YOLO — YOLO11模型以及项目详解
文章目录
- YOLO --- YOLO11模型以及项目详解
- 一,开源地址
- 二,重要模块
- 2.1 C3K2
- 2.2 C2PSA
- 2.3 检测头
- 三,网络结构
- 3.1 整体结构划分
- 3.2 Backbone 结构分析(从下往上看)
- 3.3 结构分析(特征融合)
- 3.4 Head 检测头
- 3.5 关键模块说明
- 3.7 模型主要特点
- 3.8 模型对比
- 四,开源项目
- 4.1 下载源码
- 4.2 新建环境
- 4.3 安装包
- 4.4 下载推理文件
- 4.5 数据集
- 4.6 检测文件
- 4.7 模型训练
- 五,优缺点
一,开源地址
-
官方文档:https://github.com/ultralytics/ultralytics
-
开发文档:https://docs.ultralytics.com/
二,重要模块
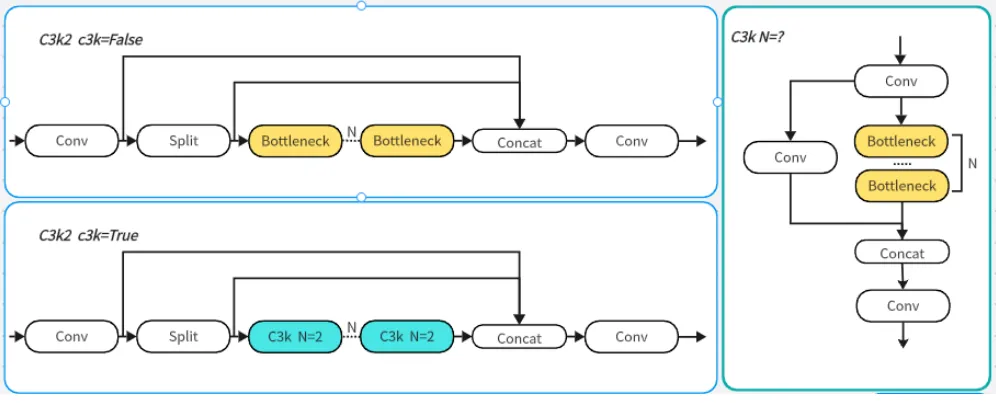
2.1 C3K2
-
C3K2 模块 是基于 C2F 模块 的一种变体,它代码中有一个设置
- 当
C3K2参数为False时,模块内部使用普通 Bottleneck - 当
C3K2参数为True时,模块内部使用 C3k 结构
- 当
-
代码中的 C3K2 的使用:
[-1, 2, C3k2, [256, False, 0.25]]- -1:该模块的输入来自哪一个模块的输出。-1 表示当前 C3k2 模块的输入 来自上一个模块的输出
- 2:表示模块内包含 2 个 C3k 或 Bottleneck 模块(具体数量需要根据网络版本的深度系数进行调整)
- C3K2:模块名称,等于搭建该模块的类的名称,用于找到该类去搭建模块
- 256:输出通道数(实际输出通道数需要乘以宽度系数
width) - False:True 表示内部使用 C3k 模块;False 表示内部使用 Bottleneck
- 0.25:用于控制 C3K2 模块中的通道数
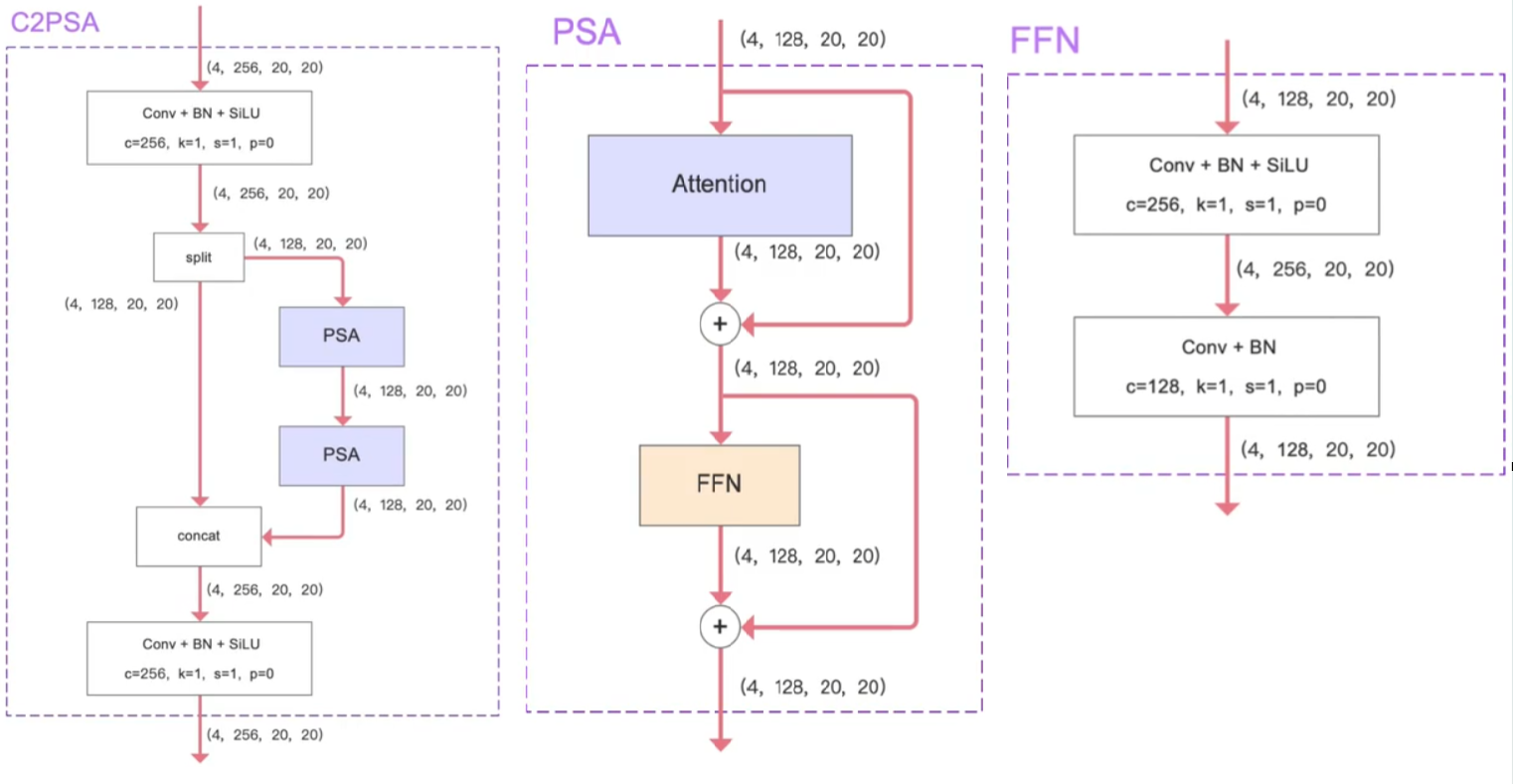
2.2 C2PSA
- C2PSA 是对 C2f 模块的扩展,它结合了 PSA(Pointwise Spatial Attention)块,用于增强特征提取与和注意力机制,C2PSA 实现了加入 PSA 块,实现了更强大的注意力机制,从而提高了模型对重要特征的捕捉能力
- C2PSA 模块由两部分构成:C2f 分支结构、PSA(Pointwise Spatial Attention)块
- 代码中 C2PSA 的使用:
[-1, 2, C2PSA, [1024]]- -1:该模块的输入来自哪一个模块的输出。-1表示 当前 C3k2 模块的输入 来自上一个模块的输出
- 2:模块内需要使用几个 PSA 模块(具体数量需要根据网络版本的深度系数进行调整)
- C2PSA:模块名称
- 1024:输出通道数(实际输出通道数需要乘以宽度系数
width)
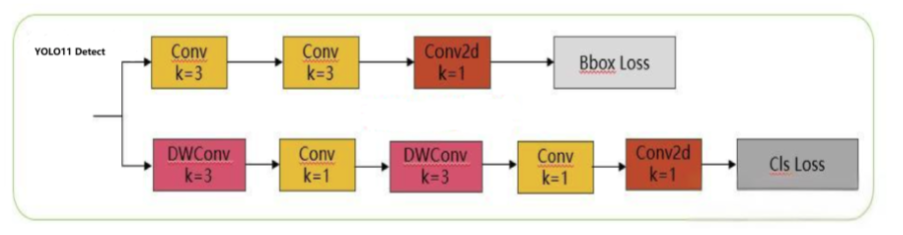
2.3 检测头
- YOLO11 在原先的 2 个解耦分类检测头中,进一步增加了两个深度可分离卷积(DWConv),提高了模型的特征提取能力
- 代码中 C2PSA 的使用:
[[16, 19, 22], 1, Detect, [nc]]- [16, 19, 22]:第16、19、22 模块的的输出,作为 Detect 检测头的输入
- 1:模块重复次数,检测头的重复次数一般都为 1,检测头通常不重复
- Detect:模块名称,等于搭建该模块的类的名称,用于找到该类去搭建模块
- nc:类别数
三,网络结构
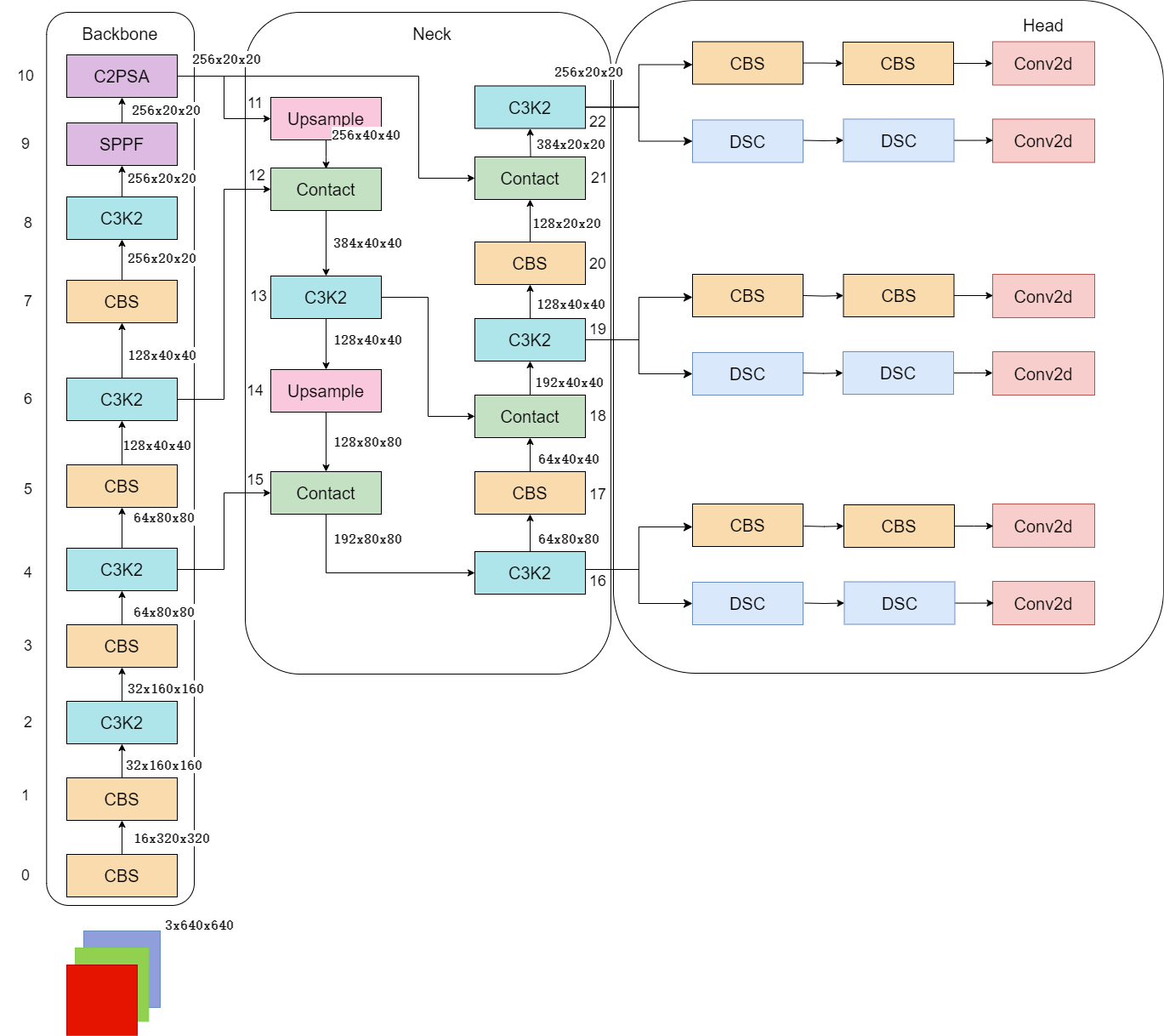
3.1 整体结构划分
| 模块名称 | 作用 | 备注 |
|---|---|---|
| Backbone | 特征提取 | 从输入图像中提取多尺度特征 |
| Neck | 特征融合 | 使用 FPN + PAN 结构进行多尺度特征融合 |
| Head | 检测头 | 输出分类、框回归、置信度等信息 |
3.2 Backbone 结构分析(从下往上看)
| 层 | 模块 | 输出尺寸 | 说明 |
|---|---|---|---|
| 输入 | Input | 3×640×640 | 输入图像 |
| 1 | CBS | 16×320×320 | 初始卷积,通道从 3 → 16 |
| 2 | C3K2 | 32×160×160 | 轻量级残差模块,通道翻倍,宽高减半 |
| 3 | CBS | 64×80×80 | 继续下采样 |
| 4 | C3K2 | 64×80×80 | 保持尺寸,增强特征 |
| 5 | CBS | 128×40×40 | 下采样 |
| 6 | C3K2 | 128×40×40 | 特征提取 |
| 7 | CBS | 256×20×20 | 下采样 |
| 8 | C3K2 | 256×20×20 | 特征提取 |
| 9 | SPPF | 256×20×20 | 空间金字塔池化,增强感受野 |
3.3 结构分析(特征融合)
| 层 | 模块 | 输出尺寸 | 说明 |
|---|---|---|---|
| 10 | C2PSA | 256×20×20 | 引入注意力机制(PSA) |
| 11 | Upsample | 256×40×40 | 上采样 |
