一、引言
文末有彩蛋
在当今高并发、低延迟的应用场景中,传统的单级缓存策略往往难以满足性能需求。随着系统规模扩大,数据访问的瓶颈逐渐显现,如何高效管理缓存成为开发者面临的重大挑战。多级缓存架构应运而生,通过分层缓存设计(如本地缓存 + 分布式缓存 + 后端存储),显著减少网络开销、降低数据库压力,成为提升Java应用性能的“秘密武器”。
本文将深入剖析多级缓存的核心理念,结合Caffeine、Redis等主流技术栈,揭示其如何通过层级化设计、数据一致性策略和智能淘汰机制,实现吞吐量与响应时间的双重突破。无论是应对电商秒杀、实时推荐,还是高负载微服务,掌握多级缓存,意味着你的系统离“快人一步”更近一程。
二、从传统缓存到多级缓存
在深入探讨多级缓存之前,先来回顾一下传统缓存架构及其面临的挑战。传统的缓存策略通常是请求到达 Tomcat 后,先查询 Redis 缓存,如果未命中则查询数据库,其架构如下图所示:
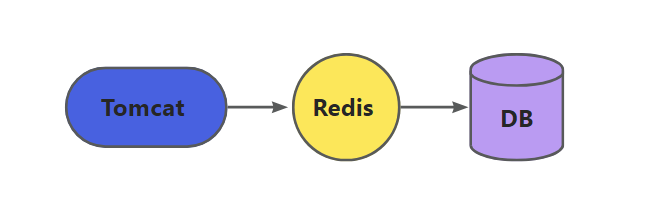
这种架构虽然简单直接,但在高并发场景下暴露出一些明显的问题:
- Tomcat 性能瓶颈:所有请求都要经过 Tomcat 处理,Tomcat 的性能成为整个系统的瓶颈。当并发请求量增大时,Tomcat 的线程池可能会被耗尽,导致请求处理延迟增加,甚至出现请求超时的情况。
- Redis 缓存失效冲击:当 Redis 缓存中的数据失效时,大量请求会直接穿透到数据库,对数据库产生巨大的冲击,可能导致数据库负载过高,甚至崩溃。这种现象被称为 “缓存雪崩”,是传统缓存架构中一个较为严重的问题。
为了解决传统缓存架构的问题,多级缓存应运而生。多级缓存的核心思想是充分利用请求处理的每个环节,分别添加缓存,从而减轻 Tomcat 的压力,提升服务性能。
在多级缓存架构中,请求的处理流程如下:
- 浏览器缓存:浏览器访问静态资源时,优先读取浏览器本地缓存。这可以大大减少对服务器的请求,提高页面的加载速度。例如,对于一些不经常更新的 CSS、JS 文件和图片,浏览器可以直接从本地缓存中读取,无需向服务器发送请求。
- Nginx 本地缓存:当请求到达 Nginx 后,优先读取 Nginx 本地缓存。如果 Nginx 本地缓存命中,则直接返回数据,无需经过 Tomcat 和 Redis。Nginx 本地缓存可以使用 Lua Shared Dict、Nginx Proxy Cache(磁盘 / 内存)、Local Redis 等实现,能够有效提升整体的吞吐量,降低后端压力,尤其在应对热点问题时非常有效。
- Redis 缓存:如果 Nginx 本地缓存未命中,则直接查询 Redis 缓存。Redis 作为分布式缓存,具有高并发、高性能的特点,能够存储大量的数据,并提供快速的数据访问能力。
- JVM 进程缓存:当 Redis 缓存也未命中时,请求进入 Tomcat,优先查询 JVM 进程缓存。JVM 进程缓存是基于本地内存的缓存,访问速度非常快,可以存储一些热点数据,减少对数据库的访问。
- 数据库查询:如果以上所有缓存都未命中,则只能查询数据库获取数据。在数据返回后,会异步将数据写到主 Redis 集群,并根据需要更新其他缓存。
通过这种多级缓存的方式,能够在不同层次上对请求进行拦截和处理,最大限度地减少对数据库的访问,提高系统的性能和响应速度。
三、多级缓存的架构与工作原理
3.1 多级缓存架构纵览
多级缓存架构是一个复杂而精妙的系统,它通常包含从客户端到数据层的多个层次,每个层次都承担着独特的角色和功能,共同协作以实现高效的数据访问和系统性能优化。
从最接近用户的客户端开始,客户端缓存主要负责存储用户设备上的临时数据,以减少对服务器的重复请求。在 Web 应用中,浏览器缓存就是一种典型的客户端缓存,它可以存储 HTML、CSS、JavaScript、图片等静态资源 。当用户再次访问相同的页面或资源时,浏览器首先检查本地缓存,如果缓存命中,就直接从本地加载资源,大大加快了页面的加载速度。
