python 生成复杂表格,自动分页等功能
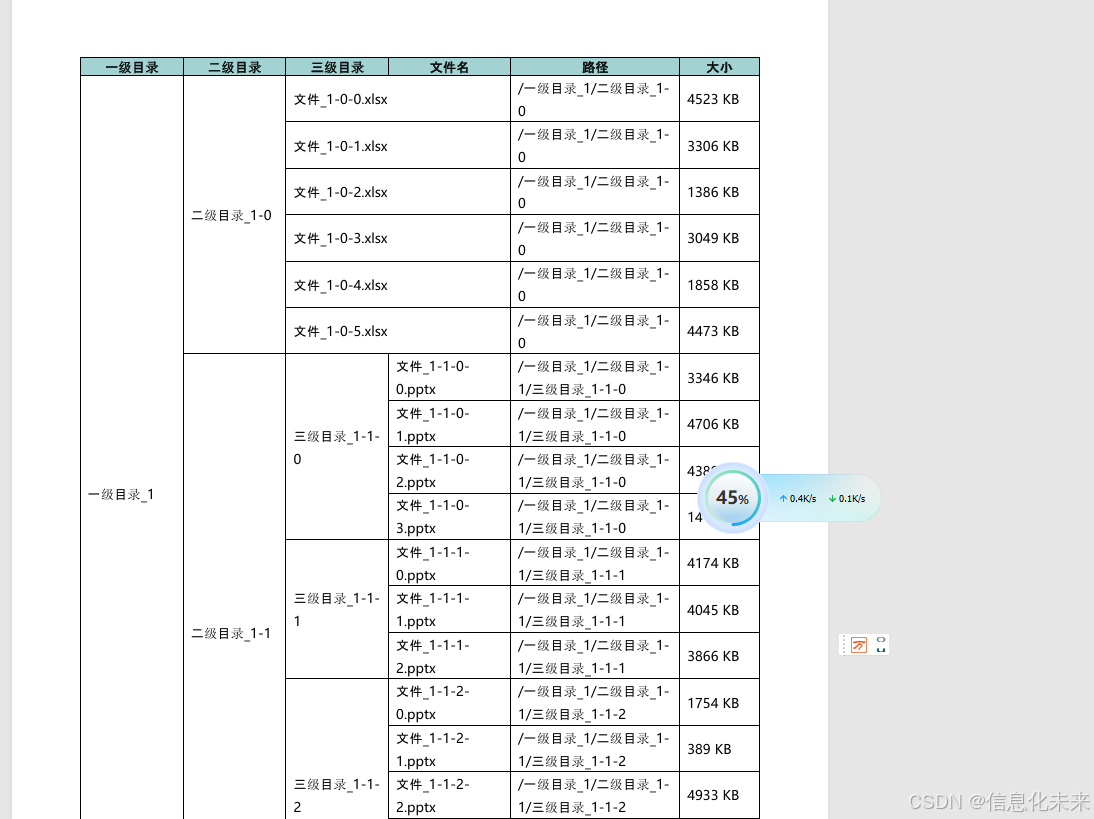
解决将Python中的树形目录数据转换为Word表格,并生成带有合并单元格的检测报告的问题。首先,要解决“tree目录数据”和“Word表格互换”,指将树形结构的数据转换成Word表格,并在转换过程中合并相应的单元格以反映层次结构。此外,还有自动分页和固定表头的问题,现在可能希望生成的报告能够自动处理这些格式问题。
首先,我需要明确树形目录数据的结构。通常,树形结构有父子节点关系,比如文件夹结构,每个节点可能有名称、类型、大小、修改日期等属性。希望将这些层次结构在Word表格中展示,通过合并单元格来表示父子关系,例如,一个父节点占据一行,其子节点在下方缩进显示,可能需要合并某些列来体现层级。
在Python中,处理树形结构通常使用递归。对于每个节点,可能需要确定其在表格中的行位置,并根据层级决定合并哪些单元格。例如,根节点可能需要合并所有列的一行,子节点可能只在第一列显示名称,后面的列合并或留空,或者根据具体需求调整。
生成Word文档需要使用python-docx库。该库允许创建表格、设置样式、合并单元格等操作。关键点是如何遍历树形数据并动态生成表格行,同时处理合并单元格的逻辑。可能需要为每个节点计算其在表格中的行数和列数,特别是当子节点存在时,父节点可能需要跨多行合并。
以下是试验代码
from docx import Document
from docx.shared import Pt, Cm
from docx.enum.table import WD_TABLE_ALIGNMENT
from docx.oxml.shared import OxmlElement, qn
import randomclass TreeNode:def __init__(self, name, depth=0, is_file=False, size=0, parent=None):self.name = nameself.depth = depthself.is_file = is_fileself.size = f"{size} KB" if is_file else ""self.parent = parentself.children = []self.start_row = 0self.end_row = 0self.col_span = 1 # 新增横向合并跨度class EnhancedDirectoryReport:def __init__(self, filename):self.doc = Document()self.filename = filenameself._setup_document()self.table = Noneself.current_row = 0self.column_map = ['一级目录', '二级目录', '三级目录', '文件名', '路径', '大小']self.current_table = Noneself.current_page_rows = 0self.max_page_rows = 35 # 根据实际内容调整每页行数self.active_directory = {} # 记录当前活跃的目录层级def _setup_document(self):section = self.doc.sections[0]margins = {'left': 2, 'right': 2, 'top': 2.5, 'bottom': 2.5}for attr, cm_val in margins.items():setattr(section, f"{attr}_margin", Cm(cm_val))style = self.doc.styles['Normal']style.font.name = '微软雅黑'style.font.size = Pt(10)def _create_new_page(self):"""创建新页面并初始化表格"""if self.current_table is not None:self.doc.add_page_break()self.current_table = self.doc.add_table(rows=0, cols=6)self.current_table.style = 'Table Grid'widths = [Cm(3.5), Cm(3.5), Cm(3.5), Cm(4), Cm(6), Cm(2.5)]for idx, w in enumerate(widths):self.current_table.columns[idx].width = wself._create_table_header()print('建表头后',self.current_row,self.current_page_rows)self.current_page_rows = 1 # 表头占1行# 重新应用活跃目录self._reapply_active_directory()def _reapply_active_directory(self):"""在新页重新应用当前活跃目录"""for depth in [1, 2, 3]:if depth in self.active_directory:node = self.active_directory[depth]self._add_directory_row(node, depth)def _add_directory_row(self, node, depth):"""添加目录行并更新活跃状态"""row = self.current_table.add_row()cells = row.cells# 填充目录信息cells[depth - 1].text = node.namecells[depth - 1].paragraphs[0].alignment = WD_TABLE_ALIGNMENT.LEFT# 设置跨列合并if depth == 1:cells[0].merge(cells[5])elif depth == 2:cells[1].merge(cells[5])elif depth == 3:cells[2].merge(cells[5])# 更新活跃目录self.active_directory[depth] = nodeself.current_page_rows += 1def _check_page_break(self):"""检查是否需要分页"""if self.current_page_rows >= self.max_page_rows:self._create_new_page()print('分页')def _add_file_row(self, node):"""添加文件行"""self._check_page_break()row = self.current_table.add_row()cells = row.cells# 填充文件信息cells[3].text = node.namecells[4].text = self._get_full_path(node)cells[5].text = node.size# 继承活跃目录for depth in [1, 2, 3]:if depth in self.active_directory:cells[depth - 1].text = self.active_directory[depth].namecells[depth - 1].paragraphs[0].alignment = WD_TABLE_ALIGNMENT.CENTERself.current_page_rows += 1def _get_full_path(self, node):path = []current = node.parentwhile current and current.depth > 0:path.insert(0, current.name)current = current.parentreturn '/' + '/'.join(path)def process_structure(self, root):"""处理目录结构"""self._create_new_page()stack = [(root, False)] # (node, visited)while stack:node, visited = stack.pop()if visited:# 后序遍历处理合并if not node.is_file:self._update_active_directory(node)continueif node.is_file:self._add_file_row(node)else:# 前序遍历添加目录self._check_page_break()self._add_directory_row(node, node.depth)stack.append((node, True))# 逆向添加子节点以保持顺序for child in reversed(node.children):stack.append((child, False))self.doc.save(self.filename)def _update_active_directory(self, node):"""更新活跃目录状态"""# 清除子目录状态for depth in list(self.active_directory.keys()):if depth > node.depth:del self.active_directory[depth]def _create_table_header(self):header = self.table.add_row()for idx, text in enumerate(self.column_map):cell = header.cells[idx]cell.text = textcell.paragraphs[0].runs[0].font.bold = Truecell.paragraphs[0].alignment = WD_TABLE_ALIGNMENT.CENTERself._set_cell_color(cell, 'A3D3D3')tr = header._trtrPr = tr.get_or_add_trPr()tblHeader = OxmlElement('w:tblHeader')tblHeader.set(qn('w:val'), "true")trPr.append(tblHeader)print(self.current_row)self.current_row += 1def _set_cell_color(self, cell, hex_color):shading = OxmlElement('w:shd')shading.set(qn('w:fill'), hex_color)cell._tc.get_or_add_tcPr().append(shading)def _smart_merge(self, node):"""智能合并策略核心方法"""# 垂直合并处理if node.depth <= 3 and not node.is_file:self._vertical_merge(node)# 横向合并处理if node.depth == 1 and not any(not c.is_file for c in node.children):self._horizontal_merge(node, 1, 3) # 一级目录合并到文件名列if node.depth == 2 and not any(not c.is_file for c in node.children):self._horizontal_merge(node, 2, 3) # 二级目录合并到文件名列def _horizontal_merge(self, node, start_col, end_col):"""安全横向合并方法"""for row_idx in range(node.start_row, node.end_row):# 获取需要合并的单元格print('nc ', row_idx, start_col, end_col)start_cell = self.table.cell(row_idx, start_col)end_cell = self.table.cell(row_idx, end_col)print(row_idx, start_col, end_col)print('开结',start_cell, end_cell)# 检查是否已经被合并if start_cell._element is end_cell._element:print('已合并过')continueelse:start_cell.merge(end_cell)def _vertical_merge(self, node):"""垂直方向合并"""if node.start_row >= node.end_row:returndepth_col_map = {1: 0, 2: 1, 3: 2}col_idx = depth_col_map.get(node.depth)if col_idx is not None:try:start_cell = self.table.cell(node.start_row, col_idx)end_cell = self.table.cell(node.end_row - 1, col_idx)start_cell.merge(end_cell)start_cell.text = node.nameexcept IndexError as e:print(f"垂直合并失败:{node.name}")raise edef _fill_row_data(self, node):"""填充数据并设置合并策略"""row = self.table.add_row()cells = row.cells# 文件信息if node.is_file:cells[3].text = node.namecells[4].text = self._get_full_path(node)cells[5].text = node.size# else:# # 设置目录层级# for d in range(1, 4):# print(d, cells[d])# print(node.name, node.depth)# if node.depth == d:# cells[d - 1].text = node.name# # if d < 3:# # cells[d].merge(cells[d])# 设置样式for cell in cells:cell.vertical_alignment = WD_TABLE_ALIGNMENT.CENTERself.current_row += 1return row# def _get_full_path(self, node):# path = []# current = node.parent# while current and current.depth > 0:# path.insert(0, current.name)# current = current.parent# return '/' + '/'.join(path) + ('' if node.is_file else f'/{node.name}')def _process_node(self, node):node.start_row = self.current_row#增限制,如为净空不加行if node.depth > 1 and node.is_file:self._fill_row_data(node)for child in node.children:self._process_node(child)node.end_row = self.current_rowself._smart_merge(node)def generate_report(self, root):self.table = self.doc.add_table(rows=0, cols=6)self.table.style = 'Table Grid'widths = [Cm(3.5), Cm(3.5), Cm(3.5), Cm(4), Cm(6), Cm(2.5)]for idx, w in enumerate(widths):self.table.columns[idx].width = w# self._create_table_header()self._create_new_page()self._process_node(root)print(self.doc.tables)self.doc.save(self.filename)# 测试数据生成器
class TestDataGenerator:@staticmethoddef create_large_structure():root = TreeNode("ROOT", depth=0)# 一级目录(10个)for i in range(1, 11):dir1 = TreeNode(f"一级目录_{i}", depth=1, parent=root)root.children.append(dir1)# 30%概率没有子目录if random.random() < 0.3:# 直接添加文件for j in range(random.randint(2, 5)):file = TreeNode(f"文件_{i}-{j}.docx", depth=4,is_file=True,size=random.randint(100, 5000),parent=dir1)dir1.children.append(file)continue# 二级目录(每个一级目录3-5个)for j in range(random.randint(3, 5)):dir2 = TreeNode(f"二级目录_{i}-{j}", depth=2, parent=dir1)dir1.children.append(dir2)# 50%概率没有三级目录if random.random() < 0.5:# 直接添加文件for k in range(random.randint(3, 6)):file = TreeNode(f"文件_{i}-{j}-{k}.xlsx", depth=4,is_file=True,size=random.randint(100, 5000),parent=dir2)dir2.children.append(file)continue# 三级目录(每个二级目录2-4个)for k in range(random.randint(2, 4)):dir3 = TreeNode(f"三级目录_{i}-{j}-{k}", depth=3, parent=dir2)dir2.children.append(dir3)# 添加文件for m in range(random.randint(3, 8)):file = TreeNode(f"文件_{i}-{j}-{k}-{m}.pptx", depth=4,is_file=True,size=random.randint(100, 5000),parent=dir3)dir3.children.append(file)return rootif __name__ == '__main__':# 生成测试数据data_generator = TestDataGenerator()root_node = data_generator.create_large_structure()# 生成报告report = EnhancedDirectoryReport("上下左右目录2.docx")report.generate_report(root_node)效果如图所示:
权威指南讲解MCU内存架构与如何查看编译器生成的地址具体位置)




:原理、架构与实战)


)








)

