网易云音乐基于 Apache Doris 替换了早期架构中 Kylin、Druid、Clickhouse、Elasticsearch、HBase 等引擎,统一了实时分析架构,并广泛应用于广告实时数仓、日志平台和会员报表分析等典型场景中,带来导入性能提升 3~30 倍,机器成本整体降低 55%、部分场景下高达 85%,每年节省数百万成本,综合效能提升 3~7 倍等显著收益。
截止目前,已有超过 9 个业务场景使用 Apache Doris,合计约 8 个 Doris 集群、100 多台机器,常规使用存储近 3PB、总容量近 8PB。
- 广告系统:通过使用 Doris 替换 Druid,P99 查询耗时控制在 2 秒内,(原先使用 Druid 查询 7 天内数据耗时尚可,但查询超过 7 天的数据会超时)。离线大表写入耗时也从原先的 11~12 小时降低至 3~4 小时。
- 日志平台:使用 Doris 替换 ClickHouse,查询效率提升 60%,机器数量减少了 50%,每年节省数百万使用成本。
- 会员报表分析:使用 Doris 替换 Kylin,大幅降本增效:数据导入耗时从原先的 6-10 小时缩短至于 10 分钟内,存储空间从 220 TB 减少至 13 TB,机器使用成本降低 85%。
基于 Apache Doris 的统一实时分析平台
网易云音乐实时分析诉求多样,早期采用了多引擎并存的架构来满足需求,使用的组件包括 Druid、Kylin、Impala、ClickHouse 、Elasticsearch 和 Hbase。然而,这种架构虽然满足了多样化分析诉求,但是带来了数据和资源冗余严重、运维困难、稳定性差、开发效率低、数据流维护复杂等一系列难题。
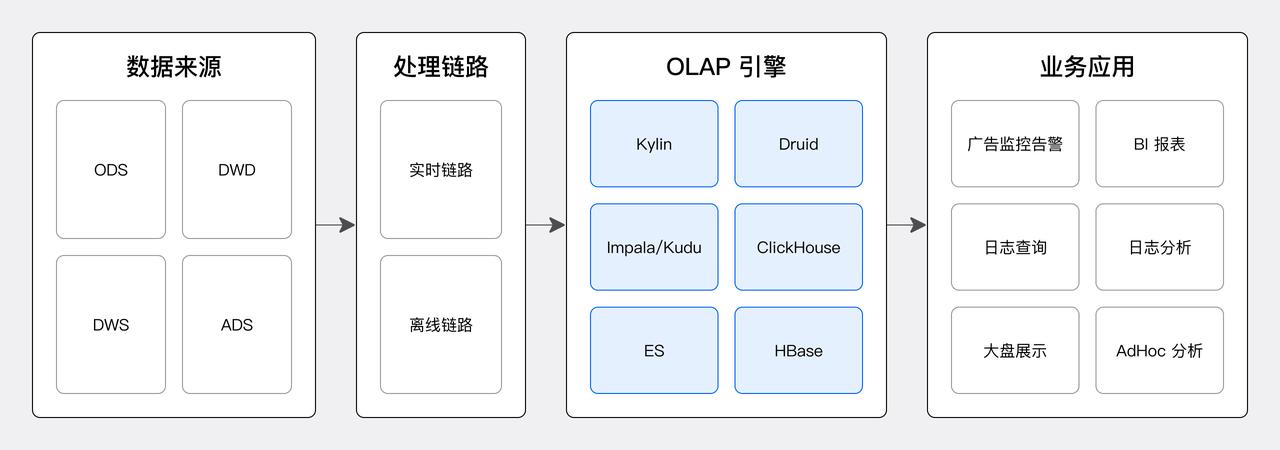
