MCP中的Context
- 1. Context
- 2. 日志输出
- 2.1 服务端
- 2.2 客户端
- 2.2.1 客户端代码调试
- 2.2.2 客户端全部代码
- 3. 进度汇报
- 3.1 服务端
- 3.2 客户端
- 3.2.1 客户端代码调试
- 3.2.2 客户端全部代码
- 4. 模型调用
- 4.1 服务端
- 4.2 客户端
- 4.2.1 客户端代码调试
- 4.2.2 客户端全部代码
1. Context
Context对象给MCP Server提供了更多获取客户端信息、以及和客户端进行交互的接口。通过Context对象,能够获取到以以下对象:
- 当前请求的id:
request_id - 客户端id:
client_id - 服务端的
session对象
能够在单次请求中额外发送以下数据给客户端:
- 日志输出:可以发送服务端的日志给客户端
- 进度汇报:在处理一些耗时操作时,可以在处理过程中发送处理进度给客户端
- 模型调用:当服务端需要客户端的大模型能力时,可以调用客户端的大模型能力
通过Context,可以实现更加复杂的需求。但是注意,Context对象只能在Tool中使用,不能在 Resource 和Prompt 中使用。使用方式也非常简单,只需要在函数上添加一个 Context 类型的参数即可。
项目文件架构:新建一个Context_mcp文件夹,下面再分别创建三个子文件夹为Log_output、Load_report和Model_call。然后再三个子文件夹中都分别创建两个py文件,命名为server.py和client.py
2. 日志输出
如果服务端代码在执行过程中想要将执行过程的日志发送给客户端,那么借助 Context 非常方便的实现。
2.1 服务端
在Log_output文件夹下的server.py文件中,添加 Context 信息,添加的方式是接着tool工具,然后再函数中添加 Context 参数,参数的具体名称不限制,往往采用ctx或者content进行命名.
比如定义日志输出的函数为log_tool,参数分别为两个:files和ctx。前者是指定文件列表,用于存放文件路径的容器,第二个就是Context对应的参数。
"""
-------------------------------------------------------------------------------
@Project : MCP projects
File : client.py
Time : 2025-06-05 17:20
author : musen
Email : xianl828@163.com
-------------------------------------------------------------------------------
"""
from mcp.server.fastmcp import FastMCP,Context# app = FastMCP
mcp: FastMCP = FastMCP()#两种书写方式,都可以
# @app.tool()
@mcp.tool()
async def log_tool(files:list[str],ctx:Context):'''处理文件的接口:param files: 文件列表:param ctx: 上下文对象,无需客户端传递:return: 处理结果'''for index,file in enumerate(files):await asyncio.sleep(1)# ctx.log()await ctx.info(f"正在处理第{index+1}个文件")return "所有文件处理完成"if __name__ == '__main__':mcp.run(transport='sse')
服务端的代码中,通过log函数进行信息的传递,其属于最基础的操作,点击函数进入技术文档可以知道如果使用log进行消息传递,需要指定level和message两个重要参数,其中level包含具体的信息类型。
