整体思路:
1.使用开源学堂在线编程环境开发MiniOB编译环境
2.使用vscode进行代码调试和开发以及上传到仓库
MiniOB源码:https://github.com/oceanbase/miniob
MiniOB文档:MiniOB 介绍 - MiniOB
数据库大赛官网:OceanBase 社区
训练营:OceanBase 社区
一、新建github仓库以及将仓库内代码CLONE到本地
前提条件:已注册 Gitee 账号,Gitee 官网地址:https://gitee.com。
创建私有仓库:
登录 Gitee 平台,选择新建仓库。
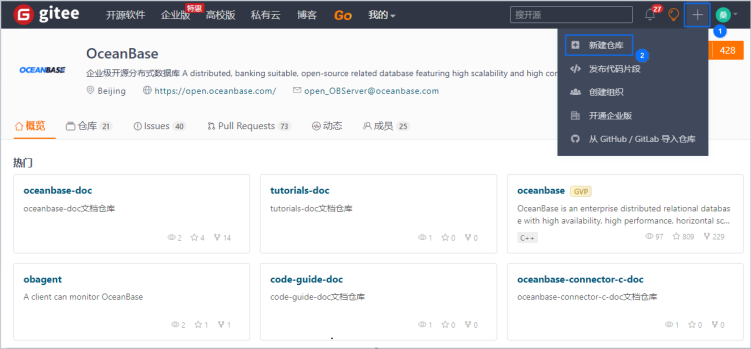
输入仓库信息,单击 创建。设置为私有仓库后其他人无法查看到你的代码。
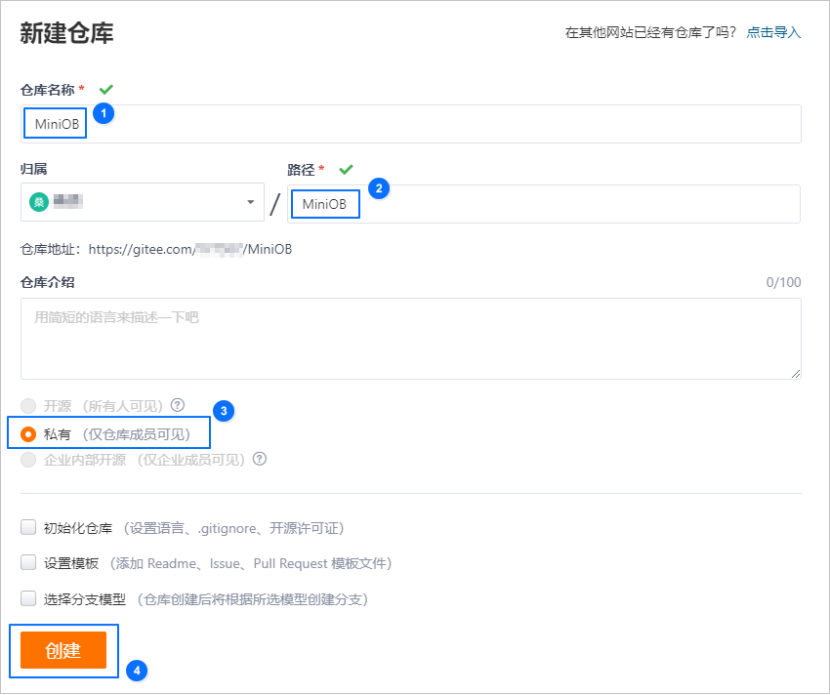
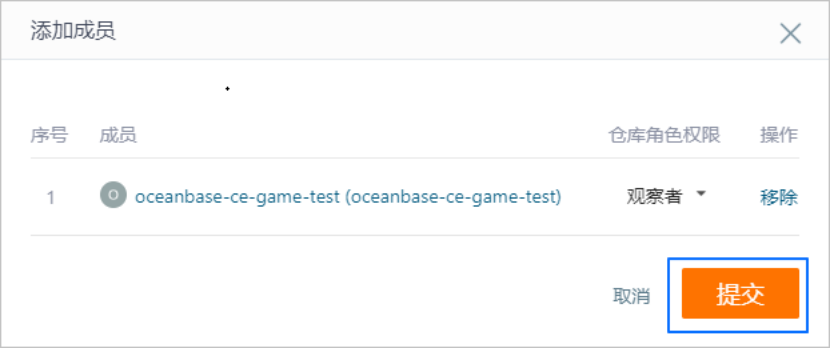
赋权官方测试账号
对于私有仓库,默认情况下其他人看不到,同样 OceanBase 测试后台也无法拉取到代码,这时想要提交测试,需要先给 OceanBase 的官方测试账号增加一个权限。
官方测试账号为:oceanbase-ce-game-test
选择管理>仓库成员管理>观察者。