接着是应用层缓存,这一层主要包括 CDN(内容分发网络)缓存和 Nginx 缓存。CDN 缓存将静态资源缓存到离用户更近的节点,利用其分布式的服务器网络,根据用户的地理位置自动选择最优的节点提供服务,有效减少了网络延迟,提高了内容的传输速度。Nginx 缓存则可以在应用服务器前端对请求进行缓存处理,减轻后端服务器的负载,它既可以缓存静态资源,也可以根据配置缓存动态内容的响应结果。
再深入到服务层,这里存在多种类型的缓存。Nginx 本地缓存是 Nginx 自身提供的一种高效缓存机制,它基于内存或磁盘存储,可以快速响应频繁访问的数据请求。Redis 作为分布式缓存,在服务层中扮演着关键角色,它以其高性能、高并发的特性,广泛应用于存储热点数据。Redis 可以存储各种类型的数据结构,如字符串、哈希表、列表、集合等,满足不同业务场景的数据缓存需求。Tomcat 进程缓存则是基于应用服务器进程内的缓存,它利用 JVM 的内存空间,对一些频繁访问且变化较小的数据进行缓存,由于数据存储在内存中,访问速度极快,能够显著提升应用的响应性能。
最后是数据层缓存,数据库系统本身通常也具备缓存机制,例如 MySQL 的查询缓存、InnoDB 缓冲池等。这些缓存用于存储数据库查询结果、索引数据等,减少磁盘 I/O 操作,提高数据库的查询效率。在数据层缓存中,数据的存储和管理与数据库的底层架构紧密相关,通过合理配置缓存参数,可以优化数据库的性能表现。
3.2 各层缓存的工作方式
客户端缓存:以浏览器缓存为例,它的工作方式涉及强缓存和协商缓存两种机制。当浏览器第一次请求某个资源时,服务器会在响应头中返回一些缓存相关的信息,如 Cache-Control、Expires、Last-Modified、ETag 等字段。如果设置了强缓存,在缓存有效期内,浏览器再次请求该资源时,直接从本地缓存中读取,不会向服务器发送请求。例如,对于一些不经常更新的静态资源,如网站的图标、样式文件等,可以设置较长的缓存时间,通过 Cache-Control: max-age=31536000(一年的秒数)这样的配置,让浏览器在一年内都直接从缓存中读取这些资源,大大减少了网络请求。
应用层缓存:CDN 缓存的工作原理基于其分布式的节点网络。当用户请求一个通过 CDN 分发的静态资源时,首先,CDN 的智能 DNS 会根据用户的 IP 地址解析出离用户最近的 CDN 节点。然后,该节点会检查本地是否已经缓存了该资源。如果缓存命中,直接将资源返回给用户;如果未命中,CDN 节点会向源服务器请求资源,获取后将其缓存到本地,并返回给用户。例如,当用户访问一个图片资源时,CDN 会将该图片缓存到各个节点,下次附近的用户请求相同图片时,就可以从最近的 CDN 节点快速获取,减少了源服务器的压力和网络传输延迟 。
服务层缓存:Nginx 本地缓存可以使用 Lua Shared Dict、Nginx Proxy Cache(磁盘 / 内存)、Local Redis 等实现。以 Nginx Proxy Cache 为例,当请求到达 Nginx 时,Nginx 首先检查缓存中是否存在对应的响应。如果存在且缓存未过期,则直接返回缓存的内容给客户端;如果缓存未命中,则将请求转发到后端服务器,后端服务器处理请求并返回响应后,Nginx 会根据配置将响应内容缓存起来,以便下次相同请求可以直接从缓存中获取 。Redis 分布式缓存则通过集群部署的方式,提供高可用和高性能的数据存储服务。当应用程序请求数据时,首先根据一定的算法(如一致性哈希算法)计算出数据所在的 Redis 节点,然后向该节点发送请求。如果节点上缓存命中,直接返回数据;如果未命中,再根据业务逻辑决定是否从数据库中获取数据并更新到 Redis 缓存中。例如,在一个电商应用中,商品的基本信息、热门商品列表等数据可以存储在 Redis 中,通过设置合适的过期时间和缓存更新策略,保证数据的时效性和一致性 。
四、多级缓存的优势
多级缓存通过巧妙的架构设计,将不同类型的缓存有机结合,从而在性能、可用性和扩展性等多个关键方面展现出显著的优势,为现代高性能系统的构建提供了坚实的技术支撑。
4.1 性能提升
多级缓存对系统性能的提升是全方位且显著的。在高并发场景下,大量请求同时涌入,如果没有高效的缓存机制,数据库很容易成为性能瓶颈,导致系统响应缓慢甚至崩溃。而多级缓存的存在,就像是为系统搭建了多条快速通道。
