导读:本文介绍科技大厂 Google 2025年 7 月最新开源的 Python 库:
LangExtract,用于从非结构文本提取结构化数据,以及非官方的Javascript、Rust语言实现版本。
文章目录
- 一、关于 LangExtract
- 1.1 需求痛点
- 1.2 LangExtract
- 1.3 参考文章
- 二、小试牛刀
- 2.1 安装依赖
- 2.2 简单的人物信息抽取
- 2.3 提取公共资源交易信息
- 2.3.1 准备示例
- 2.3.2 运行结果
- 三、JavaScript 版本
- 四、Rust 版本
- 4.1 程序跑不起来😔
- 4.2 成功运行🎉
- 4.3 未来展望 🚀
- Java 版本
一、关于 LangExtract
1.1 需求痛点
很多时候,我们需要在一堆非标准的文本里面提取特定的字段(比如提取人名、电话、地址等),形成结构化的数据,如保存到 Excel 。数据量不大的情况下,人工就能胜任。如果量很大,就得借助程序(使用规则匹配)来清洗,这种方式比人工高效,但出错率也高。因为程序是非常死板的,只认设定好的规则(不会变通),而人工可以在各种未预见的情况下,依然能找到正确的数据,程序则由于不理解自然语言与答案失之交臂😂。
1.2 LangExtract
LangExtract : A Python library for extracting structured information from unstructured text using LLMs with precise source grounding and interactive visualization.
一个 Python 库,用于使用具有精确源基础和交互式可视化的 LLM 从非结构化文本中提取结构化信息。
这个库是 Google 在 2025 年 7 月底发布,目前最新版本是 1.0.8(截至2025-08-22),具有以下特点:
- 精确的源头定位:能将每次提取的内容映射到源文本中的确切位置,可通过可视化突出显示进行追溯和验证。
- 可靠的结构化输出:基于少量示例强制执行一致的输出模式,利用Gemini等支持模型中的受控生成来保证强大的结构化结果,输出可直接接入数据库等下游流程。
- 针对长文档优化:通过优化文本分块、并行处理和多次传递的策略,克服大型文档提取中的困难,提高召回率,能处理完整的小说级别的文档。
- 交互式可视化:可即时生成一个独立的交互式HTML文件,以可视化和审查数千个提取的实体及其原始上下文,方便审核和错误分析。
- 灵活的LLM支持:支持用户偏好的模型,从Google Gemini系列等基于云的LLM到通过内置Ollama接口的本地开源模型都可使用。
- 适应任何领域:只需几个示例,即可为任何领域定义提取任务,无需进行模型微调就能适应用户需求。
LangExtract 在医疗、金融、法律、科研等领域都有广泛的应用前景,例如从临床记录中提取药物名称、剂量,从合同中提取责任条款、风险项等。
1.3 参考文章
- 谷歌出品!详解“小而美” 的LangExtract:轻量却强大的结构化信息提取神器。
- 谷歌开源LangExtract:三行代码把“文本矿山”变结构化黄金,AI信息抽取从未如此简单!
