SAE(Sparse Autoencoders)稀疏自编码器
0.引言
大模型一直被视为一个“黑箱”,研究人员对其内部神经元如何相互作用以实现功能的机制尚不清楚。因此研究机理可解释性(Mechanistic Interpretability)就成为了一个热门研究方向。大模型的复杂之处在于“叠加”(superposition)现象,即一个神经元的激活可能同时是多个完全不相关特征的组成部分,简单说例如“哈基狗”的特征可能需要激活一组神经元(我们称之为集合N),而表达“小黑子”,则需要激活另一组神经元(集合M);叠加现象就意味着,集合N和M之间存在交集,这就导致我们很难通过观察单个神经元的激活,来断定它究竟在“想”什么。最理想的情况肯定就是一个神经元对应一个特征,而SAE做的就是这样的事情,将这种叠加状态剥离出来,类似一种升维再投影的过程。
1. SAE的工作机制
稀疏自编码器(SAE)通过一个巧妙的“先扩展、后压缩”的过程,来解构神经网络内部复杂的叠加状态。它首先通过编码器将输入向量投射到一个维度远高于自身的特征空间,然后经由解码器将其重建回原始维度。其训练目标看似简单——让输出与输入尽可能一致,但真正的精髓在于训练过程中施加的“稀疏性惩罚”。
这个惩罚机制迫使那个高维的中间向量变得极其稀疏,大部分维度上的激活值都因过小而被忽略或置零。这正是SAE设计的核心所在:它认为,之所以会出现多个神经元功能叠加的“杂糅”现象,根源在于表达空间不足。因此,通过提供一个巨大的潜在特征空间,并强制模型每次只使用其中一小部分,SAE就能有效地将不同的特征分离到不同的维度上,力求达到“一个维度代表一个精细特征”的理想状态。
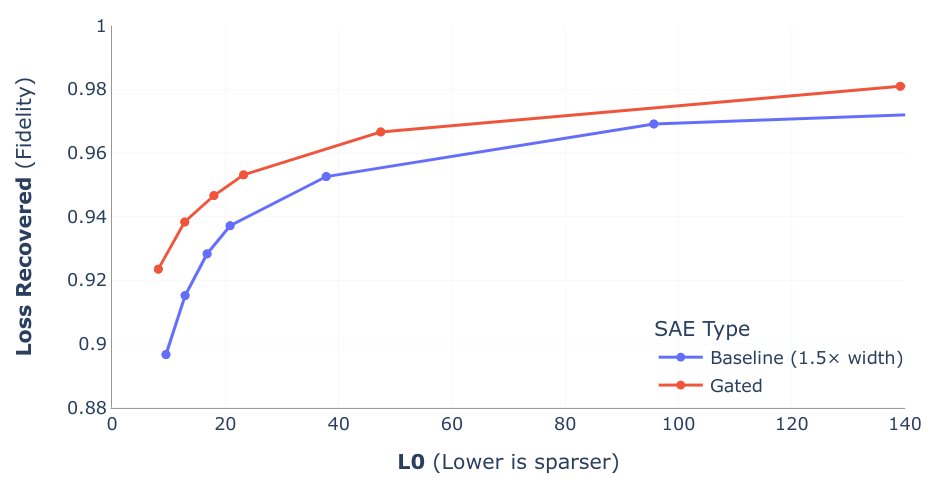
当然,这是一个有损的转换,总要在重建的“准确性”和特征的“稀疏性”之间做出权衡。SAE的训练,本质上就是在寻找这个最佳平衡点的旅程。下图纵轴可以看成代表信息的保留率(信息损失恢复率),横轴可以看成稀疏向量中激活的个数(L0 范数是衡量一个向量稀疏程度的指标;L0 范数越小,代表这个向量越稀疏),最理想的SAE效果就是接近左上点(0,1)。
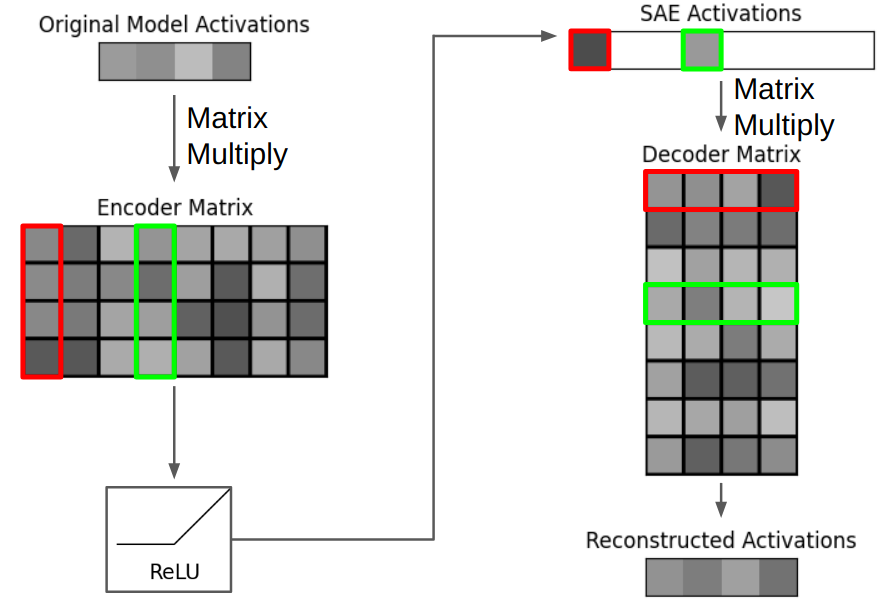