从客户端缓存开始,浏览器缓存能够拦截大量对静态资源的重复请求,使得页面加载速度大幅提升。据统计,合理配置浏览器缓存后,静态资源的重复请求可减少约 70% - 80%,这意味着用户能够更快地看到页面内容,大大提升了用户体验。
应用层缓存如 CDN 缓存,通过将内容分发到离用户更近的节点,显著降低了网络延迟。在一个面向全球用户的视频平台中,使用 CDN 缓存后,视频加载的平均延迟从原来的 5 秒降低到了 1 - 2 秒,视频播放的卡顿现象也大幅减少。Nginx 缓存则在应用服务器前端对请求进行快速处理,减轻了后端服务器的负载,提升了整体的吞吐量。
服务层缓存更是发挥了关键作用。Redis 分布式缓存以其高并发、低延迟的特性,能够快速响应大量的读请求。在一个电商促销活动中,Redis 缓存成功应对了每秒数十万次的商品信息查询请求,确保了活动的顺利进行。而 Tomcat 进程缓存利用 JVM 内存,对热点数据进行快速访问,进一步减少了请求处理时间。在一些实时性要求较高的业务场景,如股票交易系统,Tomcat 进程缓存能够在毫秒级的时间内返回数据,满足了业务对实时性的严格要求。
4.2 可用性增强
多级缓存架构在提升系统可用性方面也有着出色的表现。由于缓存分布在多个层次,每个层次都可以作为数据的备份来源,从而降低了单点故障的风险。
即使某个缓存层出现故障,系统仍然可以从其他缓存层获取数据,保证服务的连续性。以电商平台为例,假设 Redis 缓存集群中的某个节点出现故障,由于 Nginx 本地缓存和 Tomcat 进程缓存中可能还存在部分热点数据,这些缓存可以继续为用户提供服务,用户在访问商品信息、下单等操作时,基本不会受到影响。直到 Redis 缓存节点恢复正常或者数据从数据库重新加载到缓存中,系统始终能够保持一定的服务能力,大大提高了系统的容错性和可用性。
4.3 扩展性提高
随着业务的不断发展和用户量的增长,系统的扩展性成为了一个重要的考量因素。多级缓存架构具有良好的扩展性,能够轻松应对业务增长带来的挑战。
在分布式缓存层面,以 Redis 为例,通过集群部署和数据分片技术,可以方便地添加节点来扩展缓存容量和吞吐量。当电商平台的业务量翻倍时,只需要在 Redis 集群中添加新的节点,就可以轻松应对增加的缓存需求。同时,多级缓存架构还可以根据业务需求灵活调整缓存层次和策略。例如,当业务对某些特定类型的数据访问频率大幅增加时,可以在应用层或服务层增加专门的缓存层次,对这些数据进行更高效的缓存和管理,从而满足业务的动态变化需求,确保系统始终能够高效运行。
五、多级缓存的实现方式
5.1 浏览器缓存的实现
在 Java Web 应用中,开启浏览器缓存主要是通过设置 HttpServletResponse 的响应头来实现的。下面是一些关键的响应头字段及其作用:
- Cache-Control:这是一个非常重要的字段,用于指定缓存策略。例如,设置Cache-Control: max-age=31536000,表示该资源在浏览器缓存中可以保存一年(31536000 秒),在这期间,浏览器再次请求该资源时,如果缓存未过期,就直接从本地缓存读取,不会向服务器发送请求 。还可以设置Cache-Control: no-cache,表示资源不能被缓存,每次都需要向服务器验证资源是否有更新;Cache-Control: no-store,表示禁止缓存,不允许浏览器和中间缓存存储该资源。
- Expires:指定资源过期的具体时间点,是一个 HTTP 1.0 的字段。例如,Expires: Thu, 15 Apr 2024 20:00:00 GMT,表示该资源在这个时间点之后过期。不过,由于它是基于服务器时间的,存在一定的局限性,现在更多地使用 Cache-Control 字段。
- ETag:实体标签,是资源的唯一标识。服务器会为每个资源生成一个 ETag 值,当浏览器再次请求该资源时,会带上 If-None-Match 头,其值为之前获取的 ETag。服务器通过比较客户端传来的 ETag 和当前资源的 ETag,如果一致,说明资源未更新,返回 304 状态码,浏览器直接从缓存中读取资源;如果不一致,说明资源已更新,返回 200 状态码和新的资源内容。