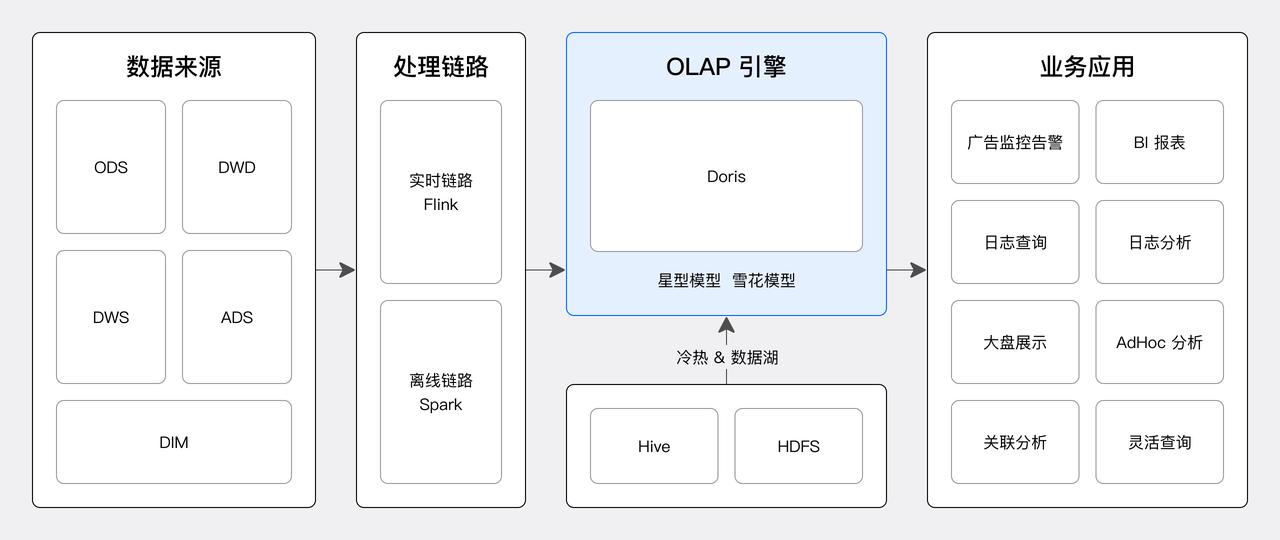
因为 Apache Doris 具有实时、统一、运维简单、社区活跃等特点,网易云音乐引入了 Doris 来解决这些难题。基于 Apache Doris 的新架构如下图。
- 使用 Doris 替换了 Kylin、Druid、Clickhouse、Elasticsearch、HBase 多个引擎,Doris 统一提供查询及分析服务。
- 在业务应用上,借助 Doris 的星型和雪花模型,大幅增强了多表关联分析和灵活查询能力。
- 基于 Doris 湖仓一体的能力,可以将 Doris 中冷数据回写到 Hive 离线数仓,也可以直接基于 Doris 查询加速 Hive 中的数据,实现了湖仓融合架构。
在线广告场景
广告系统本质上是一种推荐系统,基于日志数据分析结果来影响下一次广告推荐。同时,它也是一个在线交易平台,用户在手机上看到的广告通常是经过激烈竞价的结果。所以数据分析的实时性和高并发是广告数据分析系统中的关键。
网易云音乐之前的广告实时分析系统基于 Apache Druid 构建,随着数据量的增加和分析业务的发展,原有基于 Druid 的广告实时分析系统在实时性与灵活性上尽显疲态:单表 30 亿行离线数据导入耗时长达 12 小时,复杂查询响应时间超过 5 秒,难以支持业务侧低延迟、高并发的要求。在对 Druid 和 Doris 做了深入调研和对评测后,网易云音乐决定使用 Doris 替换 Druid ,基于 Doris 构建新一代广告实时数仓,以支持驾驶舱、A/B 测试、自助 BI、内部报表以及面向广告主的高并发分析服务。
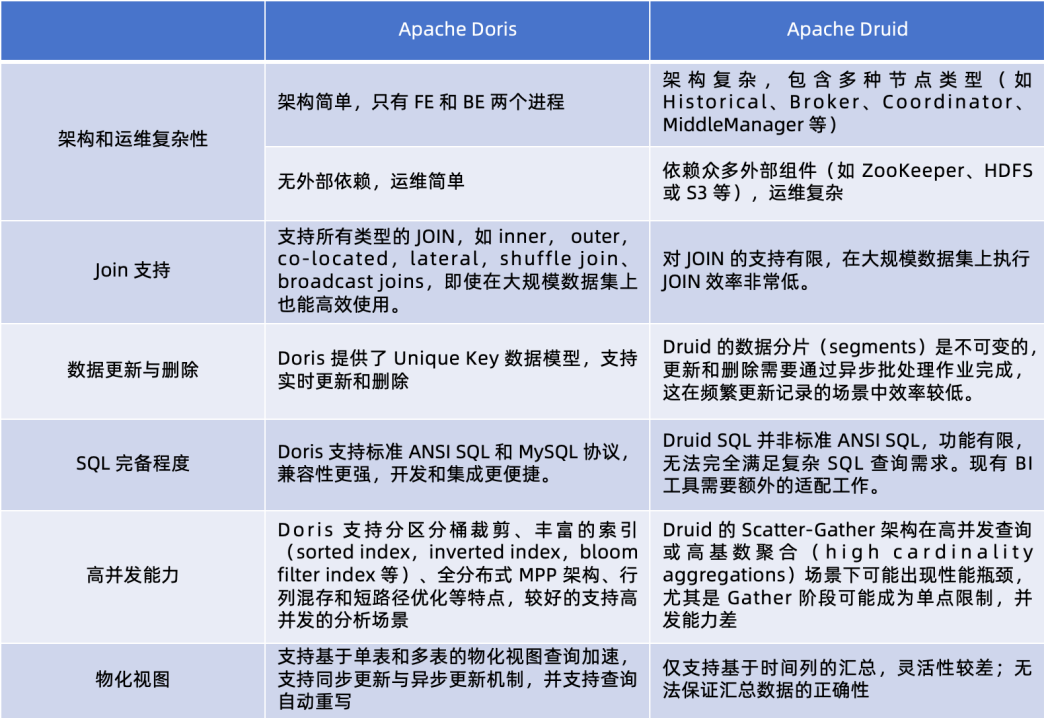
Apache Doris vs Apache Druid
