Springboot仿抖音app开发之用户业务模块后端复盘及相关业务知识总结
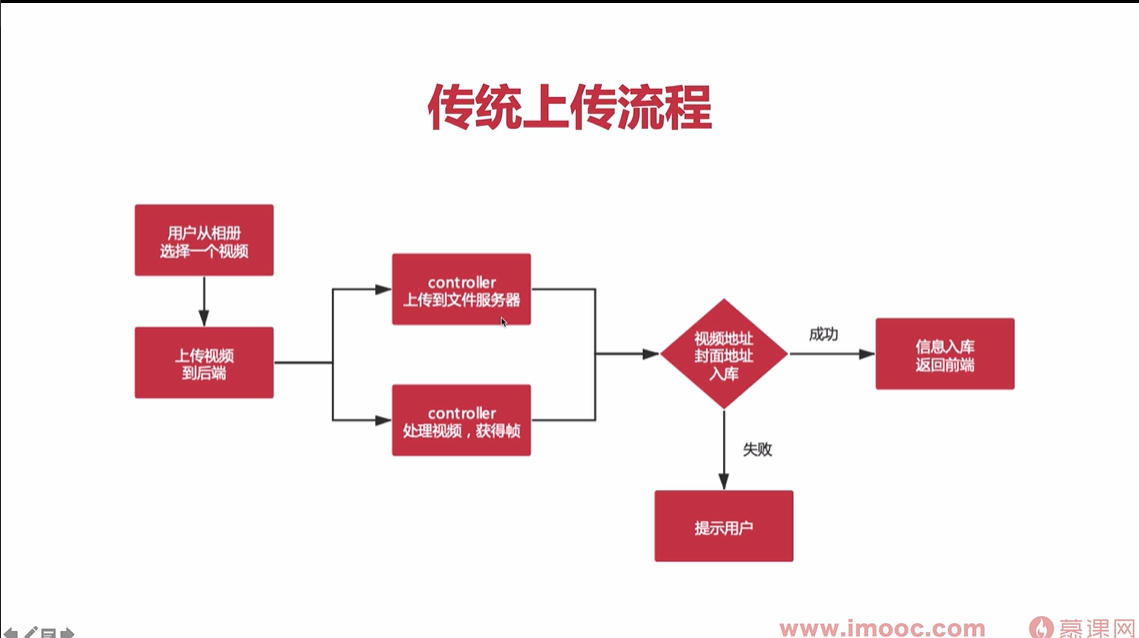
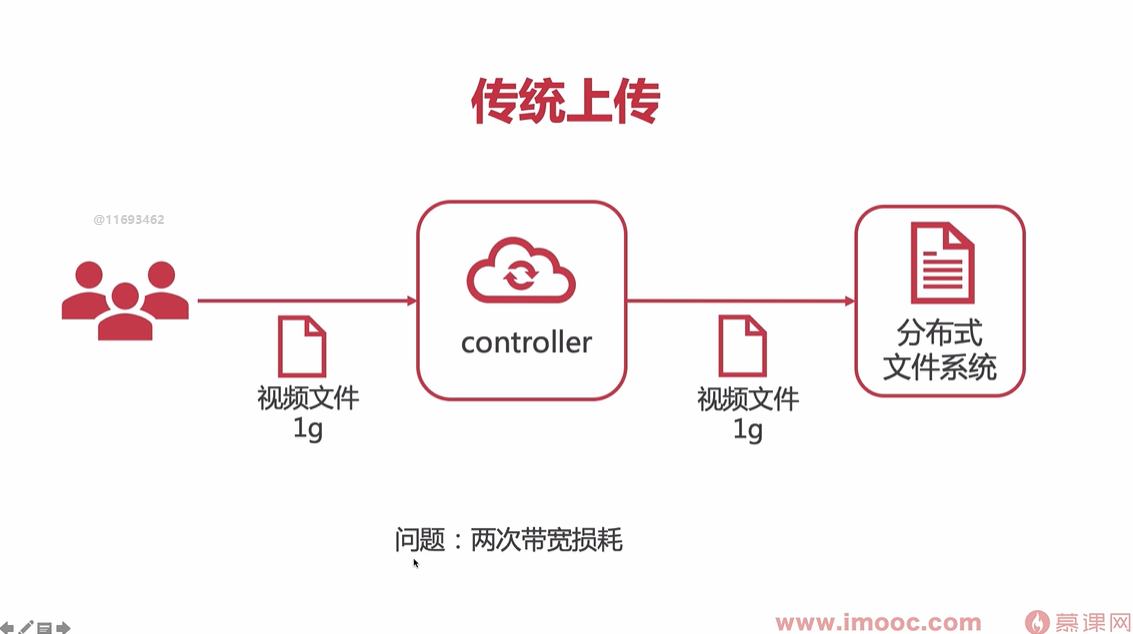
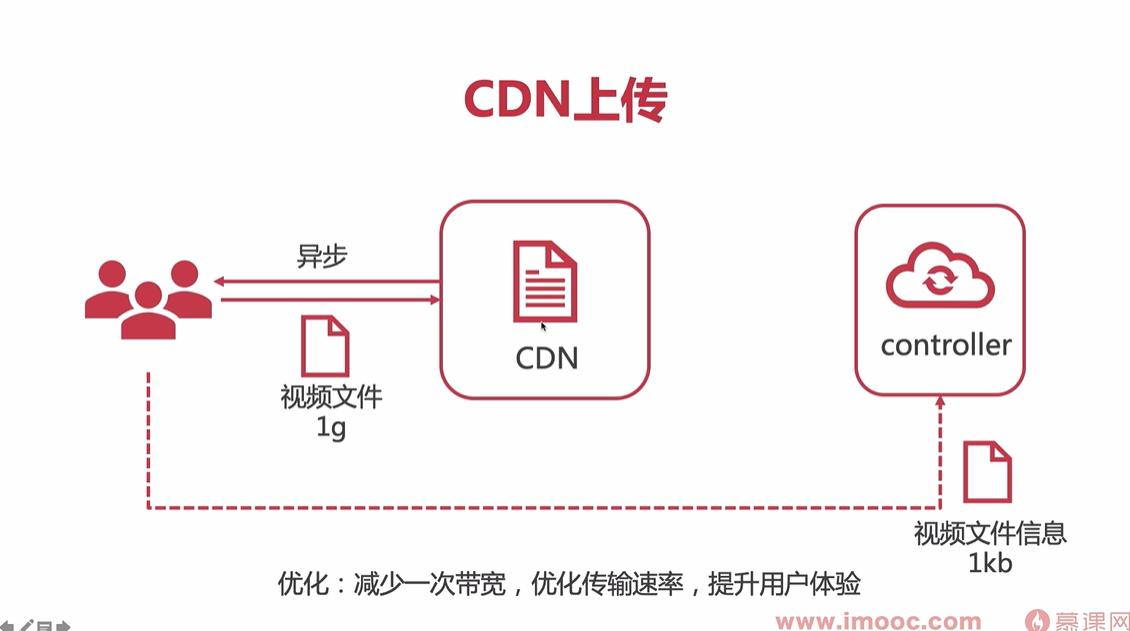
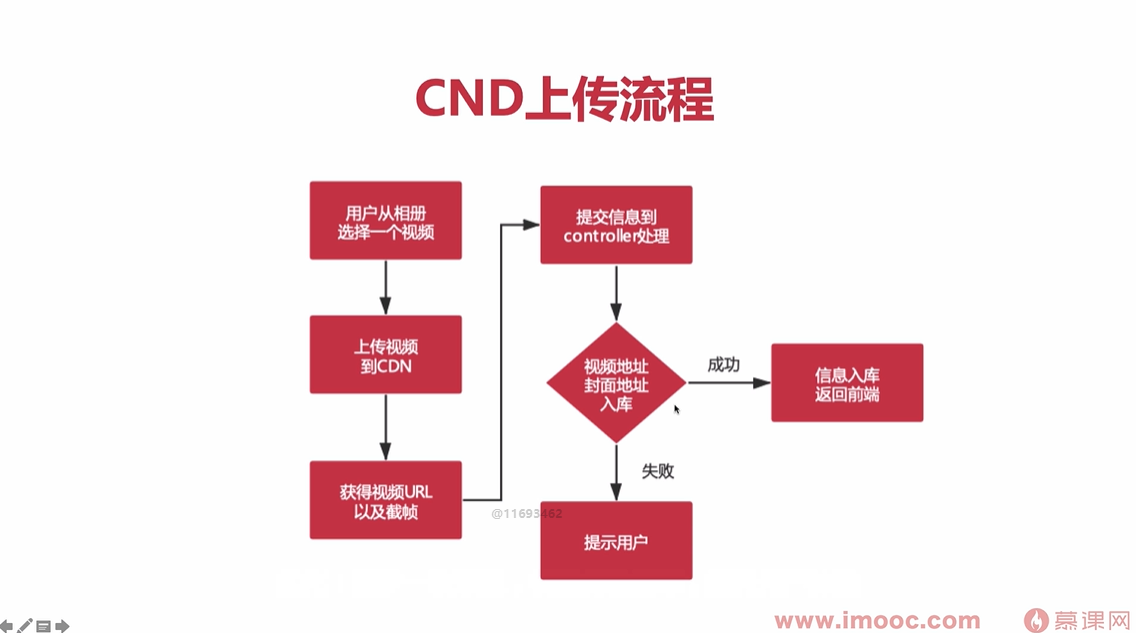
BO类和VO类的区别
BO (Business Object) - 业务对象
- 定义: 业务对象是包含业务逻辑的领域模型
- 用途: 主要用于封装业务逻辑相关的数据,在业务层(Service层)之间传递
- 特点:
- 与业务处理密切相关
- 通常包含业务处理所需的数据
- 在服务层之间或与DAO层之间传输数据
- 可能包含一些业务计算方法
VO (View Object) - 视图对象
- 定义: 视图对象是专门用于展示层的数据载体
- 用途: 主要用于封装视图展示所需的数据,在控制层(Controller)和视图层(前端)之间传递
- 特点:
- 与界面展示密切相关
- 通常只包含页面显示所需的数据
- 可能是对多个实体的组合,以适应页面展示需求
- 通常不包含业务逻辑方法
从您提供的代码示例来看:
-
VlogBO - 业务对象:
public class VlogBO {private String id;private String vlogerId;private String url;private String cover;private String title;private Integer width;private Integer height;private Integer likeCounts;private Integer commentsCounts; }- 包含视频博客的核心业务数据,如ID、URL、尺寸、点赞数等
- 可能用于视频上传、处理等业务操作
-
VlogerVO - 视图对象:
public class VlogerVO {private String vlogerId;private String nickname;private String face;private boolean isFollowed = true; }- 专注于前端展示需要的数据,如视频创作者ID、昵称、头像和关注状态
- 简化了数据结构,只包含UI层需要的信息
- 添加了UI特定的字段,如
isFollowed,这与前端交互相关
在实际应用中的区别
-
使用场景:
- BO: 主要在service层使用,封装业务逻辑所需的数据
- VO: 主要在controller层使用,向前端返回数据
-
转换关系:
- 通常会有DO(Data Object) → BO → VO的转换过程
- DO是与数据库表结构一一对应的对象
- BO可能组合多个DO,添加业务处理
- VO进一步调整BO,使其适合前端展示
-
职责分离:
- 使用这些不同类型的对象有助于实现关注点分离
- 每一层专注于自己的职责,使代码更易于维护
保存视频信息入库
1. 控制层接收请求 (VlogController)
首先,前端向 /vlog/publish 端点发送 POST 请求,携带视频信息:
@PostMapping("publish")
public GraceJSONResult publish(@RequestBody VlogBO vlogBO) {vlogService.createVlog(vlogBO);return GraceJSONResult.ok();
}
这个控制器方法:
- 使用
@RequestBody注解接收 JSON 格式的请求体,并自动反序列化为VlogBO对象 - 调用
vlogService.createVlog(vlogBO)处理业务逻辑 - 返回成功响应给前端
2. 服务层处理业务逻辑 (VlogServiceImpl)