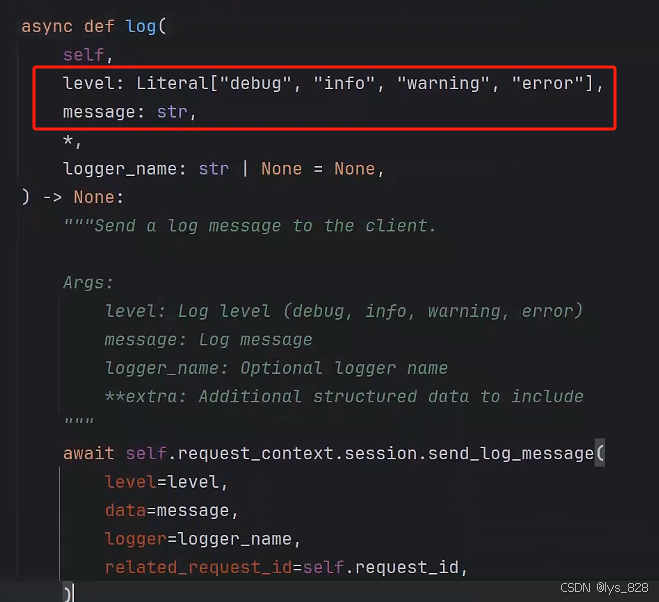
通过往下滑, 可以发现文档中已经有关于会话信息操作的封装函数,如下(刚好对应上面level参数中指定的4类,比如这里服务端的代码使用ctx.info()函数进行消息传递)
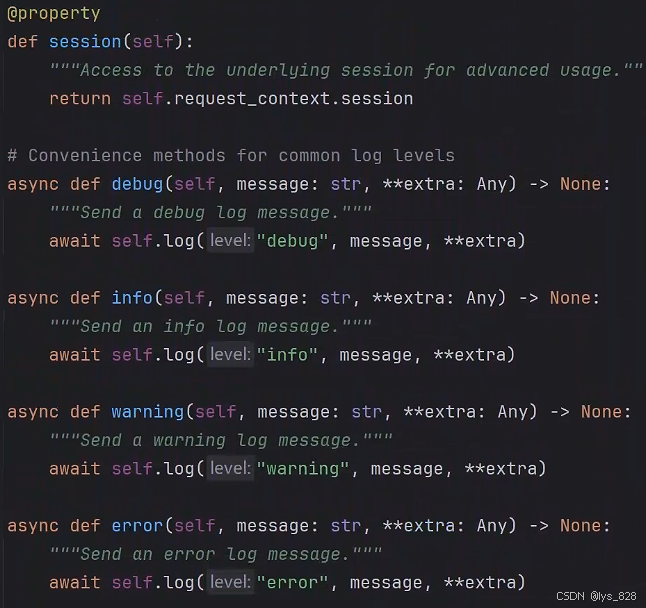
2.2 客户端
2.2.1 客户端代码调试
在Log_output文件夹下的client.py文件中,先进行架构的搭建
import asyncio
from mcp.client.sse import sse_client
from mcp import ClientSessionasync def run():async with sse_client("http://127.0.0.1:8000/sse") as (read_stream, write_stream):async with ClientSession(read_stream, write_stream) as session:await session.initialize()# 获取所有工具tools = (await session.list_tools()).toolsprint(tools)if __name__ == "__main__":asyncio.run(run())
执行结果如下:(以上代码是之前项目中都使用的框架,熟悉的操作,就看是不是结果可以正常输出)
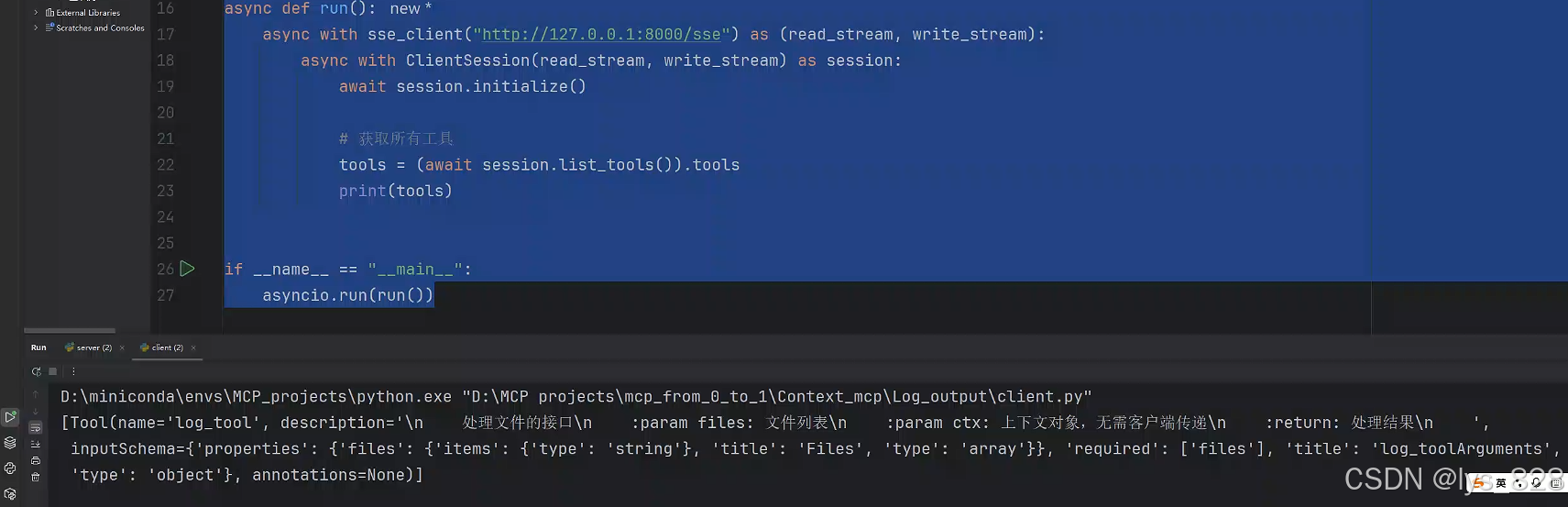
目前tool工具对象中只有一个数据,因为进行演示demo,这里可以直接进行列表对象的索引(以往的项目都是遍历循环)
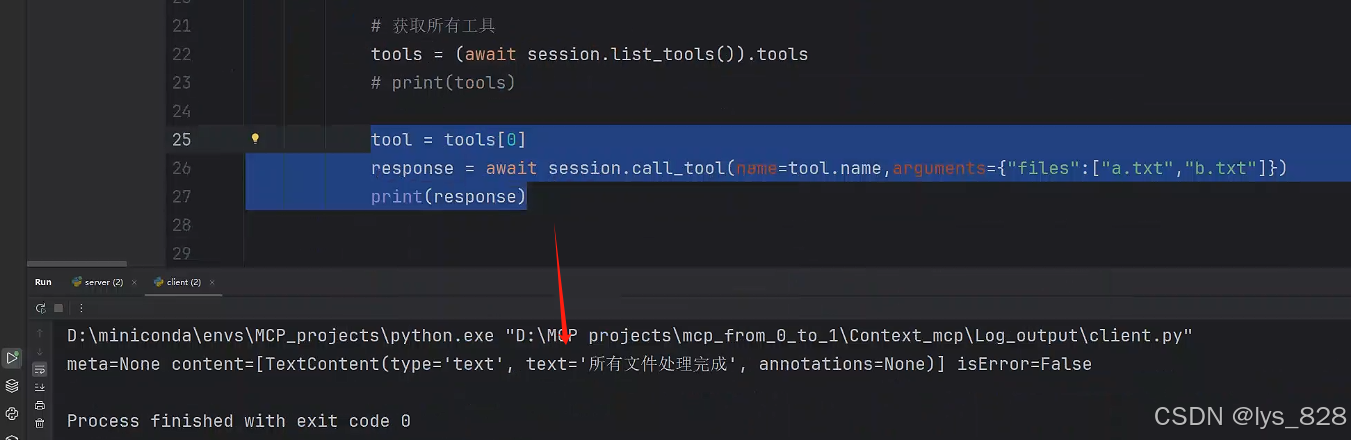
tool = tools[0]
response = await session.call_tool(name=tool.name,arguments={"files":["a.txt","b.txt"]})
print(response)
代码执行输出结果如下:(输出结果中出现“所有文件处理完毕”,说明客户端中成功调用了服务端中的日志输出工具)
现在可以成功调用工具,我们的目标是获取客户端发过来的日志信息,需要结合这个session中的logging_callback参数。
通过点击加logging_callback参数j,进入技术文档,可以发现,这参数需要制定一个回调函数。
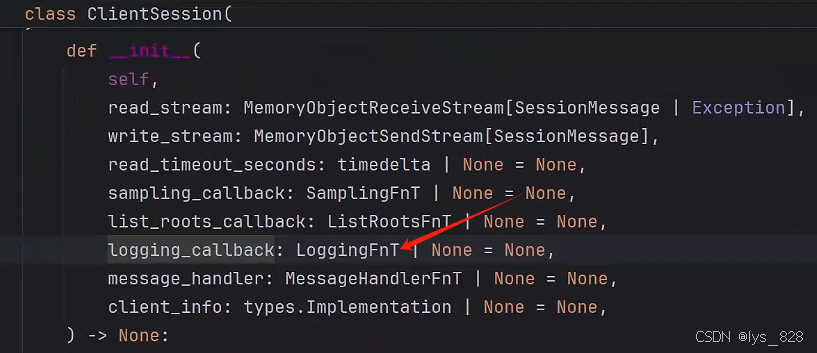
进一步,点击一个回调函数,查看具体说明,主要查看这个函数需要传入的参数类别,如下
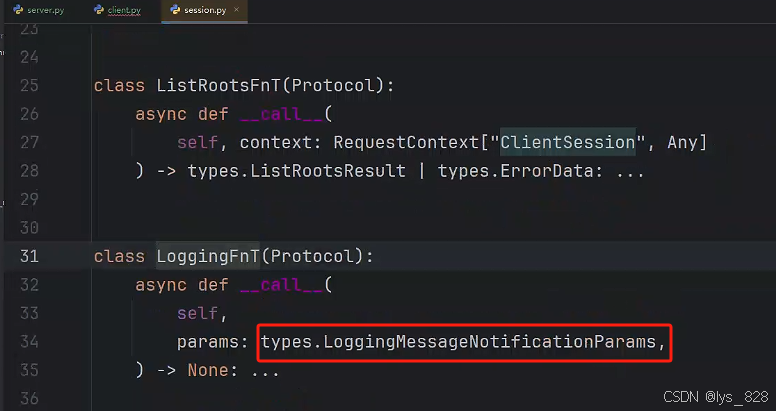
因此,在client.py中定一个回调函数,命名为logging_handle,然后这个函数指定的对应就是上面红框中的数据对象,然后再把这个回调函数赋值给logging_callback参数,如下
from mcp.types import LoggingMessageNotificationParamsasync def logging_handle(params: LoggingMessageNotificationParams):print(params)async def run():async with sse_client("http://127.0.0.1:8000/sse") as (read_stream, write_stream):async with ClientSession(read_stream,write_stream,logging_callback=logging_handle) as session:await session.initialize()....
