6、Models模型操作
1 ORM概述
- 介绍
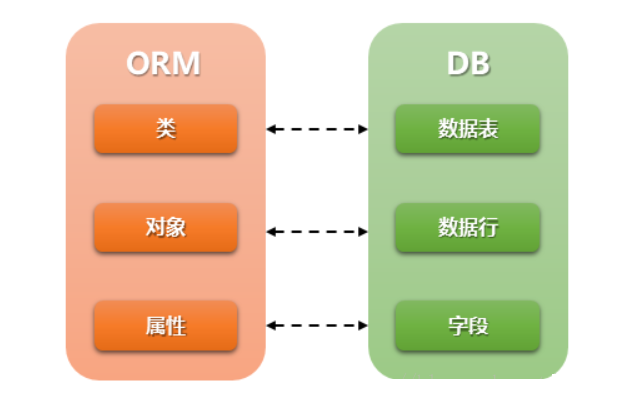
- Django对数据进行增删改操作是借助内置的ORM框架(Object Relational Mapping,对象关系映射)所提供的API方法实现的,允许你使用类和对象对数据库进行操作,从而避免通过SQL语句操作数据库。
- 简单来说,ORM框架的数据操作API是在 QuerySet 类中定义的,由开发者自定义模型对象调用 QuerySet类,来实现数据的操作。
- 作用
- 建立模型类和表之间的对应关系,允许我们通过面向对象的方式来操作数据库。
- 根据设计的模型类生成数据库中的表格。
- 通过简单的配置就可以进行数据库的切换。
- 好处
- 只需要面向对象编程, 不需要面向数据库编写代码.
- 对数据库的操作都转化成对类属性和方法的操作.
- 不用编写各种数据库的sql语句.
- 实现了数据模型与数据库的解耦, 屏蔽了不同数据库操作上的差异.
- 不在关注用的是mysql、oracle…等数据库的内部细节.
- 通过简单的配置就可以轻松更换数据库, 而不需要修改代码.
- 只需要面向对象编程, 不需要面向数据库编写代码.
- 缺点
- 对于复杂业务,使用成本较高
- 根据对象的操作转换成SQL语句,根据查询的结果转化成对象, 在映射过程中有性能损失.
- ORM 示意
1、增加数据
- 为了演示 Django项目的增删改操作,可以使用 Django 的 shell 模式(启动命令行和执行脚本)进行讲述,该模式方便开发人员开发与调试程序。
- 在Terminal中开启Shell模式,执行命令:
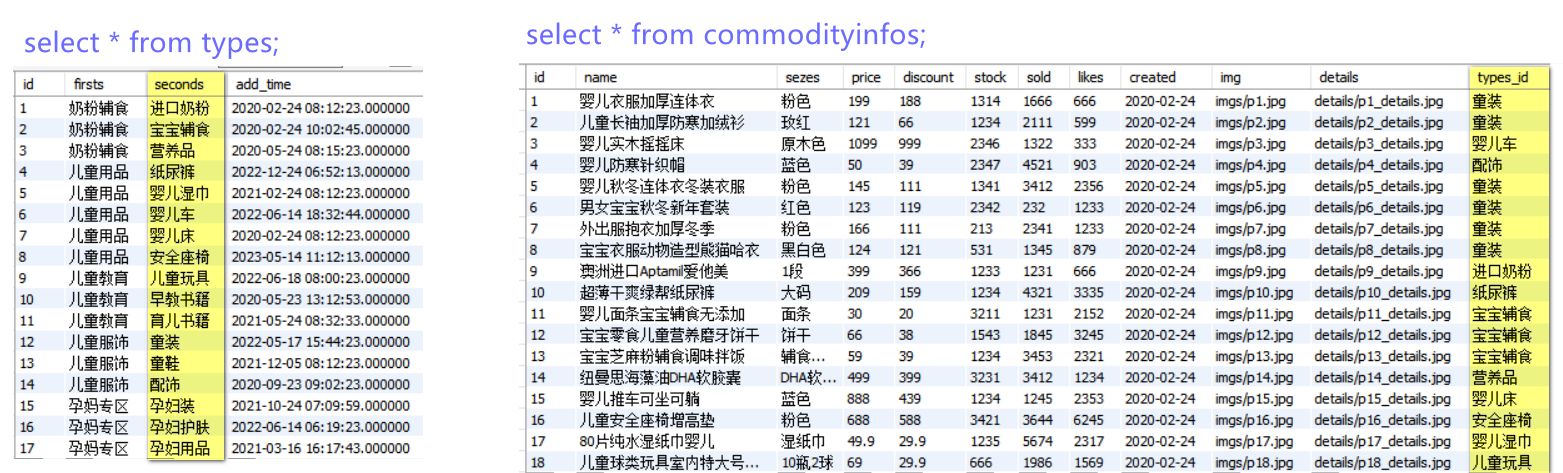
python manage.py shell,演示示例:
1 新增数据
(base) PS C:\ProjectManager\tianfu\babys> python .\manage.py shell
11 objects imported automatically (use -v 2 for details).Python 3.12.4 | packaged by Anaconda, Inc. | (main, Jun 18 2024, 15:03:56) [MSC v.1929 64 bit (AMD64)]
Type 'copyright', 'credits' or 'license' for more information
IPython 8.25.0 -- An enhanced Interactive Python. Type '?' for help.from commodity.models import Types, CommodityInfos# 1 基本数据添加方法
# 方法1:创建对象,给对象的属性赋值,调用save方法保存
t1 = Types()
t1.firsts = '儿童服饰';
t2.seconds = "女装"
t1.seconds = "女装"
t1.save()# 方法2:创建对象时,为对象的属性赋值,调用save方法保存
t2 = Types.objects.create(firsts="儿童教育", seconds="python书籍")
t2.save()# 方法3: 通过对象的objects下的create方法
t3 = Types.objects.create(firsts="儿童用品", seconds="摇摇车")
t3.save()# 方法3: 通过对象的objects下的create方法[参数较多时,可使用字典构建,在拆解]
t4_dict = {'firsts': '儿童用品', 'seconds': '早教机', 'add_time': '2025-02-12 11:08:08'}
t4 = Types.objects.get_or_create(**t4_dict)
2 获取添加
-
在执行数据新增时,为了保证数据的有效性,需要对数据进行去重判断,以确保数据不会重复新增:
-
方案1:对数据表进行查询,如果查询结果不存在,则执行新增数据。
-
方案2:Django提供 get_or_create() 方法 (推荐)
# 对应的SQL语句: # SELECT * FROM commodity_types WHERE firsts = '童装' AND seconds = '男装'; # INSERT INTO commodity_types (firsts, seconds) VALUES ('童装', '男装'); t5_dict = dict(firsts='儿童服装', seconds='男装') t5 = Types.objects.get_or_create(**t5_dict) t5 # 返回元组:(<Types: 22>, True),第一个参数表示新建的对象,第二个参数表示操作的结果 t5[0].firsts # '儿童服装' t5[0].seconds # '男装't5_dict = dict(firsts='儿童服装', seconds='潮牌') t5 = Types.objects.get_or_create(**t5_dict) t5 t5[0].seconds- 说明
- get_or_create 根据每个模型字段的值与数据表的数据进行判断:
- 只要有一个模型字段的值与数据表的数据不相同(除主键以外),就会执行新增数据操作。
- 如果每个模型字段的值与数据表的某行数据完全相同,则就不执行新增,反而返回这个这行数据的数据对象。
- get_or_create 根据每个模型字段的值与数据表的数据进行判断:
- 说明
-
3 更新添加
-
Django中还提供了 update_or_create 方法,用于判断当前数据在数据表中是否存在,若存在则执行更新操作,否则在数据表中新增数据。
# 对应的SQL语句: # SELECT * FROM commodity_types WHERE firsts = '儿童早教' AND second = '儿童玩具'; # UPDATE commodity_types SET third = NULL, addtime = NOW() WHERE id = 5; --存在 # INSERT INTO commodity_types (firsts, second, third, addtime) VALUES ('儿童早教', '儿童玩具', NULL, NOW()); -- 不存在In [26]: d4 = dict(firsts="儿童早教", second="儿童玩具") In [27]: t4 = Types.objects.update_or_create(**d4)In [28]: t4 Out[28]: (<Types: 22>, True)In [29]: t4 = Types.objects.update_or_create(**d4) In [30]: t4 Out[30]: (<Types: 22>, False)In [31]: t4[0].id Out[31]: 22
4 批量新增
-
如果想要对某个模型执行数据批量新增操作,则可以使用 bulk_create 方法实现,只需要就爱那个数据对象以列表或元组的形式传入 bulk_create 方法:
# 对应的SQL语句:INSERT INTO commodity_types (firsts, second, third, addtime) VALUES ('儿童用品', '湿纸巾', NULL, NOW()), ('儿童用品', '纸尿裤', NULL, NOW());In [32]: t5 = Types(firsts="儿童用品", second="湿纸巾") In [33]: t6 = Types(firsts="儿童用品", second="纸尿裤") In [34]: obj_lists = [t5, t6] In [35]: Types.objects.bulk_create(obj_lists) Out[35]: [<Types: None>, <Types: None>] -
在使用 bulk_create 方法前,数据类型为模型Types的实例化对象,并且在实例化过程中设置每一个字段的值,最后将所有实例化对象存放在列表或元组中,以参数的形式传递给 bulk_create 方法,从而实现数据批量化的新增操作。
2、更新数据
-
更新数据操作与新增数据步骤大致相同,唯一的区别就在于数据对象来自数据表,需要执行一次数据查询,查询的结果以对象的形式表示,并将对象的属性进行赋值处理。
# 方法1:查询单条数据后更新 # 对应SQL语句: # SELECT * FROM commodity_types WHERE id = 11; # UPDATE commodity_types SET firsts = '儿童用品', third = NULL WHERE id = 11;In [36]: t = Types.objects.get(id=11) In [37]: t.firsts = "儿童用品" In [38]: t.save()In [39]: t.firsts Out[39]: '儿童用品'# 方法2:批量更新一条或多条数据 # 查询方式使用 filter:以列表的形式返回,查询结果可能是一条或多条# 对应的SQL语句:UPDATE commodity_types SET second = '湿纸巾裤' WHERE id = 23; In [40]: t = Types.objects.filter(id=23) In [41]: t Out[41]: <QuerySet [<Types: 23>]>In [42]: t.update(sencond='湿纸巾裤') Out[42]: 1# 更新数据以字典格式表示 # 对应的SQL语句:UPDATE commodity_types SET second = '童鞋' WHERE id = 23; In [43]: d = dict(second='童鞋') In [44]: Types.objects.filter(id=23).update(**d)# 方法3:不查询直接修改:默认是对全表的数据进行更新 # 对应的SQL语句:UPDATE commodity_types SET firsts = '母婴用品'; In [44]: Types.objects.update(frists="母婴用品")# 方法4:对数据某列自增或自减 # 对应SQL语句:UPDATE commodity_types SET id = id + 10 WHERE id = 23; In [



)