二、小试牛刀
本文我们将使用豆包大模型进行实践😄。
2.1 安装依赖
mkdir langextract
# 创建虚拟环境
python -m venv .env
source .env/bin/activate # On Windows: .env\Scripts\activate
# 安装依赖
pip install langextract openai
2.2 简单的人物信息抽取
import langextract as lx# 定义示例
examples = [lx.data.ExampleData(text = "梁思成(1901年4月20日-1972年1月9日),籍贯广东新会,生于日本东京。毕生致力于中国古代建筑的研究和保护,是建筑历史学家、建筑教育家和建筑师,被誉为中国近代建筑之父。",extractions=[lx.data.Extraction(extraction_class="姓名", extraction_text="梁思成"),lx.data.Extraction(extraction_class="出生日期", extraction_text="1901年4月20日"),lx.data.Extraction(extraction_class="逝世日期", extraction_text="1972年1月9日"),lx.data.Extraction(extraction_class="出生地", extraction_text="日本东京"),lx.data.Extraction(extraction_class="职业", extraction_text="建筑历史学家、建筑教育家、建筑师"),lx.data.Extraction("荣誉", "中国近代建筑之父")]),lx.data.ExampleData(text = "林徽因(1904年6月10日-1955年4月1日),原名“徽音”,汉族,祖籍福建闽侯(今福建福州),出生于浙江杭州。为中国近现代建筑学家、文学家,清华大学建筑系教授。",extractions=[lx.data.Extraction(extraction_class="姓名", extraction_text="林徽因"),lx.data.Extraction(extraction_class="出生日期", extraction_text="1904年6月10日"),lx.data.Extraction(extraction_class="逝世日期", extraction_text="1955年4月1日"),lx.data.Extraction(extraction_class="出生地", extraction_text="浙江杭州"),lx.data.Extraction(extraction_class="职业", extraction_text="建筑学家、文学家"),lx.data.Extraction("荣誉", "")])
]# 配置模型并调用解析程序
