在年初的一篇关于商业开源的博文当中,我介绍了在开发商业软件的过程中,衍生出开源公共软件库的模式。在那篇博文里面,我只是简单罗列了相关开源库的名字及一句话总结。近期,我会结合商业开源实践的最新进展,对其中一些案例做详细展开。
首先介绍的是 Cronexpr[1],一个小巧的 Rust Crontab 解析库。其背后的开源模式,我称之为“涓滴开源”,即将商业软件依赖的微小但完整的功能模块开源出来,供其他人使用。
ScopeDB 的实际需求
开源软件的源头活水是有人需要。
“只是为了好玩”(Just For Fun)固然可以成为某人一时的动力,但是开源项目能够长期持续维护,肯定是因为有用户长期使用,倒推上游保持更新。作为互动的另一环,如果上游不再更新,用户也会逐渐流失。
Cronexpr 的需求来源于我和几位伙伴从去年开始开发的 ScopeDB 云数据库[2]。ScopeDB 是一个商业数据库,构建在云计算弹性且廉价的资源之上,通过一致的接口体验和查询语言将原本叠床架屋的数据流水线,简化为从应用直接写入 ScopeDB 后即可执行任意查询。在实现 ScopeDB 的过程中,我们发现类似数据保留策略的执行、简单的物化视图构建,以及数据存储的整理,都可以用定时后台作业的模型来建模:
CREATE JOB archive_table_tSCHEDULE = '4 2 * * * Asia/Shanghai'NODEGROUP = 'background'
ASDELETE FROM tWHERE created_at < NOW() - INTERVAL '720 hours';可以看到,这里在后台作业的调度周期的时候,用的是形如 4 2 * * * Asia/Shanghai 的 Cron 表达式。这也是定时后台作业常用的调度逻辑定义方案了。
于是,为了支持解析 Cron 表达式,并在 ScopeDB 调度后台作业的逻辑当中嵌入 Cron 表达式的计算逻辑,我第一时间想到的就是寻找一个现成的开源库来解决需求。
Cronexpr 的诞生
很快,我就找到了 Rust 生态里两个看起来不错的 Cron 表达式软件库:
croner[3]
saffron[4]
其中 croner 看起来是独立开发者发布的软件库,不过当时已经发布了 2.x 版本,今天再看已经发布了 3.x 版本,看起来作者是对软件的成熟度比较有信心的。saffron 虽然只发了一个 0.1.0 版本,但是它是 Cloudflare 出品,且看起来接口也比较正经,应该也相对成熟。
不过,这两者都不支持带时区信息的 Cron 表达式,这对用户体验来说有比较大的差别。同时,这两者对 Cron 表达式解析时的一些实现细节和扩展,都有奇特的“村规”。最后,由于这两个库实现时间较早,它们所采用的时间库是旧的 chrono 库,而不是现在更可靠的 jiff 库。至于其他 Cron 表达式相关的开源库,要么是一看就不靠谱,要么是完全实现成 Unix 下的 Cron 程序,自带不能去掉的命令执行功能,然而 ScopeDB 只需要能解析 Cron 表达式即可。
