机器学习领域存在"没有免费午餐"定理,没有任何一种模型在所有问题上都表现最优。不同模型有各自的优势和适用场景。同一数据集上,不同模型的预测性能可能有巨大差异。例如,线性关系明显的数据上线性模型可能表现优异,而复杂非线性关系则可能需要树模型或神经网络。
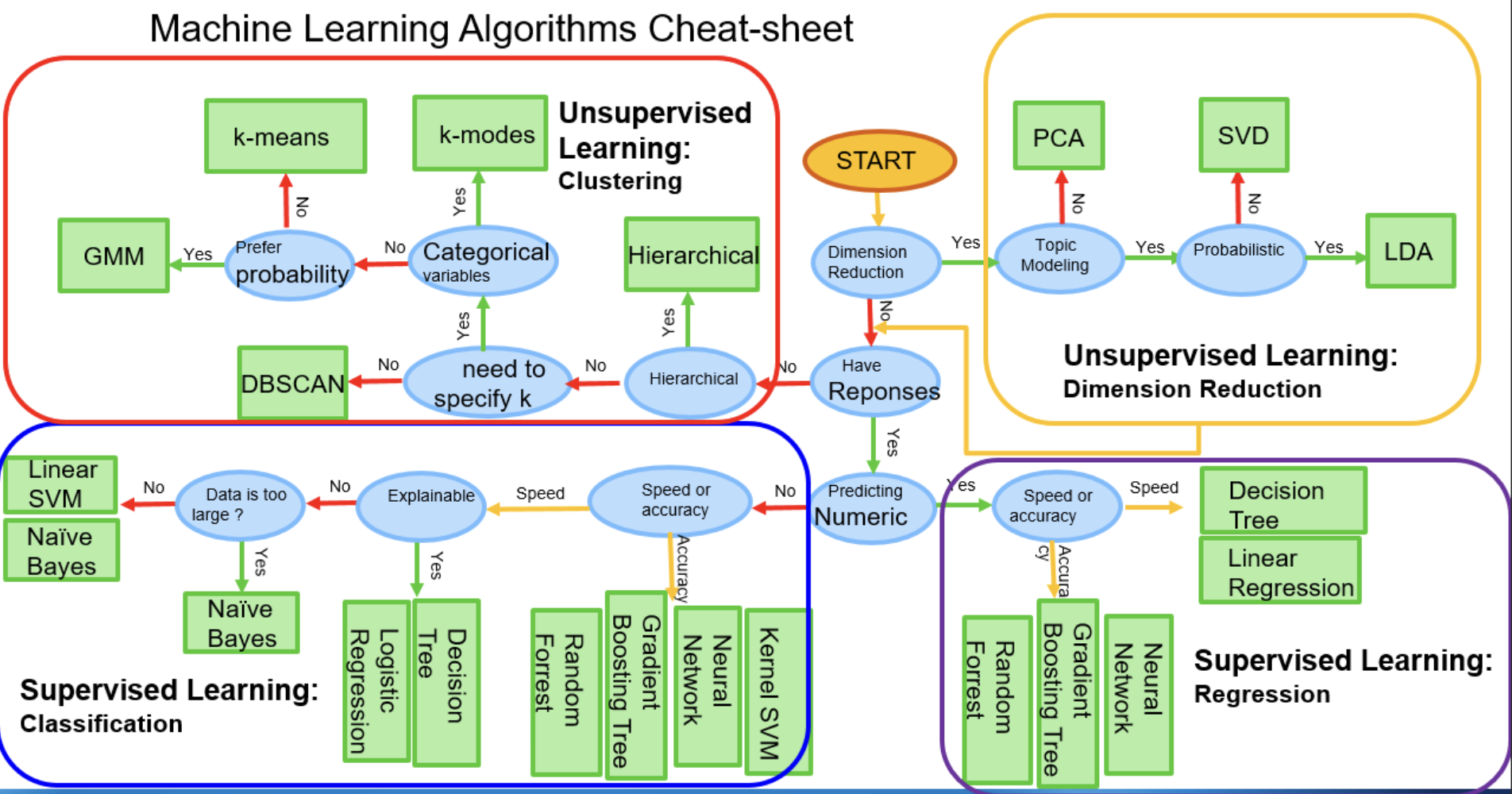
这里写目录标题
- 模型选择依据
- 根据问题类型选择合适的模型
- 根据模型特点选择合适的模型
- 根据数据特征选择合适的模型
- 用于回归任务的多种模型
- 用于分类任务的常见模型
- 分类模型选择建议
- 常见分类模型
- 1. **逻辑回归(Logistic Regression)**
- 2. **支持向量机(SVM / SVC)**
- 3. **决策树(Decision Tree)**
- 4. **随机森林(Random Forest)**
- 5. **梯度提升树(Gradient Boosting)**
- 6. **K近邻(K-Nearest Neighbors, KNN)**
- 7. **朴素贝叶斯(Naive Bayes)**
- 8. **多层感知机(MLP / 神经网络)**
- 9. **LightGBM / XGBoost / CatBoost(进阶推荐)**
模型选择依据
根据问题类型选择合适的模型
| 问题类型 | 模型方向 |
|---|---|
| 回归任务(预测连续值):房价、销量、温度 | 使用 RandomForestRegressor, XGBoost, LinearRegression 等 |
| 分类任务(预测类别):是否违约、图像分类 | 使用 RandomForestClassifier, LogisticRegression, SVC 等 |
| 聚类任务 | 。。。 |
根据模型特点选择合适的模型
| 模型 | 假设/特点 | 不适用场景 |
|---|---|---|
| 线性回归 | 特征与目标呈线性关系 | 数据高度非线性 |
| 决策树 | 分段常数预测,适合规则型数据 | 对噪声敏感,易过拟合 |
| KNN | 局部相似性有效 | 高维稀疏数据(维度灾难) |
| SVR | 小样本、非线性核有效 | 大数据集(训练慢) |
| XGBoost/LightGBM | 结构化数据王者 | 图像、文本等非结构化数据 |
根据数据特征选择合适的模型
| 数据特点 | 推荐模型 |
|---|---|
| 样本少(<1k) | SVR、KNN、线性模型 |
| 样本多(>10k) | 树模型(XGBoost、LightGBM)、神经网络 |
| 特征少且线性关系明显 | 线性回归、岭/套索回归 |
| 特征多、非线性、交互多 | 随机森林、梯度提升、MLP |
| 高维稀疏(如文本) | 线性模型 + L1 正则化、SVM |
| 存在多重共线性 | Ridge、Lasso、ElasticNet |
| 需要特征选择 | Lasso、Tree-based 模型 |
| 数据未标准化 | 树模型(不需要标准化)、避免 KNN/SVR/MLP |
| 类别特征多 | LightGBM(原生支持)、CatBoost |
用于回归任务的多种模型
-
LinearRegression(线性回归)
- 最基础的回归模型,通过寻找特征与目标变量之间的线性关系进行预测
- 公式:y = w₁x₁ + w₂x₂ + … + wₙxₙ + b
-
Ridge(岭回归)
- 线性回归的正则化版本,使用L2正则化
- 通过添加系数平方和的惩罚项防止过拟合
- alpha参数控制正则化强度
-
Lasso(套索回归)
- 线性回归的另一种正则化版本,使用L1正则化
- 可以将某些特征的系数缩减到零,实现特征选择
- 适用于高维数据集
-
Elastic Net(弹性网络)
- 结合了Ridge和Lasso的特点,同时使用L1和L2正则化
- l1_ratio参数控制两种正则化的比例
- 在处理多重共线性数据时表现良好
-
Random Forest(随机森林)
