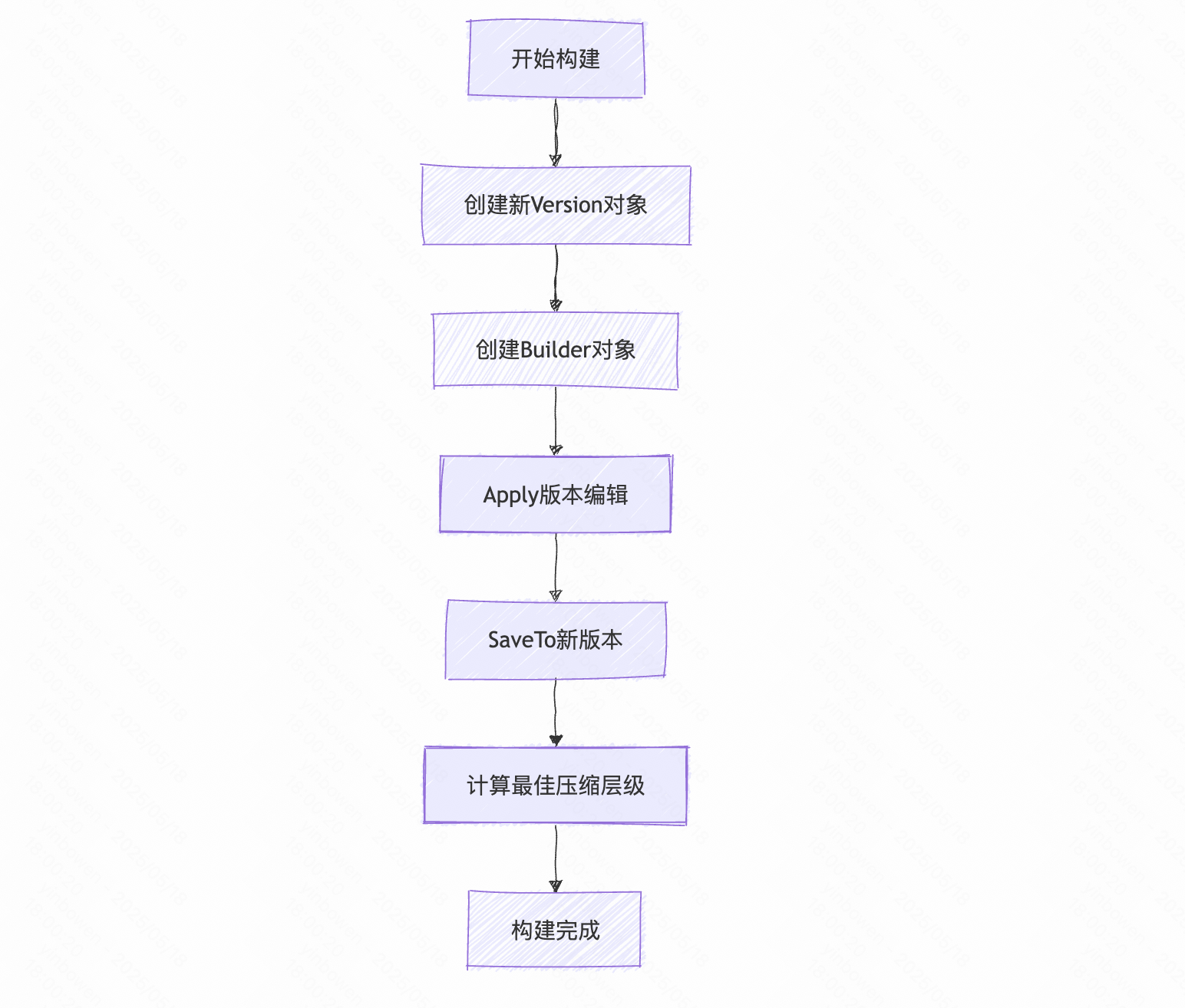
- 创建新版本 -亮点: 使用Builder模式来构建新版本
- Apply 方法 用于根据edit中的信息来生成对应的build构造器
- SaveTo 方法 用于将build构造器中的信息应用到新的version中
Version* v = new Version(this);{Builder builder(this, current_);builder.Apply(edit);builder.SaveTo(v);}// 计算 最佳压缩层级Finalize(v);
- MANIFEST处理阶段, 这里的MANIFEST
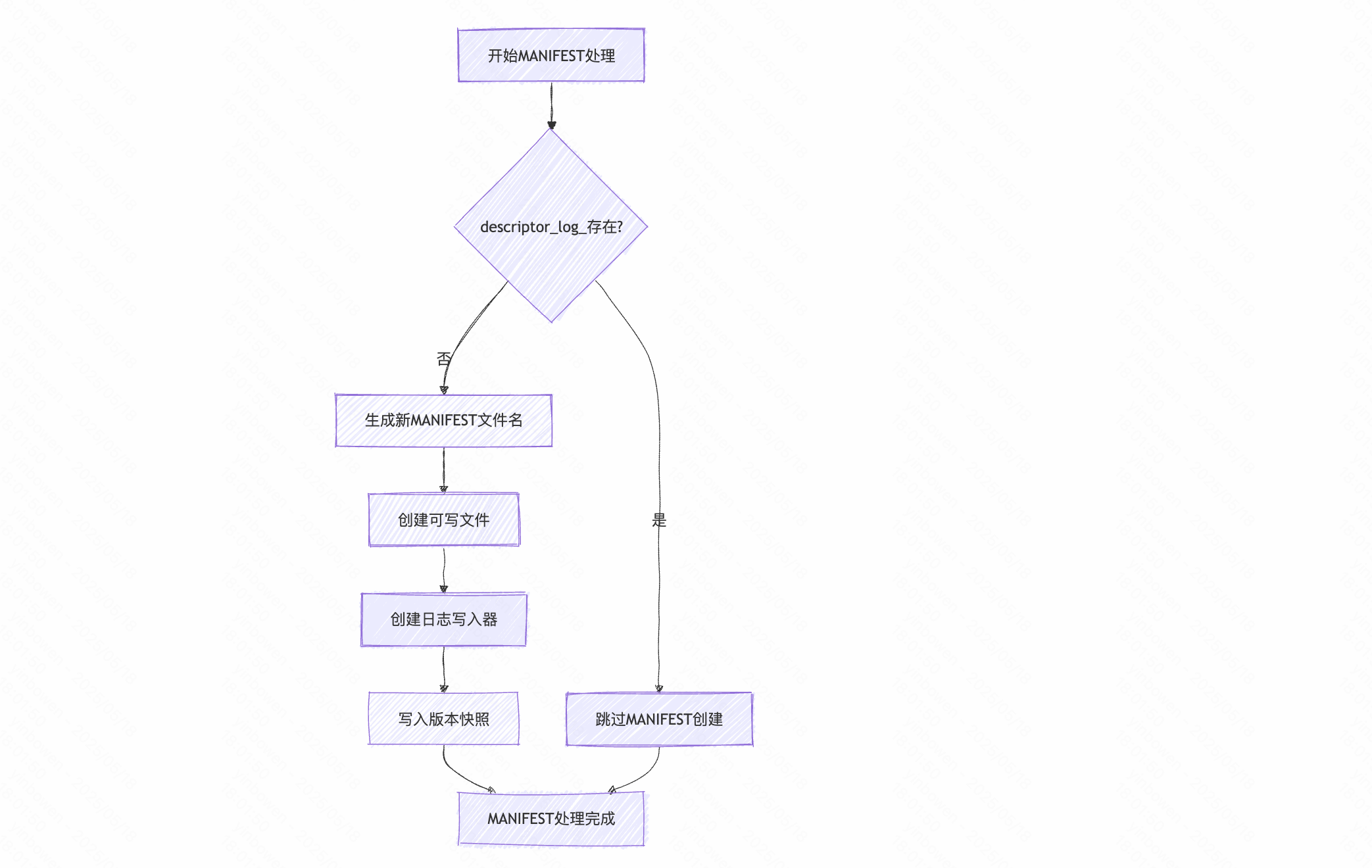
// MANIFEST 文件处理std::string new_manifest_file;Status s;if (descriptor_log_ == nullptr) {// 日志assert(descriptor_file_ == nullptr);// 底层文件操作new_manifest_file = DescriptorFileName(dbname_, manifest_file_number_);s = env_->NewWritableFile(new_manifest_file, &descriptor_file_);if (s.ok()) {descriptor_log_ = new log::Writer(descriptor_file_);// 写入快照-本质上是向 Manifest 日志中写入当前的文件状态,防止记录丢失s = WriteSnapshot(descriptor_log_);}}
- 文件同步阶段
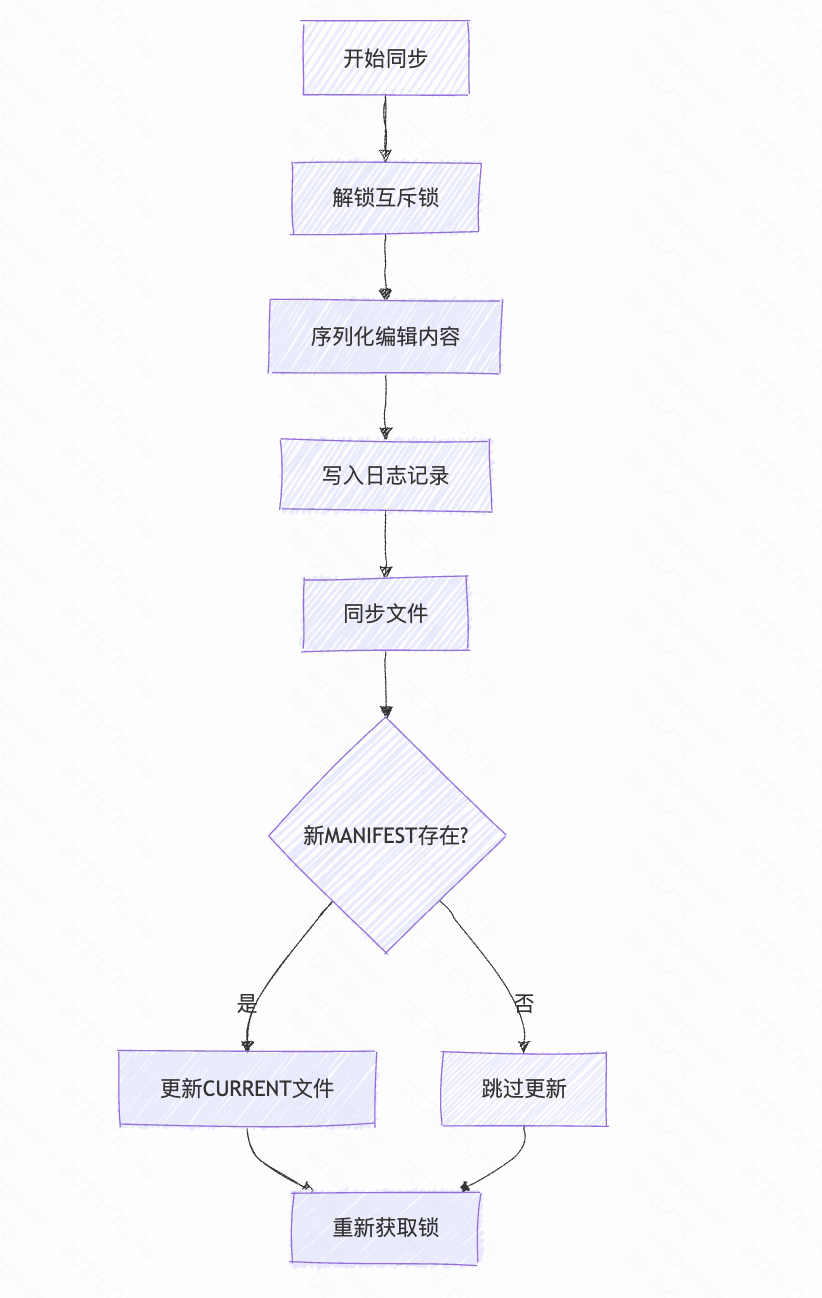
{mu->Unlock();if (s.ok()) {std::string record;edit->EncodeTo(&record);s = descriptor_log_->AddRecord(record);if (s.ok()) {s = descriptor_file_->Sync();}if (!s.ok()) {Log(options_->info_log, "MANIFEST write: %s\n", s.ToString().c_str());}}if (s.ok() && !new_manifest_file.empty()) {s = SetCurrentFile(env_, dbname_, manifest_file_number_);}// 重新获取锁mu->Lock();}
- 完成安装阶段
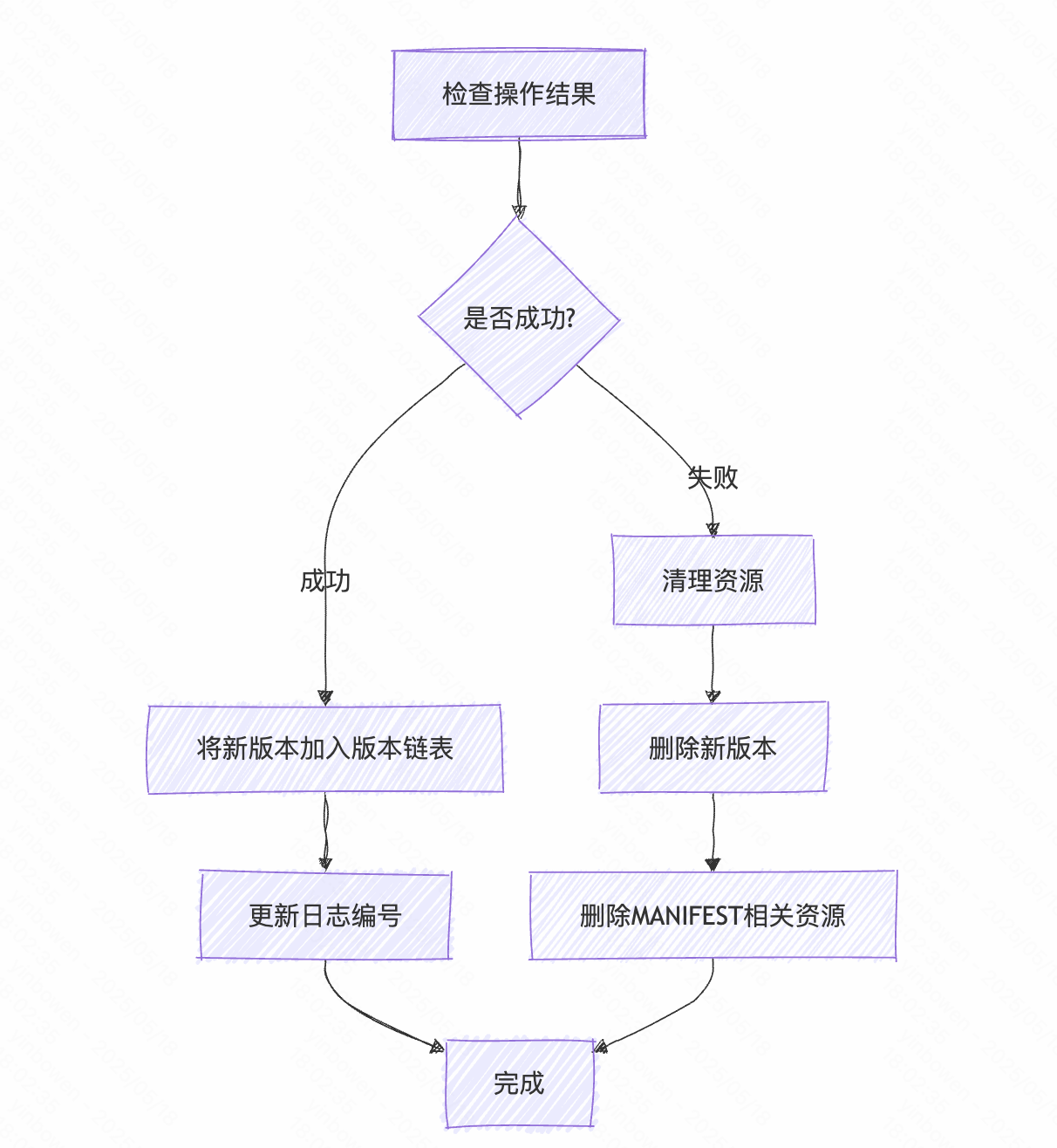
// 让基于VersionEdit和老版本if (s.ok()) {// 将新版本添加到版本链表AppendVersion(v);// 更新日志文件号log_number_ = edit->log_number_;prev_log_number_ = edit->prev_log_number_;} else {// 快照写入失败delete v;if (!new_manifest_file.empty()) {// 清理新创建的 MANIFEST 文件相关资源delete descriptor_log_;delete descriptor_file_;descriptor_log_ = nullptr;descriptor_file_ = nullptr;env_->RemoveFile(new_manifest_file);}}return s;
}
猜你喜欢
C++多线程: https://blog.csdn.net/luog_aiyu/article/details/145548529
一文了解LevelDB数据库读取流程:https://blog.csdn.net/luog_aiyu/article/details/145946636
一文了解LevelDB数据库写入流程:https://blog.csdn.net/luog_aiyu/article/details/145917173
关于LevelDB存储架构到底怎么设计的:https://blog.csdn.net/luog_aiyu/article/details/145965328?spm=1001.2014.3001.5502
PS
你的赞是我很大的鼓励
我是darkchink,一个计算机相关从业者&一个摩托佬&AI狂热爱好者
本职工作是某互联网公司数据相关工作,欢迎来聊,内推或者交换信息
vx 二维码见: https://www.cnblogs.com/DarkChink/p/18598402






集成开发环境,基于 VSCode + IoT Link 插件)







)