执行代码,输出结果如下:(此时,我们就可以成功将服务端的信息在客户端打印出来了,即获取到客户端的日志信息)
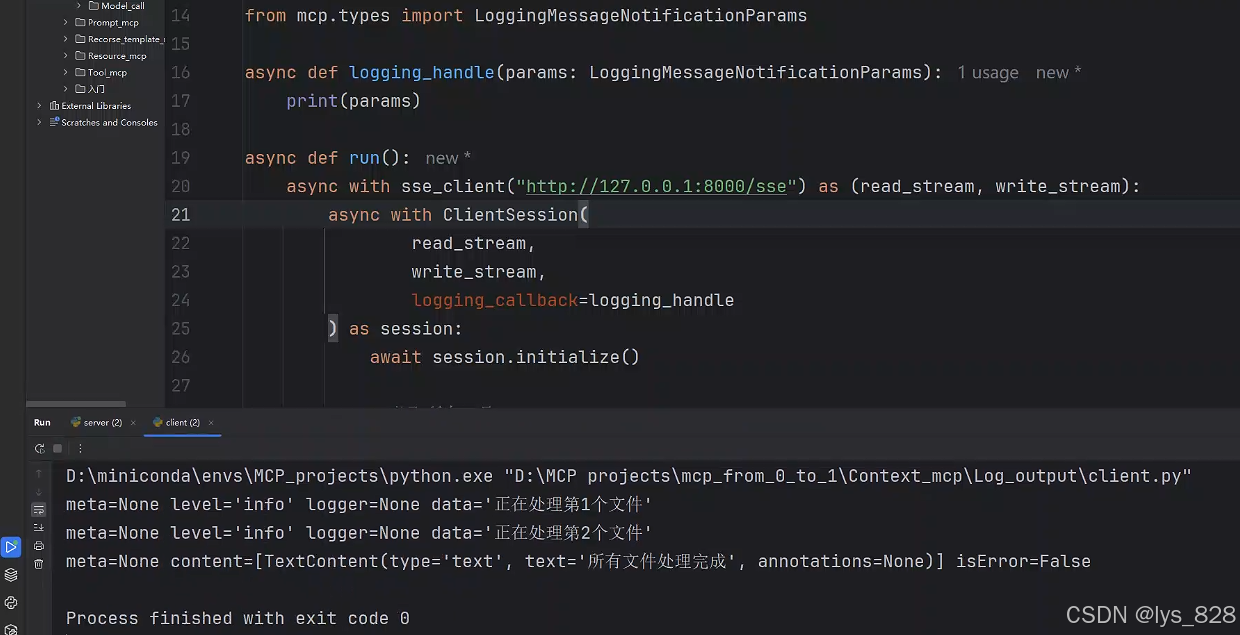
由此,就可以根据自己的需求完成一些日志方面的操作,比如将日志信息保存本地,进行日志操作之间的交互(增加用户体验)等。
2.2.2 客户端全部代码
给出client.py文件的全部代码,方便学习理解
import asyncio
from mcp.client.sse import sse_client
from mcp import ClientSession
from mcp.types import LoggingMessageNotificationParamsasync def logging_handle(params: LoggingMessageNotificationParams):print(params)async def run():async with sse_client("http://127.0.0.1:8000/sse") as (read_stream, write_stream):async with ClientSession(read_stream,write_stream,logging_callback=logging_handle) as session:await session.initialize()# 获取所有工具tools = (await session.list_tools()).tools# print(tools)tool = tools[0]response = await session.call_tool(name=tool.name,arguments={"files":["a.txt","b.txt"]})print(response)if __name__ == "__main__":asyncio.run(run())
3. 进度汇报
当服务端的代码在处理一些耗时操作时,可以向客户端实时反馈执行的进度。可以通过report_process()函数进行设置
3.1 服务端
在Load_report文件夹下的server.py文件中,输入代码如下
import asyncio
from mcp.server.fastmcp import FastMCP,Context
from mcp.types import RequestParamsmcp: FastMCP = FastMCP()@mcp.tool()
async def load_task(files:list[str],ctx: Context):'''处理多个文件进行进度汇报:param files: 多个文件路径:param ctx: 上下文对象,无需客户端传递:return: 处理结果'''for index,file in enumerate(files):await asyncio.sleep(1)ctx.request_context.meta = RequestParams.Meta(progressToken=ctx.request_id)await ctx.report_progress(index,len(files))return "处理完毕"if __name__ == '__main__':mcp.run(transport="sse")