- 集成学习方法,构建多棵决策树并取平均预测结果
- 通过随机选择特征和样本增加模型多样性
- 通常具有较高的准确性和鲁棒性
-
Extra Trees(极端随机树)
- 与随机森林类似,但在选择分割点时增加了更多随机性
- 不仅随机选择特征,还随机选择分割阈值
- 计算效率通常比随机森林高
-
Gradient Boosting(梯度提升)
- 另一种集成方法,通过顺序构建决策树来改进模型
- 每棵新树都试图修正前面树的预测错误
- 通常有很高的预测精度,但需要仔细调参
-
SVR(支持向量回归)
- 基于支持向量机(SVM)的回归方法
- 使用核函数(这里是rbf核)处理非线性关系
- 通过寻找一个函数使大部分样本点与函数的偏差不超过ε
-
KNN(K近邻回归)
- 基于实例的学习方法,不需要显式训练
- 对新样本,找到最近的k个邻居,用它们的目标值平均作为预测
- 简单直观,但对数据尺度和维度敏感
-
MLP(多层感知器)
- 一种前馈神经网络,包含输入层、隐藏层和输出层
- 这里配置有两个隐藏层,分别有100和50个神经元
- 能够学习复杂的非线性关系,但需要较多数据和计算资源
用于分类任务的常见模型
在机器学习中,分类任务(Classification)是指预测样本所属的类别(离散标签),例如:
- 垃圾邮件检测(是/否)
- 医疗诊断(患病/健康)
- 图像识别(猫/狗/车)
- 客户流失预测(会流失/不会流失)
下面是一些最常用、性能稳定且广泛应用的分类模型,适用于结构化数据(如表格 CSV)和中小规模数据集。
| 模型 | 是否适合小数据 | 是否需标准化 | 是否可解释 | 推荐指数 |
|---|---|---|---|---|
| 逻辑回归 | ✅ | ❌ | ✅ | ⭐⭐⭐⭐⭐ |
| 决策树 | ✅ | ❌ | ✅✅ | ⭐⭐⭐⭐☆ |
| 随机森林 | ✅✅ | ❌ | ✅ | ⭐⭐⭐⭐⭐ |
| XGBoost / LightGBM | ✅(中等以上) | ❌ | ⚠️(需 SHAP) | ⭐⭐⭐⭐⭐ |
| SVM | ✅ | ✅ | ❌ | ⭐⭐⭐☆ |
| KNN | ✅ | ✅ | ❌ | ⭐⭐☆ |
| 朴素贝叶斯 | ✅ | ❌ | ⚠️ | ⭐⭐⭐⭐ |
| MLP(神经网络) | ⚠️(慎用) | ✅ | ❌ | ⭐⭐☆ |
分类模型选择建议
| 场景 | 推荐模型 |
|---|---|
| 小数据(<500)+ 可解释性要求高 | 逻辑回归、决策树 |
| 中等数据 + 高精度需求 | 随机森林、XGBoost、LightGBM |
| 文本分类 | 朴素贝叶斯、逻辑回归 + TF-IDF |
| 实时预测 | 逻辑回归、KNN、决策树 |
| 特征很多但样本少 | SVM、Ridge 分类器 |
| 需要概率输出 | 逻辑回归、随机森林、SVM(开启 probability) |
| 类别特征多(如性别、地区) | CatBoost、LightGBM |
常见分类模型
1. 逻辑回归(Logistic Regression)
- 适用场景:二分类问题,特征与结果呈线性关系
- 优点:
- 简单、速度快
- 输出具有概率意义
- 可解释性强(系数表示特征影响方向)
- 缺点:无法处理复杂的非线性关系
- 代码:
from sklearn.linear_model import LogisticRegression model = LogisticRegression()
2. 支持向量机(SVM / SVC)
- 适用场景:小样本、高维数据、非线性边界(用核函数)
- 优点:
- 在小数据上表现好
- 使用 RBF 核可拟合复杂边界
- 缺点:
- 训练慢,不适合大数据
- 对特征缩放敏感(必须标准化)
- 代码:
from sklearn.svm import SVC model = SVC(kernel='rbf', probability=True) # 开启概率输出
3. 决策树(Decision Tree)
- 适用场景:规则清晰、需要可解释性的任务
- 优点:
- 易于理解和可视化
- 不需要标准化