| 12 | Contact | 384×40×40 | 与 Backbone 中同尺寸特征拼接 |
| 13 | C3K2 | 256×40×40 | 融合特征 |
| 14 | Upsample | 128×80×80 | 继续上采样 |
| 15 | Contact | 192×80×80 | 与更浅层特征拼接 |
| 16 | C3K2 | 128×80×80 | 输出 P3 层(小目标) |
| 17 | CBS | 128×40×40 | 下采样 |
| 18 | Contact | 384×40×40 | 与中层特征拼接 |
| 19 | C3K2 | 256×40×40 | 输出 P4 层(中目标) |
| 20 | CBS | 256×20×20 | 下采样 |
| 21 | Contact | 512×20×20 | 与深层特征拼接 |
| 22 | C3K2 | 256×20×20 | 输出 P5 层(大目标) |
3.4 Head 检测头
| 层 | 模块 | 输出尺寸 | 说明 |
|---|---|---|---|
| P3/P4/P5 | Conv2d | 每个尺度输出:类别数 + 4(框) + 1(置信度) | 对应小/中/大目标检测头 |
3.5 关键模块说明
| 模块名 | 作用 |
|---|---|
| CBS | Conv + BN + SiLU,标准卷积块 |
| C3K2 | 类似 C3,但使用更轻量的 bottleneck(K=2) |
| C2PSA | 引入 PSA(Pyramid Squeeze Attention)注意力机制 |
| SPPF | 快速空间金字塔池化,提升感受野 |
| Contact | 特征拼接(concatenate)操作 |
| Upsample | 上采样,用于特征融合 |
3.7 模型主要特点
-
YOLO11采用改进的骨干和颈部架构,增强了特征提取能力,提高了物体检测的精确度
-
针对效率和速度优化:精细的架构设计和优化的训练流程在保持准确性和性能之间最佳平衡的同时,提供更快的处理速度
-
更少的参数,更高的准确度:YOLO11m 在 COCO 数据集上实现了比 YOLOv8m 更高的 mAP,参数减少了 22%,提高了计算效率,同时不牺牲准确度
-
跨环境的适应性:YOLO11 可以无缝部署在边缘设备、云平台和配备 NVIDIA GPU的系统上,确保最大的灵活性
-
支持广泛的任务范围:图像分类、目标检测、实例分割、姿态估计、定向对象检测 (OBB)、多目标跟踪等

3.8 模型对比
下图是 YOLOV11 各个模型在 COCO 数据集上的表现:
- mAP50:IOU 阈值为 0.50 时的平均精度,评估较为宽松,主要反映模型的粗略检测能力
