获取Firecrawl apikey
打开官网,使用github账号登录
https://www.firecrawl.dev/

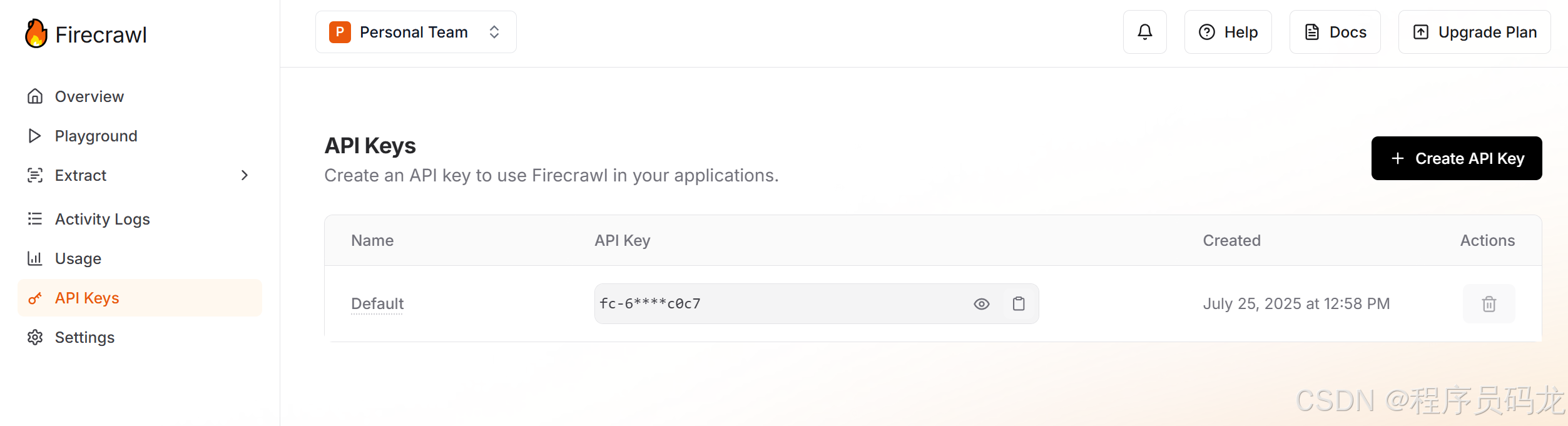
进入个人中心
https://www.firecrawl.dev/app/api-keys
使用PyCharm创建python项目
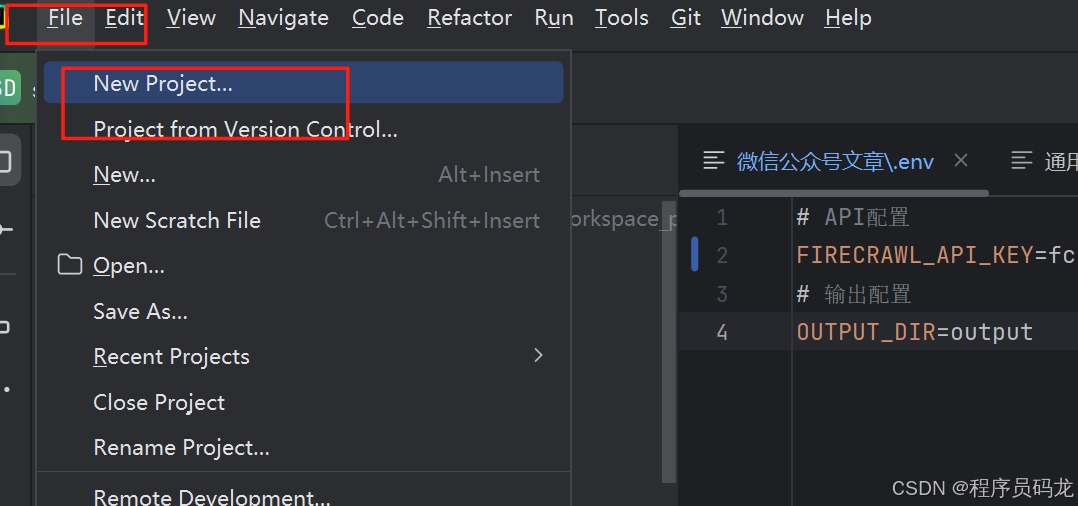
创建.env
# API配置
FIRECRAWL_API_KEY=fc-9*********0816d5ac6b20
# 输出配置
OUTPUT_DIR=output
创建url_list.txt
https://mp.weixin.qq.com/s/NH4Odi-xT_hlmZdGe0dw6Q
创建wechat_crawler.py
import os
from typing import Dict, Any, List
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import logging
import re# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)# 加载.env文件
load_dotenv()class WeChatCrawler:def __init__(self, api_key: str = None):"""初始化微信公众号爬虫Args:api_key: Firecrawl API密钥"""self.api_key = api_key or os.getenv('FIRECRAWL_API_KEY')if not self.api_key:raise ValueError("请提供Firecrawl API密钥")self.app = FirecrawlApp(api_key=self.api_key)self.output_dir = os.getenv('OUTPUT_DIR', 'output')# 创建输出目录if not os.path.exists(self.output_dir):os.makedirs(self.output_dir)def read_urls_from_file(self, file_path: str = 'url_list.txt') -> List[str]:"""从文件中读取URL列表Args:file_path: URL列表文件路径Returns:List[str]: URL列表"""urls = []try:with open(file_path, 'r', encoding='utf-8') as file:for line in file:url = line.strip()if url and url.startswith('http'): # 确保是有效的URLurls.append(url)logger.info(f"从 {file_path} 读取到 {len(urls)} 个URL")except FileNotFoundError:logger.error(f"文件 {file_path} 不存在")except Exception as e:logger.error(f"读取文件时出错: {e}")return urlsdef scrape_url(self, url: str) -> Dict[str, Any]:"""爬取单个URL的文章内容Args:url: 要爬取的URLReturns:Dict: 爬取结果"""try:logger.info(f"开始爬取: {url}")# 使用Firecrawl爬取URLresult = self.app.scrape_url(url, formats=['markdown', 'html'])logger.info(f"成功爬取: {url}")return resultexcept Exception as e:logger.error(f"爬取 {url} 时出错: {e}")return {'error': str(e)}def save_markdown(self, content: str, filename: str) -> None:"""保存Markdown内容到文件Args:content: Markdown内容filename: 文件名"""try:file_path = os.path.join(self.output_dir, filename)with open(file_path, 'w', encoding='utf-8') as file:file.write(content)logger.info(f"成功保存: {file_path}")except Exception as e:logger.error(f"保存文件 {filename} 时出错: {e}")def generate_filename(self, url: str) -> str:"""根据URL生成文件名Args:url: URLReturns:str: 生成的文件名"""try:# 尝试从微信URL中提取标识符# 微信公众号文章URL格式: https://mp.weixin.qq.com/s/标识符match = re.search(r'/s/([A-Za-z0-9_-]+)', url)if match:identifier = match.group(1)return f"wechat_article_{identifier}.md"else:# 如果解析失败,使用时间戳import timetimestamp = int(time.time())return f"wechat_article_{timestamp}.md"except:# 如果解析失败,使用时间戳import timetimestamp = int(time.time())return f"wechat_article_{timestamp}.md"def crawl_all_urls(self) -> None:"""爬取所有URL并保存为Markdown文件"""urls = self.read_urls_from_file()if not urls:logger.warning("没有找到要爬取的URL")returnlogger.info(f"开始爬取 {len(urls)} 个URL")for i, url in enumerate(urls, 1):logger.info(f"正在处理第 {i}/{len(urls)} 个URL")result = self.scrape_url(url)# 检查返回结果中是否包含markdown内容# 处理可能的超时或其他错误try:# 检查是否有错误if hasattr(result, 'error') and result.error:logger.error(f"爬取 {url} 出错: {result.error}")continue# 检查是否有markdown内容if hasattr(result, 'markdown') and result.markdown:filename = self.generate_filename(url)self.save_markdown(result.markdown, filename)else:# 尝试转换为字典result_dict = result.dict() if hasattr(result, 'dict') else resultif isinstance(result_dict, dict) and 'markdown' in result_dict and result_dict['markdown']:filename = self.generate_filename(url)self.save_markdown(result_dict['markdown'], filename)else:logger.error(f"无法获取 {url} 的Markdown内容")except Exception as e:logger.error(f"处理 {url} 的结果时出错: {e}")if __name__ == "__main__":try:# 创建爬虫实例crawler = WeChatCrawler()# 爬取所有URLcrawler.crawl_all_urls()print("所有文章爬取完成!")except Exception as e:logger.error(f"程序执行出错: {e}")print(f"程序执行出错: {e}")

登录注册 - Compose)
)


)






)






)