- 能自动处理特征交互
- 缺点:容易过拟合,泛化能力差
- 代码:
from sklearn.tree import DecisionTreeClassifier model = DecisionTreeClassifier(max_depth=5) # 控制深度防过拟合
4. 随机森林(Random Forest)
- 原理:多个决策树投票决定最终类别
- 适用场景:大多数结构化数据分类任务的“默认首选”
- 优点:
- 抗过拟合能力强
- 能处理非线性关系
- 支持特征重要性分析
- 缺点:比单棵树慢,但通常可接受
- 代码:
from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier(n_estimators=100, random_state=47)
5. 梯度提升树(Gradient Boosting)
- 代表模型:
GradientBoostingClassifier、XGBoost、LightGBM、CatBoost - 原理:逐个训练树来修正前一个模型的错误
- 优点:
- 高精度,常用于竞赛
- 对缺失值和类别特征有一定鲁棒性
- 缺点:训练较慢,需调参
- 代码示例:
或使用第三方库:from sklearn.ensemble import GradientBoostingClassifier model = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1)import xgboost as xgb model = xgb.XGBClassifier(n_estimators=100, random_state=47)
6. K近邻(K-Nearest Neighbors, KNN)
- 原理:根据最近的 K 个邻居的类别投票
- 适用场景:数据分布局部相似性强
- 优点:无需训练,直观
- 缺点:
- 预测慢(要计算距离)
- 对高维数据效果差(维度灾难)
- 必须标准化
- 代码:
from sklearn.neighbors import KNeighborsClassifier model = KNeighborsClassifier(n_neighbors=5)
7. 朴素贝叶斯(Naive Bayes)
- 适用场景:文本分类(如垃圾邮件识别)、高维稀疏数据
- 优点:
- 极快,适合实时预测
- 在文本任务中表现意外地好
- 缺点:假设特征相互独立(现实中常不成立)
- 常见变体:
GaussianNB:连续特征(假设正态分布)MultinomialNB:文本计数数据(如词频)BernoulliNB:二值特征
- 代码:
from sklearn.naive_bayes import GaussianNB model = GaussianNB()
8. 多层感知机(MLP / 神经网络)
- 适用场景:有一定数据量(>1000)、特征复杂、非线性强
- 注意:小样本(如 <500)容易过拟合
- 优点:能拟合任意复杂函数
- 缺点:需要调参多、必须标准化、训练不稳定
- 代码:
from sklearn.neural_network import MLPClassifier model = MLPClassifier(hidden_layer_sizes=(50, 25), max_iter=500, alpha=1.0)
9. LightGBM / XGBoost / CatBoost(进阶推荐)
这些是当前结构化数据分类任务中的“王者级”模型:
| 模型 | 特点 ||------|------|
| LightGBM | 快、省内存,适合大数据 |
| XGBoost | 精度高,广泛使用 |
| CatBoost | 原生支持类别特征,无需独热编码 |
import lightgbm as lgb
model = lgb.LGBMClassifier(n_estimators=100, verbose=-1)














如何进行MySQL的全局变量设置?)