代码中,关于调用ctx.report_progress()函数前,需要添加一行代码ctx.request_context.meta = RequestParams.Meta(),具体原因可以通过查看ctx.report_progress()函数技术文档,如下(这个函数中有一个progress_token参数,如果这个参数的赋值为None,这调用函数直接返回为空,相当于函数不会发送信息。而要求函数发送信息,则要求progress_token参数不为None,进一步找到前面的request_context.meta参数,这个值不能为None,然后就返回request_context.meta.progressToken对象)
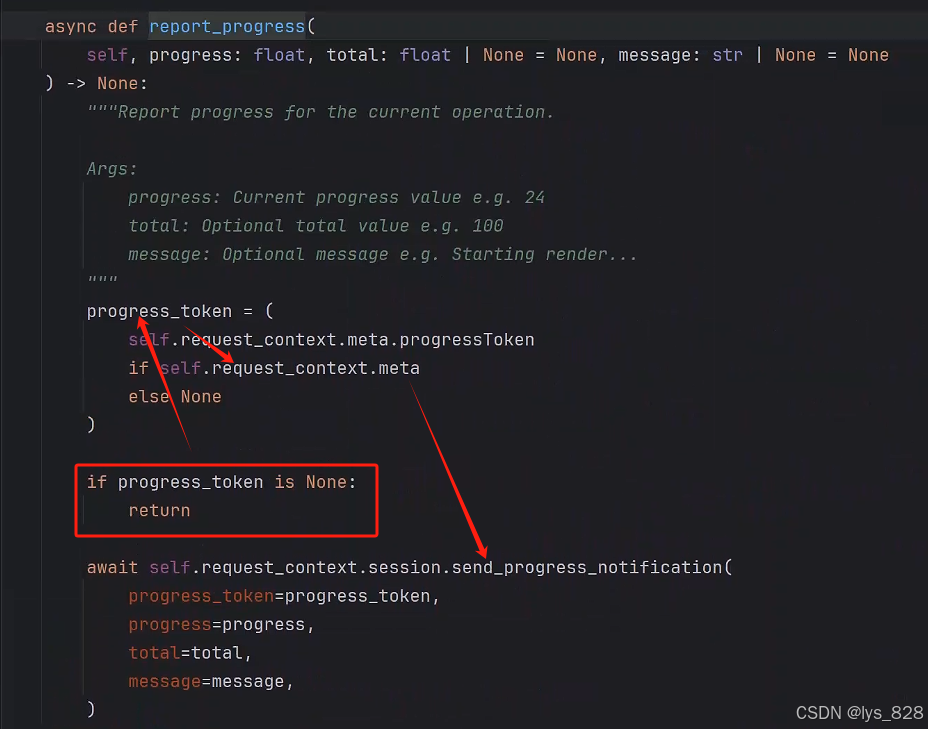
进一步点击request_context.meta.progressToken,查看它的技术文档,可以发现这个参数下还是一个函数嵌套。
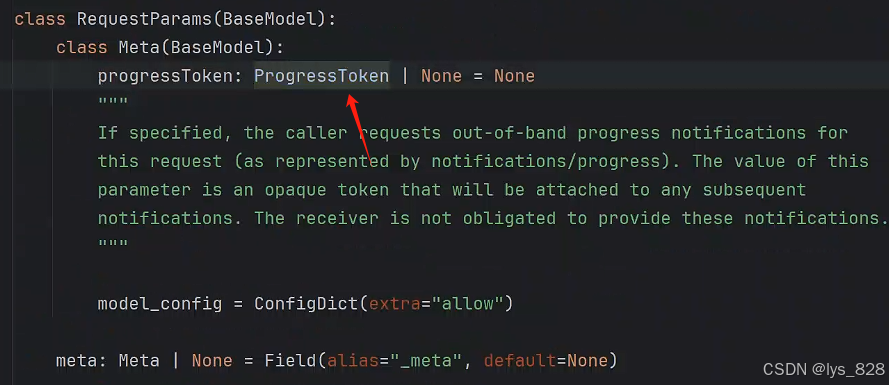
进一步点击函数,进入下一次技术文档,如下(可知这个进度的Token需要指定一个字符串或者整形的数据,避免None值出现)
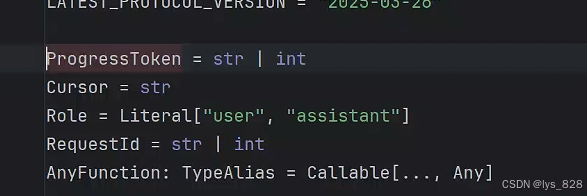
因此,为了在执行ctx.report_progress()函数前,添加一行代码ctx.request_context.meta = RequestParams.Meta(),而且里面的这个参数设置需要时唯一的,这里采用的就是每一个请求的id。 做开发项目,最有趣的过程就是在进行探索的过程,这个过程自己过一遍后,收获感会很充实。
3.2 客户端
3.2.1 客户端代码调试
在Load_report文件夹下的client.py文件中,与前面的日志输出类似,这里也有一个message_handler参数进行回调。同样,进入该参数的技术文档,查看详细说明,如下
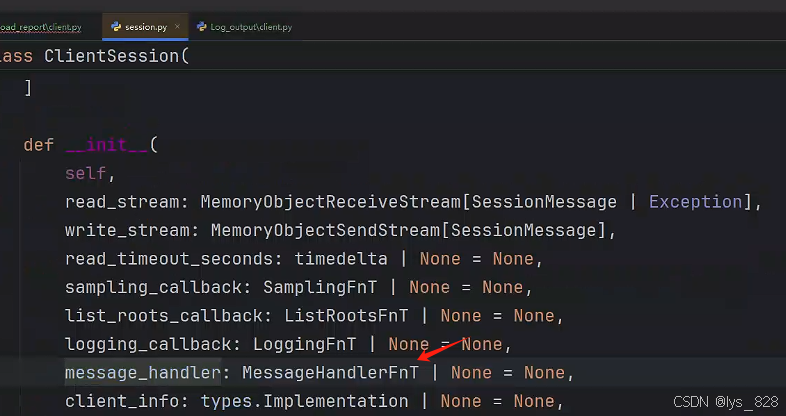
进一步点击进去,查看详细说明,如下(该函数回调只有一个参数,就是message,可接受三种数据类型)
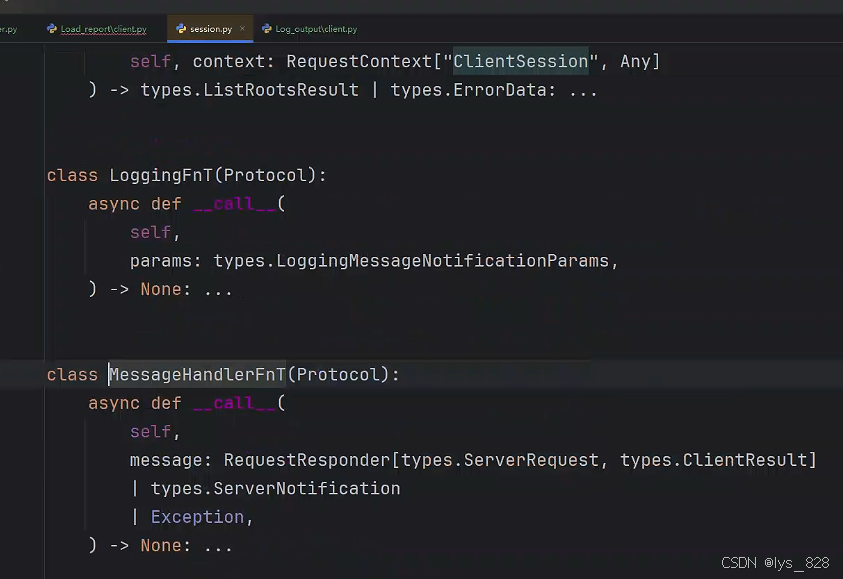
因此在定义回调函数时候,指定传入的参数类型设置,可以直接把技术文档中的说明复制过来,如下
from mcp.types import LoggingMessageNotificationParams,ServerNotification,ClientResult,ServerRequest
from mcp.client.session import RequestResponder
async def message_handler(message: RequestResponder[ServerRequest, ClientResult]| ServerNotification| Exception):print("*"*30)print(message)print("*" * 30)async def run():async with sse_client("http://127.0.0.1:8000/sse") as (read_stream, write_stream):async with ClientSession(read_stream,write_stream,logging_callback=logging_handle,message_handler=message_handler #这个参数设置) as session:await session.initialize()
