核心问题
- 小目标检测性能差: 尽管通用目标检测器(如 Faster R-CNN, YOLO, SSD)在常规目标上表现出色,但在检测微小目标(如 AI-TOD 基准定义的:非常小目标 2-8 像素,小目标 8-16 像素,较小目标 16-32 像素)时性能急剧下降。
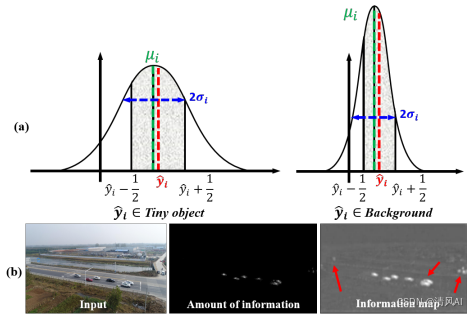
- 根本原因: 微小目标极其有限的像素导致其特征表示非常微弱且缺乏区分度。深度神经网络的下采样过程导致信息丢失,这对微小目标尤其致命,使它们在特征图上几乎与背景无法区分(如图 1(b) 所示)。
- 现有方法的不足: 现有的解决方案(如尺度感知特征融合、注意力机制、模仿学习)部分缓解了问题,但未能有效解决由极度有限像素引起的弱表示问题。注意力机制尤其容易受到微小目标稀疏像素的影响,导致注意力图不可靠。

解决方案:FIP-GDE 框架
论文提出了一种名为 Feature Information driven Position Gaussian Distribution Estimation (FIP-GDE) 的即插即用架构,旨在增强因信息丢失而变得微弱和难以区分的区域(即微小目标)。核心思想是从像素级信息量的角度出发来识别需要增强的区域。
-
像素特征信息建模 (Pixels Feature Information Modeling - PFIM)
- 目标: 无监督地识别图像中信息量丰富的区域(通常是显著目标,包括微小目标)。
- 原理: 基于信息论(香农熵)。信息量
I(x) = -log₂p(x),信息量大的区域(显著目标)出现概率p(x)小,信息量小(平滑背景)出现概率大。 - 方法:
- 对底层特征图
P₂(记为y)进行量化(添加均匀噪声模拟训练)。 - 使用 CNN 参数估计模块预测每个像素元素的均值图
μ和尺度图σ(代表其高斯分布的参数)。 - 关键创新: 最小化信息熵损失 (Information Entropy Loss -
L_IE)。该损失是量化特征ŷ的整体编码成本(比特数)的反映:L_IE = Σᵢ -log₂ pŷᵢ(ŷᵢ|μᵢ, σᵢ)。 - 优化过程的作用: 最小化
L_IE促使网络学习y的分布模型,使其能高效压缩特征。在此过程中,信息量大的区域(如目标)需要更多的编码比特(成本高),而背景区域需要的比特少(成本低)。
- 对底层特征图
- 输出 - 信息图 (Information Map
σ):- 预测的尺度图
σ被发现与信息量图(每个像素的编码成本)高度正相关,且视觉上更显著(如图 3(b) 所示)。 σ值大的区域对应信息量大、需要增强的显著区域(目标)。- 使用
σ初步增强P₂:y₁ = y ⊗ (1 + Mean(σ))(Mean为通道维度平均)。
- 预测的尺度图
2.位置高斯分布预测 (Position Gaussian Distribution Prediction - PGDP)
- 目标: 提供监督信号,使信息图
σ和增强过程更关注微小目标。微小目标需要在分布图中获得比普通目标更高的强度值。 - 核心组件 - 位置高斯分布图 (Position Gaussian Distribution Map
M_GT):- 使用高斯混合模型 (Gaussian Mixture Model) 建模。每个目标实例对应一个高斯分量。
- 关键创新 (缩放因子
αᵢ): 高斯分量的协方差矩阵Σᵢ^box根据目标框的大小动态调整:Σᵢ^box = diag((wᵢ/αᵢ)², (hᵢ/αᵢ)²)。 αᵢ取值:非常小目标 (vt) = 4, 小目标 (t) = 6, 较小目标 (s) = 8, 普通目标 = 10。这导致微小目标的协方差更小,在分布图中峰值更高(如图 4 所示)。
- 最终
M_GT通过组合所有高斯分量、乘以实例数N并应用阈值处理来增强前景背景对比度获得。
- 预测模块:
- 使用多尺度特征
P₂, P₃, P₄来预测M_GT。 - 关键设计: 将信息图
σ作为先验知识引导预测。输入为[P₄ + (1/4)σ, P₃ + (1/2)σ, P₂ + σ](1/4,1/2表示下采样)。 - 网络结构包含卷积、反卷积和跨层连接(如图 2 所示),输出三个尺度的预测图
M_pd₂, M_pd₃, M_pd₄。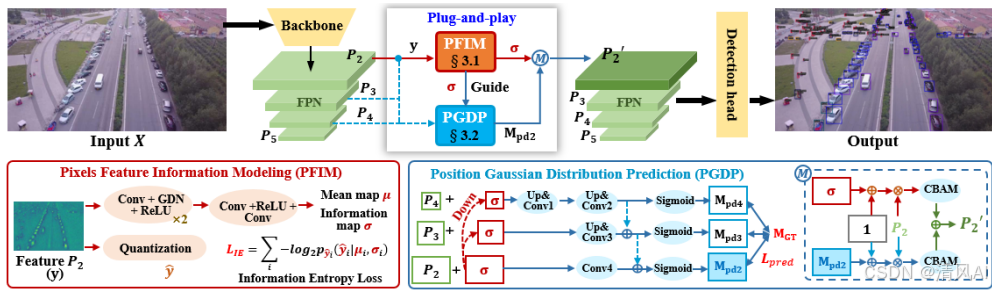
- 使用加权均方误差损失 (
L_pred) 进行深度监督,对目标区域(值 > 阈值th)赋予更高权重(10 vs 背景的 0.1)。
- 使用多尺度特征
- 协同作用:
σ指导M_pd的预测;反过来,优化L_pred也有助于生成能更好识别微小目标信息丰富区域的σ。 - 增强: 使用预测的
M_pd₂增强P₂:y₂ = y ⊗ (1 + M_pd₂)。
-
特征融合与最终输出
- 将两个增强特征
y₁(由σ增强) 和y₂(由M_pd₂增强) 分别送入 CBAM (Convolutional Block Attention Module) 模块进行进一步的空间和通道注意力优化。 - 将两个经过注意力优化的特征图按元素相加 (Element-wise Addition) 融合,得到最终的增强特征图
P₂'。 P₂'替换原始 FPN 中的P₂,送入检测头执行检测任务。