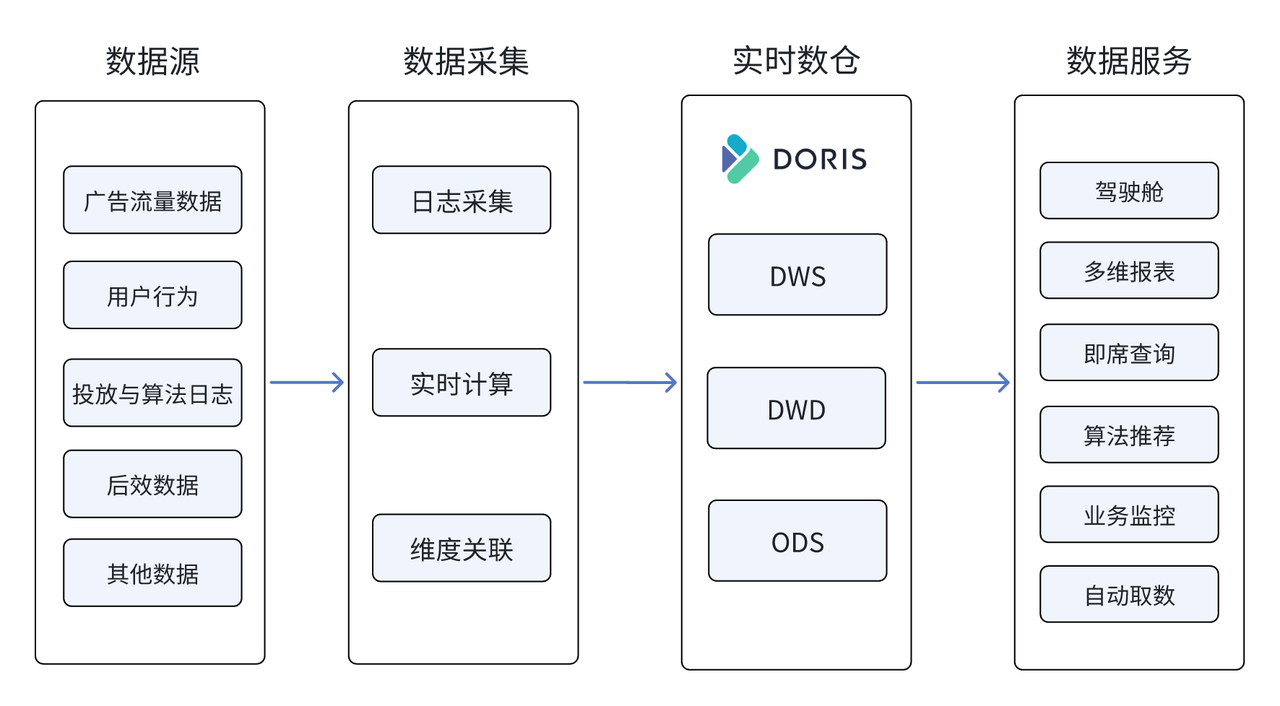
引入 Doris 后的架构如下图所示。在此架构下,成功解决了数据导入耗时过长和查询性能较差的问题,同时在数据更新和数据模型等方面实现了进一步优化。
- 在数据写入上: 引入 Doris 之后,广告系统每日可承载最高写入速率达到 307 MB/s,平均写入速率为 135 MB/s;每日写入行数最高可达 186 万 OPS/s,平均为 54.7 万 OPS/s。之前使用 Druid 导入 Hive 单表 30 亿行数据时,导入时间通常需要 7-8 小时,甚至 11-12 小时,使用 Doris 已缩短至 3~4 小时,提升 3 倍。
- 在查询优化上: 采用 Colocate Join 和 Broadcast Join 的关联优化加速了大表与维表的查询性能;合理设置物化视图,以聚合高频查询数据,进一步提升查询速度;Doris 的数据隔离能力确保了不同业务之间的资源独立,有效优化了查询负载。
- 在存储模型上: 针对大流量实时数据,首先使用 Apache Flink 进行预聚合,以减少存储压力和提升查询速度。聚合后的数据采用 Duplicate Key 模型,而维表则使用 Unique Key 模型,以确保数据的唯一性和准确性。在聚合表中,字段设置为特定类型,并根据使用频率对 key 进行排序,以提高前缀索引的命中率。同时,分区粒度设定为天,采用
log_time_minute作为分区计算参数,使查询时通过过滤log_time_minute就能有效命中分区,而减少文件扫描量。 - 在数据更新上: 广告系统使用 Unique Key 实现了行级更新,保证维表数据的实时准确性。Unique Key 模型默认更新语义为整行