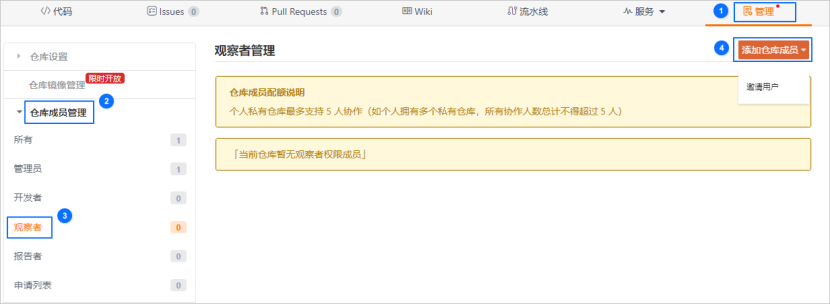
选择直接添加,搜索官方测试账号。
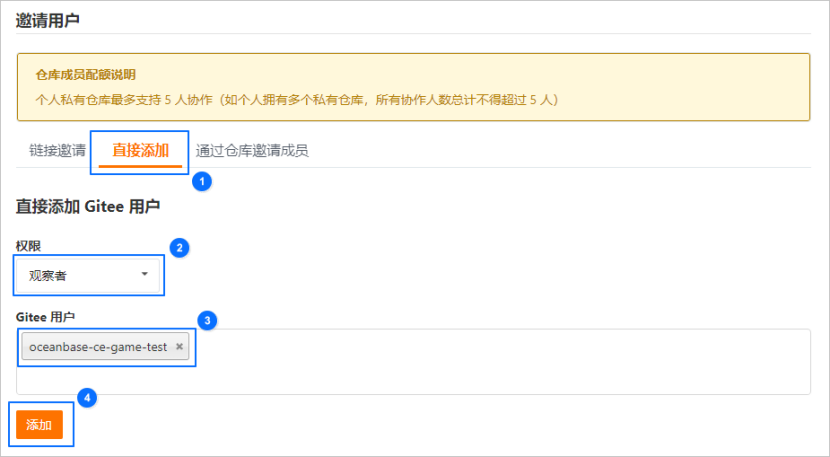
添加完成后,单击 提交。
上述完成了一系列新建仓库的操作,接下来建立本地项目与远程仓储的同步。
第一步新建文件夹,我此时新建的文件夹为MINIOB。
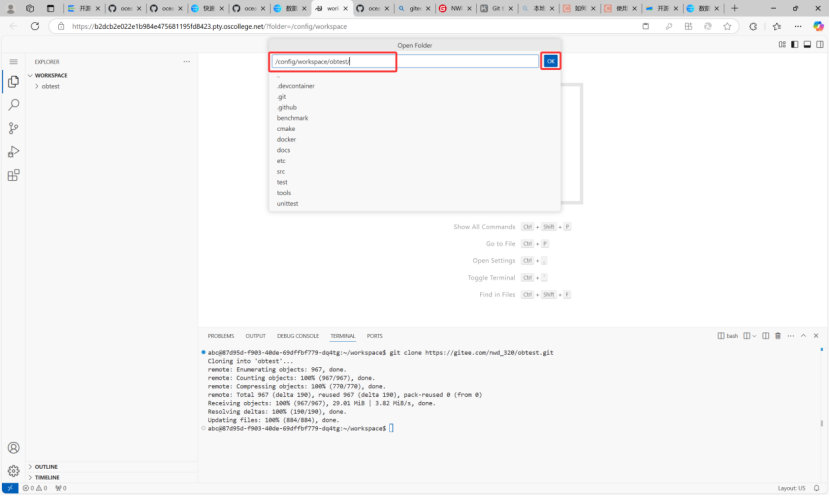
第二步打开所创建的文件夹。CLONE仓库到新建文件夹下(此时建立连接成功)
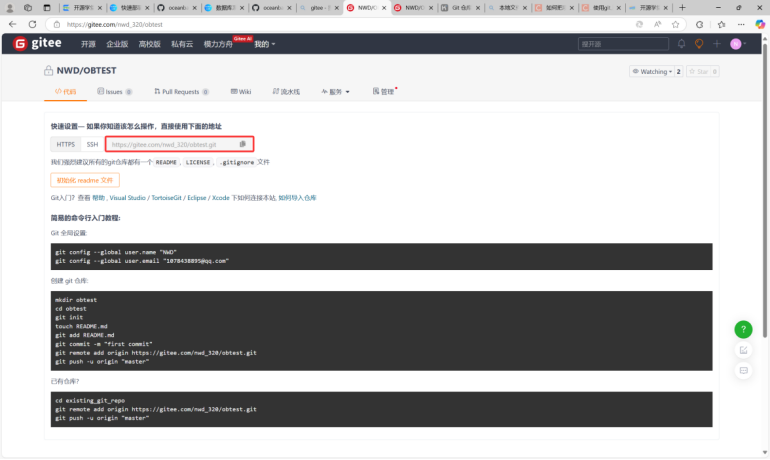
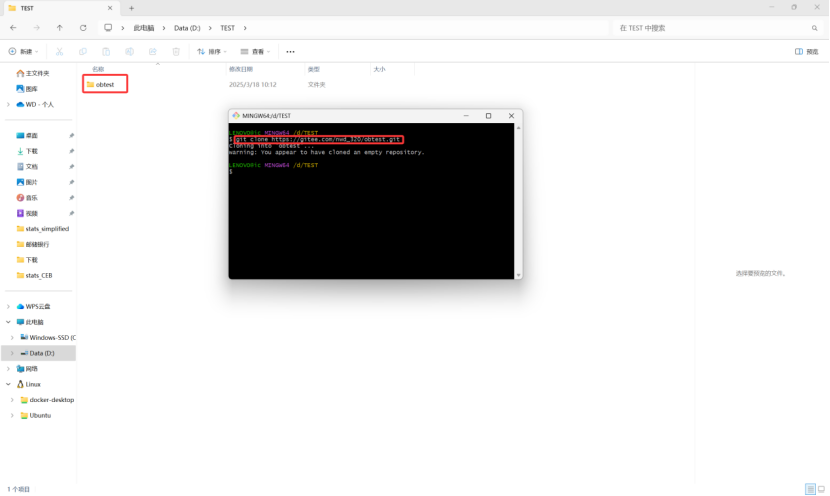
接下来打开obtest文件夹,获取miniob源码(获取地址:https://github.com/oceanbase/miniob),解压后粘贴到obtest文件夹下:
# 进入到obtest目录,删除.git目录,清除已有的git信息
cd obtest
rm -rf .git
# 重新初始化 git 信息,并将代码提交到自己的仓库
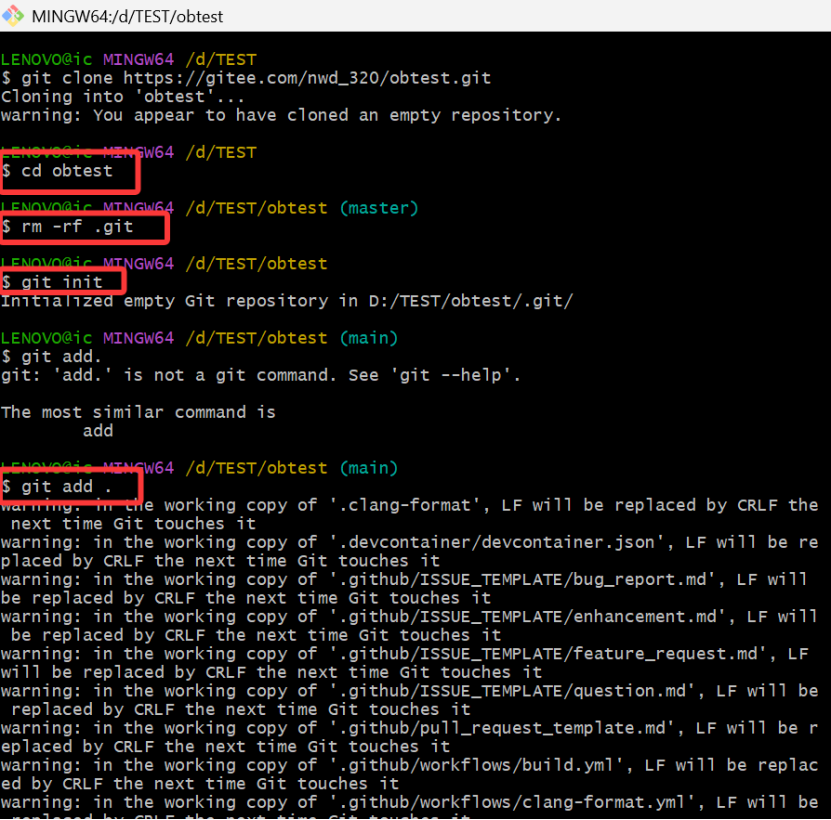
git init
git add .