- 将两个增强特征
-
损失函数
总损失函数结合了检测损失、信息熵损失和分布图预测损失:
L = L_det + λ₁L_IE + λ₂L_pred(λ₁=0.01,λ₂=1.0)
实验结果
-
数据集: 在三个公开的小目标检测数据集上进行了广泛实验:VisDrone2019, AI-TOD, AI-TODv2。
-
评估指标: 遵循 AI-TOD 基准,包括 AP, AP₀.₅, AP₀.₇₅, APvt (非常小目标), APt (小目标), APs (较小目标)。
-
主要发现:
- 显著提升: 作为即插即用模块集成到多种主流检测器(Faster R-CNN, Cascade R-CNN, DetectoRS, RFLA)中,均带来了显著性能提升,尤其在检测微小目标(APvt, APt)上提升最大(例如,在 VisDrone 上 Faster R-CNN 的 APt 提升 5.8 点)。
- SOTA 性能: 当与 RFLA 结合时,在 VisDrone2019 上取得了所有指标的最佳性能(AP=29.0, APvt=7.4)。在 AI-TOD 和 AI-TODv2 上,与 DetectoRS 结合也获得了极具竞争力的结果(通常是最好或次好)。
- 超越现有方法: 性能优于近期专门针对小目标检测的方法(如 NWD-RKA, RFLA, SR-TOD, Salience DETR),证明了提出方法的优越性。特别指出 SR-TOD 的差异图依赖图像复原质量且会损失信息,而 FIP-GDE 直接在特征图层面识别信息损失区域。
-
消融研究 (Ablation Study):
- 模块有效性: PFIM 和 PGDP 模块均独立有效,结合使用效果最佳。
- 分布图建模: 提出的基于目标大小动态调整
αᵢ的高斯建模方法优于固定缩放因子、二值掩码或自注意力生成权重图。 - 先验引导: 将
σ通过Pₙ + (scale)σ的方式添加到输入进行引导效果最佳。 - 融合策略: 元素相加融合
y₁和y₂效果优于元素相乘或拼接。
-
分析:
- 信息图有效性: 可视化(图 5, 图 6(a))和信息熵损失分析(比特每像素 bpp 与场景密集度正相关,如图 7 所示)证明了 PFIM 能有效捕获信息量大的显著区域和目标的空间结构。

- 分布图有效性: 可视化(图 6(b))表明预测的分布图
M_pd₂能清晰区分前景背景,并赋予微小目标更高强度。最终增强特征P₂'(图 6(c))中的目标更显著,检测结果(图 6(f))也证明了能检测出更多困难的微小目标。
- 信息图有效性: 可视化(图 5, 图 6(a))和信息熵损失分析(比特每像素 bpp 与场景密集度正相关,如图 7 所示)证明了 PFIM 能有效捕获信息量大的显著区域和目标的空间结构。

主要贡献
- 首次从像素级信息量的角度提出增强微小目标弱特征表示的方法,通过最小化信息熵损失无监督地生成注意力信息图
σ。 - 引入由高斯混合模型建模的位置高斯分布图
M_GT,并创新性地根据目标大小动态调整高斯分量协方差,使微小目标获得更高强度。 - 构建了以信息图为先验指导的多尺度分布图预测模块,协同调制信息图和分布图聚焦于微小目标。
- 提出的 FIP-GDE 框架是即插即用的,可灵活集成到类似 FPN 的检测器中,在三个公开数据集上的大量实验证明了其有效性和优越性,超越了当前最先进的方法。
核心代码实现
1. 像素特征信息建模模块(PFIM)
import torch
import torch.nn as nn
import torch.nn.functional as Fclass PFIM(nn.Module):def __init__(self, in_channels):super().__init__()# 参数估计网络:预测高斯分布的μ和σself.param_net = nn.Sequential(nn.Conv2d(in_channels, 64, 3, padding=1),nn.ReLU(),nn.Conv2d(64, in_channels * 2, 3, padding=1) # 输出μ和σ)def forward(self, y):"""y: 输入特征图 [B, C, H, W]返回: 信息熵损失, 增强特征y1, 信息图σ"""# 1. 参数估计params = self.param_net(y) # [B, 2*C, H, W]mu, sigma = torch.split(params, params.size(1)//2, dim=1)sigma = torch.exp(sigma) # 确保正值# 2. 量化处理(添加均匀噪声)if self.training:y_hat = y + torch.rand_like(y) - 0.5 # U(-0.5, 0.5)else:y_hat = torch.round(y) # 推理时直接取整# 3. 计算似然概率(公式5)upper = (y_hat + 0.5 - mu) / sigmalower = (y_hat - 0.5 - mu) / sigmap_yhat = self.std_normal_cdf(upper) - self.std_normal_cdf(lower)# 4. 