LRU(Least Recently Used,最近最少使用)是一种基于时间局部性原理的缓存淘汰策略。其核心思想是:最近被访问的数据在未来更可能被再次使用,而最久未被访问的数据应优先被淘汰,从而在有限的缓存空间内保留高价值数据。
数据结构设计
LRU通过 哈希表 + 双向链表 实现高效操作:
1.双向链表(DlinkedNode):维护数据访问顺序,链表头部为最新访问节点,尾部为最久未使用节点;
2.哈希表(HashMap):存储键与链表节点的映射,支持以O(1)的时间复杂度定位节点,使插入、查询、删除操作均能快速完成。
图解:
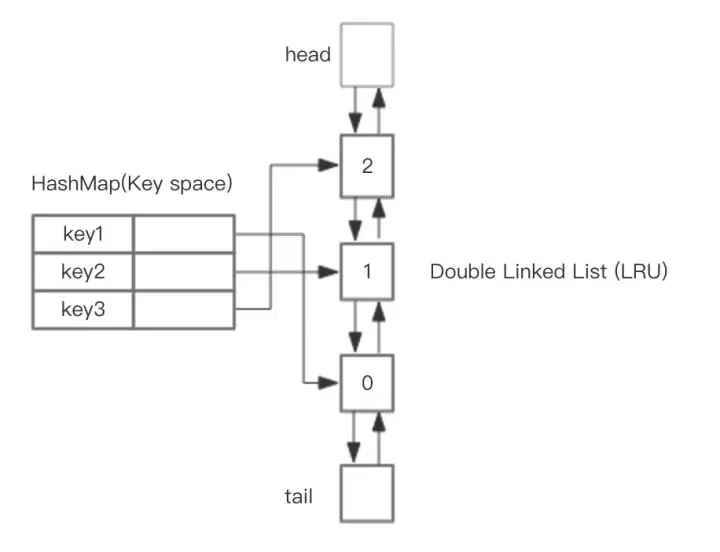
关键操作流程
1.数据访问(get方法):
· 若数据存在于缓存(哈希表命中):
· 从双向链表中移除该节点;
· 将该节点插入链表头部。
· 若数据不存在(未命中):返回默认值-1。
2.数据插入(put方法):
· 若键已存在:
· 更新节点值;
· 移动节点至链表头部。
· 若键不存在:
· 缓存已满时,删除尾部节点(最久未使用)并移除哈希表对应键;
· 创建新节点插入链表头部,并存入哈希表。
LRU的功能特性
⭐1.添加元素:将新元素插入到队头(表示最近使用);
2.访问/更新元素:将元素从原来的位置删除,再插入到队头(更新使用时间);
3.淘汰元素:当size > capacity,即容量不足时,删除队尾元素(最久未使用)。
LRU算法题实战
LCR 031. LRU 缓存 - 力扣(LeetCode)LCR 031. LRU 缓存 - 运用所掌握的数据结构,设计和实现一个 LRU (Least Recently Used,最近最少使用) 缓存机制 [https://baike.baidu.com/item/LRU] 。实现 LRUCache 类: * LRUCache(int capacity) 以正整数作为容量 capacity 初始化 LRU 缓存 * int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。 * void put(int key, int value) 如果关键字已经存在,则变更其数据值;如果关键字不存在,则插入该组「关键字-值」。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。 示例:输入["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"][[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]输出[null, null, null, 1, null, -1, null, -1, 3, 4]解释LRUCache lRUCache = new LRUCache(2);lRUCache.put(1, 1); // 缓存是 {1=1}lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}lRUCache.get(1); // 返回 1lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}lRUCache.get(2); // 返回 -1 (未找到)lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}lRUCache.get(1); // 返回 -1 (未找到)lRUCache.get(3); // 返回 3lRUCache.get(4); // 返回 4 提示: * 1 <= capacity <= 3000 * 0 <= key <= 10000 * 0 <= value <= 105 * 最多调用 2 * 105 次 get 和 put 进阶:是否可以在 O(1) 时间复杂度内完成这两种操作? 注意:本题与主站 146 题相同:https://leetcode-cn.com/problems/lru-cache/ [https://leetcode-cn.com/problems/lru-cache/] ![]() https://leetcode.cn/problems/OrIXps/题目描述:
https://leetcode.cn/problems/OrIXps/题目描述:
运用所掌握的数据结构,设计和实现一个LRU (Least Recently Used,最近最少使用) 缓存机制。
实现 LRUCache 类:
-
