01. 摘要记忆组件的类型
在 LangChain 中使用缓冲记忆组件要不就保存所有信息(占用过多容量),要不就保留最近的记忆信息(丢失太多重要信息),那么有没有一种情况是既要又要呢?
所以折中方案就出现了——保留关键信息(重点记忆),移除冗余噪音(流水式信息)。
在 LangChain 中 摘要记忆组件 就是一种折中的方案,内置封装的 摘要记忆组件 有以下几种。
① ConversationSummaryMemory,摘要总结记忆组件,将传递的历史对话记录总结成摘要进行保存(底层使用 LLM 大语言模型进行总结),使用时填充的记忆为 摘要,并非对话数据。这种策略融合了记忆质量和容量的考量,只保留最核心的语义信息,有效减少了冗余,同时质量更高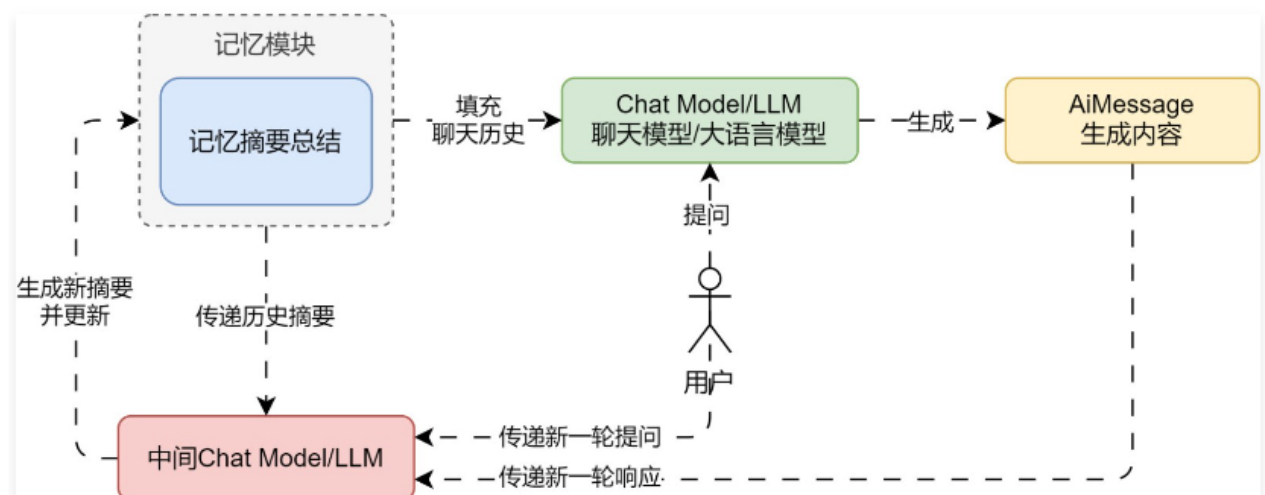
② ConversationSummaryBufferMemory,摘要缓冲混合记忆,在不超过 max_token_limit 的限制下,保存对话历史数据,对于超过的部分,进行信息的提取与总结(底层使用 LLM 大语言模型进行总结),兼顾了精确的短期记忆与模糊的长期记忆。
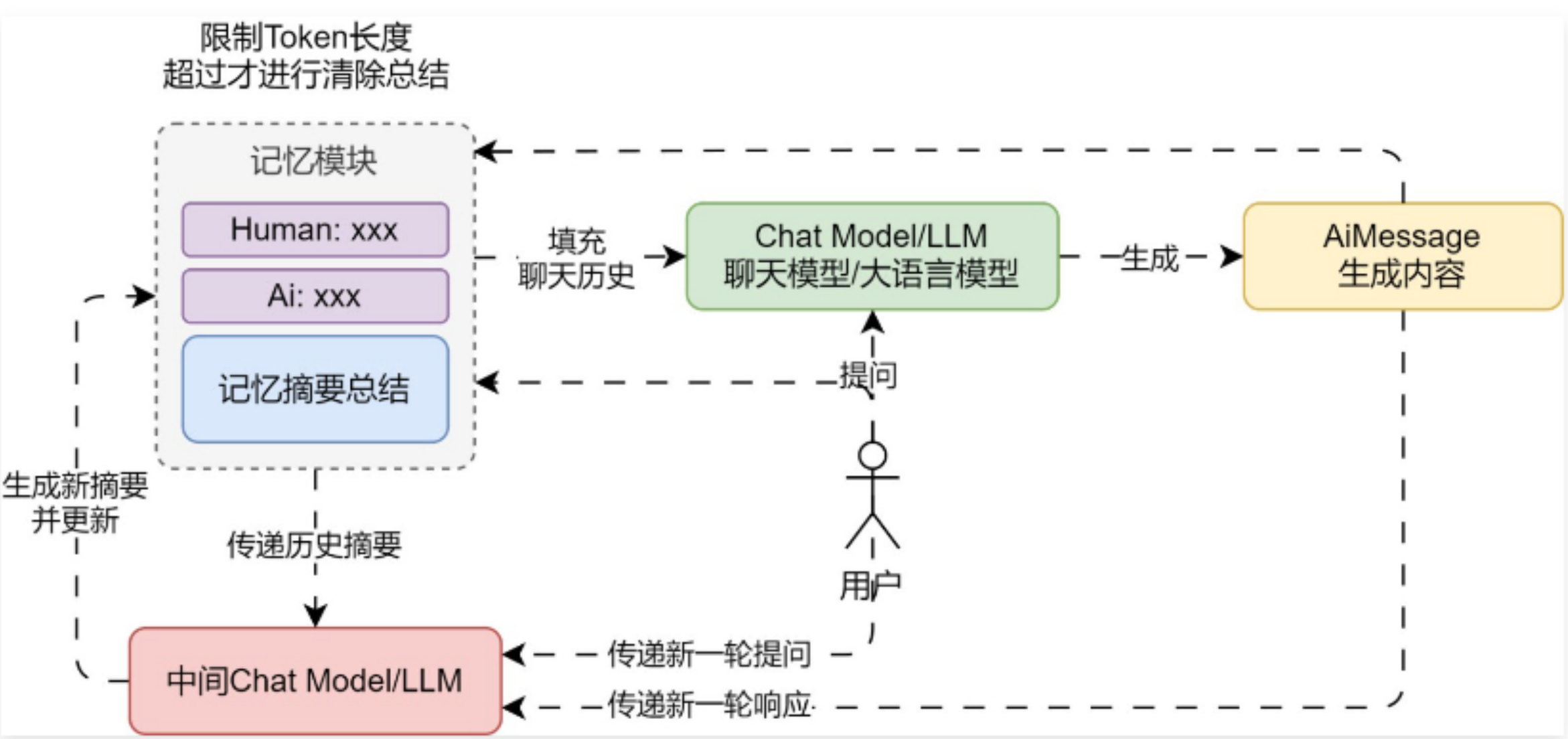
02. 摘要缓冲混合记忆示例与注意事项
2.1 摘要缓冲混合记忆示例
使用 LangChain 实现一个案例,让 LLM 应用拥有多轮对话记忆,并将历史记忆 max_token_limit 限制为 300,超过的部分进行总结产生总结记忆。代码
from operator import itemgetter
import dotenv
from langchain.memory import ConversationSummaryBufferMemory
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
# 1.创建提示模板&记忆
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个强大的聊天机器人,请根据对应的上下文回复用户问题"),
MessagesPlaceholder("history"), # 需要的history其实是一个列表
("human", "{query}"),
])
