本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。如果你想系统学习AI大模型应用开发,挑战AI高薪岗位,可在文章底部联系。
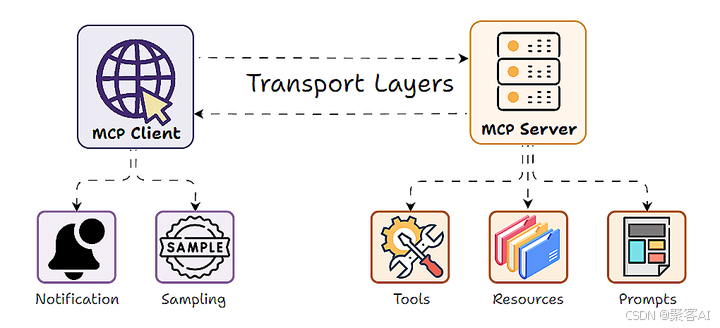
在现代大语言模型(LLM)应用架构中,Model-Client-Protocol (MCP) 设计模式因其清晰的职责分离(服务器暴露工具、数据和提示,客户端使用 LLM 调用)而广受欢迎。然而,一个关键问题随之浮现:当服务器自身逻辑也需要利用 LLM 的智能(如文本理解、生成、摘要、决策)来完成其功能时,传统的 MCP 模式就显得力不从心了。 服务器通常需要自行集成昂贵的 LLM API 或在本地运行计算密集型模型,这带来了成本、扩展性和灵活性的巨大挑战。今天我们就来探讨使用FastMCP框架进行采样的概念、实现和应用。
一、MCP 采样:概念与核心动机
LLM 采样(Sampling) 正是为解决这一矛盾而设计的创新机制。它颠覆了传统的单向 MCP 交互,创造了一个“双向”或“反转”的架构:
- 传统模式: 客户端 LLM 调用服务器提供的工具/函数。
- 采样模式:服务器在处理客户端请求的过程中,可以主动向客户端发出请求,委托客户端的 LLM 模型执行文本生成任务(即“采样”),并将结果返回给服务器。
简单来说,MCP 采样允许服务器说:“嘿,客户端,请用你的 LLM 帮我完成这个任务(比如总结这段文本、分析这个数据点、生成一条回复),然后把结果告诉我。”
ps:如果你对MCP相关技术不是很熟悉,我这边还整理了一个详细的技术文档,粉丝朋友自行领取《MCP 技术详解》
二、为什么需要采样?关键优势解析
采样机制为 MCP 架构带来了革命性的优势:
强大的可扩展性:
- 痛点: 服务器端集中处理所有 LLM 推理任务会成为性能瓶颈,尤其在高并发场景下(如数百用户同时触发文本生成)。
- 采样方案: 服务器将计算密集型的 LLM 工作负载卸载(Offload)到各个客户端。
- 效果: 服务器自身资源(CPU、内存)得以释放,专注于核心业务逻辑和协调,从而能够轻松处理海量并发请求。每个客户端负责处理自己的 LLM 计算需求,实现了分布式 AI 计算。
显著的成本效率:
- 痛点: 服务器端集中调用商业 LLM API 会产生巨额费用,或在本地部署高性能模型需要昂贵的基础设施投入和维护。
- 采样方案: 与 LLM 推理相关的所有成本(API 调用费、本地计算资源消耗)均由客户端承担。
- 效果: 服务器运营方无需为用户的 AI 计算付费或维护庞大的 GPU 集群,极大降低了运营成本。成本被自然地分摊给最终用户。
LLM 选择的终极灵活性:
- 痛点: 服务器强制规定使用的 LLM 模型,无法满足不同用户对模型性能、成本、隐私或本地部署的差异化需求。
- 采样方案:客户端完全自主决定使用哪个 LLM 模型来处理服务器的采样请求(例如:OpenAI GPT-4o、Anthropic Claude、本地运行的 LLaMA、Mistral 等)。服务器可以建议偏好模型,但决定权在客户端。
- 效果: 用户可以根据自身情况选择最优模型,服务器代码无需为适配不同模型而修改,实现了真正的解耦和灵活性。
有效避免性能瓶颈:
- 痛点: 集中式 LLM 处理容易在服务器端形成队列,导致请求延迟增加。
- 采样方案: LLM 任务由用户各自的本地环境并行处理。