UPSERT,即 UPDATE OR INSERT,若 Key 存在则更新,不存在则插入新数据。在整行UPSERT语义下,即使用户 Insert Into 指定部分列进行写入,Doris 也会在 Planner 中使用 NULL 值或默认值进行未提供列的填充。
日志与可观测性场景
网易云音乐每天都会产生大量用户行为数据、业务数据及日志数据,面对每日万亿级别数据的增量,网易云音乐早期的日志库以 ClickHouse 为核心构建,但存在运维成本高、并发能力不足、写入性能不稳定等问题。为此,使用 Apache Doris 作为日志库新方案,替换了 ClickHouse。目前已经稳定运行 3 个季度,规模达到 50 台服务器,2PB 数据,每天新增日志量超过万亿条,峰值写入吞吐达 6GB/s。
Apache Doris vs ClickHouse
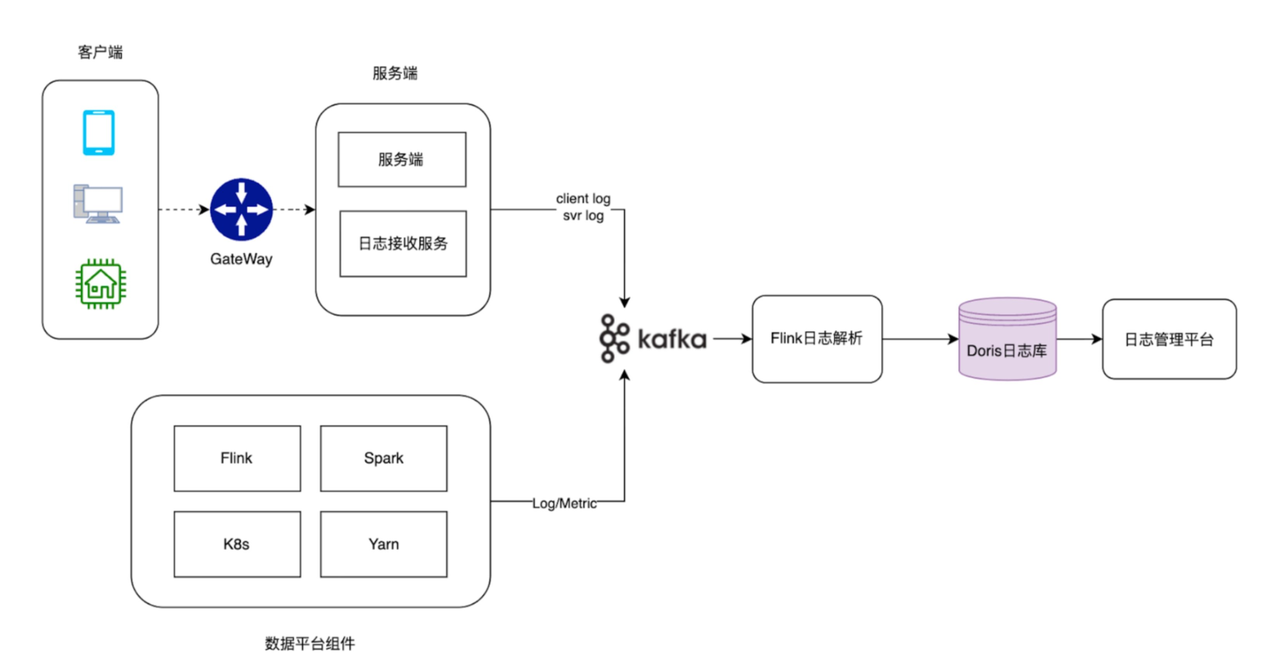
基于 Apache Doris 的日志库如下图所示。客户端、服务端日志以及数据平台组件运行日志通过采集、清洗、加工后写入 Doris 日志库中,由日志库进行明细和聚合查询,为异常用户行为、社区热点监控、任务异常分析、任务预警、大盘监控业务场景提供服务。
Doris 的引入在查询响应、并发能力、使用成本等多方面可观的收益:
- 查询响应提升:整体 P99 查询延迟降低了 30%。特别是通过倒排索引加速,Doris 的全文检索 MATCH 查询性能比 LIKE 查询提升了 3-7 倍(在查询约 6TB 数据时,LIKE 查询耗时 7-9 秒,而 MATCH 查询仅需 1-3 秒)。此外,倒排索引的全文检索具备自动的大小写和单复数归一化能力,能够高效检索出更多相关日志。
- 查询并发提升:ClickHouse 并发查询数超过 200 时就会经常出现