LRUCache(int capacity)以正整数作为容量capacity初始化 LRU 缓存。 -
int get(int key)如果关键字key存在于缓存中,则返回关键字的值,否则返回-1。 -
void put(int key, int value)如果关键字已经存在,则变更其数据值;如果关键字不存在,则插入该组「关键字-值」。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。
示例:
输入
["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
输出
[null, null, null, 1, null, -1, null, -1, 3, 4]
解释
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4
提示:
-
1 <= capacity <= 3000 -
0 <= key <= 10000 -
0 <= value <= 105 -
最多调用
2 * 10 ^ 5次get和put
class LRUCache {
public LRUCache(int capacity) {
}
public int get(int key) {
}
public void put(int key, int value) {
}
}
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache obj = new LRUCache(capacity);
* int param_1 = obj.get(key);
* obj.put(key,value);
*/
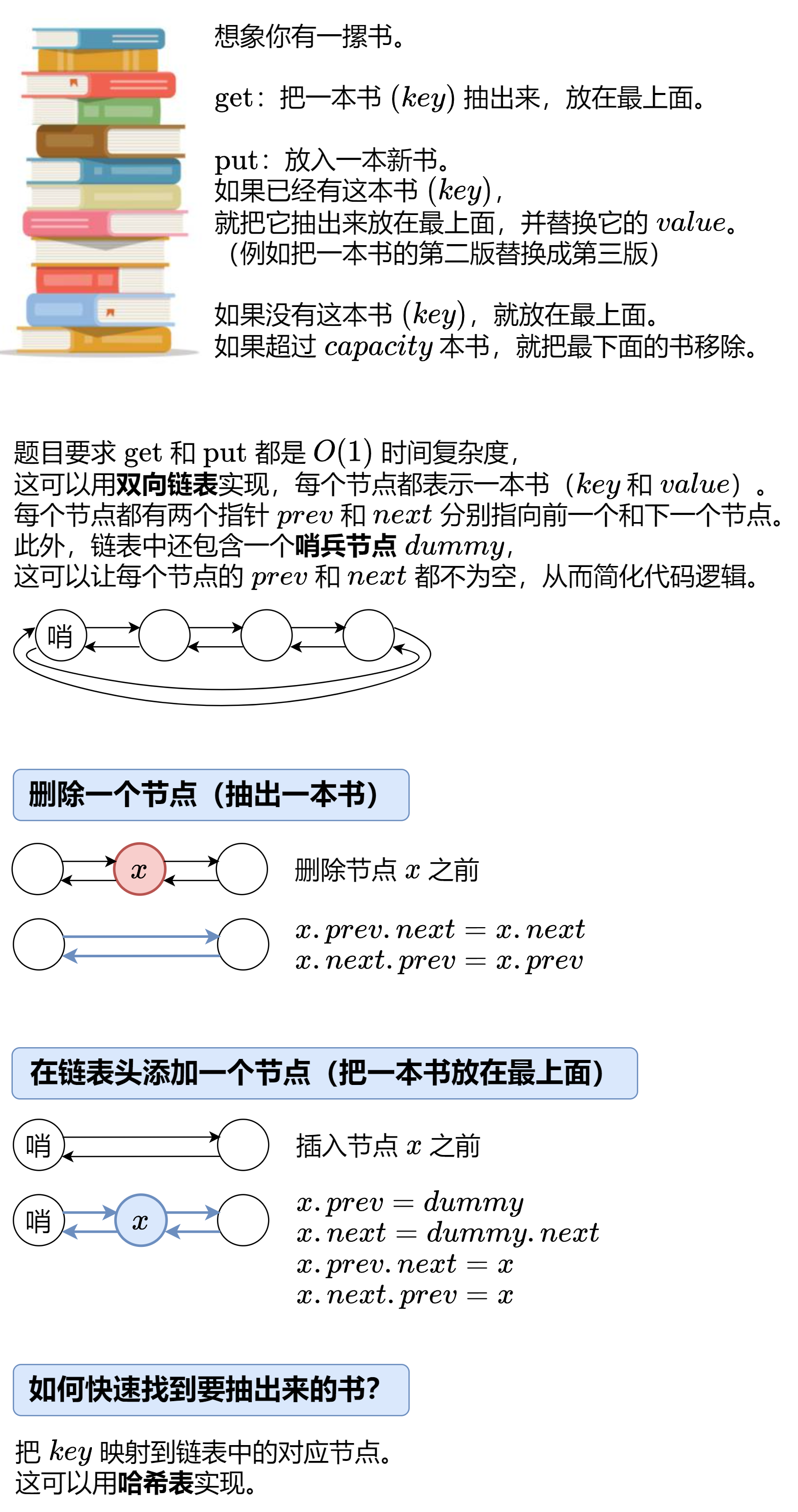
首先需要定义双向链表节点类:
1.定义双向链表节点类,包含key(对应哈希表的键)、val(缓存实际要存储的值)、prev(双向链表节点的前驱节点)、next(双向链表节点的后继节点),并提供用于初始化的无参构造方法和可用于赋值的有参构造方法。
// 双向链表节点类
class DlinkedNode {int key; // 键int val; // 值DlinkedNode prev; // 前驱节点DlinkedNode next; // 后继节点public DlinkedNode() { // 无参构造方法}public DlinkedNode(int key, int val) { // 有参构造方法this.key = key;this.val = val;}
}2.定义了LRU的核心成员变量 ,包含负责快速查找的哈希表map(通过key获取节点DlinkedNode)、虚拟头尾节点head和tail(简化对边界的处理,避免链表为空、插入第一个节点、删除最后一个节点的指针操作)、size(记录缓存中实际的节点数,用于判断是否需要淘汰数据)、capacity(缓存的最大容量,由用户设定),共同实现LRU“快速访问 + 动态维护顺序 + 容量管理”的核心需求。
// 哈希表(键,双向链表节点),用于快速查找节点
private Map<Integer, DlinkedNode> map = new HashMap<>();
// 虚拟头节点,简化边界操作
private DlinkedNode head;
// 虚拟尾节点
private DlinkedNode tail;
// 当前元素数量
private int size;
// 缓存最大容量
private int capacity;3.让当前节点的前驱节点的后继指针指向当前节点的后继节点,让当前节点的后继节点的前驱指针指向当前节点的前驱节点,即绕过当前节点,从双向链表中移除node节点。
// 从双向链表中删除指定节点(跳过当前节点)
private void remove(DlinkedNode node) {node.prev.next = node.next;node.next.prev = node.prev;
}4.首先让新节点的前驱指针指向虚拟头节点head,然后让新节点的后继指针指向head原本的下一个节点,再让原第一个节点head.next的前驱指针转而指向新节点,最后让虚拟头节点head的后继指针指向新节点,目的是将指定节点插入到虚拟头节点head之后,作为链表的第一个实际节点。
// 将节点插入到双向链表的头部
