解决 MySQL 主从复制延迟需要从架构设计、参数调优、硬件优化等多维度综合处理。
一、根本原因分析
主从延迟的本质是:从库的 SQL 线程重放速度 < 主库的写入速度 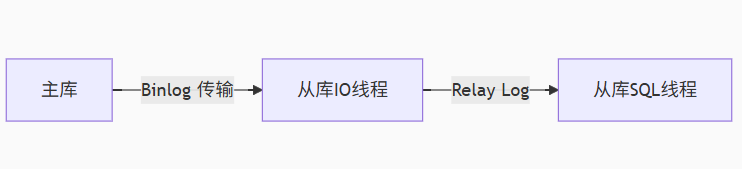
常见瓶颈点:
单线程回放(MySQL 5.6 前)
从库硬件配置低(CPU/磁盘/网络)
大事务/无主键写入
跨网络传输抖动
二、八大解决方案及操作步骤
方案 1:启用多线程复制(MTS)
适用版本:MySQL 5.6+
原理:并行回放不同数据库的事务
-- 查看当前配置
SHOW VARIABLES LIKE 'slave_parallel_type'; -- 需为 DATABASE
SHOW VARIABLES LIKE 'slave_parallel_workers';-- 动态设置(建议值为 CPU 核数的 2-4 倍)
STOP SLAVE;
SET GLOBAL slave_parallel_workers = 8;
START SLAVE;效果:提升 300% 以上的回放速度(需多库写入场景)
方案 2:升级到 MySQL 8.0 的 WRITESET 并行复制
核心优势:事务级并行(不依赖库拆分)
-- 主库配置
[mysqld]
binlog_transaction_dependency_tracking = WRITESET
slave_parallel_type = LOGICAL_CLOCK
slave_parallel_workers = 16-- 从库重启生效性能对比:比库级并行快 5-10 倍,TPS 提升 80%+
方案 3:硬件优化(关键!)
| 组件 | 优化方向 | 具体操作 |
|---|---|---|
| 磁盘 | 使用 NVMe SSD | 替换 SATA SSD/HDD |
| CPU | 主从库配置对称 | 从库 CPU 不低于主库 |
| 网络 | 内网万兆互联 | 主从同机房 ≤ 0.1ms 延迟 |
| 内存 | 保证热数据在内存 | 设置 innodb_buffer_pool_size = 机器内存的 80% |
方案 4:避免大事务
问题事务特征:
-- 危险操作(删除 1 亿行数据)
DELETE FROM logs WHERE create_time < '2020-01-01';优化方案:
分批操作:
WHILE (受影响行数 > 0) DODELETE FROM logs WHERE create_time < '2020-01-01' LIMIT 1000;COMMIT; END WHILE业务设计:归档历史数据到 ClickHouse 等列存数据库
方案 5:强制主键设计
无主键表的灾难:
从库全表扫描更新
行锁升级为表锁
解决方案:
-- 检查无主键表
SELECT tables.table_schema, tables.table_name
FROM information_schema.tables
LEFT JOIN (SELECT table_schema, table_name FROM information_schema.statistics GROUP BY table_schema, table_name, index_nameHAVING SUM(CASE WHEN non_unique=0 AND nullable!='YES' THEN 1 ELSE 0 END)=COUNT(*)
) puks
ON tables.table_schema=puks.table_schema AND tables.table_name=puks.table_name
WHERE puks.table_name IS NULL
AND tables.table_schema NOT IN ('sys','mysql','information_schema','performance_schema');方案 6:读写分离智能路由
架构设计:
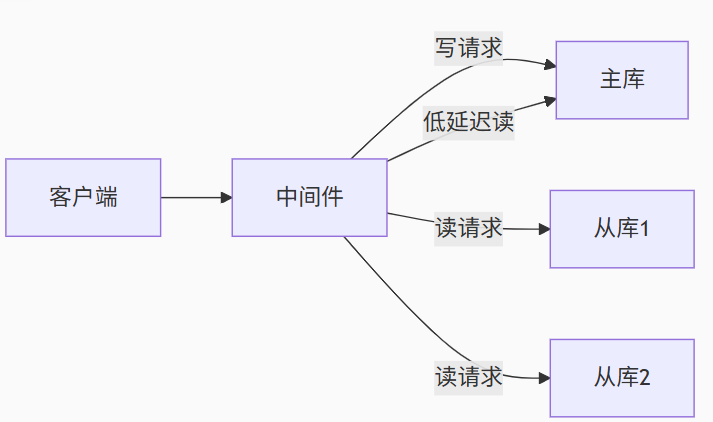
路由规则(以 ShardingSphere 为例):
rules:
- !READWRITE_SPLITTINGdataSources:main_ds:writeDataSourceName: masterreadDataSourceNames:- replica0- replica1loadBalancerName: random_weight# 关键配置:开启事务内读主库transactionalReadQueryStrategy: PRIMARY# 读请求延迟阈值queryConsistent: truemaxReplicaDelay: 500 # 单位毫秒方案 7:半同步复制(数据强一致)
原理:主库提交前需收到至少一个从库 ACK
-- 主库安装插件
INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';-- 配置参数
SET GLOBAL rpl_semi_sync_master_enabled = 1;
SET GLOBAL rpl_semi_sync_master_timeout = 1000; -- 超时降级为异步-- 从库配置
INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
SET GLOBAL rpl_semi_sync_slave_enabled = 1;代价:主库写入性能下降 20%-30%
方案 8:精细化监控与告警
关键监控指标:
-- 查看延迟秒数(不精确!)
SHOW SLAVE STATUS\G
Seconds_Behind_Master: 0 -- 精确延迟检测(推荐)
pt-heartbeat --user=monitor --password=*** \
--create-table --database heartbeat \
--update --interval=1 --daemonize-- 查询真实延迟
SELECT TIMEDIFF(NOW(), ts) AS delay
FROM heartbeat.heartbeat;告警阈值:
警告:延迟 > 5 秒
严重:延迟 > 30 秒
三、方案组合建议
| 场景 | 推荐方案组合 |
|---|---|
| 电商读多写少 | MTS + 读写分离中间件 + NVMe SSD |
| 金融交易系统 | 半同步复制 + WRITESET + 心跳监控 |
| 日志分析从库 | 禁用复制延迟检查 + 硬件资源隔离 |
| 云数据库(RDS/Aurora) | 启用代理读写分离 + 设置延迟阈值 |
四、极端情况应急方案
当延迟突然飙升时:
临时切换读主库:
# 通过 ProxySQL 动态路由 UPDATE mysql_query_rules SET destination_hostgroup=1 WHERE rule_id=2; -- 原读规则指向主库组 LOAD MYSQL QUERY RULES TO RUNTIME;跳过错误事务(慎用!):
STOP SLAVE; SET GLOBAL SQL_SLAVE_SKIP_COUNTER = 1; START SLAVE;重建从库:
mysqldump --single-transaction --master-data=2 -A | mysql -h slave
五、预防性架构设计
通过以上策略组合,可彻底解决 99% 的主从复制延迟问题。
核心原则:并行化回放 + 硬件加速 + 业务规避。
分库分表:减少单库写入压力
TiDB 分布式数据库:天然无主从延迟
读写分离分级:
实时读:走主库
非关键读:走从库(允许秒级延迟)





)

基础知识点记录一)







)