Too many simultaneous queries错误,而 Apache Doris 能够支撑 500+ 并发查询。Doris 还可以对单次查询的数据量和并发数进行调整,以灵活应对不同场景下的并发要求。 - 机器成本节省:得益于冷热数据的分层存储和高效压缩,机器数量减少了 50%,每年节省了数百万的成本。
- 写入稳定性提升:FE / BE 发生单点故障时,都能自动感知和重试恢复,保证服务高可用。
会员分析场景
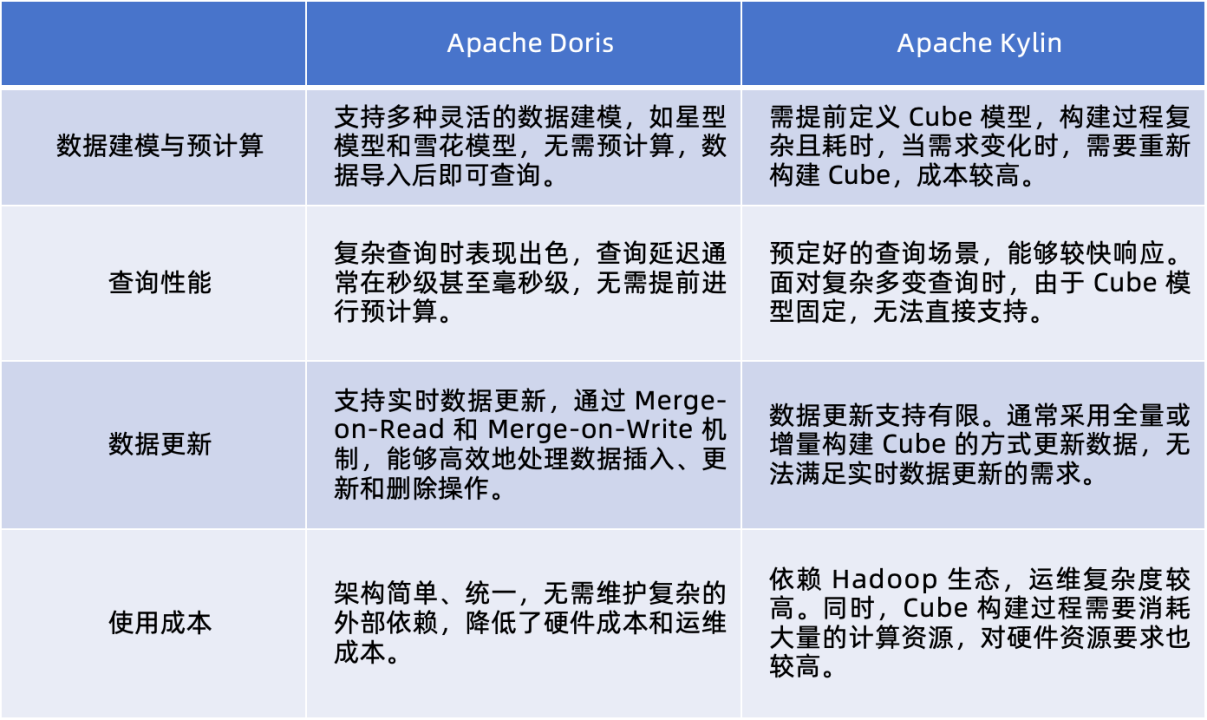
在企业精细化运营的背景下,会员数据分析已成为推动业务增长的重要动力。它承担着用户画像构建、消费行为洞察和精准营销策略制定等关键服务,这些服务主要依赖于数仓的多维分析能力。之前采用基于 Kylin 的架构,需要提前构建 Cube,数据膨胀严重、构建成本高昂、查询分析不够灵活。因此,决定引入 Apache Doris 进行优化。
Apache Doris vs Apache Kylin
引入 Apache Doris 后,具体收益如下:
-
导入效率提升 36 倍,机器使用效率提升 7 倍
早期使用 Kylin 时,数据导入需要构建大量的 Cube,而构建 Cube 需要耗费大量的时间和资源。而替换为 Doris 后,数据导入耗时从原先的 6-10 小时缩短至于 10 分钟内,导入效率至少提升 36 倍。其次,所需的存储空间也从 220 TB 减少至 13 TB,存储空间降低高达 94%,机器成本也从 35 台降低至 5 台,机器成本降低 85%。
-
查询性能提升 12 倍
该场景下,通常要求能够秒级别返回结果。而查询通常涉及多张表先进行 Join 计算、再聚合计算,Kylin 在该过程会消耗大量计算资源,并且难以保证时效性。对此,Doris 依赖其出色的复杂查询能力,并结合物化视图能够很好应对,它不仅支持直接查询,也支持透明改写,优化器会依据改写算法和代价模型,自动选择最优的物化视图来响应请求。在使用 Doris 之后,查询耗时从 4min 降到 20s,显著提升了查询性能。