接下来,控制器调用服务层的 createVlog 方法:
@Transactional
@Override
public void createVlog(VlogBO vlogBO) {String vid = sid.nextShort();Vlog vlog = new Vlog();BeanUtils.copyProperties(vlogBO, vlog);vlog.setId(vid);vlog.setLikeCounts(0);vlog.setCommentsCounts(0);vlog.setIsPrivate(YesOrNo.NO.type);vlog.setCreatedTime(new Date());vlog.setUpdatedTime(new Date());vlogMapper.insert(vlog);
}
在这个方法中执行了以下操作:
-
事务管理:
- 使用
@Transactional注解确保整个操作在一个事务中完成
- 使用
-
ID生成:
- 使用
sid.nextShort()生成唯一的视频ID Sid是一个分布式ID生成器,确保生成的ID在分布式环境中唯一
- 使用
-
对象转换:
- 创建数据库实体对象
Vlog - 使用
BeanUtils.copyProperties()将VlogBO的属性复制到Vlog实体
- 创建数据库实体对象
-
设置默认值:
- 设置视频ID:
vlog.setId(vid) - 初始化点赞数和评论数为0
- 设置视频为公开状态:
vlog.setIsPrivate(YesOrNo.NO.type) - 设置创建时间和更新时间为当前时间
- 设置视频ID:
-
数据库插入:
- 调用
vlogMapper.insert(vlog)将视频信息插入数据库
- 调用
3. 数据访问层执行SQL (VlogMapper)
最后,vlogMapper 执行数据库插入操作:
vlogMapper.insert(vlog);
这里的 VlogMapper 是一个 MyBatis 接口,会将 Vlog 对象映射为 SQL 插入语句并执行。
实现数据层mybatis自定义mapper与sql
实现查询短视频列表与分页功能
1. 前端请求入口
前端通过HTTP GET请求访问/indexList接口,传入以下参数:
userId:当前用户ID(可选)search:搜索关键词(可选)page:页码pageSize:每页显示条数
@GetMapping("indexList")
public GraceJSONResult indexList(@RequestParam(defaultValue = "") String userId,@RequestParam(defaultValue = "") String search,@RequestParam Integer page,@RequestParam Integer pageSize) {if (page == null) {page = COMMON_START_PAGE;}if (pageSize == null) {pageSize = COMMON_PAGE_SIZE;}PagedGridResult list = vlogService.queryIndexVlogList(userId, search, page, pageSize);return GraceJSONResult.ok(list);
}
2. 服务层处理
服务层实现分页查询逻辑:
@Override