result = lx.extract(text_or_documents="古龙(1938年6月7日一1985年9月21日),原名熊耀华,籍贯江西南昌,汉族。1938年6月7日出生于香港。武侠小说家,新派武侠小说泰斗,与金庸、梁羽生、温瑞安并称为中国武侠小说四大宗师。",prompt_description="从人物简要介绍中提取姓名、出生日期、逝世日期(如有)、出生地、职业、荣耀/成就",examples = examples,config= lx.factory.ModelConfig(model_id="doubao-seed-1-6-flash-250615",provider="OpenAILanguageModel",provider_kwargs={"temperature" : 0.1,"max_tokens" : 2048,"base_url" : "https://ark.cn-beijing.volces.com/api/v3","api_key" : ""})
)for entity in result.extractions:position_info = ""if entity.char_interval:start, end = entity.char_interval.start_pos, entity.char_interval.end_posposition_info = f" (位置: {start}-{end})"print(f"• {entity.extraction_class.capitalize()}: {entity.extraction_text}{position_info}")我们执行python index.py,大概 5 秒就能看到结果。

2.3 提取公共资源交易信息
我之前写过一篇Chrome插件 | 公共资源交易平台中标公示数据采集工具(仅作技术交流学习)的文章,里面就涉及结构化信息提取,当时用的是专家规则+正则表达式从文本中匹配结果,现在让我们试下 langextract 是否能做的更好😄。
2.3.1 准备示例
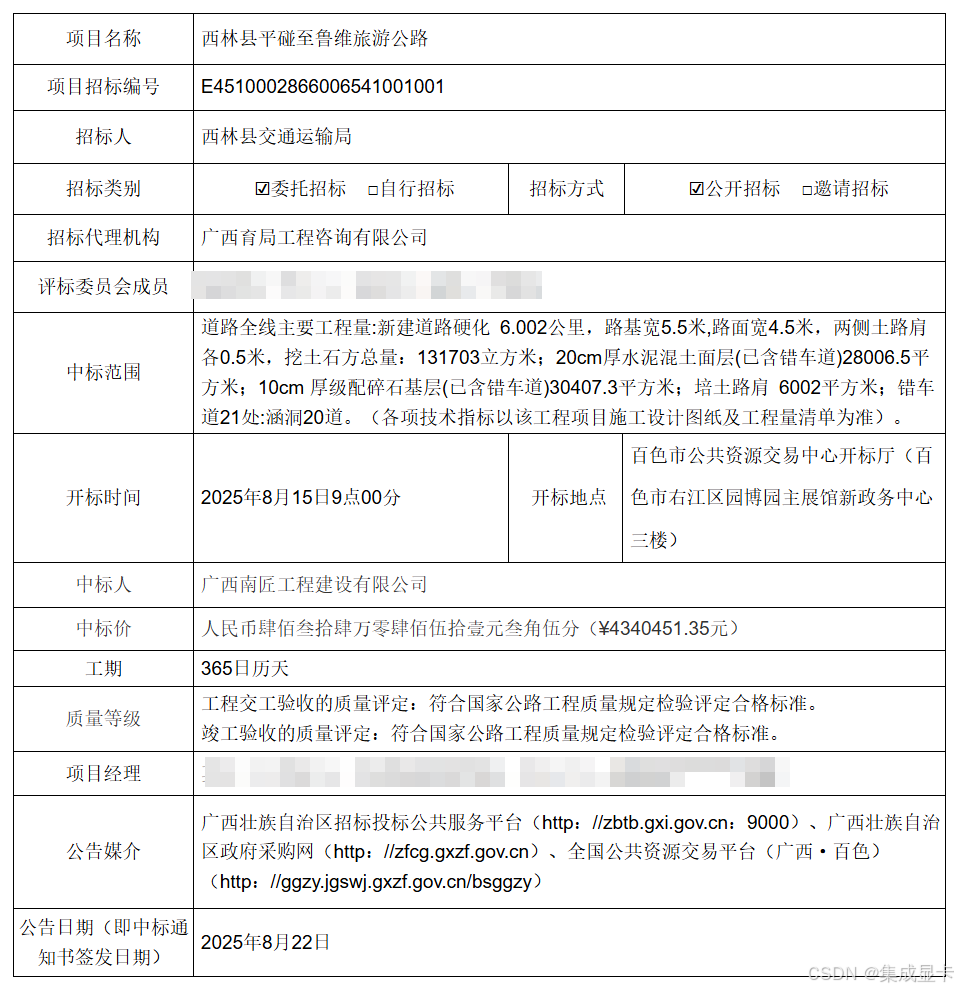
2.3.2 运行结果
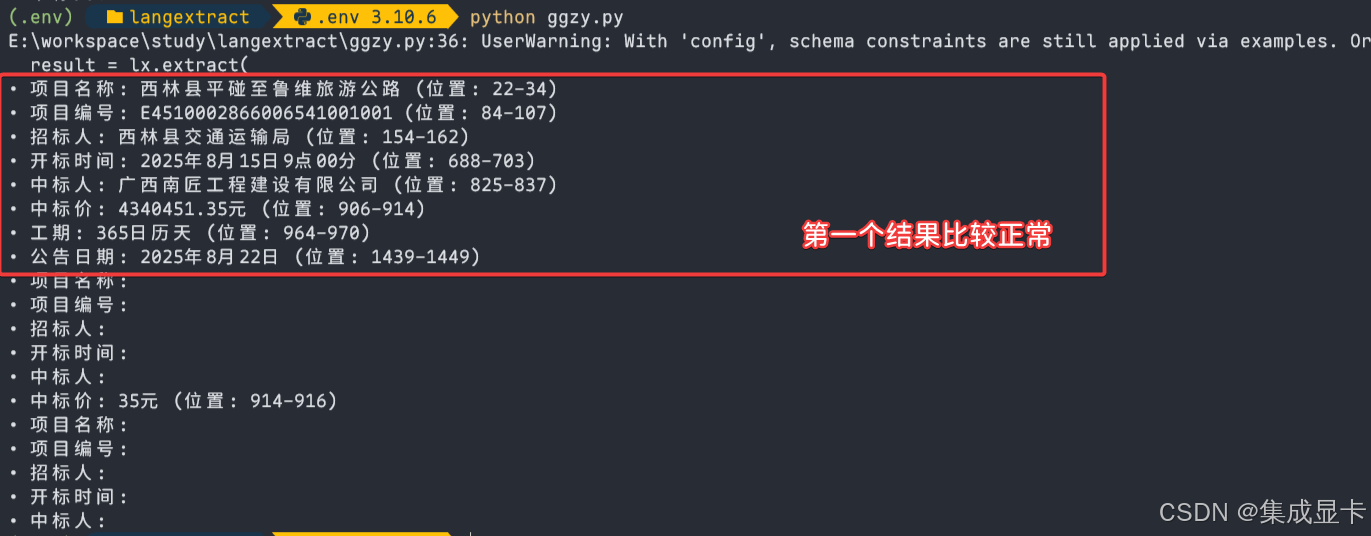
从上面的结果来看,提取的数据是准确的(耗时大概10秒),不过还多了一个结果(数据基本是空白),可以在程序中控制只要第一个结果即可😄。
借助 AI 理解自然语言,从中提取出想要的信息,是一条比专家规则更合适的路,虽然目前在时效上会久些,不过不是什么严重问题。
三、JavaScript 版本
在 github 上有一个 typescript 版本的实现:kmbro/langextract-typescript。
A TypeScript translation of the original Python LangExtract library by Google LLC. This library provides structured information extraction from text using Large Language Models (LLMs) with full TypeScript support, comprehensive visualization tools, and a powerful CLI interface.