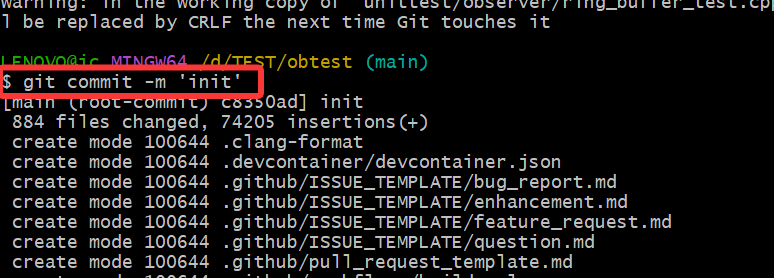
git commit -m 'init' # 提交所有代码到本地仓库
# 将代码推送到远程仓库
git remote add origin https://gitee.com/nwd_320/obtest.git # 注意替换命令中的信息为自己的库信息
git branch -M main
git push -u origin main
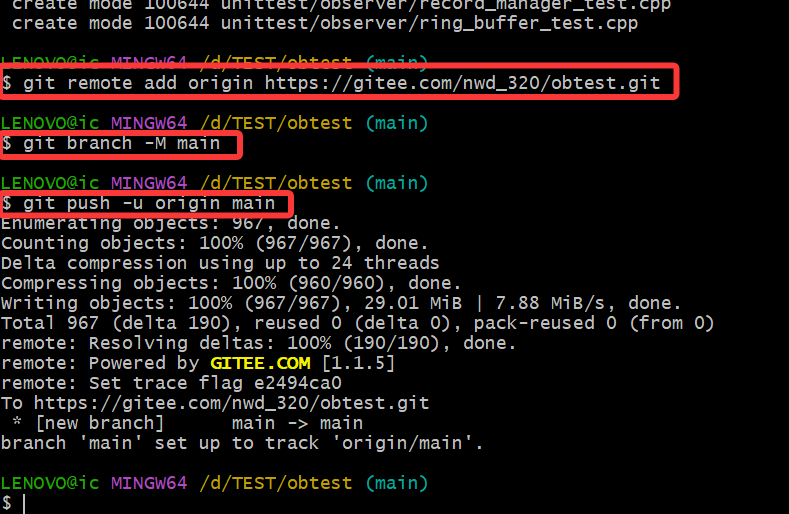
打开gittee新建的仓库,如下图所示:
二、搭建开发环境
访问开源学堂网址:云燕实验室
进入课程学习界面后,大家可以在左侧课程目录中找到对应的实验,然后点击对应的目录项,查看对应的实验的文档。
点击上方启动环境即可启动开发环境,每次实验的开发环境中的内容是会持久化保存在云端。
点击实验工具中的vscode来进行开发,将项目在浏览器中打开。
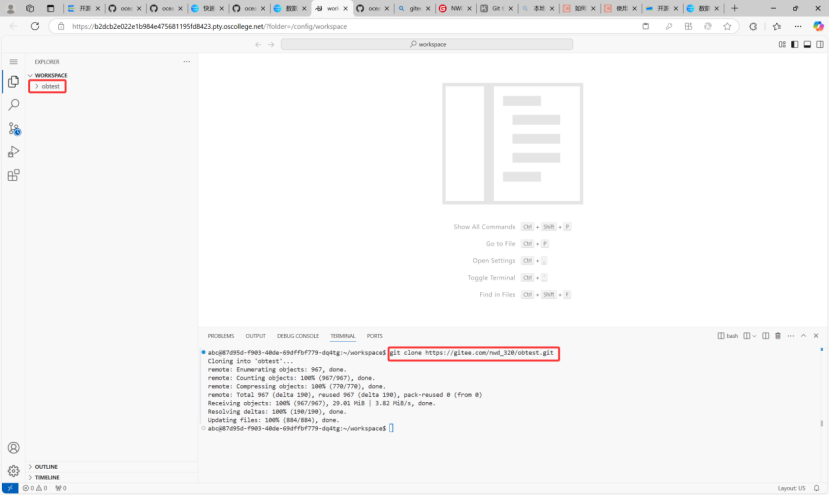
输入git clone https://gitee.com/nwd_320/obtest.git# 注意替换命令中的信息
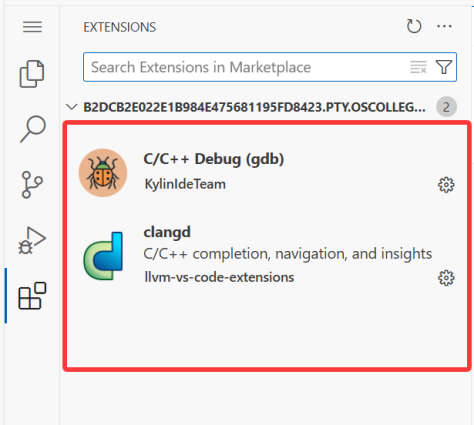
安装相应的插件:
新建两个空文档(launch.json和tasks.json)
将下列分别粘入文件中,记得保存:
launch.json:
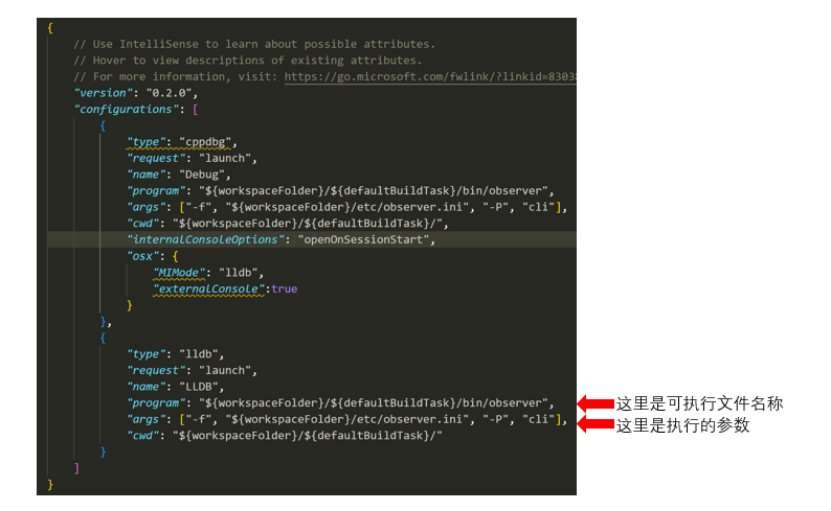
{// Use IntelliSense to learn about possible attributes.// Hover to view descriptions of existing attributes.// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387"version": "0.2.0","configurations": [{"type": "cppdbg","request": "launch","name": "Debug","program": "${workspaceFolder}/${defaultBuildTask}/bin/observer","args": ["-f", "${workspaceFolder}/etc/observer.ini", "-P", "cli"],"cwd": "${workspaceFolder}/${defaultBuildTask}/","internalConsoleOptions": "openOnSessionStart","osx": {"MIMode": "lldb","externalConsole":true}},{"type": "lldb","request": "launch","name": "LLDB","program": "${workspaceFolder}/${defaultBuildTask}/bin/observer","args": ["-f", "${workspaceFolder}/etc/observer.ini", "-P", "cli"],"cwd": "${workspaceFolder}/${defaultBuildTask}/"}]}Tasks.json:
{// See https://go.microsoft.com/fwlink/?LinkId=733558// for the documentation about the tasks.json format"version": "2.0.0","tasks": [{"label": "init","type": "shell","command": "sudo -E env PATH=$PATH bash ${workspaceFolder}/build.sh init"},{"label": "build_debug","type": "shell","command": "bash build.sh debug","problemMatcher": [],"group": {"kind": "build","isDefault": true}},{"label": "build_release","type": "shell","command": "bash build.sh release"},{"label": "gen_parser","type": "shell","command": "cd ${workspaceFolder}/src/observer/sql/parser && bash gen_parser.sh"}]}
如下图所示(这里需要等待一会儿):
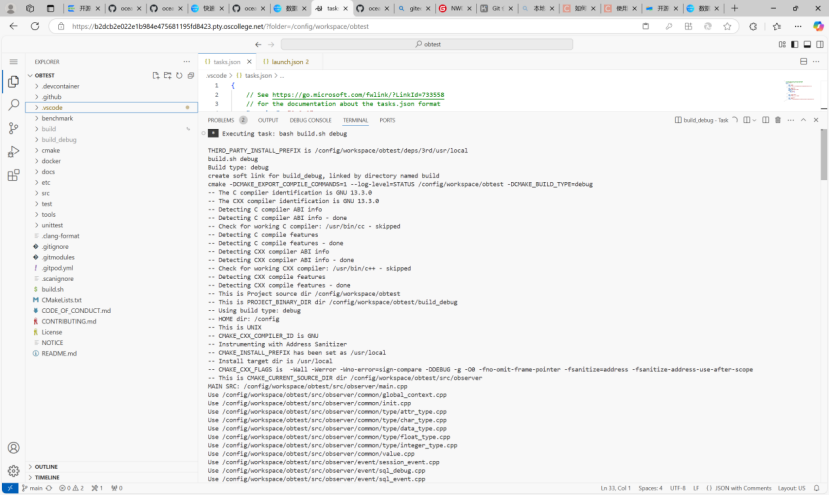
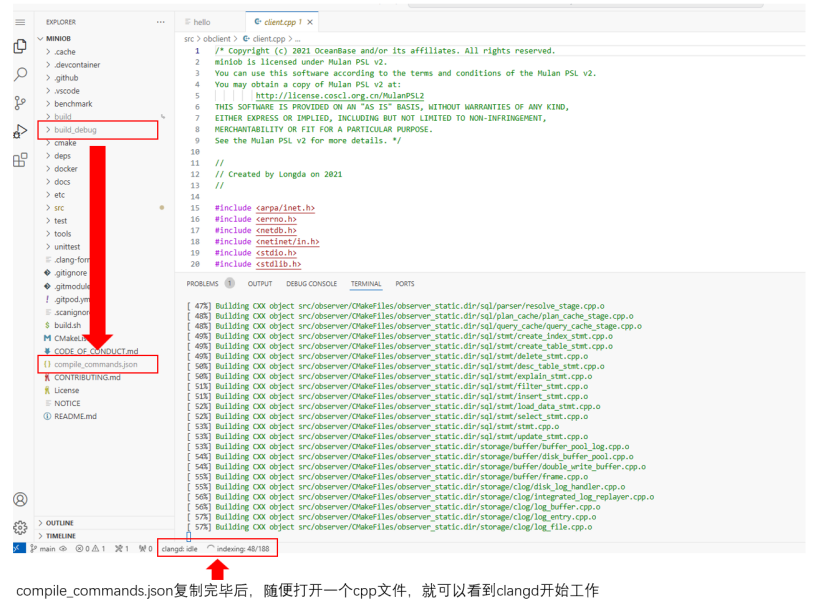
构建完毕后,将build_debug中的compile_commands.json文件复制到miniob目录中,随便打开一个cpp文件,就可以看到clangd开始工作。
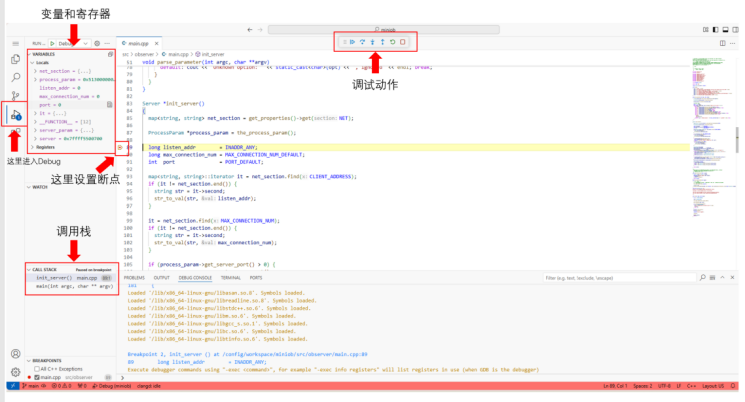
用F5进行调试,关于如何vscode如何调试,可以参考相关的资料:cpp-debug。修改launch.json文件中program和args来调试不同的可执行文件。
打开命令行输入如下信息:
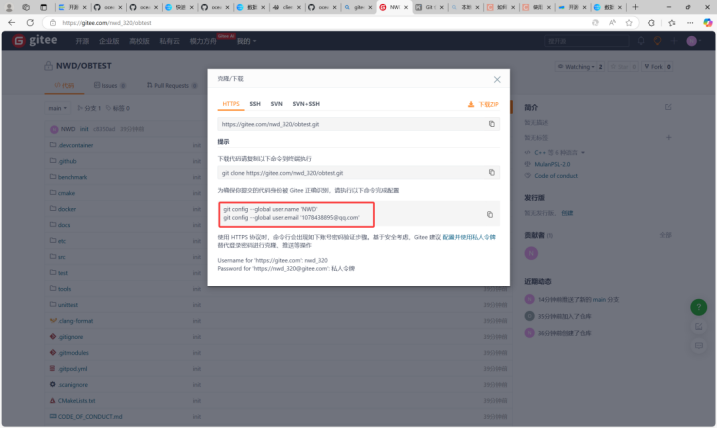
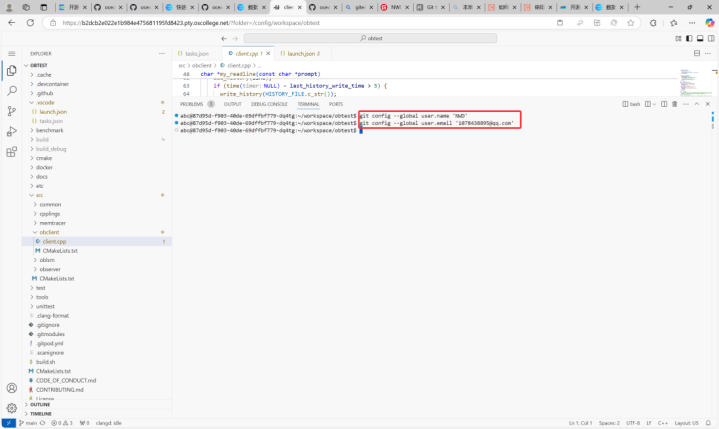
接下来提交到自己的gittee仓库中:
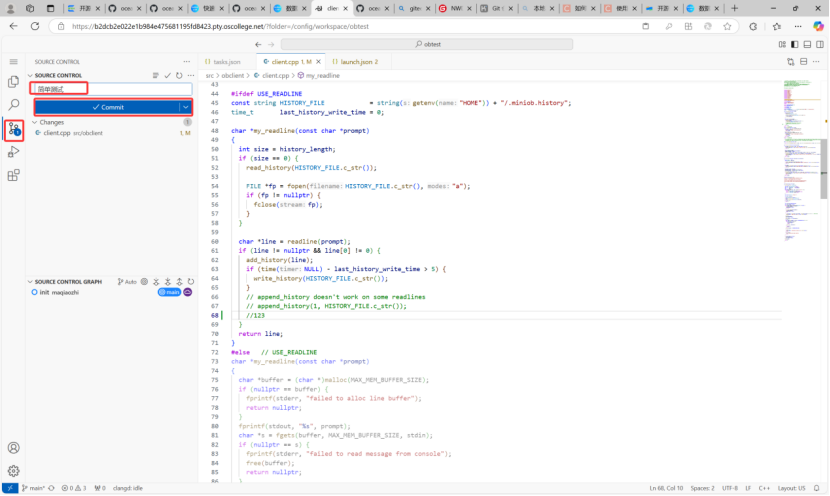
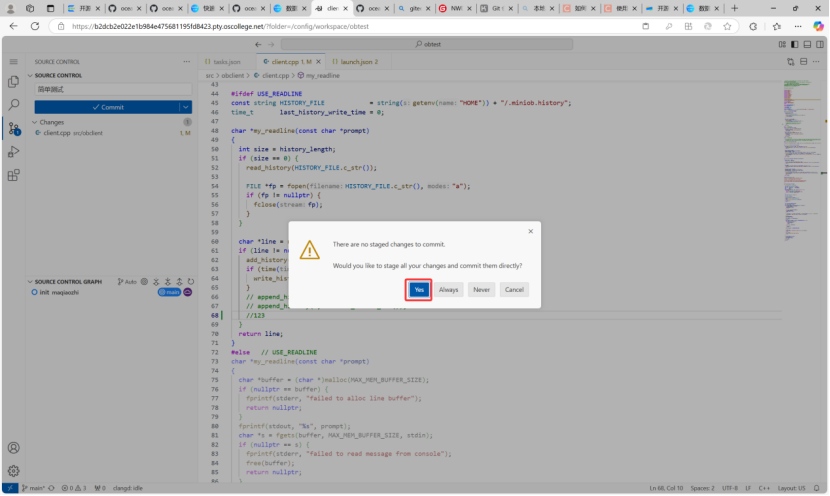
注:首先打开服务器,再去打开客户端。