public PagedGridResult queryIndexVlogList(String userId,String search,Integer page,Integer pageSize) {PageHelper.startPage(page, pageSize);Map<String, Object> map = new HashMap<>();if (StringUtils.isNotBlank(search)) {map.put("search", search);}List<IndexVlogVO> list = vlogMapperCustom.getIndexVlogList(map);// 注释掉的代码处理关注和点赞信息return setterPagedGrid(list, page);
}
这里有几个关键点:
- 使用
PageHelper.startPage(page, pageSize)启动分页功能 - 将查询参数封装到Map中
- 调用自定义Mapper执行查询
- 使用
setterPagedGrid方法封装分页结果
3. 数据访问层查询
自定义Mapper接口定义查询方法:
public List<IndexVlogVO> getIndexVlogList(@Param("paramMap") Map<String, Object> map);
对应的XML映射文件:
xml
<select id="getIndexVlogList" resultType="com.imooc.vo.IndexVlogVO" parameterType="map">SELECTv.id as vlogId,v.vloger_id as vlogerId,u.face as vlogerFace,u.nickname as vlogerName,v.title as content,v.url as url,v.cover as cover,v.width as width,v.height as height,v.like_counts as likeCounts,v.comments_counts as commentsCounts,v.is_private as isPrivateFROMvlog vLEFT JOINusers uONv.vloger_id = u.idWHEREv.is_private = 0<if test="paramMap.search != null and paramMap.search != ''">and v.title LIKE '%${paramMap.search}%'</if>ORDER BYv.created_timeDESC</select>
这里的SQL实现了:
- 联表查询视频和用户信息
- 只查询公开视频(
is_private = 0) - 条件性添加搜索条件(模糊查询标题)
- 按创建时间降序排序
分析
-
参数注解:
@Param("paramMap")是MyBatis的参数注解- 它将传入的Map参数在MyBatis中命名为"paramMap"
- 这个命名使得在XML映射文件中可以通过
paramMap来引用这个Map
-
Map参数:
- 方法接受一个
Map<String, Object>类型的参数 - 这个Map可以包含多个键值对,用于传递不同的查询条件
search是这个Map中的一个键,对应的值是搜索关键词
- 方法接受一个
-
关联用户信息(通过
在视频列表中直接显示创作者头像和名称LEFT JOIN users u)能够在一次查询中同时获取视频创作者的头像(u.face)和昵称(u.nickname),这样可以:
减少前端需要发起的额外请求
提升用户体验,用户可以一眼看到视频来源
4. 分页结果封装
将查询结果封装为统一的分页响应格式:
public PagedGridResult setterPagedGrid(List<?> list, Integer page) {PageInfo<?> pageList = new PageInfo<>(list);PagedGridResult gridResult = new PagedGridResult();gridResult.setRows(list);gridResult.setPage(page);gridResult.setRecords(pageList.getTotal());gridResult.setTotal(pageList.getPages());return gridResult;