因此,考虑到解析 Cron 表达式并不复杂,且即使使用 croner 或 saffron 也需要对其进行一些修改以满足 ScopeDB 的需求,我决定自己实现一个 Cron 表达式解析库。
Cronexpr 由此诞生。它的原型接口非常简单:
let crontab = cronexpr::parse_crontab("2 4 * * * Asia/Shanghai").unwrap();// case 0. match timestamp
assert!(crontab.matches("2024-09-24T04:02:00+08:00").unwrap());
assert!(!crontab.matches("2024-09-24T04:01:00+08:00").unwrap());// case 1. find next timestamp with timezone
assert_eq!(crontab.find_next("2024-09-24T10:06:52+08:00").unwrap().to_string(),"2024-09-25T04:02:00+08:00[Asia/Shanghai]"
);实现的细节就不展开了,这里讨论一下对依赖的选用。
Cronexpr 的依赖只有两个,一个是上面提到的 jiff 库,用来处理时间戳相关的逻辑,另一个是 winnow 库,用来处理 Cron 表达式的解析。
选用 jiff 的道理非常简单,它是目前最可靠的 Rust 日期时间库,对时区、夏令时、各种日期计算都有很好的支持。历法的制定实际上是一种话语权的争夺,历法与日期变更的计算充满了人类世界的不靠谱特质,能把里面各种烂坑填好的库不可多得。jiff 库的作者有长期良好的声誉,他是 Golang 生态当中 toml 库的作者,也是 Rust Team 的官方成员,是 Rust Regex 库的作者,也还创作过 ripgrep 和 csv 等高质量开源库。
选用 winnow 的理由就相对随机。其实 Rust 生态里比较有名的 Parser Combinator 是 nom 库。但是当时 ScopeDB 已经用过 nom 库来解析 ScopeQL 了,我感觉使用的过程中有一些不爽的点。正好当时 nom 一年多没发新版本了,我想着 winnow 号称是它的积极维护的分支,维护者是 Rust Team 的活跃成员,或许可以试试。实际情况是也没有好到哪里去,而且我写的时候不是完全按组合子的味道写的,最终结果有点半手写半组合子的风格,可能还不如纯手写。不过好在 Cron 表达式的结构非常固定,而且可见的迭代需求不多,大致知道怎么回事,代码一直能看懂就差不多了。客观来说,最初采用 winnow 还是节省了不少 while-if-match 式的样板代码。
文档与测试
由于 Cronexpr 的逻辑相对简单,经历过大约两周的迭代后,所有接口和实现基本就已经稳定了。这期间主要修正接口和实现的反馈,来自于 ScopeDB 的实用情况,以及参考现有软件库的接口设计方式。例如,我就是在看到 croner 和 saffron 的接口设计后,才想到可以做一个 iter_after 的接口。
