写在前面
在前两个章节初步使用了SlowFast,使用的都是官方给出的数据集。
附上链接:
SlowFast使用指南(一)——demo运行-CSDN博客
SlowFast使用指南(二)——训练ava数据集-CSDN博客
本文尝试了使用自己的数据集进行训练,整个训练过程十分不易,整个过程最难的便在数据集的准备,下面附上整个过程。
数据集准备
视频准备
首先需要准备了训练使用到的两个视频,和 SlowFast使用指南(二)一样一个视频用于训练,一个视频用于验证。
视频裁剪
准备完成后,如果视频过长,需要对视频进行裁剪。本文使用到的两个视频均只有10秒左右,故没有进行裁剪。
视频抽帧
裁剪完成后,需要再对视频进行抽帧处理,抽帧分为两种方式
-
1秒1帧:用来标注
#切割图片,每秒1帧
IN_DATA_DIR="./videos"
OUT_DATA_DIR="./labels"if [[ ! -d "${OUT_DATA_DIR}" ]]; thenecho "${OUT_DATA_DIR} doesn't exist. Creating it.";mkdir -p ${OUT_DATA_DIR}
fifor video in $(ls -A1 -U ${IN_DATA_DIR}/*)
dovideo_name=${video##*/}if [[ $video_name = *".webm" ]]; thenvideo_name=${video_name::-5}elsevideo_name=${video_name::-4}fiout_video_dir=${OUT_DATA_DIR}/${video_name}/mkdir -p "${out_video_dir}"out_name="${out_video_dir}/${video_name}_%06d.jpg"ffmpeg -i "${video}" -r 1 -q:v 1 "${out_name}"
done抽1帧完成的效果如下
- 1秒30帧:用于训练(因为slowfast在slow流里1秒会采集到15帧,在fast流里1秒会采集到2帧)
#切割图片,每秒30帧
IN_DATA_DIR="./videos"
OUT_DATA_DIR="./frames"if [[ ! -d "${OUT_DATA_DIR}" ]]; thenecho "${OUT_DATA_DIR} doesn't exist. Creating it.";mkdir -p ${OUT_DATA_DIR}
fifor video in $(ls -A1 -U ${IN_DATA_DIR}/*)
dovideo_name=${video##*/}if [[ $video_name = *".webm" ]]; thenvideo_name=${video_name::-5}elsevideo_name=${video_name::-4}fiout_video_dir=${OUT_DATA_DIR}/${video_name}/mkdir -p "${out_video_dir}"out_name="${out_video_dir}/${video_name}_%06d.jpg"ffmpeg -i "${video}" -r 30 -q:v 1 "${out_name}"
done抽30帧完成的效果如下

图片标注
本文采用的是 VGG Image Annotator 进行图片标注的,点击链接进入后。
- 导入图片
- 创建Attributes

- 画框标注(这里行为的编号,建议从1开始)