}
这个方法利用PageInfo类(PageHelper提供)获取分页元数据,并封装到自定义的PagedGridResult对象中。
5. PageHelper工作原理
PageHelper通过ThreadLocal变量和拦截器实现分页功能:
- 当调用
PageHelper.startPage(page, pageSize)时,在ThreadLocal中记录分页参数 - 在执行SQL前,PageHelper拦截器会修改SQL,添加分页语句(如MySQL的LIMIT)
- 执行完SQL后,PageHelper会将查询结果封装到
Page对象中 PageInfo构造函数会自动识别Page对象并提取分页信息
${}和#{}占位符的区别
and v.title LIKE '%${paramMap.search}%'
特点:
- 直接替换:
${}是字符串直接替换,会将参数值直接替换到SQL语句中 - 无类型处理:不会添加任何类型处理或转义
- 无预编译:不使用预编译占位符,而是在SQL字符串中直接替换
例子: 如果paramMap.search = "旅行",生成的SQL将是:
and v.title LIKE '%旅行%'
2. #{}占位符 - 参数绑定
WHERE v.id = #{paramMap.vlogId}
特点:
- 参数绑定:
#{}是参数绑定,会被替换为?预编译占位符 - 自动类型处理:会根据参数类型进行适当的类型处理
- 预编译:使用预编译语句,参数会作为PreparedStatement的参数传递
- 自动转义:会自动处理特殊字符,防止SQL注入
例子: 如果paramMap.vlogId = "1001",实际执行时的SQL会先被处理为:
WHERE v.id = ?
然后值"1001"作为参数绑定到这个位置。
两者的主要区别
| 特性 | ${} | #{} |
|---|---|---|
| 执行方式 | 字符串替换 | 参数绑定 |
| SQL注入风险 | 高 | 低 |
| 类型处理 | 无 | 自动 |
| 预编译支持 | 不支持 | 支持 |
| 性能 | 对于重复查询较低 | 支持语句缓存,性能更好 |
| 使用场景 | 动态表名、列名、排序字段等 | 一般的参数传递 |
为什么在这两种情况下使用不同的占位符
1. 使用${}的场景 (模糊查询)
and v.title LIKE '%${paramMap.search}%'
这里使用${}是因为:
- LIKE语句中的百分号
%需要与搜索词直接拼接 - 使用
#{}会将整个值(包括%)当作一个参数,无法实现通配符功能
注意:这种用法存在SQL注入风险,更安全的方式是:
and v.title LIKE CONCAT('%', #{paramMap.search}, '%')
2. 使用#{}的场景 (精确匹配)
WHERE v.id = #{paramMap.vlogId}
这里使用#{}是因为:
- 是精确匹配查询,不需要字符串拼接
- 需要防止SQL注入,提高安全性
- 可以利用预编译提升性能
视频详情页展示的实现
1. 控制层处理
@GetMapping("detail")
public GraceJSONResult detail(@RequestParam(defaultValue = "") String userId,@RequestParam String vlogId) {return GraceJSONResult.ok(vlogService.getVlogDetailById(userId, vlogId));
}
控制层接收两个关键参数:
vlogId:要查询的视频ID(必传)userId:当前访问用户的ID(可选,默认为空)
这里直接调用服务层方法,并使用GraceJSONResult.ok()包装结果,提供统一的响应格式。
2. 服务层处理
@Override
public IndexVlogVO getVlogDetailById(String userId, String vlogId) {Map<String, Object> map = new HashMap<>();map.put("vlogId", vlogId);List<IndexVlogVO> list = vlogMapperCustom.getVlogDetailById(map);if (list != null && list.size() > 0 && !list.isEmpty()) {IndexVlogVO vlogVO = list.get(0);// return setterVO(vlogVO, userId);return vlogVO;}// 这里应该有返回null的逻辑
}
服务层主要逻辑:
- 创建参数Map,将视频ID存入
- 调用自定义Mapper执行数据库查询
- 从查询结果列表中获取第一个元素作为结果
- 注释掉的代码
setterVO(vlogVO, userId)可能原本用于设置用户相关状态,如是否已点赞、是否已关注视频创作者等
3. 数据访问层查询
Mapper接口定义:
public List<IndexVlogVO> getVlogDetailById(@Param("paramMap") Map<String, Object> map);
XML映射文件中的SQL查询:
<select id="getVlogDetailById" parameterType="map" resultType="com.imooc.vo.IndexVlogVO">SELECTv.id as vlogId,v.vloger_id as vlogerId,u.face as vlogerFace,u.nickname as vlogerName,v.title as content,v.url as url,v.cover as cover,v.width as width,v.height as height,v.like_counts as likeCounts,v.comments_counts as commentsCounts,v.is_private as isPrivateFROMvlog vLEFT JOINusers uONv.vloger_id = u.idWHEREv.id = #{paramMap.vlogId}</select>
这个SQL查询:
- 联合查询视频表(
vlog)和用户表(users) - 通过LEFT JOIN关联视频创作者信息
- 使用
vlogId作为查询条件 - 查询结果包含视频基本信息和创作者信息
- 结果字段别名与VO对象属性名对应,实现自动映射
4. 数据结构设计
从SQL查询中可以看出,IndexVlogVO对象包含以下信息:
-
视频信息:
- vlogId:视频ID
- content:视频标题/内容
- url:视频地址
- cover:视频封面
- width/height:视频尺寸
- likeCounts:点赞数
- commentsCounts:评论数
- isPrivate:是否私有
-
创作者信息:
- vlogerId:创作者ID
- vlogerFace:创作者头像
- vlogerName:创作者昵称
5. 业务处理特点
- 单一职责:各层次职责明确,控制层处理请求,服务层处理业务,数据访问层执行查询
- 数据封装:使用VO对象封装前端展示所需数据
- 关联查询:一次查询获取视频和创作者信息,减少数据库交互
- 参数传递:使用Map传递查询参数,灵活性高
- 状态设计:预留了设置用户与视频交互状态的逻辑(被注释掉的