private void insertToHead(DlinkedNode node) {node.prev = head;node.next = head.next;head.next.prev = node;head.next = node;
}5.调用remove(node)方法,将node节点从当前所在的位置从双向链表中移除(断开与前后的连接),调用insertToHead(node)方法,将刚才删除的节点重新插入到双向链表的头部(建立该节点与原头节点的连接)。
// 将节点移动到双向链表的头部
private void moveToHead(DlinkedNode node) {remove(node); // 先删除后插入insertToHead(node);
}6.首先定位尾部节点,tail为虚拟尾节点,真正的尾部节点为尾指针的前一个节点(tail.prev),用target保存这个要删除的有效节点,再调用remove(target)删除节点,最后返回target。
// 删除尾部节点
private DlinkedNode removeTail() {DlinkedNode target = tail.prev;remove(target);return target;
}7.初始方法LRUCache:
this.size = 0;
表示当前缓存中存储的有效数据数量为0(初始为空)。
this.capacity = capacity;
记录缓存的最大容量(即最多能存储的数据个数),由外部传入并赋值。
head = new DlinkedNode();
tail = new DlinkedNode();
创建两个虚拟节点,分别作为链表的头哨兵和尾哨兵。
head.next = tail;
tail.prev = head;
连接头哨兵和尾哨兵,形成一个初始的完整闭环空链表结构。
// LRU初始化
public LRUCache(int capacity) {this.size = 0;this.capacity = capacity;head = new DlinkedNode();tail = new DlinkedNode();head.next = tail;tail.prev = head;
}8.LRU的get()方法详解:
通过哈希表的key查找对应的双向链表节点node,如果node为空,说明缓存中没有该键对应的记录,返回-1,如果node存在,调用moveToHead(node)将该节点移动到双向链表的头部,再返回找到的节点存储的值。
// 获取LRU中指定键的值
public int get(int key) {DlinkedNode node = map.get(key);if (node == null) return -1; // 节点不存在moveToHead(node); // 节点存在,标记为最近使用return node.val;
}9.LRU的put()方法详解:
DlinkedNode node = map.get(key);
通过map.get(key)查找键对应的节点node。
DlinkedNode newNode = new DlinkedNode(key, value);
map.put(key, newNode);
insertToHead(newNode);
size++;
若键不存在,创建新节点newNode,存储键值对(key, value),将新节点存入哈希表(方便后续查找使用),再调用insertToHead(newNode)将新节点插入双向链表头部,缓存当前大小size自增+1。
if (size > capacity) {
DlinkedNode del = removeTail();
map.remove(del.key);
size--;
}
若键不存在,当size > capacity时,调用removeTail()删除双向链表的尾部节点,并删除哈希表中该节点的键,最后size自减-1,保证缓存大小不超过容量。
node.val = value;
moveToHead(node);
若键已存在,更新节点的值,用value覆盖原来的val,再调用moveToHead(node)方法将该节点移向双向链表的头部,哈希表会自动同步此处的更新,无需额外操作。
// 向LRU中插入或更新键值对
