PaliGemma 2是轻量级开放式视觉语言模型 (VLM),灵感源自 PaLI-3,基于 SigLIP 视觉模型和 Gemma 语言模型等开放式组件。PaliGemma 同时接受图片和文本作为输入,并且可以回答有关图片的详细问题和背景信息。
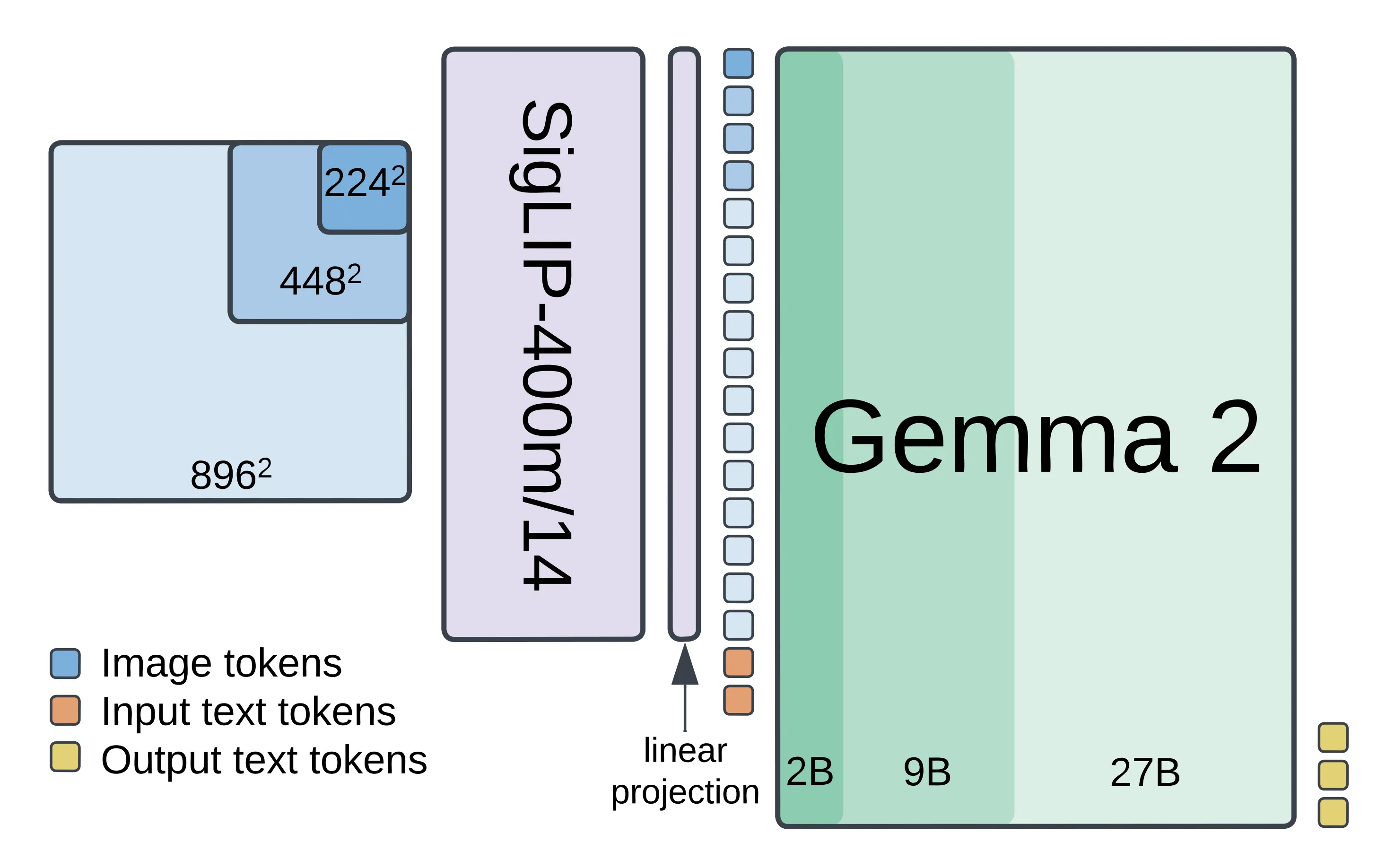
PaliGemma 2 提供 30 亿、100 亿和 280 亿个参数的大小,分别基于 Gemma 2 20 亿、90 亿和 270 亿个参数的模型。三种参数规模(3B/10B/28B)、三种分辨率(224×224/448×448/896×896)。
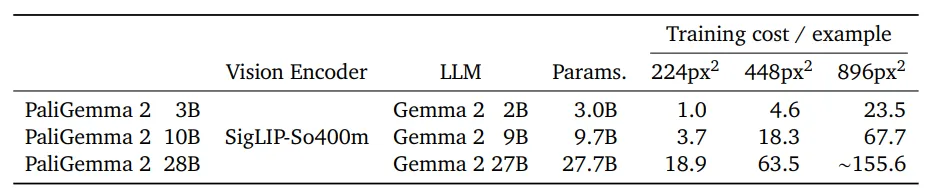
模型架构
PaliGemma 2 由 Transformer 解码器和 Vision Transformer 图片编码器组成。文本解码器从 2B、9B 和 27B 参数大小的 Gemma 2 初始化。图片编码器从 SigLIP-So400m/14 初始化。与原始 PaliGemma 模型类似,PaLiGemma 2 是按照 PaLI-3 方案训练的。
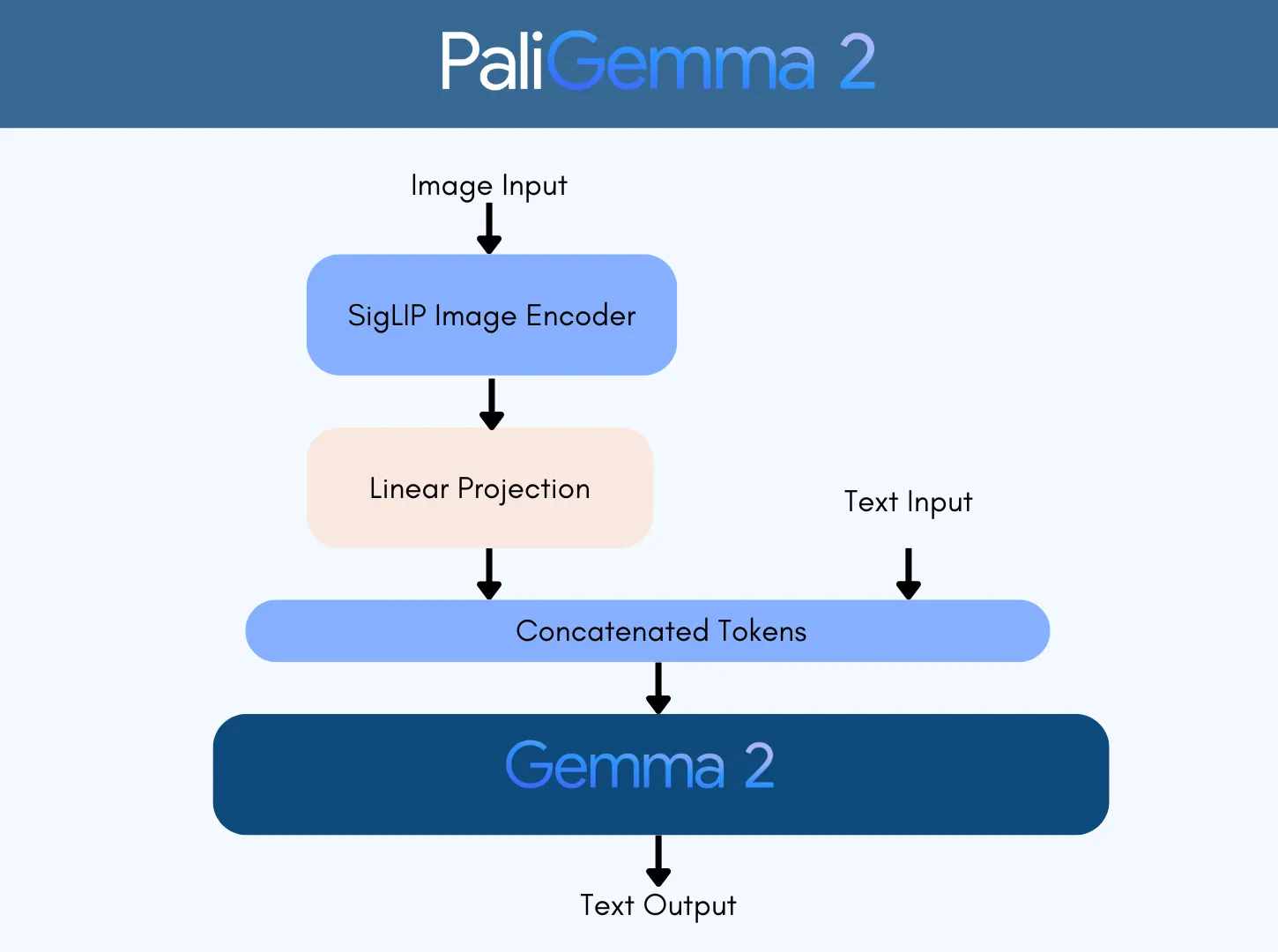
输入和输出
● 输入:图片和文本字符串,例如用于为图片添加说明的提示或问题。
● 输出:针对输入生成的文本,例如图片的标题、问题的答案、对象边界框坐标列表或分割代码词。
视觉编码器
SigLIP:其shape optimized ViT-So400m图像编码器,该模型通过sigmoid损失在大规模上进行了对比预训练,且其在小尺寸上也表现出色。
输入投影
线性投影:将SigLIP的输出到与gemma的词汇token相同的维度,以便它们可以被连接。
LLM主干。
LLM主干
Gemma2 10B:该模型可以匹配或超越使用相对更大些的语言模型的VLMs的性能,包括之前的PaLIs。
Finetune
不在这里








的工具选择方式)
![[硬件电路-57]:根据电子元器件的受控程度,可以把电子元器件分为:不受控、半受控、完全受控三种大类](http://pic.xiahunao.cn/[硬件电路-57]:根据电子元器件的受控程度,可以把电子元器件分为:不受控、半受控、完全受控三种大类)






![[前端技术基础]CSS选择器冲突解决方法-由DeepSeek产生](http://pic.xiahunao.cn/[前端技术基础]CSS选择器冲突解决方法-由DeepSeek产生)

0.5.7.3版本)
)