对于Oracle 23ai Sharding 新特性的验证脚本,目标是涵盖其核心改进和新增功能。基于 Oracle 23ai 的 Sharding 特性总结(Raft 协议、True Cache、Vector等),结合常见场景验证。
通过SQL脚本验证这些特性。例如:
- 1.基于Raft协议的分布式Sharding:需要创建分片表,并模拟跨节点的数据分布和故障切换。
- 2.True Cache集成:需要启用缓存并查询缓存命中情况。
- 3.自动化分片管理:需要动态添加分片并观察数据重新分布。
- 4.JSON与关系模型的统一分片:创建包含JSON类型的分片表,并插入数据验证分片策略。
- 5.AI Vector Search:可能需要使用向量存储并执行相似性搜索。
也许Oracle在MAA 架构领域太过强大的缘故,导致它的分布式raft实现没有其他分布式产品宣传的那么多,那么强。
大多数的企业是否真得需要一个分布式数据库,那就是另外一个话题了。
由于Oracle 23 ai free目前的版本,能测的Sharding特性不是很多,这个坑需要在OP版本发布后再填上。
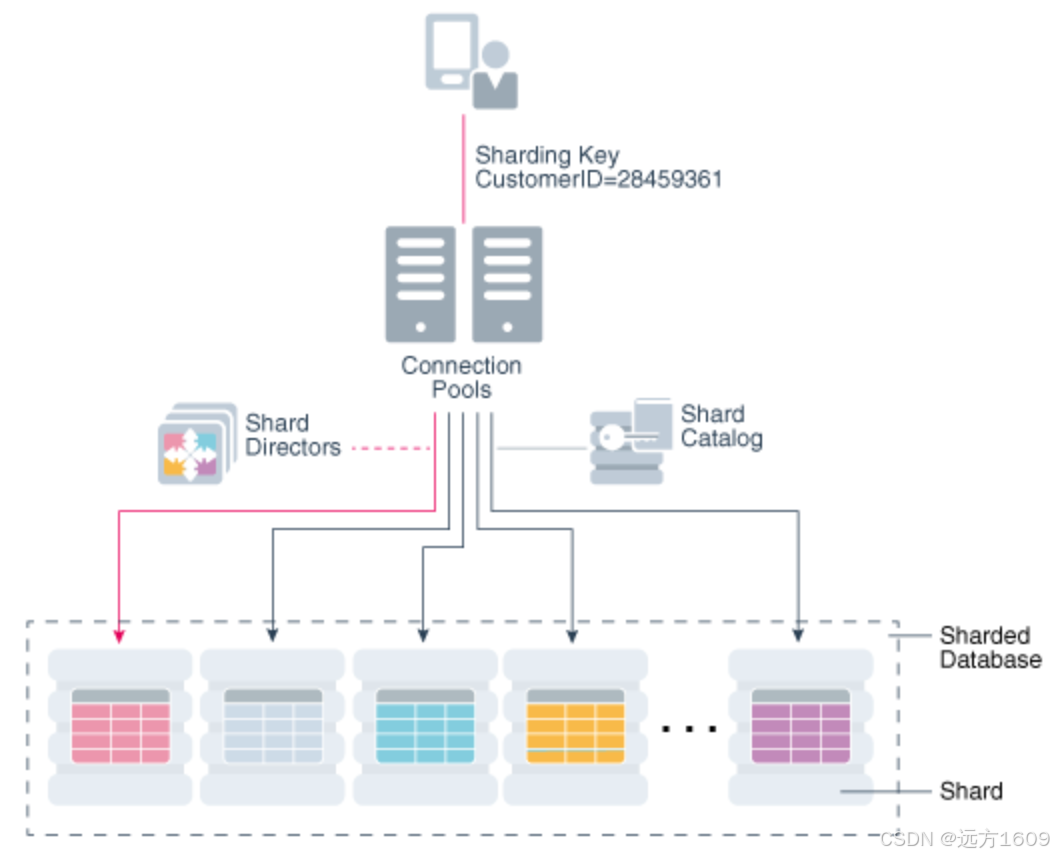
1. 验证基于 Raft 协议的分布式 Sharding
验证:创建分片表并模拟跨节点故障切换。
-- 1. 创建分片表(假设使用 Raft 协议)CREATE TABLE employees_shard (employee_id NUMBER PRIMARY KEY,name VARCHAR2(100),department_id NUMBER
)
PARTITION BY HASH (employee_id)
PARTITIONS 4;-- 2. 插入测试数据INSERT INTO employees_shard VALUES (1, 'Alice', 10);
INSERT INTO employees_shard VALUES (2, 'Bob', 20);
INSERT INTO employees_shard VALUES (3, 'Charlie', 30);-- 3. 查询分片分布(需启用 Raft 协议相关视图),free不存在视图
--SELECT * FROM v$sharding_nodes;
--SELECT * FROM v$sharding_partition_map WHERE table_name = 'EMPLOYEES_SHARD';-- 4. 模拟故障切换(需关闭一个分片节点)
-- 假设分片节点 1 故障,Oracle 23ai 会自动切换到其他节点
-- 验证数据一致性SELECT * FROM employees_shard;
SYS@CDB$ROOT> SELECT * FROM employees_shard;EMPLOYEE_ID NAME DEPARTMENT_ID
______________ __________ ________________2 Bob 201 Alice 103 Charlie 30SYS@CDB$ROOT>2. 验证 True Cache 与 Sharding 集成
验证:启用 True Cache 并观察缓存命中率,free不存在视图
-- 1. 启用 True Cache(需先安装并配置多个HOST)
ALTER SYSTEM SET TRUE_CACHE_ENABLED = TRUE SCOPE=BOTH;-- 2. 创建分片表并插入数据CREATE TABLE sales_shard (sale_id NUMBER PRIMARY KEY,product_id NUMBER,amount NUMBER
)
PARTITION BY RANGE (sale_id) (PARTITION p1 VALUES LESS THAN (100),PARTITION p2 VALUES LESS THAN (200)
);
Table SALES_SHARD created.