setterVO方法)
6. 实现特点与优势
- 代码复用:与首页视频列表使用类似的数据结构和查询逻辑
- 查询效率:通过ID直接查询,高效精准
- 结构清晰:各层次分工明确,易于维护
- 扩展性好:预留了添加用户交互状态的扩展点
- 统一响应:使用
GraceJSONResult统一API响应格式
实现转为私密或公开视频
1. 控制层处理请求
应用提供了两个端点,分别用于将视频设为私密或公开:
@PostMapping("changeToPrivate")
public GraceJSONResult changeToPrivate(@RequestParam String vlogerId,@RequestParam String Id) {vlogService.changeToPrivateOrPublic(vlogerId,Id,YesOrNo.YES.type);return GraceJSONResult.ok();
}@PostMapping("changeToPublic")
public GraceJSONResult changeToPublic(@RequestParam String vlogerId,@RequestParam String Id) {vlogService.changeToPrivateOrPublic(vlogerId,Id,YesOrNo.NO.type);return GraceJSONResult.ok();
}
这两个方法的特点:
- 都使用HTTP POST请求
- 接收相同的参数:
vlogerId(创作者ID)和Id(视频ID) - 调用同一个服务方法,但传入不同的状态值
- 使用枚举
YesOrNo来表示状态(YES表示私密,NO表示公开) - 返回统一的成功响应
2. 服务层实现业务逻辑
服务层实现了统一的方法来处理状态变更:
@Transactional
@Override
public void changeToPrivateOrPublic(String userId, String vlogId, Integer yesOrNo) {Example example = new Example(Vlog.class);Example.Criteria criteria = example.createCriteria();criteria.andEqualTo("id", vlogId);criteria.andEqualTo("vlogerId", userId);Vlog pendingVlog = new Vlog();pendingVlog.setIsPrivate(yesOrNo);vlogMapper.updateByExampleSelective(pendingVlog, example);
}
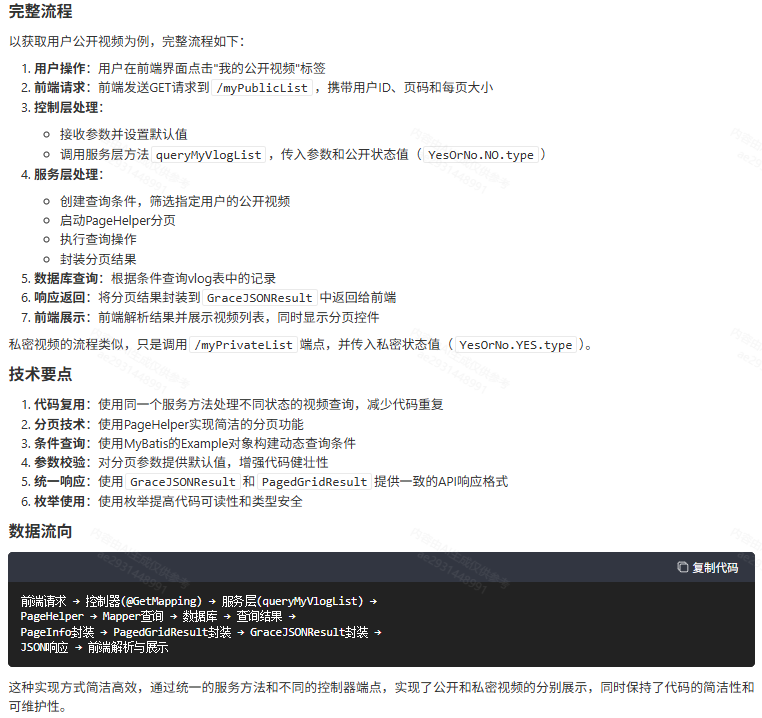
展示我的公开和私密视频
1. 控制层处理请求
应用提供了两个端点,分别用于获取用户的公开和私密视频列表:
@GetMapping("myPublicList")
public GraceJSONResult myPublicList(@RequestParam String userId,@RequestParam Integer page,@RequestParam Integer pageSize) {if (page == null) {page = COMMON_START_PAGE;}if (pageSize == null) {pageSize = COMMON_PAGE_SIZE;}PagedGridResult gridResult = vlogService.queryMyVlogList(userId,page,pageSize,YesOrNo.NO.type);return GraceJSONResult.ok(gridResult);