import { extract } from "langextract"/**@type {Array<import("langextract").ExampleData>} */
const examples = [{text:"梁思成(1901年4月20日-1972年1月9日),籍贯广东新会,生于日本东京。毕生致力于中国古代建筑的研究和保护,是建筑历史学家、建筑教育家和建筑师,被誉为中国近代建筑之父。",extractions:[{ extractionClass:"姓名", extractionText:"梁思成"},{ extractionClass:"出生日期", extractionText:"1901年4月20日"},{ extractionClass:"逝世日期", extractionText:"1972年1月9日"},{ extractionClass:"出生地", extractionText:"日本东京"},{ extractionClass:"职业", extractionText:"建筑历史学家、建筑教育家、建筑师"},{ extractionClass:"荣誉", extractionText:"中国近代建筑之父"}]},{text:"林徽因(1904年6月10日-1955年4月1日),原名“徽音”,汉族,祖籍福建闽侯(今福建福州),出生于浙江杭州。为中国近现代建筑学家、文学家,清华大学建筑系教授。",extractions:[{ extractionClass:"姓名", extractionText:"林徽因" },{ extractionClass:"出生日期", extractionText:"1904年6月10日"},{ extractionClass:"逝世日期", extractionText:"1955年4月1日"},{ extractionClass:"出生地", extractionText:"浙江杭州"},{ extractionClass:"职业", extractionText:"建筑学家、文学家"},{ extractionClass:"荣誉", extractionText:""}]}
]extract("古龙(1938年6月7日一1985年9月21日),原名熊耀华,籍贯江西南昌,汉族。1938年6月7日出生于香港。武侠小说家,新派武侠小说泰斗,与金庸、梁羽生、温瑞安并称为中国武侠小说四大宗师。",{promptDescription :"从人物简要介绍中提取姓名、出生日期、逝世日期(如有)、出生地、职业、荣耀/成就",examples,modelType : 'openai',modelId : 'doubao-seed-1-6-flash-250615',baseURL : 'https://ark.cn-beijing.volces.com/api/v3',apiKey : '',temperature : 0.1,debug : true}
)
.then(result=>{console.debug(`documentId=${result.documentId}`)console.debug(result.extractions)
})
.catch(e=>console.debug(e))
很遗憾,这个代码执行后没有任何结果😔,感觉是对大模型的兼容性还不够高。

四、Rust 版本