执行代码输出结果如下:(可以输出加载信息)
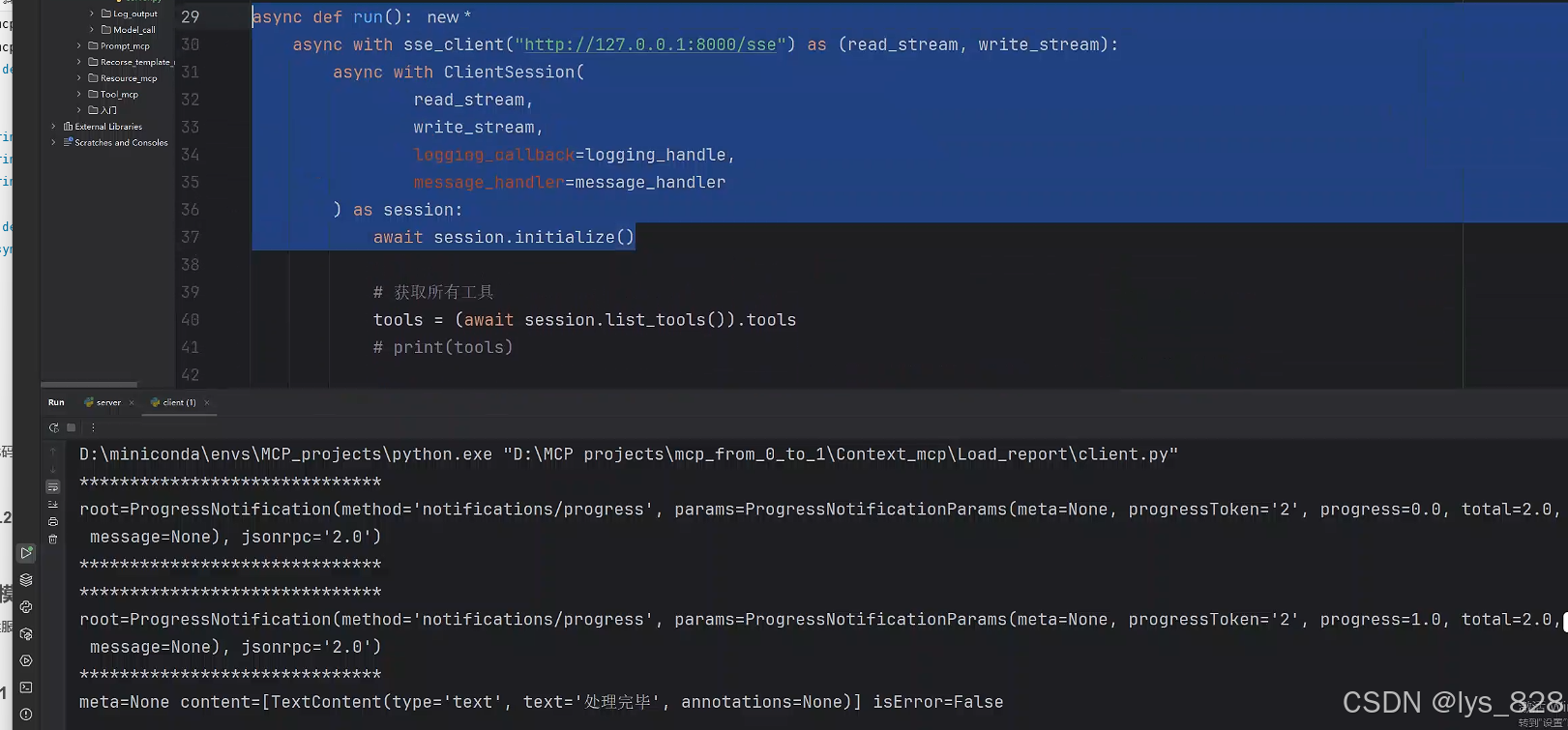
3.2.2 客户端全部代码
import asyncio
from mcp.client.sse import sse_client
from mcp import ClientSession
from mcp.types import LoggingMessageNotificationParams,ServerNotification,ClientResult,ServerRequest
from mcp.client.session import RequestResponderasync def message_handler(message: RequestResponder[ServerRequest, ClientResult]| ServerNotification| Exception):print("*"*30)print(message)print("*" * 30)async def run():async with sse_client("http://127.0.0.1:8000/sse") as (read_stream, write_stream):async with ClientSession(read_stream,write_stream,logging_callback=logging_handle,message_handler=message_handler) as session:await session.initialize()# 获取所有工具tools = (await session.list_tools()).tools# print(tools)tool = tools[0]response = await session.call_tool(name=tool.name,arguments={"files":["a.txt","b.txt"]})print(response)if __name__ == "__main__":asyncio.run(run())
4. 模型调用
有时候服务端可能需要调用大模型的能力,那么可以使用MCP提供的sampling功能来实现。(注意是服务端调用大模型能力,之前项目都是客户端调用大模型来执行服务端中的Tool)
4.1 服务端
在Mdel_call文件夹下的server.py文件中,具体实现就是调用Context对象下面的session.create_message()函数
"""import asyncio
from mcp.server.fastmcp import FastMCP,Context
from mcp.types import SamplingMessage, TextContentmcp: FastMCP = FastMCP()@mcp.tool()