INSERT INTO sales_shard VALUES (1, 101, 1000);
INSERT INTO sales_shard VALUES (101, 102, 2000);
1 row inserted.
1 row inserted.
-- 3. 查询数据并触发缓存
SYS@CDB$ROOT> SELECT * FROM sales_shard WHERE sale_id = 101;SALE_ID PRODUCT_ID AMOUNT
__________ _____________ _________101 102 2000
-- 4. 查看 True Cache 命中率,free不存在视图
--SELECT * FROM v$true_cache_hit_ratio;3. 验证 自动化分片管理--整体报错,无法验证
验证:动态扩缩容并观察数据自动平衡。
-- 1. 创建分片表(假设支持自动化管理)--LIST分区报错CREATE TABLE customer_data (customer_id NUMBER PRIMARY KEY,name VARCHAR2(100),region VARCHAR2(50)
)
PARTITION BY LIST (region) (PARTITION p_east VALUES IN ('East'),PARTITION p_west VALUES IN ('West')
);-- 2. 插入数据INSERT INTO customer_data VALUES (1, 'John', 'East');
INSERT INTO customer_data VALUES (2, 'Jane', 'West');-- 3. 动态添加分片(AI 自动平衡数据)ALTER TABLE customer_data ADD PARTITION p_north VALUES IN ('North');-- 4. 验证数据分布(AI 自动迁移数据)SELECT * FROM dba_part_partitions WHERE table_name = 'CUSTOMER_DATA';4. 验证 JSON 与关系模型的统一分片
验证:创建 JSON 分片表并查询数据。
-- 1. 创建 JSON 分片表CREATE TABLE user_logs (user_id NUMBER PRIMARY KEY,log_data JSON
)
PARTITION BY HASH (user_id)
PARTITIONS 2;
Table USER_LOGS created.
-- 2. 插入 JSON 数据INSERT INTO user_logs VALUES (1,JSON_OBJECT('event' VALUE 'login', 'timestamp' VALUE SYSTIMESTAMP)
);
1 row inserted.
-- 3. 查询 JSON 数据(分片内查询)SELECT user_id, log_data FROM user_logs WHERE user_id = 1;
SYS@FREE> SELECT user_id, log_data FROM user_logs WHERE user_id = 1;USER_ID LOG_DATA
---------- --------------------------------------------------------------------------------1 {"event":"login","timestamp":"2025-06-08T19:34:47.636391+08:00"}-- 4. 验证分片分布
SELECT * FROM dba_part_tables WHERE table_name = 'USER_LOGS';
SYS@CDB$ROOT> SELECT * FROM dba_part_tables WHERE table_name = 'USER_LOGS';OWNER TABLE_NAME PARTITIONING_TYPE SUBPARTITIONING_TYPE PARTITION_COUNT DEF_SUBPARTITION_COUNT PARTITIONING_KEY_COUNT SUBPARTITIONING_KEY_COUNT STATUS DEF_TABLESPACE_NAME DEF_PCT_FREE DEF_PCT_USED DEF_INI_TRANS DEF_MAX_TRANS DEF_INITIAL_EXTENT DEF_NEXT_EXTENT DEF_MIN_EXTENTS DEF_MAX_EXTENTS DEF_MAX_SIZE DEF_PCT_INCREASE DEF_FREELISTS DEF_FREELIST_GROUPS DEF_LOGGING DEF_COMPRESSION DEF_COMPRESS_FOR DEF_BUFFER_POOL DEF_FLASH_CACHE DEF_CELL_FLASH_CACHE REF_PTN_CONSTRAINT_NAME INTERVAL AUTOLIST INTERVAL_SUBPARTITION AUTOLIST_SUBPARTITION IS_NESTED DEF_SEGMENT_CREATION DEF_INDEXING DEF_INMEMORY DEF_INMEMORY_PRIORITY DEF_INMEMORY_DISTRIBUTE DEF_INMEMORY_COMPRESSION DEF_INMEMORY_DUPLICATE DEF_READ_ONLY DEF_CELLMEMORY DEF_INMEMORY_SERVICE DEF_INMEMORY_SERVICE_NAME AUTO