1.在MiniOB代码目录下,运行下面命令来编译MiniOB
bash build.sh debug
2.进入build_debug目录
cd build_debug/
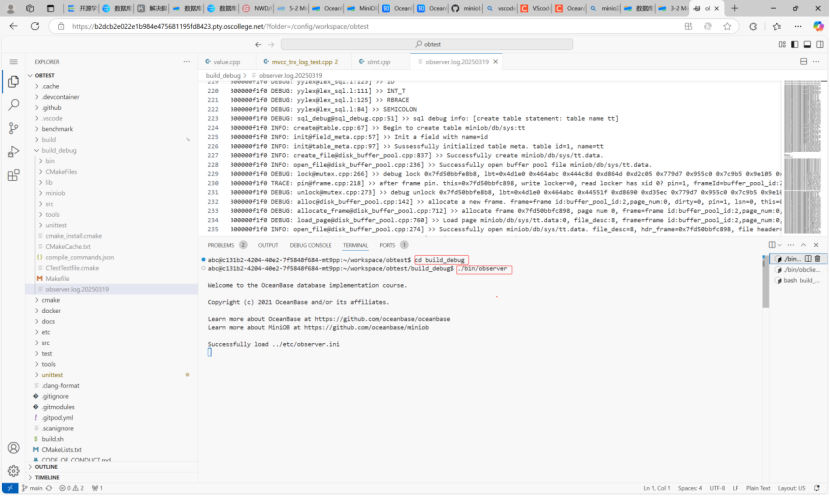
3.在MiniOB代码目录下,运行下面命令来启动 MiniOB
./bin/observer
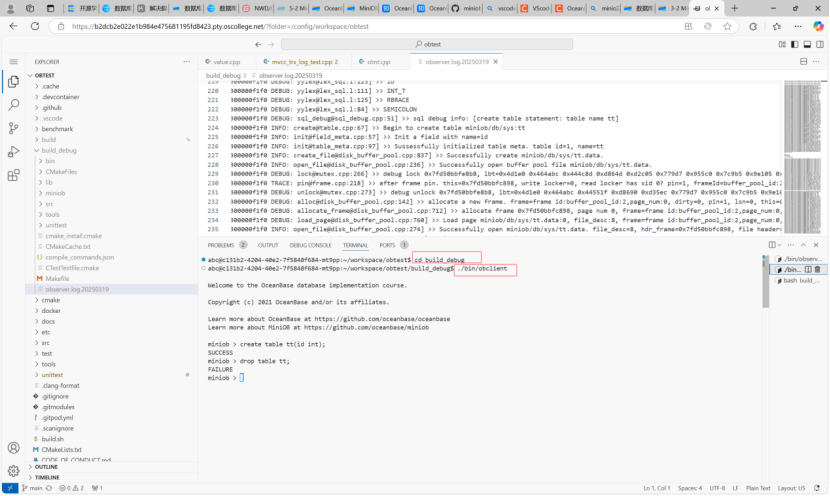
4.打开另一个终端,进入build_debug目录,运行下面命令来启动MiniOB client
./bin/obclient
三、miniob训练营提交(basic测试)
进入miniob训练营官网,选择basic。
点击进入
接下来到官网提交代码,首先找到仓库地址
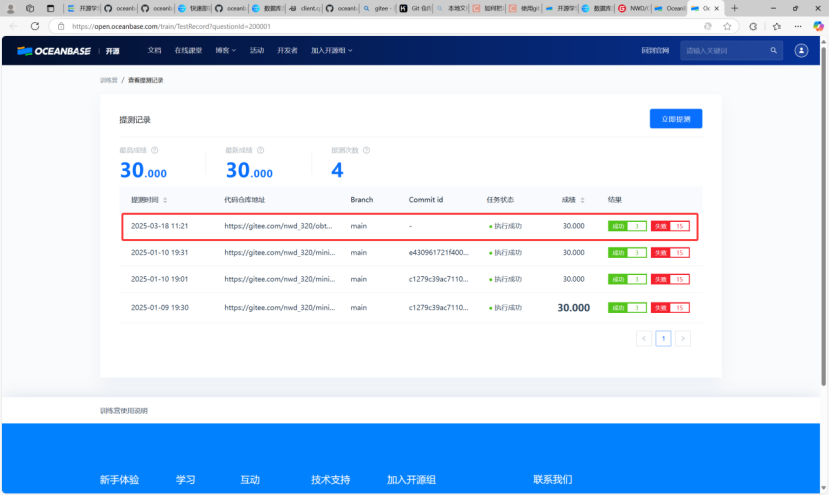
我进行简单提交如图所示:
四、搭建开发环境MiniOB框架
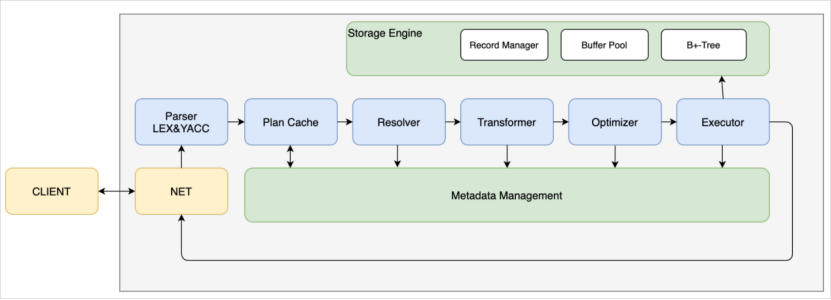
1.如图所示左边是客户端,右边是服务端。客户端发起命令,通过网络通讯和服务端的网络模块去通讯收发命令。服务端的网络模块收到SQL(字符串形式存储)请求后,交给词法(lex_sql.l)/语法(yacc_sql.y)解析模块(Parser模块)(它的代码在src/observer/sql/parser中。),经过词法解析和语法解析模块将SQL请求字符串转换成带有语法结构信息的内存数据结构(语法树)。
2.再转发给下一个执行缓存模块Plan Cache,执行计划缓存模块会将该SQL第一次生成的执行计划缓存在内存中,后续的执行可以反复执行这个计划,避免了重复查询优化的过程。如果命中,直接将查询计划交给 Executor进行执行。
3.若Plan Cache未命中,直接再转发给Resolver模块。Resolver模块会将判断模块解析出来的语法树,进一步细化后转换成真实的对象(STMT)。比如查询一张表,会把表名转换成具体的表对象;如果是查询某个字段,会转换成对应的字段名;如果是select *,会把 * 转换成对应表的各个字段。除此之外还会做一些预检,比如查询一张不存在的表,就会提前返回错误。
4.把处理的结果给到Transformer(逻辑优化阶段)。分析用户 SQL 的语义,并根据内部的规则或代价模型,将用户SQL改写为与之等价的其他形式,并将其提供给后续的优化器做进一步的优化。Transformer的工作方式是在原Statement Tree上做等价变换,变换的结果仍然是一棵Statement Tree。
5.经过这个规则转换(Transformer)后,交给优化模块(Optimizer)。优化模块会根据一些条件找到更好的查询路径。比如查询数据,需要先判断直接使用索引查询,速度更快,还是通过全表遍历查询速度更快。因为有时部分因素或条件会导致索引查询更慢,所以优化模块会做一些判断,选择较好的查询计划,再转发给下一个执行模块。