async def sampling_tool(ctx:Context):# 直接发送一个Sampling的消息response = await ctx.session.create_message(max_token=2048,messages=[SamplingMessage(role="user",content=TextContent(type="text",text="请帮我按照主题“2025年高考”为主题写两篇诗词"))])print(response)return "采样成功"if __name__ == '__main__':mcp.run(transport="sse")
关于函数中具体参数的配置,也可以参考本博客中前2个案例,都是通过技术文档中的说明,逐步进行完善,然后填写完整,这个过程不是要背具体的方式,而是要学会具体的方法。比如这里对于大模型能力的应用,知道借助上下文Context对象下面的session.create_message()函数创建就可以了,然后就是具体的参数设置直接借助说明文档快速完成。
4.2 客户端
4.2.1 客户端代码调试
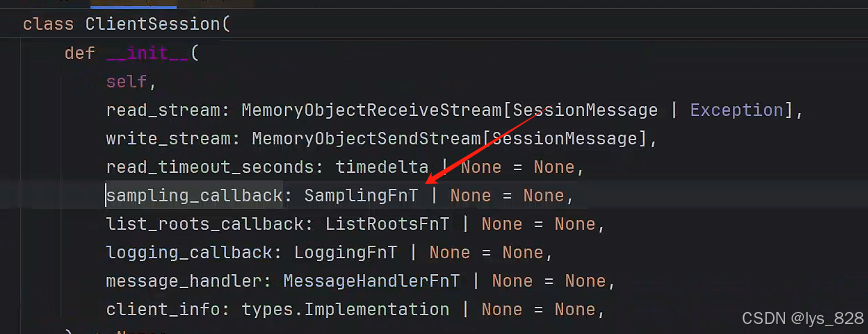
在Mdel_call文件夹下的client.py文件中,客服端中对应的就是sampling_callback参数完成
点击该参数,进入技术文档,如下
然后进入下一级的技术文档,如下(此时就出现了具体的参数和数据类型了)
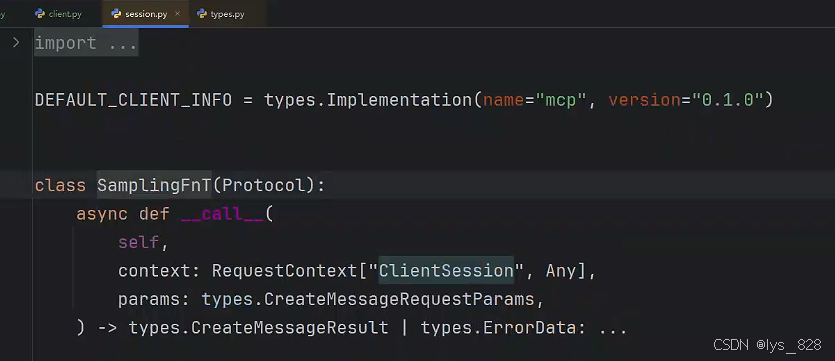
在客户端,新定一个函数为sampling_handler(),然后把上图中的下面介绍两个参数及对应的数据类型的代码全部复制到创建的函数中。还需要注意,技术文档中回调函数需要返回CreateMessageResult数据类型。我们可以先手动创建一个类数据对象,如下
from mcp.types import CreateMessageRequestParams, TextContent, CreateMessageResult
from mcp.client.session import RequestContext
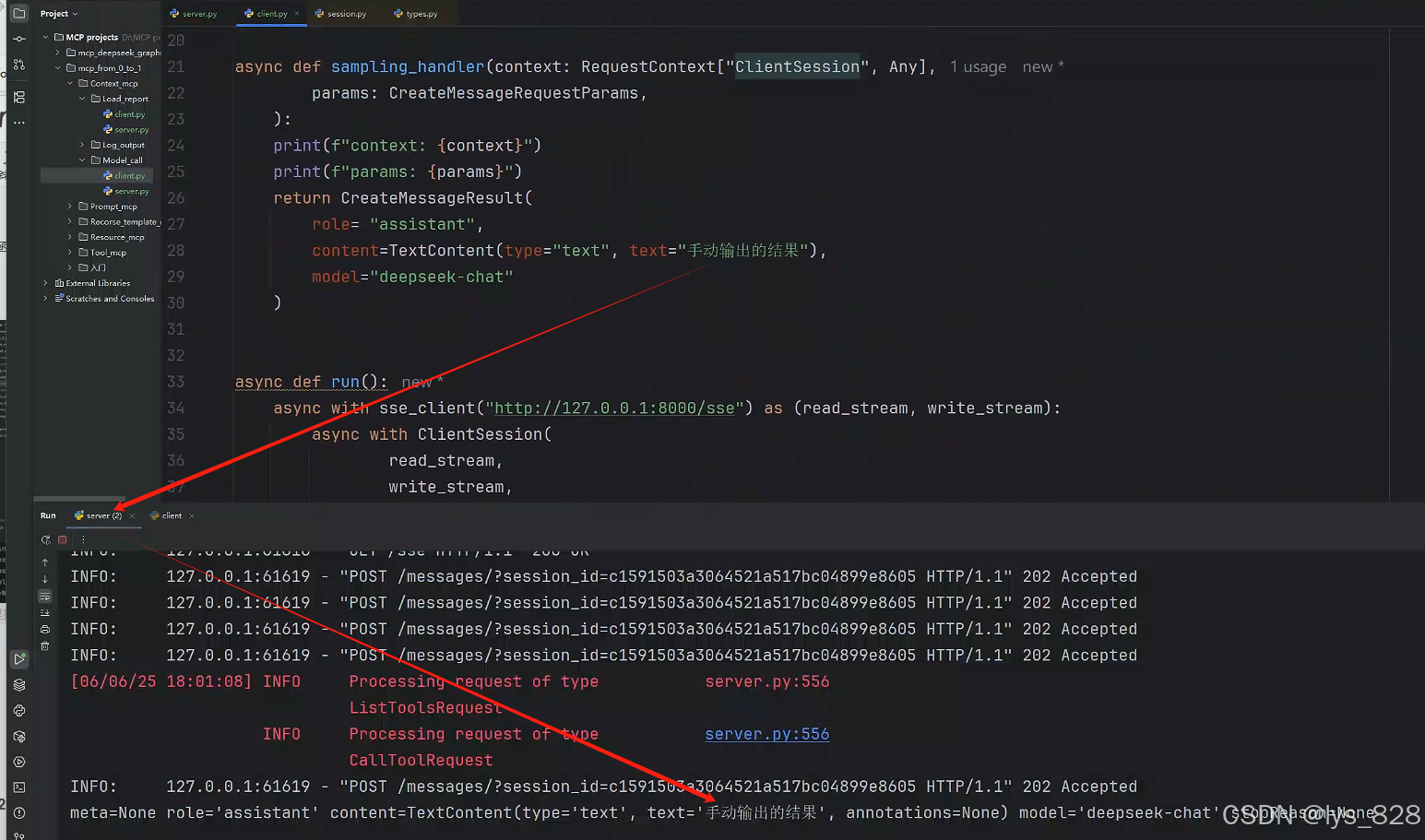
async def sampling_handler(context: RequestContext["ClientSession", Any],params: CreateMessageRequestParams,):print(f"context: {context}")print(f"params: {params}")return CreateMessageResult(role= "assistant", # 大模型返回的信息,此时的角色对应的是assistantcontent=TextContent(type="text", text="手动输出的结果"),model="deepseek-chat")
将回调函数复制给对应的参数后,执行客户端代码,结果输出如下(检查客户端输出没有报错,然后服务端出现自己手动创建的CreateMessageResult数据,即证明代码可以跑通)
客户端:
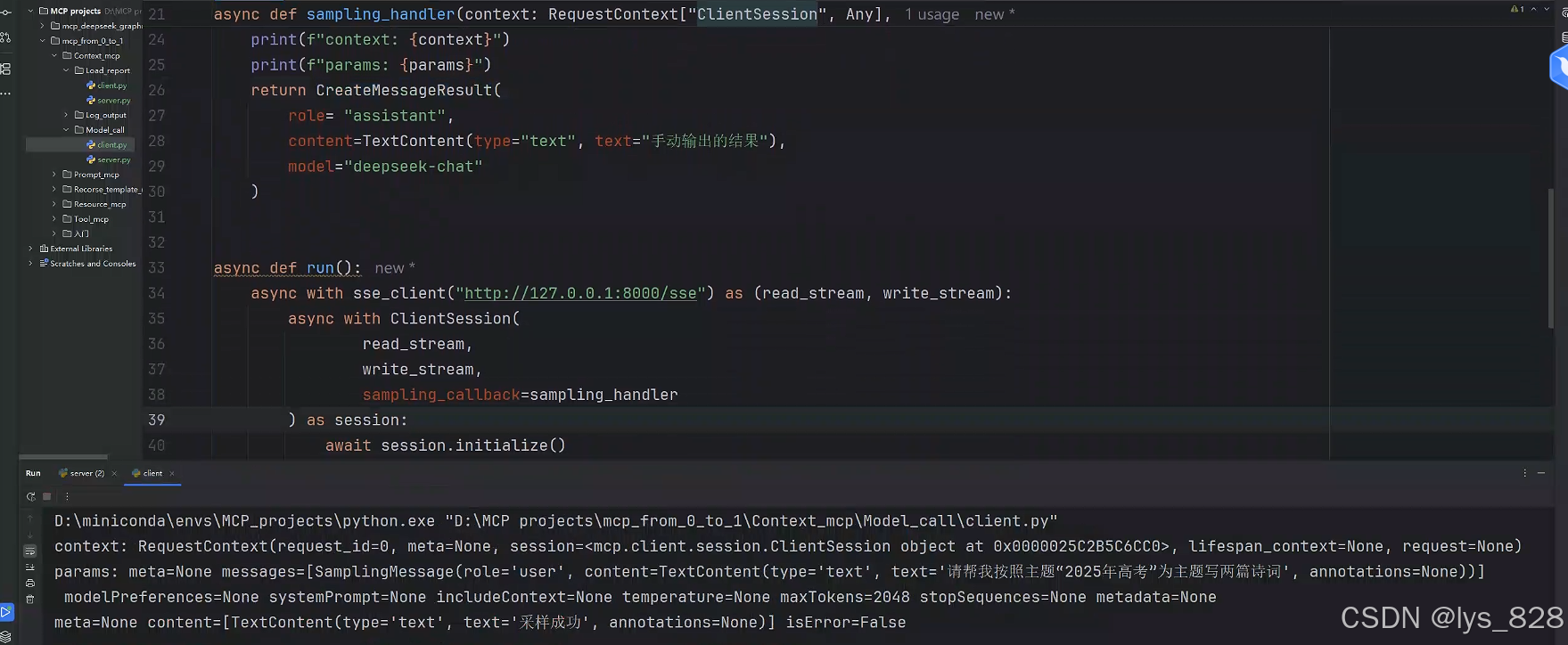
服务端:
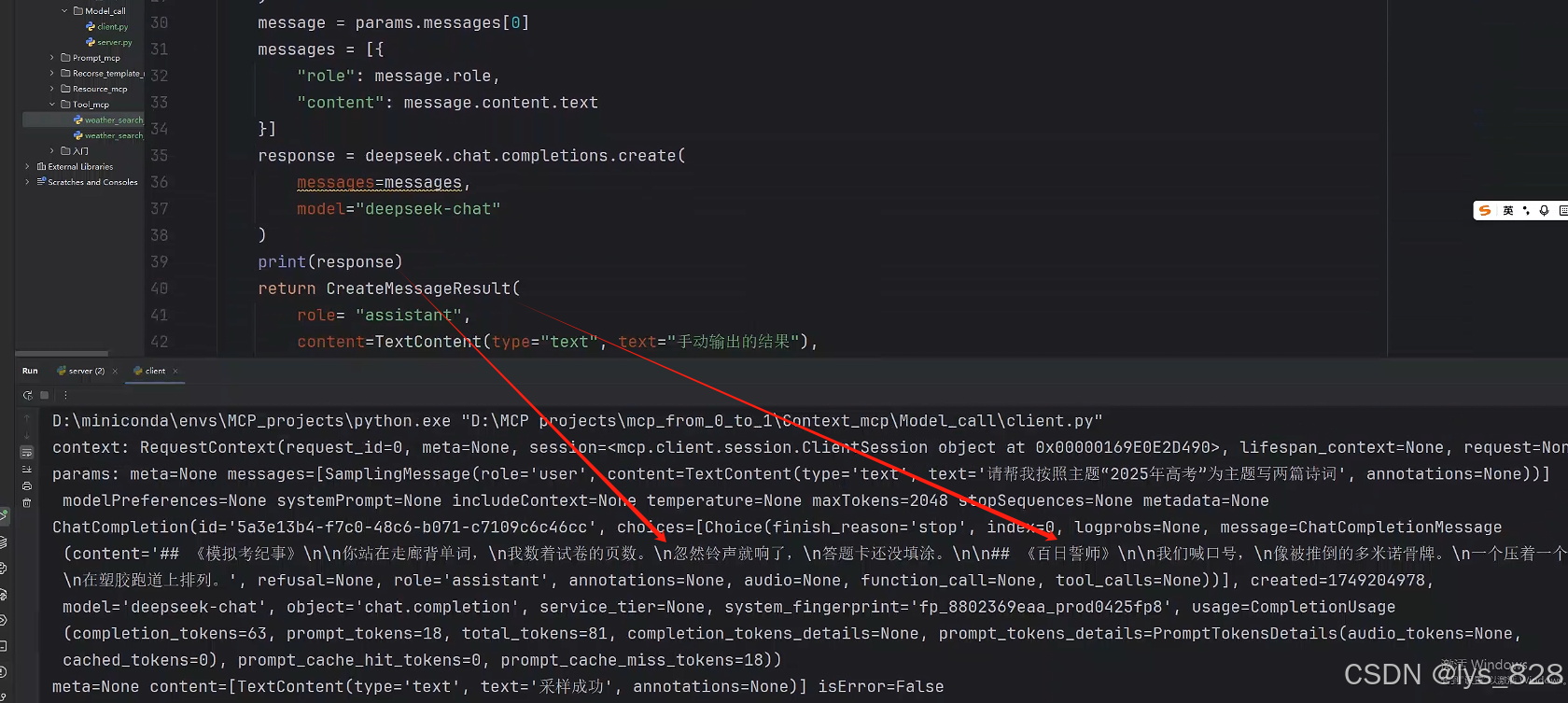
那么接下来,就是换用加入大模型,让其进行返回结果到服务端,如下(关于message变量的赋值,可以参考上图客户端输出结果进行获取,由此而进一步获得对应的role和content内容)