目前我在 github 找到两个 Rust 的实现:modularflow/langextract-rust、daleione/langextract。
从文档的质量及 crates.io 下载量来看,langextract-rust 更胜一筹,所以我选择了它😎。
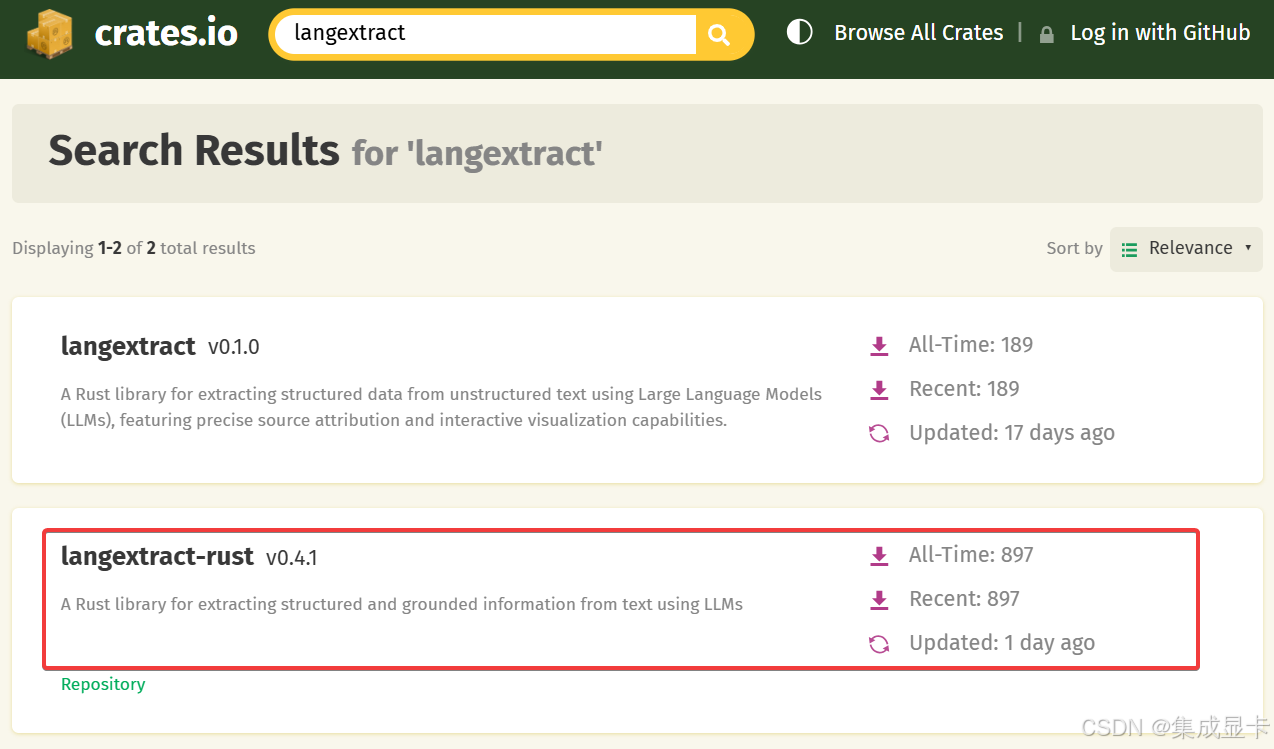
另外提一句,daleione/langextract 提交到 crates.io 的库应该是搞错了,依赖下载后是货不对板的一个示例函数(间下图),估计是作者没上传最新的版本。
4.1 程序跑不起来😔
按照文档写了一段代码,还是上面一样的人物信息识别,不出意外报错了。 报的是ConfigurationError("Custom provider inference not yet implemented"),我在 github 上提了 issue,希望能够得到解决。
4.2 成功运行🎉
经过排查,发现上述的错误是因为代码本身并没有实现Custom provider inference,

那要怎么样才能使用豆包大模型呢?
一番努力后,终于被我找到了破解之法。
use langextract_rust::{extract, ExtractConfig,data::{ExampleData, Extraction},providers::ProviderConfig,
};#[tokio::main]
async fn main()-> Result<(), Box<dyn std::error::Error>> {// 获取环境变量,不存在会返回 Errlet api_key = std::env::var("API_KEY").expect("请设置 API_KEY 环境变量");// 提取示例let examples = vec![ExampleData::new("梁思成(1901年4月20日-1972年1月9日),籍贯广东新会,生于日本东京。毕生致力于中国古代建筑的研究和保护,是建筑历史学家、建筑教育家和建筑师,被誉为中国近代建筑之父。".to_string(),vec![Extraction::new("姓名".to_string(), "梁思成".to_string()),Extraction::new("出生日期".to_string(), "1901年4月20日".to_string()),Extraction::new("逝世日期".to_string(), "1972年1月9日".to_string()),Extraction::new("出生地".to_string(), "日本东京".to_string()),Extraction::new("职业".to_string(), "建筑历史学家、建筑教育家、建筑师".to_string()),Extraction::new("荣誉".to_string(), "中国近代建筑之父".to_string())]),ExampleData::new("林徽因(1904年6月10日-1955年4月1日),原名“徽音”,汉族,祖籍福建闽侯(今福建福州),出生于浙江杭州。