- Last-Modified:表示资源的最后修改时间。浏览器请求资源时,会带上 If-Modified-Since 头,其值为之前获取的 Last-Modified 时间。服务器比较客户端传来的时间和当前资源的最后修改时间,如果资源未修改,返回 304 状态码;如果已修改,返回 200 状态码和新的资源内容。
在 Java 代码中,可以这样设置响应头来开启浏览器缓存:
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.util.Date;public class CacheServlet extends HttpServlet {@Overrideprotected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {// 设置Cache-Control头,缓存1小时response.setHeader("Cache-Control", "max-age=3600");// 设置Expires头,1小时后过期Date expirationDate = new Date(System.currentTimeMillis() + 3600 * 1000);response.setDateHeader("Expires", expirationDate.getTime());// 设置ETag头,这里简单模拟一个ETag值response.setHeader("ETag", "123456");// 设置Last-Modified头,这里简单模拟一个最后修改时间Date lastModifiedDate = new Date();response.setDateHeader("Last-Modified", lastModifiedDate.getTime());// 处理请求并返回响应// ...}
}5.2 Nginx 缓存的开启
在 Nginx 中开启缓存需要进行以下几个步骤的配置:
1. 定义缓存配置:在 Nginx 的 http 块中定义缓存路径、共享内存区域、缓存有效期等参数。例如:
http {proxy_cache_path /data/nginx/cache levels=1:2 keys_zone=my_cache:10m inactive=60m max_size=1g use_temp_path=off;# /data/nginx/cache 是缓存文件存储路径,确保Nginx有写入权限# levels=1:2 表示缓存文件目录层级结构为2层,可提高文件访问效率# keys_zone=my_cache:10m 定义一个名为my_cache的共享内存区域,大小为10m,用于存储缓存键值对# inactive=60m 表示缓存项在60分钟内未被访问则视为过期# max_size=1g 表示缓存总大小限制为1g,超过会按LRU算法删除旧缓存项# use_temp_path=off 表示不使用临时存储区域,避免不必要的文件复制
}2. 启用缓存:在 server 块或 location 块中启用缓存,并指定使用的缓存配置。例如:
server {location / {proxy_cache my_cache;proxy_pass http://backend_server;}
}这里proxy_cache my_cache表示启用名为 my_cache 的缓存配置,proxy_pass http://backend_server指定请求转发的后端服务器地址。
3. 设置缓存有效期:可以根据不同的 HTTP 状态码设置缓存的有效时间。例如:
location / {proxy_cache my_cache;proxy_pass http://backend_server;proxy_cache_valid 200 302 60m;proxy_cache_valid 404 10m;