public void put(int key, int value) {DlinkedNode node = map.get(key);if (node == null) {DlinkedNode newNode = new DlinkedNode(key, value);map.put(key, newNode);insertToHead(newNode);size++;if (size > capacity) { // 超出容量则需淘汰最久未使用的元素DlinkedNode del = removeTail();map.remove(del.key);size--;}} else { // 节点存在,更新值并移到头部node.val = value;moveToHead(node);}
}LRU实现完整源码:
class DlinkedNode {int key;int val;DlinkedNode prev; DlinkedNode next; public DlinkedNode() { }public DlinkedNode(int key, int val) { this.key = key;this.val = val;}
}class LRUCache {private Map<Integer, DlinkedNode> map = new HashMap<>();private DlinkedNode head;private DlinkedNode tail;private int size;private int capacity;public LRUCache(int capacity) {this.size = 0;this.capacity = capacity;head = new DlinkedNode();tail = new DlinkedNode();head.next = tail;tail.prev = head;}public int get(int key) {DlinkedNode node = map.get(key);if (node == null) return -1; moveToHead(node); return node.val;}public void put(int key, int value) {DlinkedNode node = map.get(key);if (node == null) {DlinkedNode newNode = new DlinkedNode(key, value);map.put(key, newNode);insertToHead(newNode);size++;if (size > capacity) { DlinkedNode del = removeTail();map.remove(del.key);size--;}} else { node.val = value;moveToHead(node);}}private void remove(DlinkedNode node) {node.prev.next = node.next;node.next.prev = node.prev;}private void insertToHead(DlinkedNode node) {node.prev = head;node.next = head.next;head.next.prev = node;head.next = node;}private void moveToHead(DlinkedNode node) {remove(node);insertToHead(node);}private DlinkedNode removeTail() {DlinkedNode target = tail.prev;remove(target);return target;}
}代码直观理解:
LRU的优势分析
1.贴合数据访问的局部性特点:实际中数据访问常呈现短期集中的热点(如当前操作的数据),LRU优先保留近期被访问的数据,能高效命中这些短期高频使用的数据,符合实际场景的访问规律。
2.动态响应性好:当访问模式变化(如新热点出现),可快速淘汰旧冷门数据,为新数据腾空间,适应变化灵活。
3.实现高效低成本:通过哈希表+双向链表,可在O(1)时间完成查找、更新和淘汰操作,无需复杂统计,资源消耗低。
4.命中率较优:相比FIFO(先进先出),避免盲目淘汰有用老数据,相比LFU(最不经常使用),更易更新新热点,在多数场景下命中率较高,平衡实用与性能。
实际应用场景
· 操作系统的内存页面置换;
· 数据库缓冲池;
· Web服务器/浏览器缓存;
· 移动端应用(如图片缓存)。

)
- 图表辅助元素)





:时间分片(Time Slicing):让你的应用在高负载下“永不卡顿”的秘密)



)




)


一种在路径规划和图搜索中广泛使用的启发式搜索算法)