一、 消息队列
1. 什么是消息队列
消息(Message)是指在应用间传送的数据。消息可以非常简单,比如只包含文本字符串,也可以更复杂,可能包含嵌入对象。消息队列(Message Queue)是一种应用间的通信方式,消息发送后可以立即返回,由消息系统来确保消息的可靠传递。消息发布者只管把消息发布到MQ中而不用管谁来取,消息使用者只管从 MQ中取消息而不管是谁发布的。这样发布者和使用者都不用知道对方的存在。
2. 消息队列的特征
(1) 存储
与依赖于使用套接字的基本 TCP和 UDP 协议的传统请求和响应系统不同,消息队列通常将消息存储在某种类型的缓冲区中,直到目标进程读取这些消息或将其从消息队列中显式移除为止。
(2) 异步
与请求和响应系统不同,消息队列通过缓冲消息可以在应用程序中实现一定程度的异步性,允许源进程发送消息并在队列中累积消息,而目标进程则可以挑选消息进行处理。 这样,应用程序就可以在某些故障情况下运行,例如连接断断续续或源进程或目标进程故障。路由:消息队列还可以提供路由功能,其中多个进程可以在同一队列中读取或写入消息,从而实现广播或单播通信模式。
3. 为什么需要消息队列
(1)解耦
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
(2) 冗余
消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的"插入-获取-删除"范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。
(3) 扩展性
因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。
(4) 灵活性&峰值处理能力
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
(5) 可恢复性
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
(6) 顺序保证
在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。(Kafka保证一个Partition 内的消息的有序性)
(7) 缓冲
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
(8) 异步通信
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
二、 Kafka基础与入门
1. Kafka 基本概念
Kafka 是一种高吞吐量的分布式发布/订阅消息系统,这是官方对 kafka 的定义kafka 是 Apache 组织下的一个开源系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于 hadoop 平台的数据分析、低时延的实时系统、storm/spark 流式处理引擎等。kafka现在已被多家大型公司作为多种类型的数据管道和消息系统使用。
2. Kafka 相关术语
kafka 的一些核心概念和角色
- Broker:Kafka 集群包含一个或多个服务器,每个服务器被称为 broker(经纪人)。Topic:每条发布到 Kafka 集群的消息都有一个分类,这个类别被称为 Topic(主题)。
- Producer:指消息的生产者,负责发布消息到kafka broker。
- Consumer:指消息的消费者,从kafka broker 拉取数据,并消费这些已发布的消息。
- Partition: Partition 是物理上的概念,每个 Topic 包含一个或多个 Partition,每个 partition 都是一个有序的队列。partition 中的每条消息都会被分配一个有序的 id(offset)。
- Consumer Group:消费者组,可以给每个Consumer 指定消费组,若不指定消费者组,则属于默认的 group。
- Message:消息,通信的基本单位,每个producer 可以向一个 topic 发布一些消息。
5. Producer 生产机制
Producer 是消息和数据的生产者,它发送消息到broker 时,会根据Paritition 机制选择将其存储到哪一个 Partition。如果 Partition 机制设置的合理,所有消息都可以均匀分布到不同的 Partition 里,这样就实现了数据的负载均衡。如果一个 Topic 对应一个文件,那这个文件所在的机器 I/0 将会成为这个 Topic 的性能瓶颈,而有了 Partition 后,不同的消息可以并行写入不同broker 的不同 Partition 里,极大的提高了吞吐率。
6. Consumer消费机制
Kafka 发布消息通常有两种模式:队列模式(queuing)和发布/订阅模式(publish-subscribe)。在队列模式下,只有一个消费组,而这个消费组有多个消费者,一条消息只能被这个消费组中的一个消费者所消费;而在发布/订阅模式下,可有多个消费组,每个消费组只有一个消费者,同一条消息可被多个消费组消费。
Kafka 中的 Producer 和 consumer 采用的是 push、pull 的模式,即 producer 向broker 进行 push 消息,comsumer 从 bork 进行 pul1 消息,push 和 pu11 对于消息的生产和消费是异步进行的。pul1模式的一个好处是consumer 可自主控制消费消息的速率,同时consumer 还可以自己控制消费消息的方式是批量的从broker 拉取数据还是逐条消费数据。
三、 Zookeeper概念介绍
ZooKeeper是一种分布式协调技术,所谓分布式协调技术主要是用来解决分布式环境当中多个进程之间的同步控制,让他们有序的去访问某种共享资源,防止造成资源竞争(脑裂)的后果。脑裂是指在主备切换时,由于切换不彻底或其他原因,导致客户端和 Slave 误以为出现两个 activemaster,最终使得整个集群处于混乱状态
1. zookeeper应用举例
(1) 什么是单点故障问题呢?
所谓单点故障,就是在一个主从的分布式系统中,主节点负责任务调度分发,从节点负责任务的处理,而当主节点发生故障时,整个应用系统也就瘫痪了,那么这种故障就称为单点故障。那我们的解决方法就是通过对集群 master 角色的选取,来解决分布式系统单点故障的问题。
(2) 传统的方式是怎么解决单点故障的?以及有哪些缺点呢?