}@GetMapping("myPrivateList")
public GraceJSONResult myPrivateList(@RequestParam String vlogerId,@RequestParam Integer page,@RequestParam Integer pageSize) {if (page == null) {page = COMMON_START_PAGE;}if (pageSize == null) {pageSize = COMMON_PAGE_SIZE;}PagedGridResult gridResult = vlogService.queryMyVlogList(vlogerId,page,pageSize,YesOrNo.YES.type);return GraceJSONResult.ok(gridResult);
}
这两个方法的特点:
- 都使用HTTP GET请求
- 接收相同的参数:用户ID、页码和每页大小
- 对页码和每页大小提供默认值
- 调用同一个服务方法,但传入不同的状态值
- 返回统一格式的分页结果
2. 服务层实现业务逻辑
服务层实现了统一的方法来查询不同状态的视频:
@Override
public PagedGridResult queryMyVlogList(String userId, Integer page, Integer pageSize, Integer yesOrNo) {Example example = new Example(Vlog.class);Example.Criteria criteria = example.createCriteria();criteria.andEqualTo("vlogerId", userId);criteria.andEqualTo("isPrivate", yesOrNo);PageHelper.startPage(page, pageSize);List<Vlog> list = vlogMapper.selectByExample(example);return setterPagedGrid(list, page);
}
这个方法的关键点:
- 查询条件:通过用户ID和私密状态筛选视频
- 分页实现:使用PageHelper进行分页
- 通用Mapper:使用MyBatis通用Mapper执行查询
- 结果封装:调用
setterPagedGrid方法封装分页结果
3. 分页结果封装
前面代码片段中有setterPagedGrid方法用于封装分页结果:
public PagedGridResult setterPagedGrid(List<?> list, Integer page) {PageInfo<?> pageList = new PageInfo<>(list);PagedGridResult gridResult = new PagedGridResult();gridResult.setRows(list);gridResult.setPage(page);gridResult.setRecords(pageList.getTotal());gridResult.setTotal(pageList.getPages());return gridResult;
}
该方法将原始列表和分页信息封装到PagedGridResult对象中,包括:
- 数据行(rows)
- 当前页码(page)
- 总记录数(records)
- 总页数(total)
4. 枚举使用
代码使用了YesOrNo枚举来表示视频状态:
YesOrNo.NO.type:表示公开视频(值可能为0)YesOrNo.YES.type:表示私密视频(值可能为1)
)




:OpenBCI_GUI:从环境搭建到数据可视化(上))

深度解析:原理、类型、历史案例及共识机制的影响)
调试、发布)