计算信息熵损失(公式7)p_yhat = torch.clamp(p_yhat, min=1e-10) # 避免log(0)loss_IE = -torch.log2(p_yhat).sum()# 5. 生成信息图(通道平均)info_map = sigma.mean(dim=1, keepdim=True) # [B, 1, H, W]# 6. 特征初步增强(公式8)y1 = y * (1 + info_map)return loss_IE, y1, info_mapdef std_normal_cdf(self, x):"""标准正态分布累积函数近似"""return 0.5 * (1 + torch.erf(x / torch.sqrt(torch.tensor(2.0))))2. 位置高斯分布预测模块(PGDP)
class PGDP(nn.Module):def __init__(self, in_channels):super().__init__()# 多尺度融合网络(P2-P4)self.conv_p2 = nn.Conv2d(in_channels, 64, 3, padding=1)self.conv_p3 = nn.Conv2d(in_channels, 64, 3, padding=1)self.conv_p4 = nn.Conv2d(in_channels, 64, 3, padding=1)# 上采样和融合层self.upsample = nn.ModuleList([nn.ConvTranspose2d(64, 64, 4, stride=2, padding=1),nn.ConvTranspose2d(64, 64, 4, stride=2, padding=1)])# 预测头self.pred_head = nn.Sequential(nn.Conv2d(64 * 3, 64, 3, padding=1),nn.ReLU(),nn.Conv2d(64, 1, 1) # 输出单通道分布图)def forward(self, p2, p3, p4, info_map):"""输入: p2, p3, p4 - 多尺度特征图 [B, C, H, W]info_map - 信息图 [B, 1, H, W]返回: 预测分布图M_pd2, 增强特征y2"""# 1. 信息图下采样适配各尺度info_p4 = F.interpolate(info_map, size=p4.shape[2:]) * 0.25info_p3 = F.interpolate(info_map, size=p3.shape[2:]) * 0.5# 2. 特征与信息图融合p4_in = self.conv_p4(p4 + info_p4)p3_in = self.conv_p3(p3 + info_p3)p2_in = self.conv_p2(p2 + info_map)# 3. 上采样和特征融合p4_up = self.upsample[0](p4_in) # P4->P3尺寸p3_fused = p3_in + p4_upp3_up = self.upsample[1](p3_fused) # P3->P2尺寸p2_fused = torch.cat([p2_in, p3_up, p3_up], dim=1)# 4. 预测最终分布图M_pd2 = torch.sigmoid(self.pred_head(p2_fused))# 5. 特征增强y2 = p2 * (1 + M_pd2)return M_pd2, y23. 特征增强与融合模块
class FeatureEnhancer(nn.Module):def __init__(self, in_channels):super().__init__()# CBAM注意力模块(简化实现)self.channel_att = nn.Sequential(nn.AdaptiveAvgPool2d(1),nn.Conv2d(in_channels, in_channels//8, 1),nn.ReLU(),nn.Conv2d(in_channels//8, in_channels, 1),nn.Sigmoid())self.spatial_att = nn.Sequential(nn.Conv2d(2, 1, 7, padding=3),nn.Sigmoid())def forward(self, y1, y2):"""输入: PFIM增强特征y1, PGDP增强特征y2返回: 融合后的增强特征P2'"""# 1. 分别应用CBAM注意力y1_att = self.cbam(y1)y2_att = self.cbam(y2)# 2. 特征融合(元素相加)y_fused = y1_att + y2_attreturn y_fuseddef cbam(self, x):"""简化版CBAM"""# 通道注意力channel_att = self.channel_att(x)x_channel = x * channel_att# 空间注意力avg_out = torch.mean(x_channel, dim=1, keepdim=True)max_out, _ = torch.max(x_channel, dim=1, keepdim=True)spatial_att = self.spatial_att(torch.cat([avg_out, max_out], dim=1))return x_channel * spatial_att4. 整体框架集成