理想情况下,SAE表示中的每个激活的数字都对应于某个可理解的组件。假设,当大模型处理一段Python代码时,其模型内部的一个12288维的激活向量 [0.8, -2.1, 5.5, ...] 对它来说就意味着**“这是一个Python代码块”**。这个向量不仅仅代表“代码”,它还可能包含了代码的结构、缩进、常见关键字等语法风格的复杂信息。
现在,我们有一个SAE,其解码器是一个形状为 (49512, 12288) 的巨大矩阵。我们可以把这个解码器看作是一个拥有49512个“概念定义”的字典,每个“定义”都是一个12288维的向量。
假设,经过训练,这个SAE中编号为 #8888 的特征,其使命就是专门识别和表示“Python代码”。那么,该特征对应的解码器向量(Decoder Vector #8888),就会在数值上非常接近GPT-4内部代表“Python代码”的那个向量,即约等于 [0.8, -2.1, 5.5, ...]。
2. SAE的应用——如何确定SAE中的特征和实际特征的关系
定性分析:分析最大激活输入 (Maximally Activating Inputs)
- 首先,在一个非常庞大的、多样化的数据集(例如包含数十亿个句子的文本库)上运行大语言模型,并记录下每一个SAE特征在处理每个文本片段时的激活值。
- 然后,针对某一个你感兴趣的SAE特征(例如特征编号317),找出那些让这个特征产生最高激活值的文本输入。
- 最后,由人类研究员来审查这些“最大激活样本”,并试图找出它们之间共同的、可被人类理解的模式或概念。
因果干预 (Causal Interventions)
- 基于第一步的定性分析,假设已经对一个特征有了一个假设(例如,“特征317代表‘哈基狗’这个概念”)。
- SAE的解码器部分为这个特征学习到了一个向量,这个向量被认为是“哈基狗”这个概念在模型激活空间中的“真实方向”。
- 研究员可以在模型处理任何输入时,人为地将这个特征的解码器向量添加到模型的中间激活中。
当Anthropic的研究人员将他们认为是“金门大桥”特征的向量注入到Claude模型的激活中时,Claude在每一个回答中都被迫地开始提及金门大桥。这个实验强有力地证明了该特征与“金门大桥”这个概念之间的因果关系。
最后,强烈推荐一下Adam Karvonen大佬的https://adamkarvonen.github.io/machine_learning/2024/06/11/sae-intuitions.html笔记,看了十几个视频笔记,还是这篇讲解得最到位。







)



)


 编译环境)