async def sampling_handler(context: RequestContext["ClientSession", Any],params: CreateMessageRequestParams,):print(f"context: {context}")print(f"params: {params}")deepseek = OpenAI(api_key="sk-5d307e0xxxxx5a6ce4575ff9",base_url="https://api.deepseek.com",)message = params.messages[0] messages = [{"role": message.role,"content": message.content.text}]response = deepseek.chat.completions.create(messages=messages,model="deepseek-chat")print(response)return CreateMessageResult(role= "assistant",content=TextContent(type="text", text="手动输出的结果"),model="deepseek-chat")
这里执行代码,输出如下(此时,只是测试代码是否正常运行,输出的结果是在客户端的输出窗口)
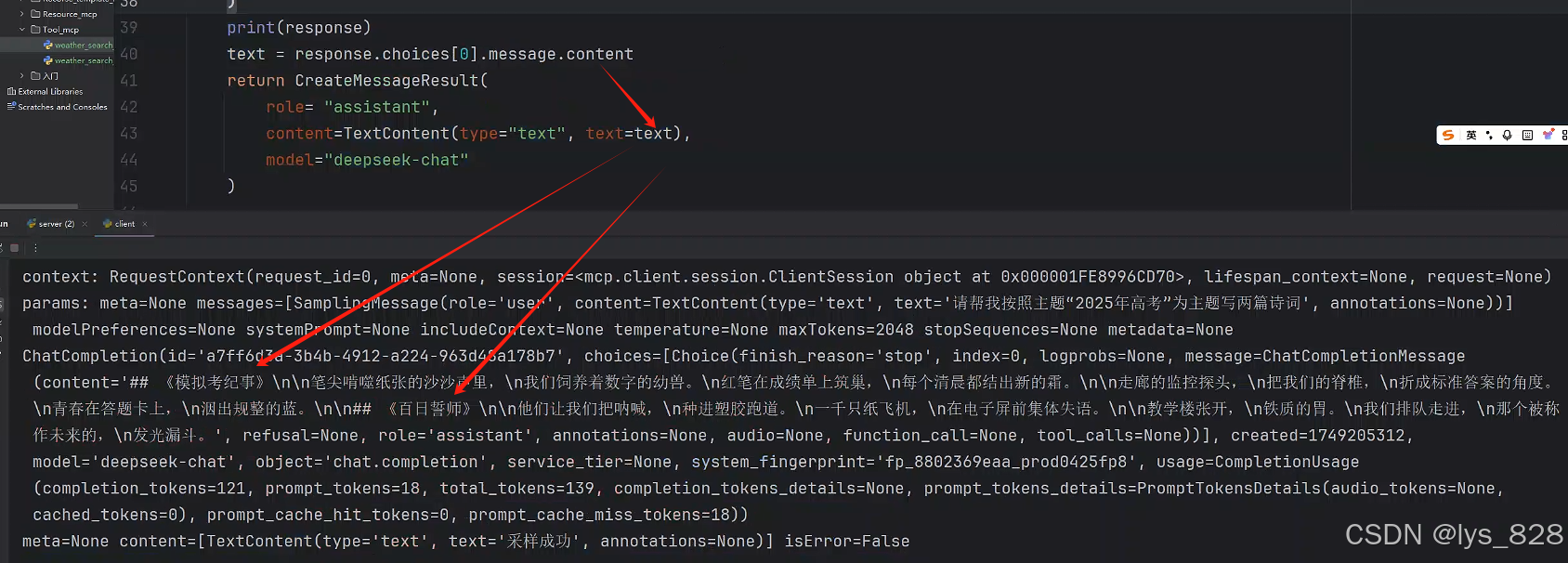
最后,就是把return中返回的结果使用response变量中的数据进行替换(根据上图的输出结果,逐步进行获取里面content内容),即可,代码如下
print(response)
text = response.choices[0].message.content
return CreateMessageResult(role= "assistant",content=TextContent(type="text", text=text),model="deepseek-chat"
重新执行客户端的代码,输出结果如下
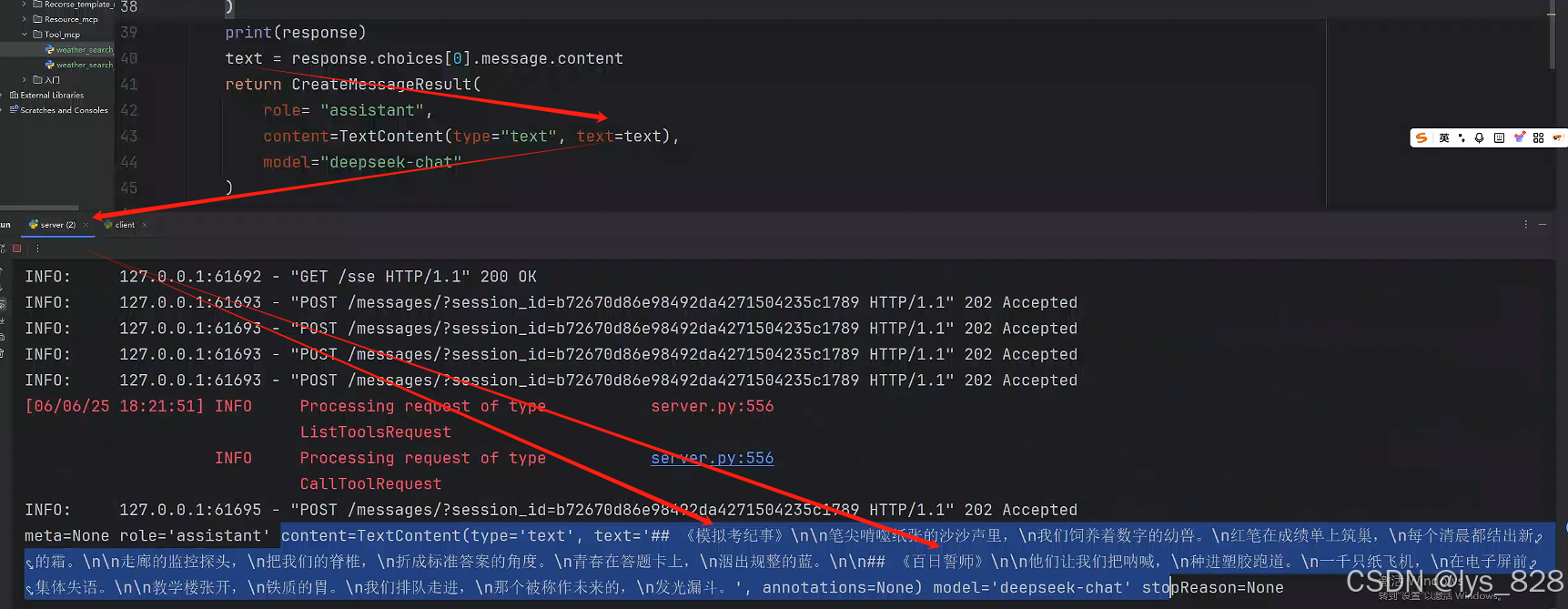
当客户端的代码运行完毕后,此时,点击服务端的输出窗口,检查是否可以获取到客户端调用大模型输出的结果,如下(完美获取想要的结果)
4.2.2 客户端全部代码
在强调一遍,这个项目是服务端获取客户端调用大模型返回的结果,这里是功能实现,具体后续的扩展开发就任凭需求了。
"""
-------------------------------------------------------------------------------
@Project : MCP projects
File : client.py
Time : 2025-06-05 17:20
author : musen
Email : xianl828@163.com
-------------------------------------------------------------------------------
"""import asyncio
from typing import Any
from mcp.client.sse import sse_client