}上述配置表示对于 HTTP 200 和 302 状态码的响应,缓存 60 分钟;对于 HTTP 404 状态码的响应,缓存 10 分钟。
4. 配置反向代理:确保反向代理配置正确,将请求转发到后端服务器,并正确处理缓存命中和未命中的情况。例如:
location / {proxy_cache my_cache;proxy_pass http://backend_server;proxy_cache_bypass $http_pragma $http_authorization;proxy_cache_revalidate on;proxy_cache_min_uses 3;proxy_cache_lock on;
}- proxy_cache_bypass $http_pragma $http_authorization:表示当请求头中包含pragma或authorization时,绕过缓存,直接请求后端服务器。
- proxy_cache_revalidate on:启用缓存响应的重新验证,使用条件请求向源服务器发送 GET 请求,减少数据传输。
- proxy_cache_min_uses 3:表示缓存被使用的最小次数为 3 次,低于此次数的缓存,在缓存空间达到上限时会被删除。
- proxy_cache_lock on:当多个请求都未找到相应缓存时,按时间顺序依次向源服务器请求资源,防止多个请求同时更新缓存。
5. 重新加载配置:完成配置后,重新加载 Nginx 配置,使新配置生效。可以使用以下命令:
sudo systemctl reload nginx5.3 本地缓存与分布式缓存结合
在 Java 应用中,结合本地缓存与分布式缓存可以充分发挥两者的优势。以 Caffeine 实现本地缓存、Redis 实现分布式缓存为例,下面是一个简单的实现思路和代码示例:
1. 引入依赖:在 Maven 项目中,添加 Caffeine 和 Redis 相关依赖:
<dependency><groupId>com.github.ben-manes.caffeine</groupId><artifactId>caffeine</artifactId><version>3.1.6</version>
</dependency>
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>2. 配置 Caffeine 本地缓存:在 Spring Boot 应用中,可以通过配置类来创建 Caffeine 缓存管理器:
import com.github.benmanes.caffeine.cache.Caffeine;
import org.springframework.cache.CacheManager;
import org.springframework.cache.caffeine.CaffeineCacheManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.concurrent.TimeUnit;@Configuration
public class CacheConfig {@Beanpublic CacheManager caffeineCacheManager() {CaffeineCacheManager cacheManager = new CaffeineCacheManager("myLocalCache");cacheManager.setCaffeine(Caffeine.newBuilder().expireAfterWrite(10, TimeUnit.MINUTES) // 缓存10分钟后过期.initialCapacity(100) // 初始容量.maximumSize(200)); // 最大缓存条目return cacheManager;}
}3. 配置 Redis 分布式缓存:在 Spring Boot 应用中,配置 Redis 连接信息,例如在application.properties文件中:
spring.redis.host=127.0.0.1
