上一篇文章我们搭建了JVM内存结构的整体框架,知道程序计数器、虚拟机栈、本地方法栈属于“线程私有区域”——每个线程启动时会单独分配内存,线程结束后内存直接释放,无需GC参与。这三个区域看似“小众”,却是理解线程执行逻辑、排查栈溢出异常的关键,也是面试中高频被问的考点。今天我们就深入拆解这三个区域,从“作用原理”到“异常场景”,再到“实战配置”,彻底搞懂线程私有区域的底层逻辑。
一、程序计数器:线程的“执行路标”,为何是唯一不会OOM的区域?
在多线程环境中,CPU会在不同线程间频繁切换——当线程A执行到一半被暂停,切换到线程B执行,等线程A再次获得CPU时,如何知道自己该从哪行代码继续执行?答案就藏在“程序计数器”里。

1. 程序计数器的核心作用:记录执行位置
程序计数器(Program Counter Register)的本质是一块“小型内存区域”,它的唯一作用是存储当前线程正在执行的字节码指令的地址(或行号) 。具体来说,有两种执行场景:
- 当线程执行Java方法时,计数器存储的是“当前字节码指令的偏移地址”——比如
OrderService.createOrder()方法对应的字节码文件中,第10行指令的地址; - 当线程执行Native方法时(如
System.currentTimeMillis()),计数器的值会被设为“Undefined”——因为Native方法由C/C++实现,不属于Java字节码范畴,JVM无法跟踪其执行位置。
举个实际例子:假设线程A正在执行calculateSum(100)方法,执行到字节码的第20行(计算累加的关键步骤)时,CPU被切换到线程B。此时线程A的程序计数器会“记住”第20行的地址;当线程A再次获得CPU时,JVM会读取程序计数器中的地址,直接跳转到第20行继续执行,不会出现“重复执行”或“执行中断”的问题。
2. 为什么必须是“线程私有”?
这是新手最容易困惑的问题,答案其实和“线程切换”的特性直接相关:每个线程的执行路径、代码逻辑都是独立的——线程A在执行订单创建方法,线程B在执行支付回调方法,它们的字节码指令地址完全不同。如果程序计数器是“线程共享”的,那么线程切换时,计数器的值会被覆盖,导致线程恢复执行时找不到正确位置。
因此,JVM会为每个线程单独分配一块程序计数器内存,线程间的计数器值互不干扰——线程启动时创建,线程结束时销毁,全程与线程生命周期绑定,这就是“线程隔离”的底层保障之一。