- 效果: 消除了服务器端的单一 LLM 处理瓶颈,显著降低延迟,提升整体系统响应速度和用户体验。
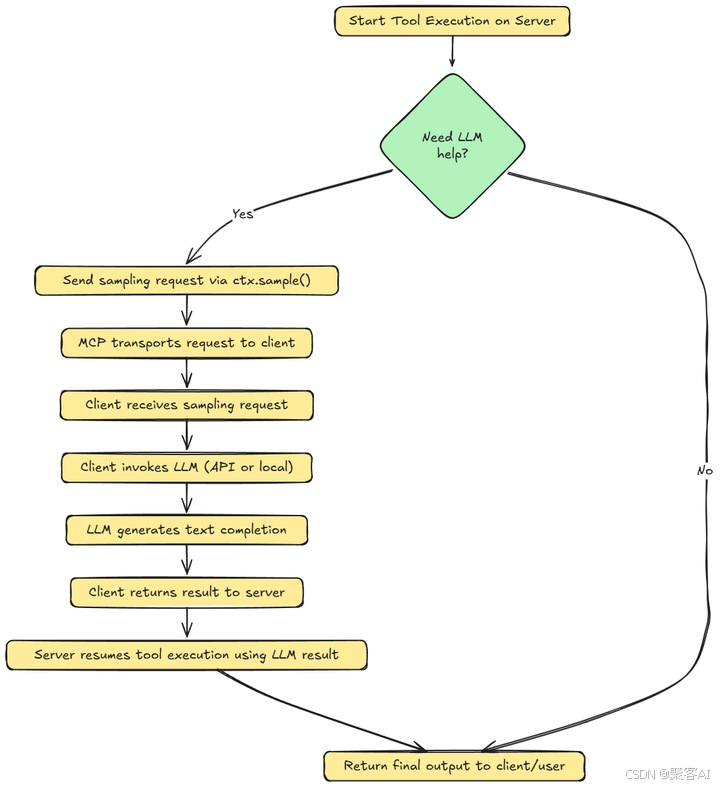
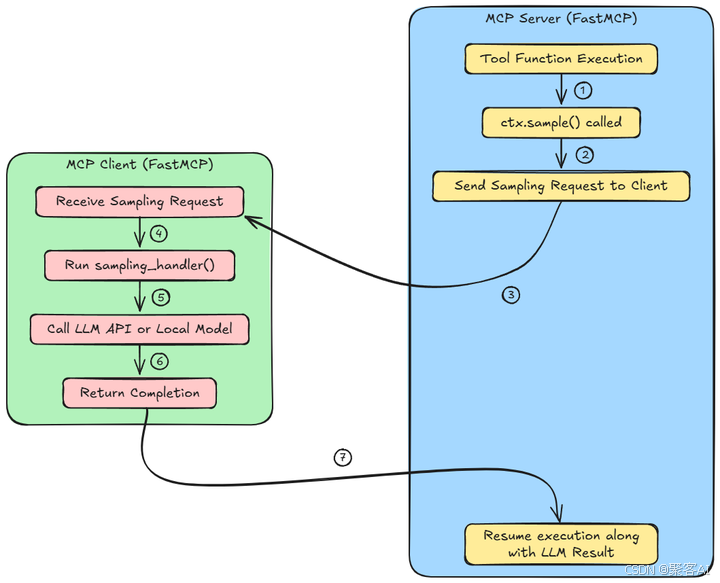
三、MCP 采样架构深度解析
理解采样如何融入 MCP 的客户端-服务器模型至关重要:
MCP 服务器(蓝色)
- 一个函数/工具正在服务器上的代理工作流程中运行。
- 在这个函数内部,
ctx.sample()被调用来调用一个大语言模型以生成响应或做出决策。 - 此调用不会在本地执行采样。相反,它将请求打包并发送到MCP客户端。
MCP客户端(绿色)
- 客户端监听来自服务器的采样请求,并接收此请求。
- 用户定义的
sampling_handler()被触发。此函数定义了如何处理请求。例如,格式化提示,处理重试等。 - 客户端使用外部LLM API(如OpenAI)或本地模型(如LLaMA或Mistral)来完成请求。
- 客户端将生成的文本作为对服务器的响应发送回来。
完成之后,我们返回MCP服务器(蓝色),并继续执行LLM的结果。服务器从客户端接收结果,并使用LLM生成的输出恢复工具函数的执行。
关键技术点:
- 异步非阻塞: 整个采样过程是异步的。当服务器工具函数调用
ctx.sample()时,该协程会暂停(Yield) 并等待客户端响应,期间服务器可以处理其他请求,避免阻塞。 - 协议保障: MCP 协议负责采样请求和响应的可靠传输。FastMCP 等框架抽象了底层传输细节(stdio, SSE, WebSocket 等)。
- 安全边界: 采样请求严格限定为请求文本生成。服务器无法强制客户端执行任意代码;客户端也仅在其安全环境下运行自己的 LLM 处理预设的提示词。这符合最小权限原则。
- 上下文对象 (
ctx): 在 FastMCP 中,服务器工具函数通过Context对象(通常命名为ctx)访问采样功能(ctx.sample())。这个对象是强大的枢纽,还提供日志记录、发送进度更新等功能。框架通过依赖注入自动将ctx提供给声明了该参数的函数。
FastMCP 实现示例
# 服务器端 (FastMCP Server - Blue)
from fastmcp import tool, Context@tool
async def analyze_data(ctx: Context, input_data: dict) -> dict:"""一个需要LLM协助分析数据的工具函数。"""# ... 一些预处理逻辑 ...# 关键采样调用:请求客户端LLM分析数据# 提示词由服务器定义,但执行在客户端analysis_prompt = f"基于以下数据生成关键洞察报告:\n{input_data}\n报告要求:..."llm_analysis = await ctx.sample(prompt=analysis_prompt,model="gpt-4-turbo", # 可选:服务器建议的模型偏好temperature=0.7,max_tokens=500) # 此处异步等待客户端返回# ... 使用 llm_analysis 结果进行后续处理 ...final_result = process_analysis(llm_analysis, input_data)return final_result# 客户端 (FastMCP Client - Green)