spring.redis.port=63794. 结合使用本地缓存和分布式缓存:在服务层代码中,先从本地缓存中获取数据,如果未命中,再从分布式缓存中获取,若仍未命中,则查询数据库并更新缓存。示例代码如下:
import com.github.benmanes.caffeine.cache.Cache;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.ReentrantLock;@Service
public class DataService {@Autowiredprivate Cache<String, Object> caffeineCache;@Autowiredprivate RedisTemplate<String, Object> redisTemplate;private final ReentrantLock lock = new ReentrantLock();public Object getData(String key) {// 先从本地缓存获取Object data = caffeineCache.getIfPresent(key);if (data != null) {return data;}// 本地缓存未命中,从Redis获取data = redisTemplate.opsForValue().get(key);if (data != null) {// 将数据存入本地缓存caffeineCache.put(key, data);return data;}// Redis缓存也未命中,查询数据库(这里模拟查询数据库的方法)lock.lock();try {data = queryFromDatabase(key);if (data != null) {// 将数据存入Redis和本地缓存redisTemplate.opsForValue().set(key, data, 60, TimeUnit.MINUTES);caffeineCache.put(key, data);}} finally {lock.unlock();}return data;}private Object queryFromDatabase(String key) {// 模拟从数据库查询数据return "data from database for key: " + key;}
}通过上述配置和代码,实现了本地缓存与分布式缓存的结合,在提高数据访问速度的同时,也兼顾了分布式环境下的数据一致性和扩展性。
六、多级缓存的应用场景与案例分析
6.1 电商场景下的多级缓存应用
在电商系统中,多级缓存发挥着至关重要的作用,显著提升了系统性能和用户体验。以商品详情页为例,这是用户获取商品详细信息的关键页面,承载着大量的流量和订单转化。在高并发的购物节期间,如 “双十一”,商品详情页的访问量会呈指数级增长。
通过多级缓存架构,当用户请求商品详情页时,首先会检查浏览器缓存。如果用户之前访问过该页面,且缓存未过期,浏览器会直接从本地缓存中加载页面,这大大加快了页面的加载速度,减少了用户等待时间。据统计,在电商平台中,约 30% - 40% 的商品详情页请求可以通过浏览器缓存直接处理 。
若浏览器缓存未命中,请求会到达 Nginx。Nginx 本地缓存会尝试处理该请求。在电商场景中,Nginx 本地缓存可以存储热门商品的详情数据,如苹果手机、小米家电等热门商品。由于这些商品的访问频率极高,Nginx 本地缓存能够有效拦截大量请求。以某大型电商平台为例,在促销活动期间,Nginx 本地缓存的命中率可达 20% - 30%,大大减轻了后端服务器的压力 。
如果 Nginx 本地缓存也未命中,请求会继续查询 Redis 分布式缓存。Redis 中存储着商品的详细信息、价格、库存等数据。在电商系统中,Redis 缓存的高并发读写能力能够应对大量的商品查询请求。例如,在 “双十一” 期间,某电商平台的 Redis 缓存每秒能够处理数十万次的商品查询请求,确保了系统的稳定运行 。