6.执行模块(Executor)(相关代码在src/observer/sql/executor中)会按照查询计划去执行,访问索引、Buffer Pool、记录管理、以及底层的模块。然后把查询的结果返回给网络模块。网络模块再通过 Socket 返回给客户端。
其中:
元数据管理(Meta Data):记录当前的数据库、表、字段和索引元数据信息;
存储引擎(Storage Engine):负责数据的存储和检索;包括:【Record Manager:组织记录一行数据在文件中如何存放。Buffer Pool:文件跟内存交互的关键组件。B+Tree:索引结构。】
五、Drop-table实验
删除表。清除表相关的资源。
注意:要删除所有与表关联的数据,不仅仅是在create table时创建的资源,还包括索引等数据。
我们可以根据create table的方式模仿实现Drop-table。可以使用日志文件辅助发现问题在哪。如下图所示。可以发现创建statement失败,是在Resolver模块中。无需从Parser模块开始修改。
实现具体细节可参考:
https://gitee.com/nwd_320/obtest/commit/9dca2fef06f1e5c76d579aa637664989f38fa86b
测试集:
test/case/test/primary-drop-table.test
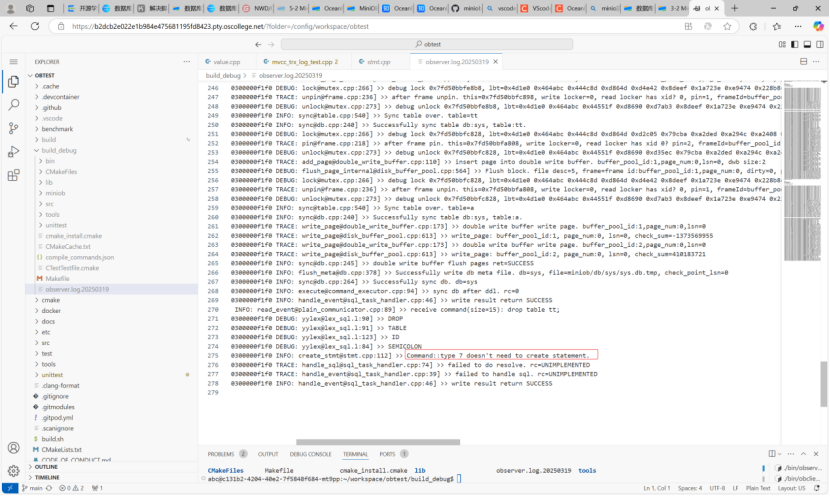
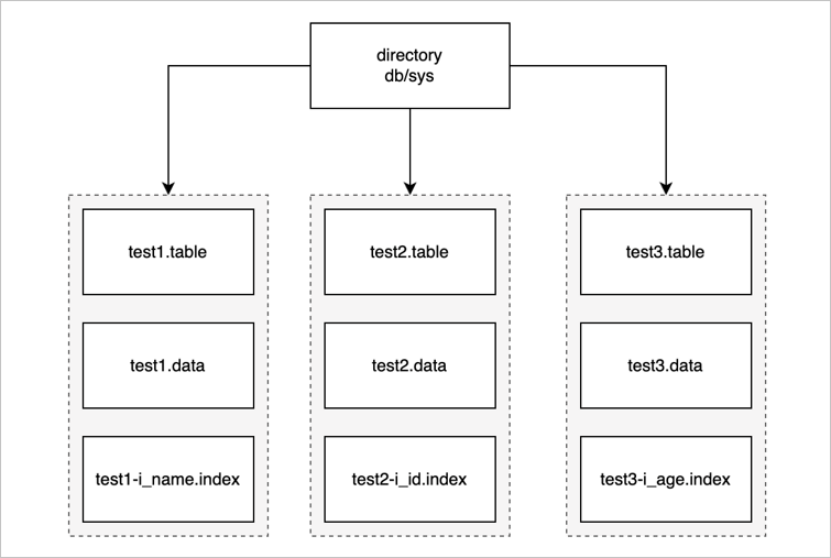
Create table就是新建表,比如在create table t时,会新建一个t.table文件,同时为了存储数据也会新建一个t.data文件存储下来。同时创建索引的时候,也会创建记录索引数据的文件。
因此删除表,就需要删除t.table文件、t.data文件和关联的索引文件。同时由于buffer pool的存在,在新建表和插入数据的时候,会写入buffer pool缓存。所以drop table,不仅需要删除文件,也需要清空buffer pool,防止在数据没落盘的时候,再建立同名表,仍然可以查询到数据。如果建立了索引,比如t_id on t(id),那么也会新建一个t_id.index文件,也需要删除这个文件。这些东西全部清空,那么就完成了drop table。存储方式如下图所示。
(1)新增SQL类型只需添加对应分支和Stmt子类(Resolver模块)
在src/observer/sql/stmt/stmt.cpp添加drop_table相关分支
在src/observer/sql/stmt/目录下新增drop_table_stmt.cpp(模仿create_table_stmt.cpp)
在src/observer/sql/stmt/目录下新增drop_table_stmt.h(模仿create_table_stmt.h)