结束语
网易云音乐使用 Apache Doris 替换了早期架构中 Kylin、Druid、Clickhouse、Elasticsearch、HBase 等引擎,统一了实时分析架构,广泛应用于广告系统、日志平台和会员报表分析等典型场景,在写入、查询、存储性能方面得到全面提升:导入性能提升 3~30 倍,机器成本整体降低 55%、部分场景下高达 85%,每年节省数百万成本,综合效能提升 3~7 倍等显著收益。未来,网易云音乐将进一步挖掘 Doris 能力,扩展其应用范围:
- 结合大模型 + AI:我们正在探索 Doris 与大模型 AI 能力的结合创新。目前,社区已经推出了 Apache Doris MCP Server,用户可通过自然语言在 Doris 集群上运行 SQL 查询、可利用 LLM 与 BI 进行交互、同时支持将分析结果嵌入到 AI 应用中,为用户提供了一套全面、强大且便捷的数据交互和分析工具。后续 Doris 还会在已有倒排索引全文检索基础上推出向量检索和 HybridSearch,用于 RAG 等场景,我们也将积极尝试在 AI 场景落地。
- 数据湖:计划使用数据湖、存算分离以及冷热分层策略来提升集群的稳定性。
- 稳定性建设:未来将构建集群管控平台,增强健康度监测能力。关注连接数、tablet 数量以及每个数据库的存储使用限制,避免因事务超限或存储空间超限而导致的任务失败。





![[论文阅读] 人工智能+软件工程 | 结对编程中的知识转移新图景](http://pic.xiahunao.cn/[论文阅读] 人工智能+软件工程 | 结对编程中的知识转移新图景)


:爬虫伪装)