from mcp import ClientSession
from mcp.types import CreateMessageRequestParams, TextContent, CreateMessageResult
from mcp.client.session import RequestContext
from openai import OpenAIasync def sampling_handler(context: RequestContext["ClientSession", Any],params: CreateMessageRequestParams,):print(f"context: {context}")print(f"params: {params}")deepseek = OpenAI(api_key="sk-5d307e0a45xxxxx4575ff9",base_url="https://api.deepseek.com",)message = params.messages[0]messages = [{"role": message.role,"content": message.content.text}]response = deepseek.chat.completions.create(messages=messages,model="deepseek-chat")print(response)text = response.choices[0].message.contentreturn CreateMessageResult(role= "assistant",content=TextContent(type="text", text=text),model="deepseek-chat")async def run():async with sse_client("http://127.0.0.1:8000/sse") as (read_stream, write_stream):async with ClientSession(read_stream,write_stream,sampling_callback=sampling_handler) as session:await session.initialize()# 获取所有工具tools = (await session.list_tools()).tools# print(tools)tool = tools[0]response = await session.call_tool(name=tool.name) #服务端的tool中函数没有参数arguments,这里就不需要指定print(response)if __name__ == "__main__":asyncio.run(run())
至此,关于 MCP中的Context的日志输出、进度汇报和服务端调用客户端的大模型输出结果的三个项目的实战详细梳理就完结了,撒花✿✿ヽ(°▽°)ノ✿。

![[华为eNSP] OSPF综合实验](http://pic.xiahunao.cn/[华为eNSP] OSPF综合实验)


P95+P96+P97+P98+P99+P100+P101)

)
)



)



技术的实现原理与应用场景解析)



: 循环神经网络(RNN))