为中国近现代建筑学家、文学家,清华大学建筑系教授。".to_string(),vec![Extraction::new("姓名".to_string(), "林徽因".to_string()),Extraction::new("出生日期".to_string(), "1904年6月10日".to_string()),Extraction::new("逝世日期".to_string(), "1955年4月1日".to_string()),Extraction::new("出生地".to_string(), "浙江杭州".to_string()),Extraction::new("职业".to_string(), "建筑学家、文学家".to_string()),Extraction::new("荣誉".to_string(), "".to_string())])];// 配置大模型let custom_config = ProviderConfig::openai_compatible("https://ark.cn-beijing.volces.com/api/v3","doubao-seed-1-6-flash-250615",Some(api_key.clone()));let extract_config = ExtractConfig {language_model_params:{let mut params = std::collections::HashMap::new();params.insert("provider_config".to_string(), serde_json::to_value(&custom_config)?);params},debug: false,..Default::default()};let result = extract("古龙(1938年6月7日一1985年9月21日),原名熊耀华,籍贯江西南昌,汉族。1938年6月7日出生于香港。武侠小说家,新派武侠小说泰斗,与金庸、梁羽生、温瑞安并称为中国武侠小说四大宗师。",Some("从人物简要介绍中提取姓名、出生日期、逝世日期(如有)、出生地、职业、荣耀/成就"),&examples,extract_config).await?;println!("✅ Extracted {} items", result.extraction_count());// Show extractions with character positionsif let Some(extractions) = &result.extractions {for extraction in extractions {println!("• [{}] '{}' at {:?}",extraction.extraction_class,extraction.extraction_text,extraction.char_interval);}}Ok(())
}
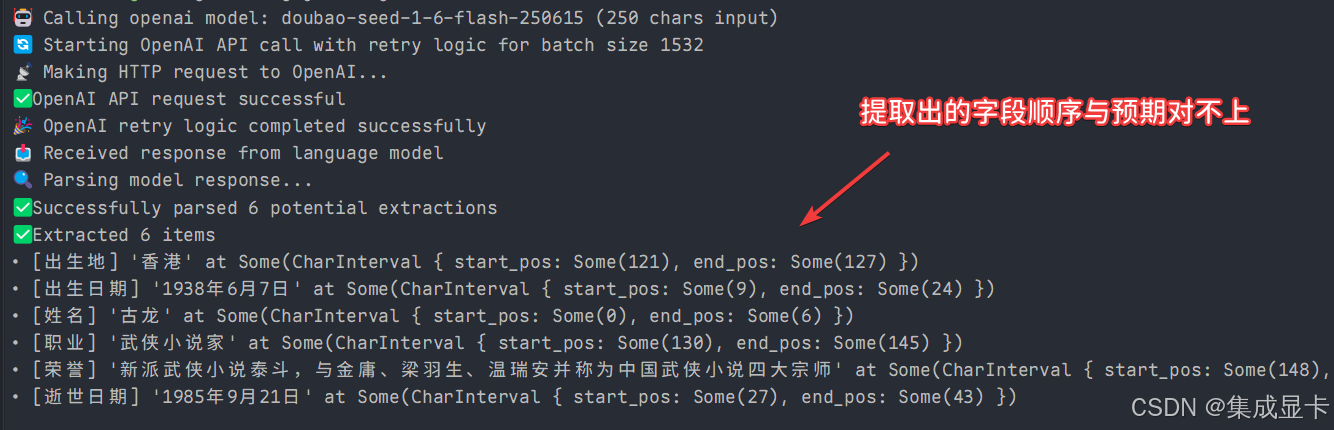
运行代码,得到以下的结果✌。个人觉得我设置了 debug=false ,应该不显示运行时日志才对,就跟 python 版本一样默默返回结果。
4.3 未来展望 🚀
我计划做一个带 GUI 的结构化信息提取程序,基于 Tauri,所以有一个能用的 rust 版本 langextract 尤为重要😄。
Java 版本
目前我还没有找到 Java 实现的版本,是不是一个机会😄?





)
)









)

)