class FIPGDE(nn.Module):def __init__(self, backbone_channels):super().__init__()# 实例化核心模块self.pfim = PFIM(backbone_channels)self.pgdp = PGDP(backbone_channels)self.enhancer = FeatureEnhancer(backbone_channels)# 损失权重self.lambda1 = 0.01self.lambda2 = 1.0def forward(self, p2, p3, p4, gt_bboxes=None):"""输入: p2, p3, p4 - FPN特征图gt_bboxes - 训练时提供GT框用于生成M_GT返回: 增强后的P2'特征, 总损失"""# 1. PFIM模块loss_IE, y1, info_map = self.pfim(p2)# 2. PGDP模块M_pd2, y2 = self.pgdp(p2, p3, p4, info_map)# 3. 计算PGDP损失(训练时)loss_pred = 0if gt_bboxes is not None:M_GT = self.generate_M_GT(gt_bboxes, p2.shape)# 加权MSE损失(公式13)mask = (M_GT > self.threshold).float()weights = mask * 10 + (1 - mask) * 0.1loss_pred = F.mse_loss(M_pd2, M_GT, reduction='none')loss_pred = (loss_pred * weights).mean()# 4. 特征增强与融合p2_prime = self.enhancer(y1, y2)# 5. 总损失total_loss = loss_IE * self.lambda1 + loss_pred * self.lambda2return p2_prime, total_lossdef generate_M_GT(self, gt_bboxes, feat_shape):"""生成位置高斯分布图(公式9-12)gt_bboxes: [N, 5] (batch_idx, x1, y1, x2, y2)feat_shape: [B, C, H, W]"""# 初始化M_GT为零矩阵B, _, H, W = feat_shapeM_GT = torch.zeros(B, 1, H, W, device=gt_bboxes.device)# 遍历所有GT框for box in gt_bboxes:b, x1, y1, x2, y2 = boxb = int(b)# 计算中心点(映射到特征图坐标)cx = ((x1 + x2) / 2) / 4 # P2尺寸是原图1/4cy = ((y1 + y2) / 2) / 4w = (x2 - x1) / 4h = (y2 - y1) / 4# 确定缩放因子α(基于目标大小)area = w * hif area < 8: alpha = 4 # very tinyelif area < 16: alpha = 6 # tinyelif area < 32: alpha = 8 # smallelse: alpha = 10 # general# 生成高斯分布(公式10)x_grid, y_grid = torch.meshgrid(torch.arange(W, device=M_GT.device), torch.arange(H, device=M_GT.device))gaussian = torch.exp(-(((x_grid - cx) / (w/alpha))**2 + ((y_grid - cy) / (h/alpha))**2))# 累加到M_GT(公式11)M_GT[b, 0] += gaussian# 后处理(公式12)M_GT *= len(gt_bboxes) / (B * len(gt_bboxes)) # 平均化threshold = M_GT.mean()M_GT = ((M_GT > threshold).float() * 0.5 + M_GT)return M_GT论文地址:https://openaccess.thecvf.com/content/CVPR2025/papers/Bian_Feature_Information_Driven_Position_Gaussian_Distribution_Estimation_for_Tiny_Object_CVPR_2025_paper.pdf









用法示例(C++和Python))





C++入门教程:前言——你的随身教程和学习笔记)
重定向 | 时间相关指令 | 文件查找 | 打包与压缩)
)