传统的方式是采用一个备用节点,这个备用节点定期向主节点发送 ping 包,主节点收到 ping 包以后向备用节点发送回复 Ack 信息,当备用节点收到回复的时候就会认为当前主节点运行正常,让它继续提供服务。而当主节点故障时,备用节点就无法收到回复信息了,此时,备用节点就认为主节点宕机,然后接替它成为新的主节点继续提供服务。
这种传统解决单点故障的方法,虽然在一定程度上解决了问题,但是有一个隐患,就是网络问题,可能会存在这样一种情况:主节点并没有出现故障,只是在回复 ack 响应的时候网络发生了故障,这样备用节点就无法收到回复,那么它就会认为主节点出现了故障,接着,备用节点将接管主节点的服务,并成为新的主节点,此时,分布式系统中就出现了两个主节点(双Master 节点)的情况,双 Master 节点的出现,会导致分布式系统的服务发生混乱。这样的话,整个分布式系统将变得不可用。为了防止出现这种情况,就需要引入 ZooKeeper 来解决这种问题。
2. zookeeper的工作原理是什么?
(1) master 启动
在分布式系统中引入 Zookeeper 以后,就可以配置多个主节点,这里以配置两个主节点为例,假定它们是主节点A和主节点B,当两个主节点都启动后,它们都会向 ZooKeeper 中注册节点信息。我们假设主节点A注册的节点信息是master00001,主节点B注册的节点信息是 master00002 ,注册完以后会进行选举,选举有多种算法,这里以编号最小作为选举算法为例,编号最小的节点将在选举中获胜并获得锁成为主节点,也就是主节点A将会获得锁成为主节点,然后主节点B将被阻塞成为一个各用节点。这样,通过这种方式 Zookeeper 就完成了对两个 Master 进程的调度。完成了主、备节点的分配和协作
(2) master 故障
如果主节点A 发生了故障,这时候它在 ZooKeeper 所注册的节点信息会被自动删除,而 ZooKeeper 会自动感知节点的变化,发现主节点A故障后,会再次发出选举,这时候 主节点B 将在选举中获胜,替代主节点A 成为新的主节点,这样就完成了主、被节点的重新选举。
(3) master 恢复
如果主节点恢复了,它会再次向 ZooKeeper 注册自身的节点信息,只不过这时候它注册的节点信息将会变成 master00003,而不是原来的信息。ZooKeeper会感知节点的变化再次发动选举,这时候,主节点B在选举中会再次获胜继续担任主节点,主节点A 会担任备用节点。
zookeeper 就是通过这样的协调、调度机制如此反复的对集群进行管理和状态同步的。
3. zookeeper 集群架构
zookeeper 一般是通过集群架构来提供服务的,下图是 zookeeper 的基本架构图。
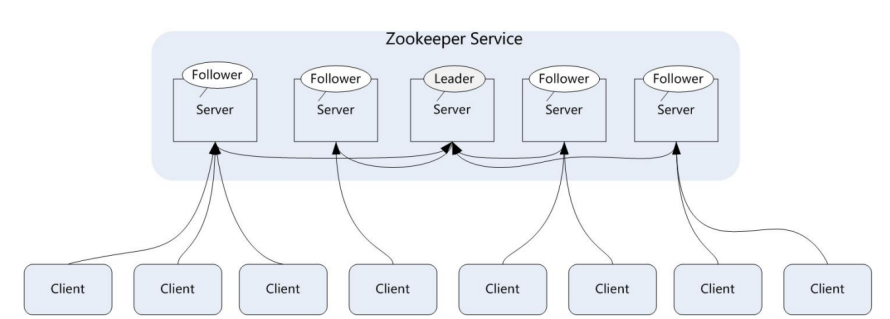
zookeeper 集群主要角色有 server 和 client,其中 server 又分为 leader、follower 和 observer 三个角色,每个角色的含义如下:
- Leader:领导者角色,主要负责投票的发起和决议,以及更新系统状态。follower:跟随着角色,用于接收客户端的请求并返回结果给客户端,在选举过程中参与投票。
- observer:观察者角色,用户接收客户端的请求,并将写请求转发给leader,同时同步 1eader 状态,但是不参与投票。0bserver 目的是扩展系统,提高伸缩性。
- client:客户端角色,用于向zookeeper 发起请求。
4. zookeeper的工作流程
Zookeeper 修改数据的流程: Zookeeper 集群中每个 Server 在内存中存储了一份数据,在 Zookeeper 启动时,将从实例中选举一个 Server 作为 leader,Leader 负责处理数据更新等操作,当且仅当大多数 Server 在内存中成功修改数据,才认为数据修改成功。
Zookeeper 写的流程为:客户端 Client 首先和一个 Server 或者 0bserve 通信,发起写请求,然后 Server 将写请求转发给Leader,Leader 再将写请求转发给其它 Server,其它 Server 在接收到写请求后写入数据并响应 Leader,Leader在接收到大多数写成功回应后,认为数据写成功,最后响应C1ient,完成一次写操作过程。
五、 单节点部署Kafka
1. 安装 Zookeeper
先安装java
[root@localhost ~]# dnf -y install java[root@localhost ~]# ls anaconda-ks.cfg apache-zookeeper-3.6.0-bin.tar.gz kafka_2.13-2.4.1.tgz[root@localhost ~]# tar zxvf apache-zookeeper-3.6.0-bin.tar.gz [root@localhost ~]# mv apache-zookeeper-3.6.0-bin /etc/zookeeper[root@localhost ~]# cd /etc/zookeeper/conf [root@localhost conf]# mv zoo_sample.cfg zoo.cfg [root@localhost conf]# ls configuration.xsl log4j.properties zoo.cfg[root@localhost conf]# vim zoo.cfg dataDir=/etc/zookeeper/zookeeper-data在/etc/zookeeper/目录下创建zookeeper-data目录 [root@localhost zookeeper]# mkdir zookeeper-data##切换到指定目录,启动zookeeper服务 cd /etc/zookeeper/bin [root@localhost bin]# ./zkServer.sh start
2. 安装Kafka