- mAP50-95:在不同 IOU 阈值下(从 0.50 到 0.95,步长 0.05,共 10 个值)计算 AP 的均值,是更为严谨和全面的性能指标,在报告模型性能时,mAP50-95 能值够更好地衡量模型的总体表现,更具参考价值
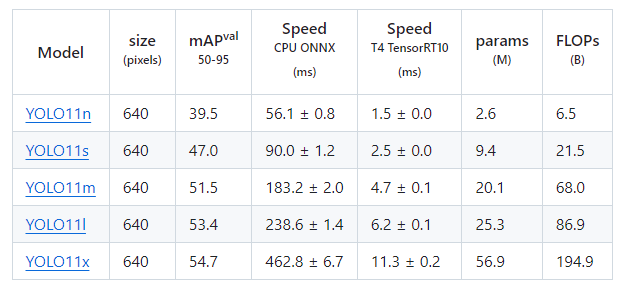
和其他 YOLO 版本性能对比图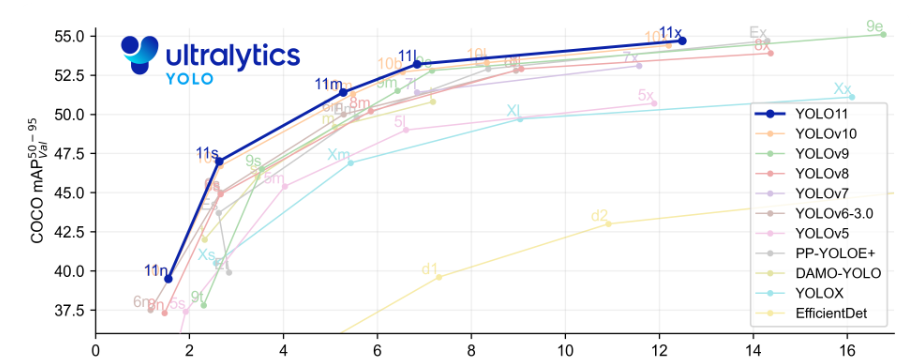
四,开源项目
4.1 下载源码
第一步:下载 yolo11 源码,前面的步骤已经完成
4.2 新建环境
第二步:新建环境,见
https://blog.csdn.net/m0_73338216/article/details/146123256
4.3 安装包
-
在 yolov11_env 虚拟环境中安装库:
- 在 Python≥3.8 的环境中先根据计算机是否支持 GPU 安装 Pytorch>=1.8,如果没有 GPU 可以不执行这一步【这个下载命令有的有问题,尽量选择 pip 命令下载,如果 cuda 版本太低,先去更新驱动】
# CUDA 12.1 pip install torch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0 --index-url https://download.pytorch.org/whl/cu121- 安装 ultralytics 包及其所有需求
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple
4.4 下载推理文件
先下载 yolov11 的权重文件,选择下载一个即可,然后放入项目文件夹中
执行检测命令:可以选择命令方式,也可以选择代码方式,可以参考网站https://docs.ultralytics.com/zh/modes/predict/#key-features-of-predict-mode
4.5 数据集
第六步:数据集标注
-
模型训练的数据、验证的数据都是由专门的人标注制作的,常用的标注工具labelImg、labelme。 这里介绍 labelImg 的使用
- 新建虚拟环境,略 -
激活环境,输入命令
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple安装 labelimg 库
在激活环境下,执行命令labelimg打开 labelimg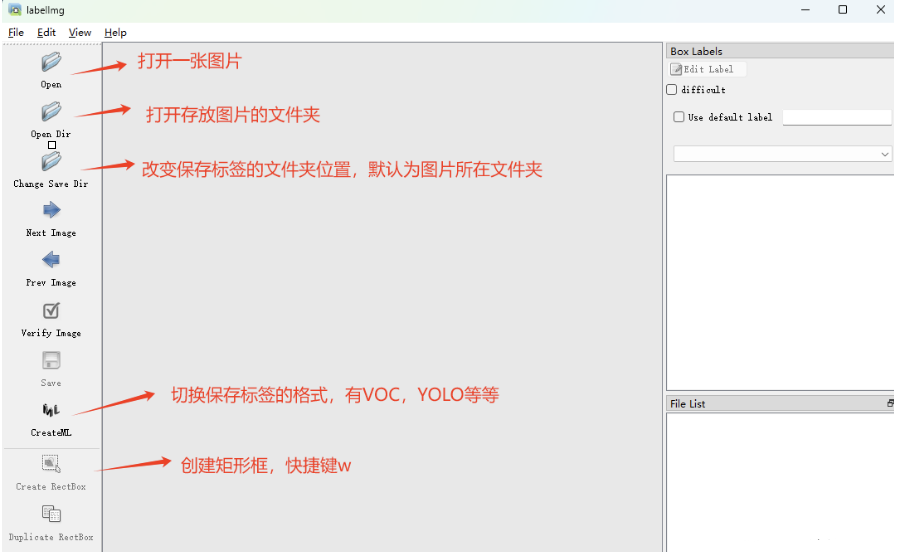
标注完成后的数据集,图示: -
images:存放需要被标注的图片信息
-