(2)增加drop_table执行器(Executor模块)
在src/observer/sql/executor/command_executor.cpp添加drop_table相关分支
在src/observer/sql/executor/目录下新建drop_table_executor.cpp(同上)
在src/observer/sql/executor/目录下新建drop_table_executor.h(同上)
(3)找到对应的Db对象,并且实现表对象的逻辑删除
在src/observer/storage/db/db.cpp添加drop_table函数
在src/observer/storage/db/db.h添加drop_table定义
(4)删除.table文件和.data文件,这个表对应的索引文件,以及DiskBufferPool中的相关资源:
在src/observer/storage/table/table.cpp添加drop函数(包括删除.table文件,删除.data文件以及包括调用删除索引文件以及缓存的函数)。
在src/observer/storage/table/table.h添加drop定义
在src/observer/storage/index/bplus_tree.cpp添加desdroy函数(删除索引文件)
在src/observer/storage/index/bplus_tree.h添加desdroy函数定义
在src/observer/storage/index/bplus_tree_index.cpp添加desdroy函数(删除索引)
在src/observer/storage/index/bplus_tree_index.cpp添加desdroy函数定义
在src/observer/storage/buffer/disk_buffer_pool.cpp添加remove_file()函数(删除缓存)
在src/observer/storage/buffer/disk_buffer_pool.h添加remove_file()函数定义
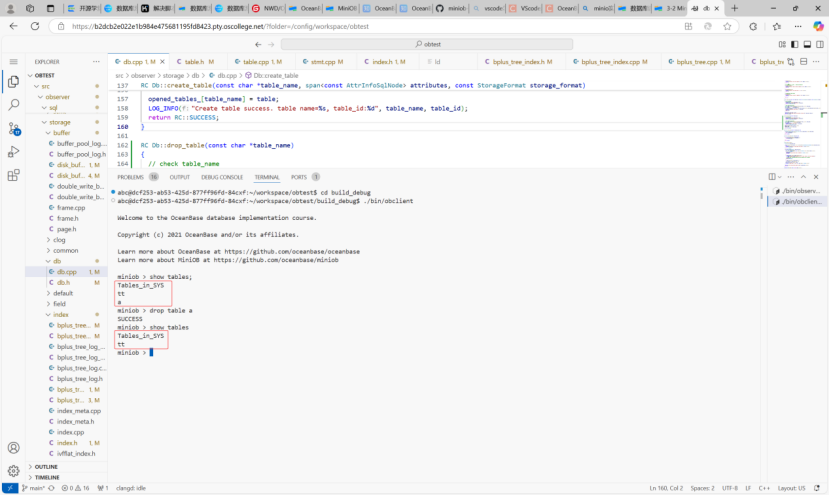
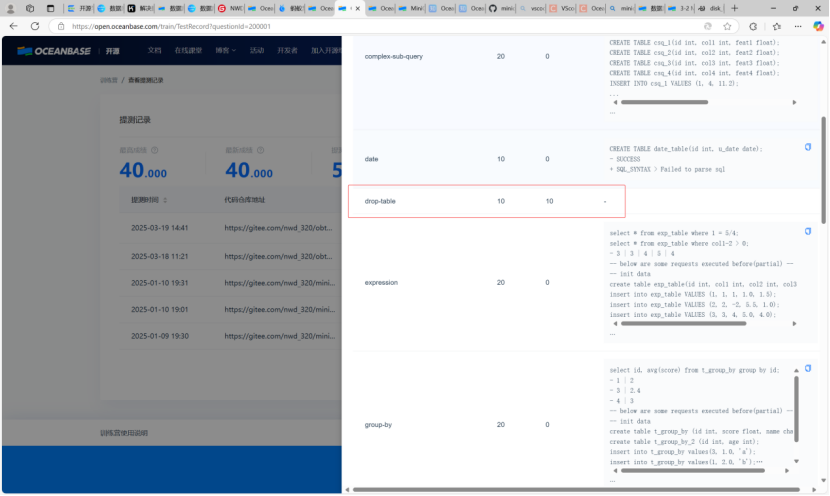
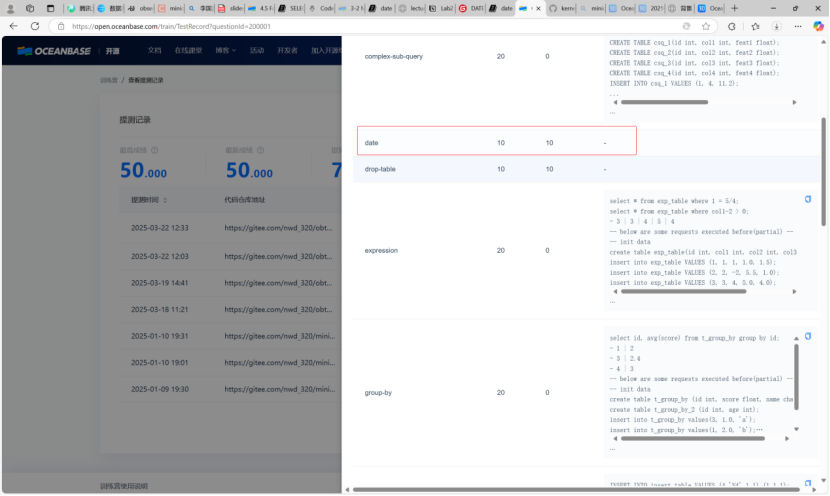
如上图所示功能实现成功。上传至私人仓库。提交至训练营。如下图所示
六、DATE实验
要求实现日期类型字段。date测试不会超过2038年2月,不会小于1970年1月1号。注意处理非法的date输入,需要返回FAILURE。
当前已经支持了int、char、float类型,在此基础上实现date类型的字段。
这道题目需要从词法解析开始,一直调整代码到执行阶段,还需要考虑DATE类型数据的存储。
注意:
- 需要考虑date字段作为索引时的处理,以及如何比较大小;
- 这里限制了日期的范围,所以简化了溢出处理的逻辑,测试数据中也删除了溢出日期,比如没有 2040-01-02;