________ _____________ ____________________ _______________________ __________________ _________________________ _________________________ ____________________________ _________ ______________________ _______________ _______________ ________________ ________________ _____________________ __________________ __________________ __________________ _______________ ___________________ ________________ ______________________ ______________ __________________ ___________________ __________________ __________________ _______________________ __________________________ ___________ ___________ ________________________ ________________________ ____________ _______________________ _______________ _______________ ________________________ __________________________ ___________________________ _________________________ ________________ _________________ _______________________ ____________________________ _______
SYS USER_LOGS HASH NONE 2 0 1 0 VALID SYSTEM 10 40 1 255 DEFAULT DEFAULT DEFAULT DEFAULT DEFAULT DEFAULT 0 0 NONE NONE DEFAULT DEFAULT DEFAULT NO NO NO NONE ON NONE NO NOSYS@CDB$ROOT>5. 验证 AI Vector Search 与分片集成
验证:存储向量数据并执行相似性搜索。
-- 1. 创建向量分片表(假设支持 AI Vector Search)CREATE TABLE image_vectors (image_id NUMBER PRIMARY KEY,features VECTOR(128) -- 假设向量维度为 128
)
PARTITION BY HASH (image_id)
PARTITIONS 3;
--Table IMAGE_VECTORS created.
-- 2. 插入向量数据(示例)--INSERT INTO image_vectors VALUES (1, VECTOR(1, 2, 3,128));
--INSERT INTO image_vectors VALUES (2, VECTOR(4, 5, 6, ..., 128));-- 3. 执行相似性搜索(跨分片)--错误
--SELECT * FROM image_vectors WHERE SIMILARITY(features, VECTOR(1, 2, 3, 128)) > 0.8;-- 4. 验证分片内的向量索引
SELECT * FROM dba_part_indexes WHERE table_name = 'IMAGE_VECTORS';
SYS@CDB$ROOT> SELECT * FROM dba_part_indexes WHERE table_name = 'IMAGE_VECTORS';OWNER INDEX_NAME TABLE_NAME PARTITIONING_TYPE SUBPARTITIONING_TYPE PARTITION_COUNT DEF_SUBPARTITION_COUNT PARTITIONING_KEY_COUNT SUBPARTITIONING_KEY_COUNT LOCALITY ALIGNMENT DEF_TABLESPACE_NAME DEF_PCT_FREE DEF_INI_TRANS DEF_MAX_TRANS DEF_INITIAL_EXTENT DEF_NEXT_EXTENT DEF_MIN_EXTENTS DEF_MAX_EXTENTS DEF_MAX_SIZE DEF_PCT_INCREASE DEF_FREELISTS DEF_FREELIST_GROUPS DEF_LOGGING DEF_BUFFER_POOL DEF_FLASH_CACHE DEF_CELL_FLASH_CACHE DEF_PARAMETERS INTERVAL AUTOLIST INTERVAL_SUBPARTITION AUTOLIST_SUBPARTITION
________ ___________________________ ________________ ____________________ _______________________ __________________ _________________________ _________________________ ____________________________ ___________ _______________ ______________________ _______________ ________________ ________________ _____________________ __________________ __________________ __________________ _______________ ___________________ ________________ ______________________ ______________ __________________ __________________ _______________________ _________________ ___________ ___________ ________________________ ________________________
SYS SYS_IL0000076364C00002$$ IMAGE_VECTORS HASH NONE 3 0 1 0 LOCAL NON_PREFIXED 10 1 255 DEFAULT DEFAULT DEFAULT DEFAULT DEFAULT DEFAULT 0 0 NONE DEFAULT DEFAULT DEFAULT NO NOSYS@CDB$ROOT>6. 验证 Shrink Tablespace 与分片存储优化
验证:收缩分片表的表空间。ORA-14809
-- 1. 创建分片表并插入数据CREATE TABLE logs_shard (log_id NUMBER PRIMARY KEY,message VARCHAR2(4000)
)
PARTITION BY RANGE (log_id) (PARTITION p1 VALUES LESS THAN (100),PARTITION p2 VALUES LESS THAN (200)
);
Table LOGS_SHARD created.
