前言
生成对抗网络(GAN)是lan J. Goodfellow团队在2014年提出的生成架构, 该架构自诞生起,就产生了很多的话题,更是被称为生成对抗网络是“新世纪以来机器学习领域内最有趣的想法”。如今,基于生成对抗网络思想的架构在图像处理、生成方面的能力越来越强大,已经成为视觉领域中不可忽视的存在,可以这样说,GAN的诞生,让这个世界的物理表象变得具有欺骗性了。
一、GAN的原理
最初GAN的目标就是用来生成图像,首先GAN的目标就是利用生成器 G 根据真实数据生成的假数据,并希望生成的假数据能够以假乱真,从而骗过判别器 D;同时,又希望判别器 D 能够区分真假数据。如下所示:
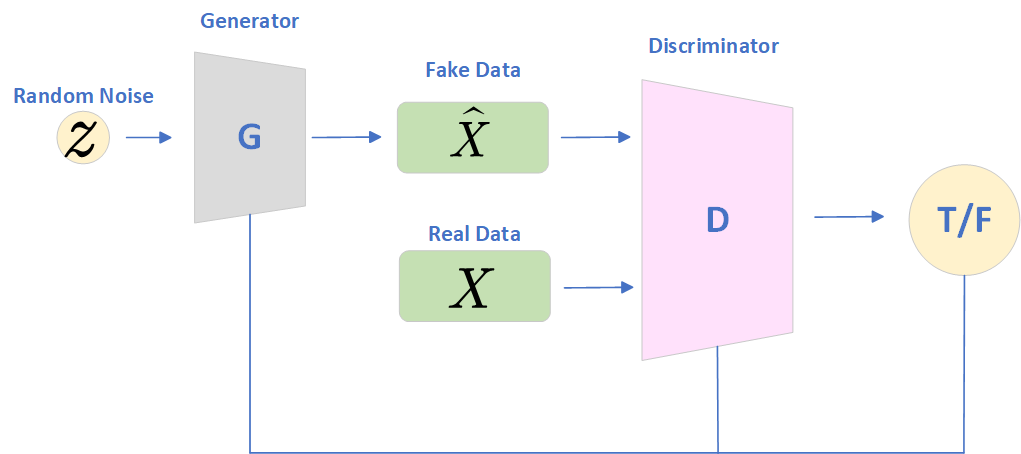
整个网络由生成器 G 和判别器 D 构成,随机初始化噪声数据,然后输入生成器生成假数据,判别器判断生成的数据和真实数据哪个才是真的。生成器没有标签,是无监督网络,判别器是监督网络,标签是“真或假”(0/1)。原始论文规定判别器输出当前数据为真的概率(标签为1的概率),当概率大于0.5,判别器认为样本是真实数据,小于0.5,判别器认为样本是由生成器生成的假数据。
其核心思想就是:
- 通过两个神经网络(生成器 G 与判别器 D)之间的对抗博弈,让生成器学会产生以假乱真的数据
二、GAN的损失函数
其实GAN的整过训练过程就是一个零和博弈。在训练过程中,生成器和判别器的目标是相互竞争的:生成器的任务是尽可能生成以假乱真的数据,让判别器判断不出来,其目的就是让判别器的准确性降低;箱单,判别器的目的是尽量判断出真伪,让自己判断的准确性越来越高。
当生成器生成的数据越来越真时,判别器为保证自己的准确性,就会朝着判断能力强的方向迭代。当判断器判断能力越来越强大时,生成器为了保证自己生成的真实性,就会朝着生成能力强的方向迭代。在整个的关系中,判别器的准确性由论文中定义的交叉熵 来衡量,判别器和生成器共同影响着
。
1. 交叉熵 V
在生成器和判别器的特殊关系中,GAN的目标损失 为:
由于期望代表的是数据均值,因此,式子可以改为:
其中, 为真实数据,
为与真实数据结构相似的随机噪音,
为生成器生成的假数据,
为判别器在真实数据
上的判别的结果,
为判别器在假数据(
)上判别的结果,其中
与
都是样本为真(标签为1)的概率。
由于
与
都是概率,所以值在 (0,1] 之间,因此,取对数后的值域为
,所以损失
的值域也在
2. 对于判别器损失
在 V 的表达式中,对数都与判别器有关,因此,对于判别器来说, 即判别器的损失:
我解释一下,判别器的目的是尽量使自己作出正确的判断,且判别器输出的是标签为真的概率,因此,判别器的最佳表现是:对于所有在真实数据上的判别器的输出 都接近1,所有假数据上判别器
都接近0,因此,对于判别器的最佳损失就是:
- 因此,判别器希望
越大越好,即
,判别能力越强,值越大,理想情况下值最大为0。
3. 对于生成器损失
在 的表达式中,生成器只会影响
,因此只有
的后半部分的表达式与生成器有关,即:
去掉常数项:
生成器的目标是尽可能使生成的假数据让判别器判断为真,即 越接近1越好,因此,对于生成器的最佳损失为:
- 可以看出,生成器希望
越小越好,即
无限接近负无穷,因此生成器的本质就是追求
- 从整个GAN的角度看,我们的目标就是与生成器的目标一致,因此,对于我们而言,
4. 求最优解
上面我已经推导了GAN损失函数 的由来,那么如何求最优解呢?下面我们来推导一下:
第一步:固定生成器 G,求最优判别器 D:
当我们固定 G 时,要求最优判别器 D,此时 G 是确定的,因此 生成了一个伪样本
,这意味这我们可以把:
,
服从分布
,即
因此,第二项期望就可以写作:
所以,原式就变为了:
我们将期望转化为积分:
将两个分布 和
放在同一个积分中:
这是一个关于 的泛化优化问题,对每个点
,我们要最大化,令:
对 求导数,令导数为 0,得到最优
:
解得:
第二步:将 代入原损失函数,优化生成器的目标
:
我们对其化简:
这里,我们介绍一个概念,Jensen-Shannon散度,是衡量两个分布差异的对称度量,它与KL散度有如下关系:
因此,最终式子变为:
若要使得 取得最小,那么KL散度应当为0,当KL散度为0时,就相当于:
由此可知, 逼近
时,目标函数取得最优值,并且当
判别器就无法判断出样本是来自假数据样本 ,还是来自真实数据样本
了,此时生成器的生成效果便达到了最好。
三、GAN的训练流程
接下来,我将使用MINST数据集来实现一下GAN的训练流程:
训练过程:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torchvision.utils import save_image, make_grid
from torch.utils.tensorboard import SummaryWriter
import os# 定义生成器与判别器
class Generator(nn.Module):def __init__(self, latent_dim):super().__init__()self.net = nn.Sequential(nn.ConvTranspose2d(latent_dim, 256, 4, 1, 0), # 1x1 -> 4x4nn.BatchNorm2d(256),nn.ReLU(True),nn.ConvTranspose2d(256, 128, 4, 2, 1), # 4x4 -> 8x8nn.BatchNorm2d(128),nn.ReLU(True),nn.ConvTranspose2d(128, 64, 4, 2, 1), # 8x8 -> 16x16nn.BatchNorm2d(64),nn.ReLU(True),nn.ConvTranspose2d(64, 1, 4, 4, 0), # 16x16 -> 64x64nn.Tanh())def forward(self, z):return self.net(z)class Discriminator(nn.Module):def __init__(self):super().__init__()self.net = nn.Sequential(nn.Conv2d(1, 64, 4, 4, 0), # 64x64 -> 16x16nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(64, 128, 4, 2, 1), # 16x16 -> 8x8nn.BatchNorm2d(128),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(128, 256, 4, 2, 1), # 8x8 -> 4x4nn.BatchNorm2d(256),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(256, 1, 4, 1, 0), # 4x4 -> 1x1nn.Sigmoid())def forward(self, x):return self.net(x).view(-1, 1).squeeze(1)
# 设置超参数
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
latent_dim = 100
batch_size = 128
epochs = 50
image_size = 64
lr = 2e-4
log_dir = "./GAN/runs/log"
sample_dir = "./GAN/samples"
os.makedirs(sample_dir, exist_ok=True)# 加载数据
transform = transforms.Compose([transforms.Resize(image_size),transforms.ToTensor(),transforms.Normalize([0.5], [0.5])
])
dataset = datasets.MNIST(root='./GAN', train=True, transform=transform, download=False)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True)G = Generator(latent_dim).to(device)
D = Discriminator().to(device)
criterion = nn.BCELoss()
optimizer_G = optim.Adam(G.parameters(), lr=lr, betas=(0.5, 0.999))
optimizer_D = optim.Adam(D.parameters(), lr=lr, betas=(0.5, 0.999))writer = SummaryWriter(log_dir)
fixed_noise = torch.randn(64, latent_dim, 1, 1, device=device)