- 需要考虑闰年。
实现具体细节可参考:
https://gitee.com/nwd_320/obtest/commit/f0e0054d743cda3f9cc8b451a832af2438f6758a
测试集:
test/case/test/primary-date.test
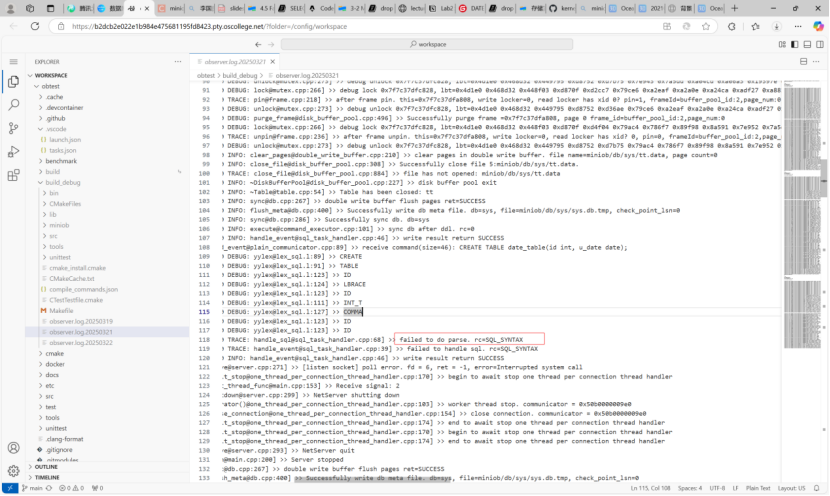
实现DATE类型可以模仿别的数据类型实现。我们采用日志文件可以发现,DATE类型从Parser模块就未定义。如下图所示。
(1)新增DATE类型,支持语法分析和词法分析(Parser模块)
在src/observer/sql/parser/lex_sql.l添加DATE类型(词法分析)
在src/observer/sql/parser/yacc_sql.y添加DATE类型(语法分析)
注意:
此时在src/observer/sql/parser/目录下,执行以下命令:
./gen_parser.sh
将会生成词法分析代码 lex_sql.h 和 lex_sql.cpp,语法分析代码 yacc_sql.hpp 和 yacc_sql.cpp。
由于当前没有把lex_sql.l和yacc_sql.y加入CMakefile.txt中,所以修改这两个文件后,需要手动生成c代码,然后再执行编译。
(2)元数据管理的修改
在src/observer/common/type/attr_type.cpp添加date类型
在src/observer/common/type/attr_type.h添加date类型
在src/observer/common/type/date_type.cpp目录下新建date_type.cpp(模仿现有类型)
在src/observer/common/type/date_type.h目录下新建date_type.cpp(模仿现有类型)
在src/observer/common/type/data_type.cpp添加DATE实例化对象(模仿现有类型)
在src/observer/common/type/char_type.cpp添加DATE类型转换
在src/observer/common/value.h添加DATE类型标识(模仿现有类型)
在src/observer/common/value.cpp添加DATE类型(模仿现有类型)
(3)Date的合法性判断
在src/common/time/datetime.cpp添加判断DATE合法性函数
在src/common/time/datetime.h添加判断DATE合法性函数定义
功能实现成功。上传至私人仓库。提交至训练营。如下图所示


一个博客带你了解所有问题)






 开发环境搭建)
)



![[系统架构设计师]大数据架构设计理论与实践(十九)](http://pic.xiahunao.cn/[系统架构设计师]大数据架构设计理论与实践(十九))

)