当 Redis 缓存未命中时,请求会进入 Tomcat,查询 JVM 进程缓存。JVM 进程缓存可以存储一些热点数据,如热门商品的实时销量、最新的促销信息等。这些数据的更新频率较高,但由于存储在 JVM 内存中,访问速度极快。在电商场景中,JVM 进程缓存能够在毫秒级的时间内返回数据,满足了业务对实时性的要求 。
若 JVM 进程缓存也未命中,才会查询数据库获取数据。在数据返回后,会异步将数据写到主 Redis 集群,并根据需要更新其他缓存。通过这样的多级缓存机制,电商系统在高并发场景下能够快速响应用户请求,提高了用户的购物体验,同时也降低了数据库的负载,确保了系统的稳定性和可靠性。
6.2 内容管理系统中的实践
在内容管理系统(CMS)中,多级缓存同样是提升系统性能和用户体验的关键技术。以一个新闻资讯类的内容管理系统为例,系统需要处理大量的文章发布、编辑和浏览请求。
当用户请求浏览一篇新闻文章时,首先会经过浏览器缓存。如果用户之前访问过该文章,且缓存未过期,浏览器会直接从本地缓存中加载文章内容,这大大提高了页面的加载速度。对于新闻资讯类网站来说,用户通常会在短时间内多次访问同一篇热门文章,浏览器缓存能够有效减少重复请求,提高用户体验。
若浏览器缓存未命中,请求会到达 Nginx。Nginx 本地缓存可以存储热门文章的内容和相关元数据。在内容管理系统中,一些热点新闻的访问量会非常大,Nginx 本地缓存能够拦截这些高频请求,减轻后端服务器的压力。例如,在某重大事件发生时,相关新闻文章的访问量会瞬间飙升,Nginx 本地缓存能够快速响应这些请求,确保用户能够及时获取新闻内容 。
如果 Nginx 本地缓存也未命中,请求会查询 Redis 分布式缓存。Redis 中存储着文章的详细内容、作者信息、发布时间等数据。在内容管理系统中,Redis 缓存的高可用性和高性能能够保证文章数据的快速读取。通过合理设置缓存过期时间和更新策略,能够确保用户获取到的文章内容是最新的 。
当 Redis 缓存未命中时,请求会进入 Tomcat,查询 JVM 进程缓存。JVM 进程缓存可以存储一些热点文章的摘要、推荐阅读列表等数据。这些数据的更新频率相对较低,但访问速度要求较高。在内容管理系统中,JVM 进程缓存能够快速返回这些数据,提高了页面的加载速度 。
若 JVM 进程缓存也未命中,才会查询数据库获取数据。在数据返回后,会异步将数据写到主 Redis 集群,并根据需要更新其他缓存。通过这样的多级缓存机制,内容管理系统能够快速响应大量的文章浏览请求,提高了系统的吞吐量和用户满意度,同时也降低了数据库的负载,保障了系统的稳定运行。
七、总结
多级缓存作为提升系统性能的关键技术,在现代软件开发中扮演着不可或缺的角色。它通过在不同层次设置缓存,有效减少了数据访问的延迟,显著提升了系统的响应速度和吞吐量,增强了系统的可用性和扩展性,为用户带来了更流畅、高效的体验。
在实际项目中,应根据业务需求和系统架构的特点,精心设计和合理配置多级缓存。充分发挥浏览器缓存、Nginx 缓存、Redis 缓存、JVM 进程缓存等各层缓存的优势,构建一个高效、稳定的缓存体系。同时,要关注缓存的更新策略、数据一致性等问题,确保缓存中的数据始终准确、有效。
展望未来,随着技术的不断进步,缓存技术也将迎来新的发展。一方面,缓存的性能和容量将不断提升,以满足日益增长的大数据量和高并发访问的需求。例如,新型的内存缓存技术可能会进一步提高数据的读写速度,分布式缓存系统也将在数据一致性和故障恢复方面取得更大的突破。另一方面,智能缓存技术将逐渐成为研究和应用的热点。通过机器学习和人工智能算法,缓存系统能够自动根据数据的访问模式和业务需求,动态调整缓存策略,实现更精准的缓存管理,进一步提升系统性能。
希望读者能够在自己的项目中积极应用多级缓存技术,不断探索和优化缓存策略,让系统性能得到质的飞跃。如果你在实践过程中有任何问题或心得,欢迎在评论区留言分享,让我们共同学习,共同进步。
彩蛋:最近整理了各板块和大厂的面试题以及简历模板(不同年限的都有),涵盖高并发,分布式等面试热点问题,足足有大几百页,需要的可以联系(v:bxlj_jcj),备注面试





)

)




Java常用类库)



如何使用UNSIGNED属性?)