best_d_loss = float('inf')
# 训练
for epoch in range(epochs):for i, (real_imgs, _) in enumerate(dataloader):real_imgs = real_imgs.to(device)valid = torch.ones(real_imgs.size(0), device=device)fake = torch.zeros(real_imgs.size(0), device=device)# -------------------# 训练生成器 G# -------------------optimizer_G.zero_grad()z = torch.randn(real_imgs.size(0), latent_dim, 1, 1, device=device)gen_imgs = G(z)g_loss = criterion(D(gen_imgs), valid)g_loss.backward()optimizer_G.step()# -----------------------# 训练判别器 D# -----------------------optimizer_D.zero_grad()real_loss = criterion(D(real_imgs), valid)fake_loss = criterion(D(gen_imgs.detach()), fake)d_loss = real_loss + fake_lossd_loss.backward()optimizer_D.step()# 日志记录batches_done = epoch * len(dataloader) + iwriter.add_scalar("Loss/Generator", g_loss.item(), batches_done)writer.add_scalar("Loss/Discriminator", d_loss.item(), batches_done)print(f"Epoch {epoch+1}/{epochs} | G_loss: {g_loss.item():.4f} | D_loss: {d_loss.item():.4f}")# 保存最优模型if d_loss.item() < best_d_loss:best_d_loss = d_loss.item()torch.save(G.state_dict(), "best_generator.pth")torch.save(D.state_dict(), "best_discriminator.pth")生成:
# 生成新图像
加载保存训练好的生成器
G.load_state_dict(torch.load("best_generator.pth", map_location=device))
G.eval()
noise = torch.randn(64, latent_dim, 1, 1, device=device)
with torch.no_grad():fake_imgs = G(noise).detach().cpu()
os.makedirs("final_samples", exist_ok=True)
grid = make_grid(fake_imgs, nrow=8, normalize=True)
save_image(grid, "final_samples/generated_grid.png")在这里,我简单的训练了一个GAN网络,并生成64张数字图片,生成效果如下:

可以看到,简单训练的GAN能够生成不错的效果。
总结
以上就是本文对GAN原理的全部介绍,相信小伙伴们在看完之后对GAN的原理会有更深刻的理解。总的来说,GAN为我们带来了新的视角,它让我们不再试图去拟合复杂的数据分布,而是建立一个“博弈系统”,通过竞争机制驱动模型学习。从14年到现在,基于GAN架构的生成模型已经发展了很多,比如StyleGAN、CycleGAN等模型,但是它们的核心仍然是GAN的架构。
如果小伙伴们觉得本文对各位有帮助,欢迎:👍点赞 | ⭐ 收藏 | 🔔 关注。我将持续在专栏《人工智能》中更新人工智能知识,帮助各位小伙伴们打好扎实的理论与操作基础,欢迎🔔订阅本专栏,向AI工程师进阶!














(附安装包))
Git + GitHub Actions:自动化工作流如何让我的开发效率提升200%?)

:多核任务调度策略详解)

【Linux操作系统】)