使用逻辑回归识别 信用卡欺诈行为:基于creditcard.csv的实战与评估分析
项目背景
在金融行业中,信用卡欺诈检测是一项关键任务。欺诈交易在整个交易中占比极低,导致数据极度不平衡。本案例通过经典数据集 creditcard.csv,构建逻辑回归模型,并使用多个评价指标(如准确率、召回率、F1 等)来全面评估模型性能。
数据介绍
信用卡欺诈检测数据集 creditcard.csv
-
数据来源:Kaggle Credit Card Fraud Detection
 https://www.kaggle.com/datasets/mlg-ulb/creditcardfraud
https://www.kaggle.com/datasets/mlg-ulb/creditcardfraud -
样本总数:284,807 条
-
特征数:30(28个匿名特征 + 金额
Amount+ 时间Time) -
目标变量:
Class(0=正常交易,1=欺诈交易)

完整代码解析
import pandas as pd # 用于数据处理和分析
from sklearn.linear_model import LogisticRegression # 导入逻辑回归模型
from sklearn.model_selection import train_test_split # 用于拆分训练集和测试集
from sklearn.preprocessing import StandardScaler # 用于数据标准化处理# 读取信用卡交易数据
data = pd.read_csv('creditcard.csv')# 初始化标准化器,将数据转换为均值为0、标准差为1的分布
scaler = StandardScaler()
# 对Amount列进行标准化处理,并覆盖原始数据
data['Amount'] = scaler.fit_transform(data[['Amount']])# 准备特征数据X(排除时间和目标变量)和目标变量y(欺诈标签)
X = data.drop(["Time","Class"], axis=1)
y = data.Class# 将数据拆分为训练集(70%)和测试集(30%),设置随机种子保证结果可复现
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=100)# 初始化逻辑回归模型并在训练集上训练
model = LogisticRegression()
model.fit(X_train, y_train)# 使用训练好的模型在测试集上进行预测
y_pred = model.predict(X_test)
# 计算并打印模型在测试集上的准确率
accuracy = model.score(X_test, y_test)
print(f'准确率:{accuracy}')# 导入评估指标库并生成详细的分类报告
from sklearn import metrics
print('分类报告:')
print(metrics.classification_report(y_test, y_pred))# 统计目标变量Class中各类别的样本数量(查看数据分布,尤其是欺诈与正常交易的比例)
labels_count = pd.value_counts(data['Class'])
print(labels_count)模型评估指标详解(来自sklearn.metrics.classification_report)
在欺诈检测中,“准确率”往往是不可靠的。因为如果模型预测全为 0(正常交易),准确率仍然可能达到 99.9%。
![]()
因此,我们重点关注如下指标:
| 指标名称 | 说明 |
|---|---|
| Precision(精确率) | 被预测为正类的条目中 真正是正类的比例。衡量“预测为欺诈中真正欺诈”的比例 |
| Recall(召回率) | 实际为正类的条目中 被预测是正类的比例。(检出率) |
| F1-score | 精确率和召回率的调和平均,平衡二者 |
| Support | 每个类在测试集中出现的样本数。如85301为测试集(284,807条的30%)中的“0”类 |
示例输出:
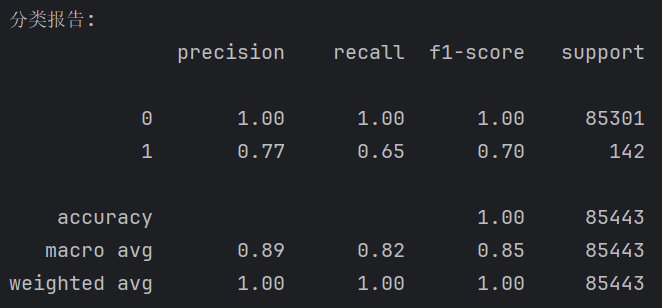
重点分析 1 类(欺诈交易)
-
Precision = 0.77:误报很多,意味着模型判定为欺诈的交易中,存在不少误判情况。
-
Recall = 0.65:召回率并不好,说明很多欺诈并没有被识别。
-
F1-score = 0.70:它综合考虑了精确率(Precision)和召回率(Recall),用于衡量在不平衡数据集中模型对“少数类”的综合表现。
-
support: 85301表示测试集中0的条数,142表示测试集中1的条数
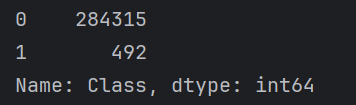
之所以预测结果并不好,是因为数据的极度不平衡:
28万条 的 正常交易
492条 的 欺诈交易
模型优化建议
| 方法 | 原理 |
|---|---|
下采样(Undersampling) | 减少多数类样本,使正负样本比例接近,降低模型对多数类的偏好。适用于数据量较大的场景,但可能丢失信息。 |
| 过采样(Oversampling) | 通过复制少数类或生成合成样本(如SMOTE)来平衡数据,提高模型对少数类的识别能力。适用于数据稀缺时。 |
| 调整阈值(threshold) | 将默认的分类阈值(通常为0.5)向下调整,使模型更容易预测为“欺诈”类,从而提高 Recall,适用于对漏检特别敏感的任务 |
| 调整类别权重(class_weight) | 在训练过程中对少数类样本给予更高权重,引导模型更关注少数类。可通过设置 class_weight='balanced' 实现,适用于多数 sklearn 分类器。 |
此文章同一专栏内包含有1.下采样、2.过采样、3.调整阈值、4.LogisticRegression()的参数
class_weight='balanced'即为LogisticRegression()的参数
总结
逻辑回归虽为线性模型,但在欺诈检测中依然具备一定实用性。通过合理的数据预处理、参数设置(如 class_weight='balanced')、指标解读,可以使模型在真实场景中更可靠。评价指标远比准确率更重要,特别是在处理不平衡分类问题时。






)
![[RK3566-Android11] U盘频繁快速插拔识别问题](http://pic.xiahunao.cn/[RK3566-Android11] U盘频繁快速插拔识别问题)


)







--学习笔记15(分页查询PageHelper))
