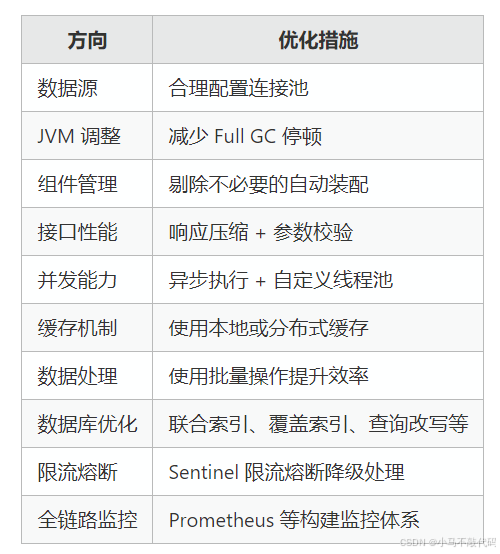
数据库连接池调优:精准匹配系统资源
症状:
默认配置下,连接池资源使用不当,高并发时连接耗尽或排队。
常见误区:
spring:datasource:hikari:maximum-pool-size: 1000 # 设置过大connection-timeout: 30000 # 设置过长
推荐配置:
spring:datasource:hikari:maximum-pool-size: ${CPU核心数 * 2}minimum-idle: 5connection-timeout: 3000max-lifetime: 1800000idle-timeout: 600000
根据硬件环境(如 CPU 核心数)合理配置连接池,避免资源浪费。
JVM 参数优化:降低 GC 停顿带来的抖动
建议启动参数:
java-Xms4g-Xmx4g\
-XX:NewRatio=1\
-XX:+UseG1GC\
-XX:MaxGCPauseMillis=200\
-XX:InitiatingHeapOccupancyPercent=35\
-XX:+AlwaysPreTouch
将新生代与老年代等比设置,使用 G1 收集器,最大暂停时间控制在 200ms 内。
精简自动装配:去除不必要的组件
示例:
@SpringBootApplication(exclude = {DataSourceAutoConfiguration.class,SecurityAutoConfiguration.class
})
屏蔽当前未使用的自动装配组件,有助于提升应用启动速度与资源占用效率。
启用响应压缩:减少传输体积,提升响应速度
server:compression:enabled: truemime-types: text/html,text/xml,text/plain,text/css,text/javascript,application/jsonmin-response-size: 1024
启用 Gzip 压缩功能,尤其对接口返回大量 JSON 数据的场景效果明显。
接口参数校验:防止资源被恶意占用
@GetMapping("/products")
public PageResult<Product> list(@RequestParam @Max(100) int pageSize,@RequestParam @Min(1) int pageNum) {// ...
}
通过注解式参数验证,及时阻断不合理请求,保护服务端资源。
异步执行任务:提升吞吐,释放主线程
@Async("taskExecutor")
public CompletableFuture<List<Order>> process() {return CompletableFuture.completedFuture(doHeavyWork());
}@Bean("taskExecutor")
public Executor taskExecutor() {ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();executor.setCorePoolSize(5);executor.setMaxPoolSize(10);executor.setQueueCapacity(500);return executor;
}
适用于非实时或耗时较长的处理流程。
缓存机制接入:减少重复查询压力
@Cacheable(cacheNames = "products", key = "#id", cacheManager = "caffeineCacheManager")
public Product getProductDetail(Long id) {return productDao.getById(id);
}
使用 Caffeine 或 Redis 缓存,可有效减轻数据库负担,提升接口响应速度。
批量操作替代单条处理:成倍提升写入效率
@Transactional
public void batchInsert(List<Product> products) {jdbcTemplate.batchUpdate("INSERT INTO product(name,price) VALUES(?,?)",products,500,(ps, product) -> {ps.setString(1, product.getName());ps.setBigDecimal(2, product.getPrice());});
}
将频繁的单条操作合并为批处理,减少数据库连接与事务开销。
深度优化 SQL 与索引:保障查询效率
场景问题:
SELECT * FROM products WHERE category = '手机' AND price > 5000 ORDER BY create_time DESC;
优化建议:
① 联合索引:
ALTER TABLE products ADD INDEX idx_category_price_create (category, price, create_time);
② 覆盖索引:
仅查询索引字段:
SELECT id, category, price, create_time FROM products WHERE category ='手机'AND price > 5000 ORDERBY create_time DESC;
③ 避免函数索引失效:
错误:
WHERE DATE(create_time) = '2023-01-01'
正确:
WHERE create_time BETWEEN '2023-01-01 00:00:00' AND '2023-01-01 23:59:59'
④ 监控与分析:
SELECT*FROM sys.schema_index_statistics WHERE table_name ='products';
使用 EXPLAIN FORMAT=JSON 分析执行计划。
自定义线程池:应对高并发的可控策略
@Bean("customPool")
public Executor customThreadPool() {return new ThreadPoolExecutor(10,50,60, TimeUnit.SECONDS,new LinkedBlockingQueue<>(1000),new CustomThreadFactory(),new ThreadPoolExecutor.CallerRunsPolicy());
}
杜绝默认线程池带来的资源不可控问题,自定义线程池策略更符合业务场景。
接口限流与熔断:抵御突发流量冲击
@SentinelResource(value = "orderQuery",blockHandler = "handleBlock",fallback = "handleFallback")
@GetMapping("/orders/{id}")
public Order getOrder(@PathVariable Long id) {return orderService.getById(id);
}public Order handleBlock(Long id, BlockException ex) {throw new RuntimeException("当前访问过多,请稍后再试");
}public Order handleFallback(Long id, Throwable t) {return Order.getDefaultOrder();
}
使用 Sentinel 实现服务保护机制,避免单点失控造成连锁故障。
全链路监控体系:问题诊断有据可依
management:endpoints:web:exposure:include: "*"metrics:export:prometheus:enabled: true
结合 Prometheus + Grafana 打造指标可视化平台,全面掌握系统运行状态。
总结
优化三大原则:
1、预防为主
写代码时就要考虑性能;
2、指标驱动
以数据为依据来做优化;
3、持续迭代
性能调优是长期过程。
推荐工具集:
1、Arthas:线上问题诊断
2、JProfiler:性能分析
3、Prometheus + Grafana:指标监控系统



原理与应用)




Java/python/JavaScript/C/C++/GO最佳实现)








--最简单的核函数)
)