[root@localhost ~]# tar zxvf kafka_2.13-2.4.1.tgz [root@localhost ~]# mv kafka_2.13-2.4.1 /etc/kafka [root@localhost ~]# cd /etc/kafka[root@localhost kafka]# vim config/server.properties log.dirs=/etc/kafka/kafka-logs ##60行修改[root@localhost kafka]# mkdir kafka-logs##启动kafka服务 [root@localhost ~]# cd /etc/kafka/bin [root@localhost bin]# ./kafka-server-start.sh ../config/server.properties &
3. 测试
[root@localhost bin]# netstat -anpt |grep java tcp6 0 0 :::45561 :::* LISTEN 5055/java tcp6 0 0 :::2181 :::* LISTEN 5055/java tcp6 0 0 :::9092 :::* LISTEN 5098/java tcp6 0 0 :::43721 :::* LISTEN 5098/java tcp6 0 0 :::8080 :::* LISTEN 5055/java tcp6 0 0 127.0.0.1:2181 127.0.0.1:56962 ESTABLISHED 5055/java tcp6 0 0 127.0.0.1:9092 127.0.0.1:53582 ESTABLISHED 5098/java tcp6 0 0 127.0.0.1:53582 127.0.0.1:9092 ESTABLISHED 5098/java tcp6 0 0 127.0.0.1:56962 127.0.0.1:2181 ESTABLISHED 5098/java ##生产消息 [root@localhost bin]./kafka-console-producer.sh --broker-list 127.0.0.1:9092 -topic testaaa >123 >456 >789##打开一个新的终端,查看消息 [root@localhost bin]# ./kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 -topic testaaa 123 456 789
六、 集群部署Kafka
1。 基础环境设置
关闭防火墙、安装java
systemctl stop firewalld setenforce 0 dnf -y install java
##三台服务器修改名字 hostnamectl set-hostname kafka1 hostnamectl set-hostname kafka2 hostnamectl set-hostname kafka3cat /etc/hosts ##在该文件中添加 192.168.10.101 kafka1 192.168.10.105 kafka2 192.168.10.106 kafka3
2. 安装 Zookeeper
[root@kafka1 ~]# cd /etc/zookeeper/conf [root@kafka1 conf]# ls configuration.xsl zoo.cfg zoo_sample.cfg log4j.properties zoo.cfg.dynamic.next[root@kafka1 conf]# vim zoo.cfg dataDir=/etc/zookeeper/zookeeper-data ##修改并添加几行 clientPort=2181 server.1=192.168.10.101:2888:3888 server.2=192.168.10.105:2888:3888 server.3=192.168.10.106:2888:3888[root@kafka1 conf]# mkdir /etc/zookeeper/zookeeper-data/echo '1'>//etc/zookeeper/zookeeper-data/myid echo '2'>//etc/zookeeper/zookeeper-data/myid echo '3'>//etc/zookeeper/zookeeper-data/myid[root@kafka1 ~]# cd /etc/zookeeper/bin [root@kafka1 bin]# ./zkServer.sh setart ##一定要启动zookeeper
3. 安装 kafka
[root@kafka1 ~]# cd /etc/kafka/config[root@kafka1 config]# vim server.properties broker.id=1 ##id值不能一样,其他两个id为2和三 listeners=PLAINTEXT://192.168.10.101:9092 ##三台填写自己的ip log.dirs=/etc/kafka/kafka-logs zookeeper.connect=192.168.10.101:2181,192.168.10.105:2181,192.168.10.106:2181##启动kafka [root@kafka1 ~]# cd /etc/kafka/bin [root@kafka1 bin]# ./kafka-server-start.sh ../config/server.properties &
4. 测试
任意一台服务器创建topic ./kafka-topics.sh --create --zookeeper kafka1:2181 --replication-factor 1 --partitions 1 --topic test1111111./kafka-console-producer.sh --broker-list kafka1:9092 -topic test1111111 生产消息./kafka-console-consumer.sh --bootstrap-server kafka1:9092 --topic test1111111 另一台消费消息




)





(A-E))