3. 特殊点:唯一不会OOM的JVM内存区域
《Java虚拟机规范》明确规定:程序计数器的内存大小是“固定的”,不会随着线程执行过程动态扩展。它的内存大小取决于当前线程执行的方法——比如执行简单的getter方法,需要记录的指令地址较少,计数器占用内存就小;执行复杂的循环方法,指令地址虽多,但计数器仍能通过固定大小的内存存储(本质是地址值,占用空间有限)。
正因为内存大小固定,程序计数器永远不会出现“内存不足”的情况,也就成为了JVM中唯一不会抛出OutOfMemoryError的内存区域。这一点在面试中经常被问到,一定要记牢。
二、虚拟机栈:方法调用的“临时舞台”,栈溢出的根源在这里
如果说程序计数器是“执行路标”,那虚拟机栈就是线程执行方法的“临时舞台”——每个方法的调用、执行、返回,都对应虚拟机栈中“栈帧”的入栈、执行、出栈过程。理解虚拟机栈,就能搞懂“递归为什么会栈溢出”“局部变量存在哪里”这些实际问题。
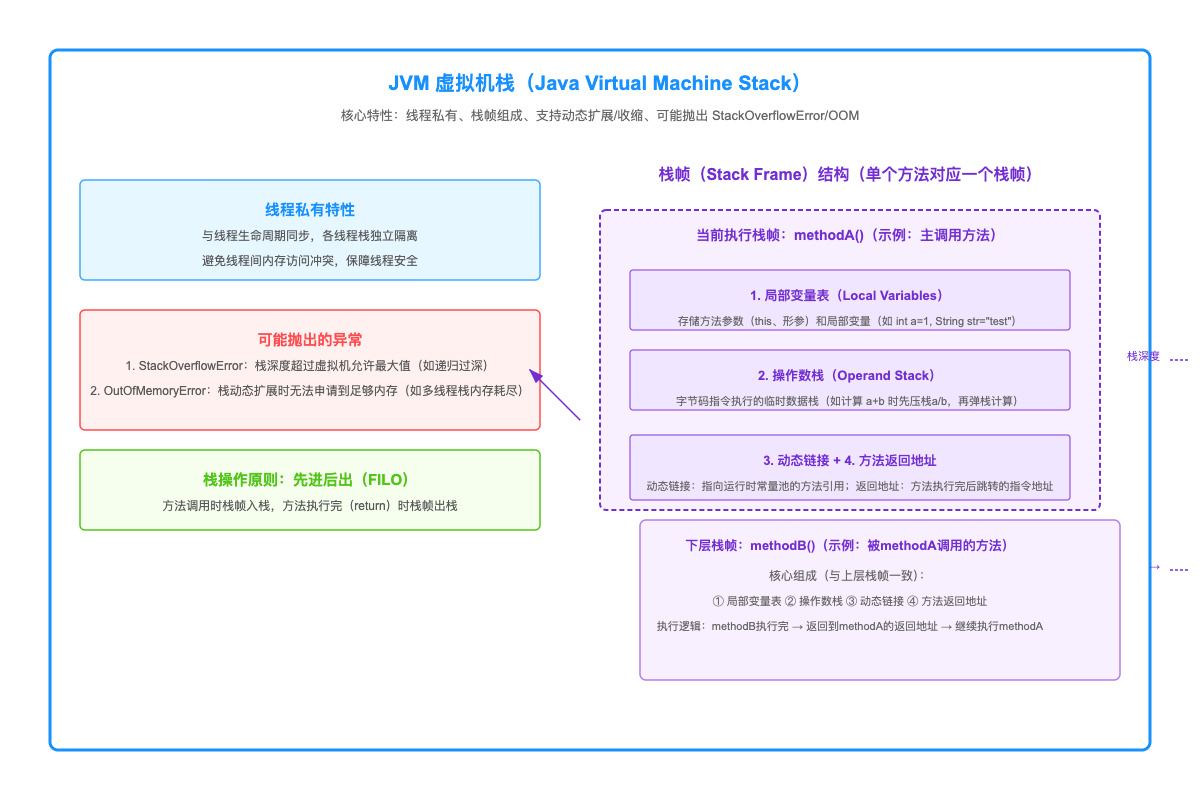
1. 虚拟机栈的核心结构:栈帧的“四大部分”
虚拟机栈(Java Virtual Machine Stack)的本质是“栈式结构的内存区域”,其中存储的基本单位是“栈帧”(Stack Frame)。每个Java方法被调用时,JVM会创建一个对应的栈帧,并入栈;当方法执行完成(正常返回或抛出异常),栈帧会出栈并释放内存。
一个栈帧包含四大部分,我们用“调用UserService.getUserById(100)方法”为例,拆解每部分的作用:
(1)局部变量表:存储方法的局部变量
局部变量表是栈帧中最核心的部分之一,它存储方法的参数、局部变量,以及方法执行过程中创建的临时变量。比如getUserById(int id)方法中,参数id(值为100)、方法内定义的User user = null变量,都会存在局部变量表中。
局部变量表的大小在“编译期”就已确定——JVM会根据方法的参数和局部变量数量,计算出所需的“变量槽”(Slot)数量,并存入字节码文件中。比如一个int类型的变量占1个Slot,long、double类型占2个Slot,对象引用(如User user)也占1个Slot(存储的是对象在堆中的地址)。<














等级考试试卷-实操题(2021年12月))