同时,由于 Cron 表达式有参考实现,而且在开发的过程中,我遇到了很多具体“村规”的理解和处理,叠加上当时受到 jiff 库详实文档的启发,我把 Cronexpr 开发过程当中所有的设计理念跟概念都用文档的形式记录了下来。后来发布到 Hacker News 上的时候,也有读者回应称从文档里了解到许多此前不知道的 Cron 表达式的细节。
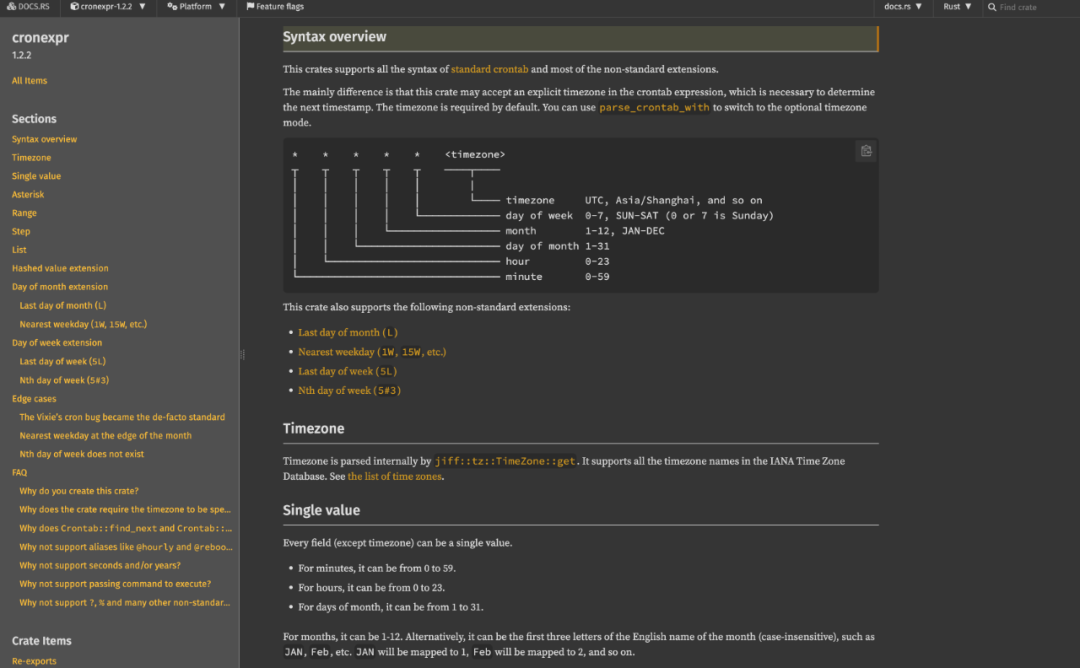
除此以外,实现一个成熟的功能,也很容易找到前人写过的测试集。Cronexpr 最适合的测试模式,当然是所谓的快照测试(Snapshot Testing),即把解析和匹配 Cron 表达式的返回值作为快照记录下来,在迭代过程中保证这些返回值总是一致。因为返回值的文本,尤其是报错时的文本经常相对冗长,所以用手写 assert_eq! 的方式可能会难以维护。我用 insta[5] 工具维护了近一百个测试结果的快照。
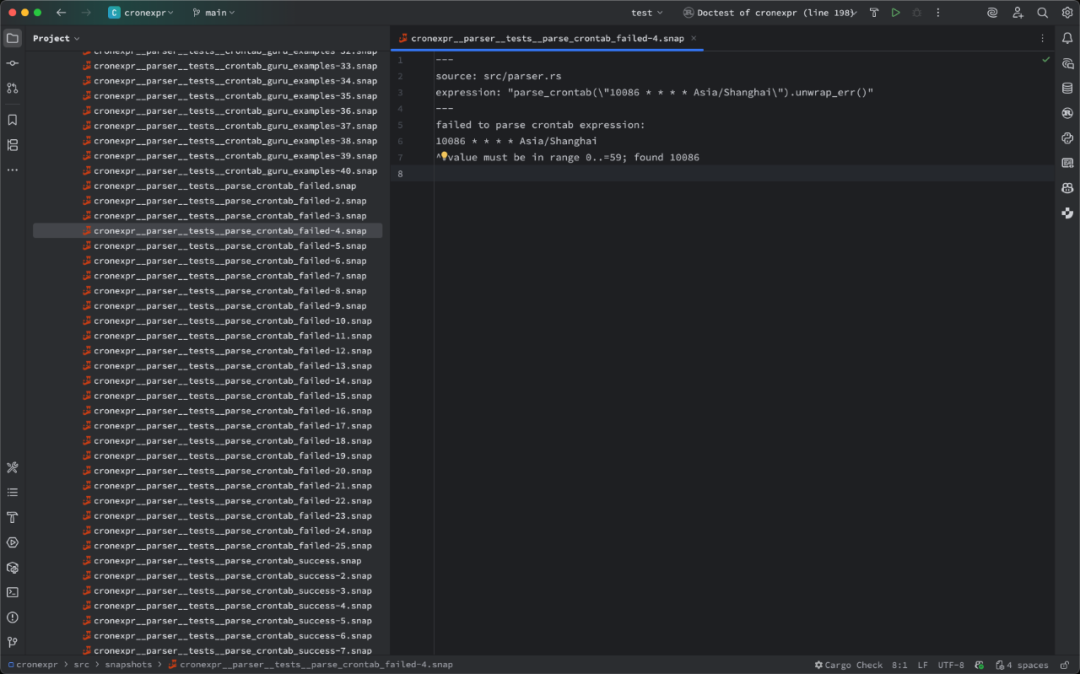
顺带一提,ScopeDB 也重度使用 insta 做快照测试,包括 ScopeQL 的 Parsing 测试,以及端到端的类 sqllogictest 的测试。实际效果跟 sqllogictest 基本一样,而且能够跟 Rust 原生的功能做更紧密且可定制化的集成,不用依赖一个新的 DSL 跟每次需要新功能就要对 DSL 做扩展开发。
实际效果与现状
ScopeDB 从第一个测试版本开始就支持 CREATE JOB 功能。
Cronexpr 首先被用在 CREATE JOB 的执行上,即在创建后台作业时先校验 Cron 表达式是否是合法的。随后,ScopeDB 的 server 进程本身会启动一个线程,实时监督哪些 JOB 已经到了需要再次调度的时刻,并触发 JOB 执行。虽然涉及的代码行数不多,但却是 ScopeDB 能够高效运维的核心能力之一。
目前,Cronexpr 已经发布了 1.0 版本,除了偶尔跟进一下依赖库的版本,平常基本没有什么需要再做开发的地方。我能想到的迭代需求,可能还有以下几个:
有开发者提出过给 Cronexpr 做一套 Fuzz 测试。我觉得没啥必要,因为实际的 case 非常有限,目前基本都枚举完了。但是如果有人做了一个不错的 Fuzz 方案,可以拿 Cronexpr 做实验。
把 winnow 的依赖去掉。这样,继我在写作本文之前把 thiserror 依赖去掉以后,Cronexpr 就可以仅依赖不可能去掉的 jiff 库,尽可能的减少不必要的依赖。如前所述,winnow 在 Cron 表达式这样一个语法非常固定的场景里作用有限。
有人可能想要支持可选的秒级、年份级 Cron 表达式。不过这些都是比较小众的需求,我在自己有实际需求之前就不实现了。
涓滴开源与开源的可持续性
在 ScopeDB 的开发过程中,不只有 Cronexpr 一个开源库诞生。上面提到的 server 进程本身会启动一系列后台线程,这些后台线程的调度就是由 Fastimer[6] 库支持的。此外,ScopeDB 使用的 Fastrace[7] + Logforth[8] 方案,实际上是当前 Rust 生态非常先进且可靠的一套日志追踪方案。这些案例或许我在后续文章中还会展开。