memory = ConversationSummaryBufferMemory(
return_messages=True,
input_key="query",
llm=ChatOpenAI(model="gpt-3.5-turbo-16k"),
max_token_limit=300,
)
# 2.创建大语言模型
llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
# 3.构建链应用
chain = RunnablePassthrough.assign(
history=RunnableLambda(memory.load_memory_variables) | itemgetter("history")
) | prompt | llm | StrOutputParser()
# 4.死循环构建对话命令行
while True:
query = input("Human: ")
if query == "q":
exit(0)
chain_input = {"query": query, "language": "中文"}
response = chain.stream(chain_input)
print("AI: ", flush=True, end="")
output = ""
for chunk in response:
output += chunk
print(chunk, flush=True, end="")
memory.save_context(chain_input, {"output": output})
print("")
print("history: ", memory.load_memory_variables({}))
2.2 使用注意事项
ConversationSummaryBufferMemory 会将汇总摘要的部分默认设置为 system 角色,创建系统角色信息,而其他消息则正常显示,传递的消息列表就变成:[system, system, human, ai, human, ai, human]。
但是部分聊天模型是不支持传递多个角色为 System 的消息,并且在 langchain_community 中集成的模型并没有对多个 System 进行集中合并封装(Chat Model 未更新同步),如果直接使用可能会出现报错。