labels:存放标注的图片的位置、类型信息
4.6 检测文件
from ultralytics import YOLO
# 加载训练好的模型,改为自己的路径
model = YOLO('yolo11s.pt')
# 修改为自己的图片路径及文件名
source = 0
# 运行推理,并附加参数
model.predict(source, show=True, save=True)
# model.predict(source, # 图片或视频的源目录
# conf=0.5, # 用于检测的 对象置信阈值,只有置信度高于此阈值的对象才会被检测出来
# iou=0.7, # 非极大值抑制(NMS)的交并比(loU)值
# imgsz=160, # 输入图像尺寸
# half=False, # 使用半精度(FP16)
# device=0, # 运行设备,如device=0或device = cpu
# max_det=300, # 每个图像的最大检测数
# # vid_srtide=False,# 视频帧率步长,预测试图片需要注释
# stream_buffer=False, # 缓冲所有流帧( True )或 返回最近的帧( Fa1se )
# visualize=False, # 是否可视化模型特征
# augment=False, # 是否对预测源应用图像增强
# agnostic_nms=False, # 是否使用类别不可知(无关)的非极大值抑制(NMS)
# classes=None, # 按类别筛选结果,即classes=0或classes=[0,2,3]
# retina_masks=False, # 是否使用高分辨率的分割掩膜
# embed=None, # 返回给定层的特征向量/嵌入
# show=False, # 如果环境允许,是否显示预测的图像和视频
# save=True, # 是否保存预测的图像和视频
# save_frames=False, # 是否保存预测的单个视频帧
# save_txt=False, # 是否将结果保存为 .txt 文件
# save_conf=False, # 是否将检测结果与置信度分数一起保存
# save_crop=False, # 是否保存裁剪的图像与结果
# show_labels=False, # 是否显示预测标签
# show_conf=False, # 是否显示预测置信度
# show_boxes=False, # 是否显示预测边界框
# line_width=None, # 边界框的线宽(如果为 None ,则缩放为图像大小)
# ))
4.7 模型训练
from ultralytics import YOLO