要说跟 Cronexpr 相似的,应当是 StackSafe[9] 这个用于避免递归调用和递归数据结构栈溢出的小公共库。库作者 Andy 老师还写了一篇博文[10]介绍其设计理念跟使用方式。
其他还有一些体量不大的软件库,比如 Mea 和 Fastpool 等等。但是它们设计到我很想吐槽的 Async Rust 生态,所以可能会单独写几篇文章讨论它们的情况。
回到开源项目的可持续性上来,这些项目的源头活水,首先就是被 ScopeDB 商业产品所需求。在开源以后,例如 Cronexpr、Fastrace 和 Logforth 等软件库,也逐渐有了第三方的下游依赖。这些新的用户为我们开源的项目提供了宝贵的反馈,有些帮我们提前解决了将要遇到的问题,有些帮助我们更好的设计接口。用户反馈本身也是对工程师编写软件的正向反馈:看到自己写作的软件能够帮到更多的人,被更多的人认可,是一件非常开心的事情。
因此,涓滴开源是一种可持续的开源模式。开源开发者通过商业软件已经实现了经济可持续,将开发商业软件过程中,微小但完整的功能模块,且其本身不产生商业价值,反而最好开源寻求同行评审,以公共库的形式开源发布出来,这是商业开源生产软件的其中一种形式。
这个世界上这样产生的开源软件有很多,包括前文提到的 Cloudflare 开源的 saffron 也属于此类。只要公司不做禁止,这类软件就可自由生长;而如果企业能够稍加引导,这些软件就能成为技术品牌影响力的一部分,其价值将在长时间跨度上不断为企业带来正面的回报。
参考资料
[1]
Cronexpr: https://crates.io/crates/cronexpr
[2]ScopeDB 云数据库: https://www.scopedb.io/
[3]croner: https://docs.rs/croner/latest/croner/
[4]saffron: https://docs.rs/saffron/latest/saffron/
[5]insta: https://insta.rs/
[6]Fastimer: https://github.com/fast/fastimer
[7]Fastrace: https://github.com/fast/fastrace
[8]Logforth: https://github.com/fast/logforth
[9]StackSafe: https://github.com/fast/stacksafe
[10]博文: https://fast.github.io/blog/stacksafe-taming-recursion-in-rust-without-stack-overflow/
)


)




 打不开,无网络连接的问题!)






 视频教程 - 词云图-微博评论词云图实现)

、内核链表、栈(系统栈、实现方式)、队列(实现方式、应用))
:windows安装使用node.js 安装express,suquelize,sqlite,nodemon)