from fastmcp import FastMCPClientdef my_sampling_handler(request: SamplingRequest) -> SamplingResponse:"""用户定义的采样处理器。request 包含 prompt, model(建议), temperature 等参数。"""# 1. (可选) 根据 request.model 或客户端配置决定最终使用的模型chosen_model = select_model(request.model) # 客户端有最终选择权# 2. (可选) 对提示进行最终处理或添加指令final_prompt = f"你是一个数据分析专家。{request.prompt}"# 3. 调用实际LLM (示例: 使用OpenAI API, 也可以是本地模型)import openairesponse = openai.chat.completions.create(model=chosen_model,messages=[{"role": "user", "content": final_prompt}],temperature=request.temperature,max_tokens=request.max_tokens)# 4. 提取生成的文本llm_output = response.choices[0].message.content.strip()# 5. 构建并返回采样响应return SamplingResponse(content=llm_output)# 创建客户端并注册采样处理器
client = FastMCPClient(server_url="...")
client.register_sampling_handler(my_sampling_handler)
client.connect() # 开始连接服务器并监听请求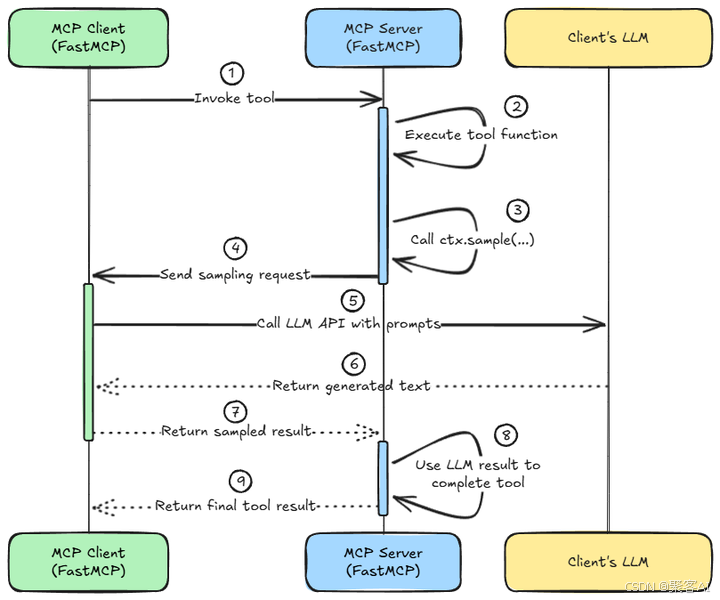
四、应用场景:释放服务器端 AI 潜能
MCP 采样的应用场景极其广泛,尤其适用于需要服务器端引入智能但希望保持轻量和成本效益的场景:
- 智能文档处理服务器: 服务器接收文件,委托客户端 LLM 进行摘要、翻译、关键信息提取、问答,然后整合结果提供高级服务。
- 个性化内容生成服务: 服务器管理内容和规则,将具体的、高度个性化的文本生成(如邮件草稿、营销文案、故事延续)委托给用户选择的 LLM。
- 数据分析与洞察平台: 服务器处理原始数据,将需要自然语言理解和推理的数据解释、报告生成任务卸载到客户端 LLM。
- AI 驱动的决策支持系统: 服务器提供决策框架和上下文,将基于复杂信息的建议生成或风险评估委托给客户端 LLM。
- 交互式代理(Agents)工作流: 在复杂的多步骤 Agent 工作流中,服务器协调的 Agent 可以将特定的 LLM 思考、规划或生成子任务分发给客户端执行。
结语:总结来说,MCP中的采样允许分布式AI计算。MCP服务器可以在不嵌入模型或调用外部API的情况下,整合强大的LLM功能。这是一座在通常确定性的服务器逻辑和动态文本生成之间的桥梁,通过标准化的协议调用来实现。好了,本次分享就到这里,如果对你有所帮助,记得告诉身边有需要的人,我们下期见。


)






)

)