INSERT INTO logs_shard SELECT ROWNUM, 'Test log' FROM dual CONNECT BY ROWNUM <= 150;
150 rows inserted.
-- 2. 收缩表空间(回收未使用空间)ALTER TABLE logs_shard MOVE PARTITION p1 ONLINE;
--ORA-14809: schema does not support ONLINE MOVE PARTITION
ALTER TABLESPACE users COALESCE;
TABLESPACE USERS altered.
-- 3. 验证表空间大小SELECT segment_name, bytes/1024/1024 AS size_mb FROM dba_segments WHERE tablespace_name = 'USERS';
--no rows selected7. 验证 Schema Annotations 与分片元数据
验证:为分片表添加注释并查询。报错
-- 1. 创建分片表CREATE TABLE products_shard (product_id NUMBER PRIMARY KEY,name VARCHAR2(100)
)
PARTITION BY HASH (product_id)
PARTITIONS 2;
Table PRODUCTS_SHARD created.
-- 2. 添加表级注释ALTER TABLE products_shard ANNOTATIONS (ADD Title 'Product Data');
SYS@CDB$ROOT> ALTER TABLE products_shard ANNOTATIONS (ADD Title 'Product Data');Table PRODUCTS_SHARD altered.-- 3. 查询注释
SELECT * FROM user_annotations_usage WHERE object_type = 'TABLE' AND column_name IS NULL;
SYS@CDB$ROOT> SELECT * FROM user_annotations_usage WHERE object_type = 'TABLE' AND column_name IS NULL;OBJECT_NAME OBJECT_TYPE COLUMN_NAME DOMAIN_NAME DOMAIN_OWNER ANNOTATION_NAME ANNOTATION_VALUE
_________________ ______________ ______________ ______________ _______________ __________________ ___________________
PRODUCTS_SHARD TABLE TITLE Product Data
-- 4. 添加列级注释,语法错误
ALTER TABLE products_shard ANNOTATIONS (ADD COLUMN (name) Description 'Product Name');
ORA-11548: missing or invalid annotation name 'COLUMN' in the ANNOTATIONS sequence
-- 5. 查询列级注释
SELECT * FROM user_annotations_usage WHERE object_type = 'TABLE' AND column_name IS NOT NULL;
SYS@CDB$ROOT> SELECT * FROM user_annotations_usage WHERE object_type = 'TABLE' AND column_name IS NOT NULL;no rows selected8. 验证 IF [NOT] EXISTS 语法在 Sharding 中的兼容性
验证:IF [NOT] EXISTS
-- 1. 创建分片表(验证if exists忽略已存在错误)CREATE TABLE IF NOT EXISTS employees_shard (employee_id NUMBER PRIMARY KEY,name VARCHAR2(100)
)
PARTITION BY HASH (employee_id)
PARTITIONS 4;
Table EMPLOYEES_SHARD created.
-- 2. 重复执行上述语句(无错误)
SYS@CDB$ROOT> CREATE TABLE IF NOT EXISTS employees_shard (2 employee_id NUMBER PRIMARY KEY,3 name VARCHAR2(100)4 )5 PARTITION BY HASH (employee_id)6* PARTITIONS 4;Table EMPLOYEES_SHARD created.-- 3. 删除表并验证 IF EXISTS 子句
DROP TABLE IF EXISTS employees_shard;
SYS@CDB$ROOT> DROP TABLE IF EXISTS employees_shard;Table EMPLOYEES_SHARD dropped.9. 向量索引加速
验证:向量索引,分片表查询优化报错
-- 向量索引加速
CREATE VECTOR INDEX doc_vec_idx ON document_vectors (doc_vector)ORGANIZATION INMEMORY NEIGHBOR GRAPH;
SYS@CDB$ROOT> CREATE VECTOR INDEX doc_vec_idx ON document_vectors (doc_vector)2* ORGANIZATION INMEMORY NEIGHBOR GRAPH;Vector INDEX created.-- 分片表查询优化
SELECT /*+ SHARD_MIN_MAX */ *
FROM document_vectors
WHERE doc_id BETWEEN 100 AND 1000;
Error report -
ORA-17001: Internal error: Unknown or unimplemented accessor type: 127
https://docs.oracle.com/error-help/db/ora-17001/TIPS:
- 1.环境要求:确保 Oracle 23ai 已启用 Sharding 和相关特性(如 Raft 协议、True Cache)。
- 2.权限:部分操作需要 DBA 或 ADMINISTER DATABASE TRIGGER 权限。
- 3.验证工具: v$sharding_nodes、dba_part_partitions 等视图监控分片状态,free不存在。
- 4.AI 功能依赖:AI Vector Search 和自动化分片管理需依赖 Oracle 23ai 的机器学习组件。

与提示词撰写)




 语言原理介绍)







)
实战)