而且绝大部分聊天模型在传递历史信息时,传递的信息必须是信息组,也就是 1 条 Human 消息 + 1 条 AI 消息这种格式,例如百度的文心大模型,链接:https://cloud.baidu.com/doc/WENXINWORKSHOP/s/clntwmv7t。
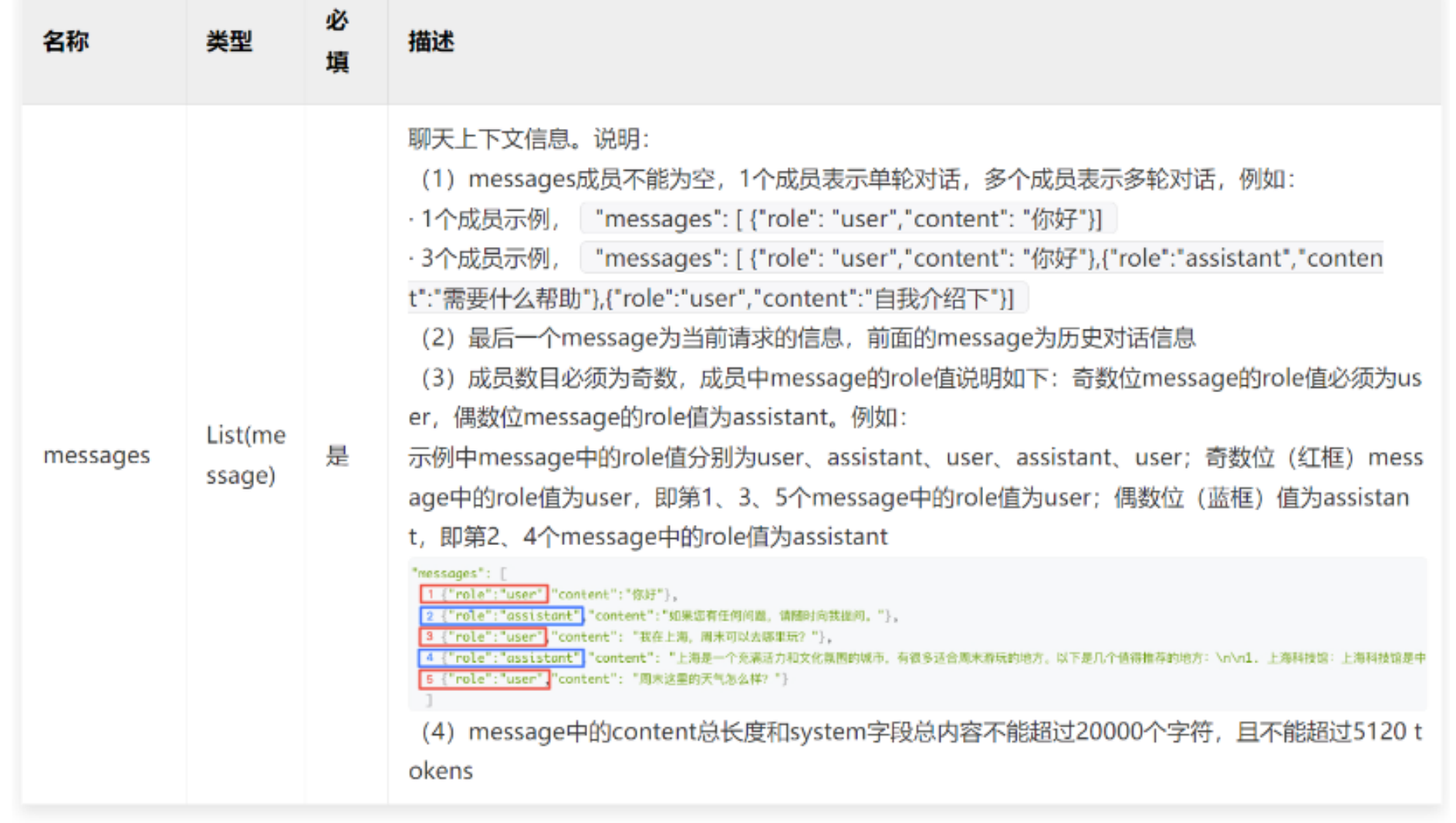
所以在使用 ConversationSummaryMemory 这种类型的记忆组件时,需要检查对应的模型传递的 messages 的规则,以及 LangChain 是否对特定的模型封装进行了更新。
除此之外,在某些极端的场合下,例如第一条提问回复内容比较短,第二条提问内容比较长,ConversationSummaryMemory 执行两次 Token 长度计算,如果不异步执行任务,对话速度会变得非常慢。
摘要更新 逻辑代码
# langchain/memory/summary_buffer.py
def prune(self) -> None:
"""Prune buffer if it exceeds max token limit"""
buffer = self.chat_memory.messages
curr_buffer_length = self.llm.get_num_tokens_from_messages(buffer)
if curr_buffer_length > self.max_token_limit:
pruned_memory = []
while curr_buffer_length > self.max_token_limit:
pruned_memory.append(buffer.pop(0))
curr_buffer_length = self.llm.get_num_tokens_from_messages(buffer)
self.moving_summary_buffer = self.predict_new_summary(
pruned_memory, self.moving_summary_buffer
)


 和 endGeometry () 打造自定义 3D 模型)
NMPC非线性模型预测控制及机械臂ROS控制器实现)







——文件归并排序思路详解(附代码实现))