"""参数 默认值 说明model None 用于训练的模型文件的路径data None 数据集配置文件的路径(例如 coco8.yaml)epochs 100 训练历元总数batch 16 批量大小,可调整为整数或自动模式imgsz 640 用于训练的目标图像大小device None 用于训练的计算设备,如 cpu, 0, 0,1或 mpssave True 可保存训练检查点和最终模型权重project None 保存训练结果的项目目录名称
"""
if __name__ == "__main__":# 加载模型结构和配置文件model = YOLO("yolo11s.pt")# 开始训练results = model.train(data="ultralytics/cfg/datasets/animal.yaml",epochs=25,batch=8,imgsz=640,device='0',project='runs',)
五,优缺点
| 维度 | 优点 | 缺点 |
|---|---|---|
| 检测精度 | • 在 COCO 上 mAP 比 YOLOv8 高 1-2 pp(小目标提升更明显) • 引入 C2PSA(Pyramid Squeeze Attention),增强遮挡、小目标检测 | • 对极端长宽比、旋转密集目标仍有漏检 • 极低分辨率输入时精度下降明显 |
| 推理速度 | • 仍保持单阶段架构,速度>300 FPS(YOLO11-n,T4 GPU) • 支持 TensorRT / OpenVINO 高效部署 | • 注意力模块带来 5-10 % 额外延迟 • 参数量略大于同规模 YOLOv8,边缘端需量化 |
| 模型大小 | • 提供 n/s/m/l/x 五级权重,可按需选择 • 引入 C3K2 轻量瓶颈,参数量控制良好 | • 最小模型仍比 YOLOv8-nano 大 0.4 M 参数量 |
| 训练友好度 | • 沿用 YOLOv8 训练框架,超参少、易复现 • 支持自动锚框、断点续训、混合精度 | • 官方仅放出新版代码,向下兼容脚本需手动调整 • anchor-free 对小目标收敛速度稍慢 |
| 部署生态 | • 官方导出 ONNX、Engine、RKNN、CoreML 一键完成 • 支持 NCNN / MNN 移动端量化部署 | • 新版算子(C2PSA)在部分旧版推理框架上需自定义实现 |
| 代码/社区 | • Ultralytics 维护,文档完善,社区活跃 |

)



)



 |)


 的界面和功能)
![[NCTF2019]True XML cookbook](http://pic.xiahunao.cn/[NCTF2019]True XML cookbook)