- 导出标注csv文件
本文由于图片数量较少,采用的是手动标注。如果图片数量较多,建议自动标注。最终得到如下结果。
via转ava
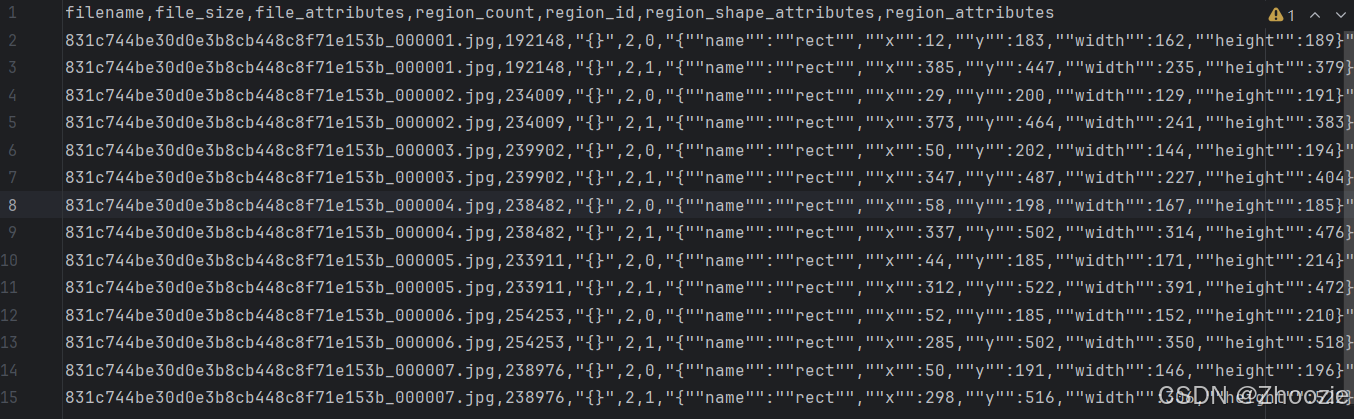
导出的csv格式明显与slowfast所需要的csv格式不相匹配,需要对其进行转换。
import csv# 输入输出文件
via_csv = "via_project_27Aug2025_14h55m_csv.csv"
ava_csv = "ava_val_v2.2.csv"# 图像宽高(根据你的实际视频分辨率填写)
IMG_WIDTH = 1080
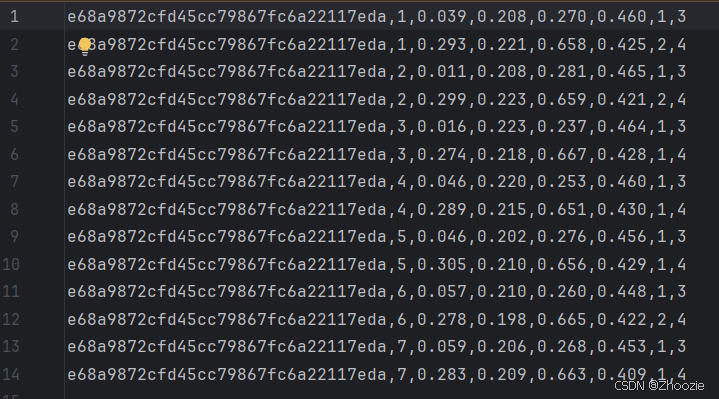
IMG_HEIGHT = 1920def via_to_ava(via_csv, ava_csv, img_w=IMG_WIDTH, img_h=IMG_HEIGHT):with open(via_csv, newline='') as fin, open(ava_csv, 'w', newline='') as fout:reader = csv.DictReader(fin)writer = csv.writer(fout)for row in reader:filename = row['filename']video_id = filename.split('_')[0]frame_str = filename.split('_')[1].split('.')[0]frame_sec = int(frame_str.lstrip('0'))# 每30帧为1秒# 解析 region_shape_attributesshape = eval(row['region_shape_attributes'])x, y, w, h = shape['x'], shape['y'], shape['width'], shape['height']# 归一化坐标x1 = x / img_wy1 = y / img_hx2 = (x + w) / img_wy2 = (y + h) / img_h# 解析 actionaction = eval(row['region_attributes'])['action']action_id = int(action)person_id = eval(row['region_attributes'])['id']person_id = int(person_id)# AVA 格式:video_id, frame_sec, x1, y1, x2, y2, action_id, person_idwriter.writerow([video_id, frame_sec, f"{x1:.3f}", f"{y1:.3f}",f"{x2:.3f}", f"{y2:.3f}", action_id, person_id])via_to_ava(via_csv, ava_csv)其中via_csv、ava_csv表示输入路径和输出路径,需要根据实际位置进行修改。IMG_WIDTH 和IMG_HEIGHT 表示图片分辨率,也需要根据实际情况修改。最后得到如下结果。
生成其他配置文件
ava_action_list_v2.2_for_activitynet_2019.pbtxt
item {name: "normal"id: 1
}
item {name: "abnormal"id: 2
}此为你要识别的行为类别,本文识别了两种类别正常和不正常
frame_lists
frame_lists下的文件使用1秒抽30帧的图片。
import os
from typing import List, Dictdef build_vid_map(frames_root: str) -> Dict[str, int]:"""返回 目录名 → video_id 的字典序映射"""dirs = sorted([d for d in os.listdir(frames_root)if os.path.isdir(os.path.join(frames_root, d))])return {d: idx for idx, d in enumerate(dirs)}def generate_val_csv(dirs: List[str],frames_root: str = '../frames',out_csv: str = 'frame_lists/val.csv') -> None:"""仅针对给定目录列表生成 val.csv:param dirs: 目录名列表,顺序即 video_id:param frames_root: 帧根目录:param out_csv: 输出文件"""vid_map = build_vid_map(frames_root)os.makedirs(os.path.dirname(out_csv), exist_ok=True)with open(out_csv, 'w') as f:f.write('original_vido_id video_id frame_id path labels\n')for orig_vid in dirs:vid_id = vid_map[orig_vid]vid_dir = os.path.join(frames_root, orig_vid)if not os.path.isdir(vid_dir):continuefor fname in sorted(os.listdir(vid_dir)):if fname.endswith('.jpg'):frame_id = int(fname.split('_')[-1].split('.')[0])f.write(f'{orig_vid} {vid_id} {frame_id} {orig_vid}/{fname} ""\n')print(f'✅ 已生成 {out_csv},目录 {dirs} 已处理')# ===== 用法 =====
if __name__ == '__main__':generate_val_csv(['e68a9872cfd45cc79867fc6a22117eda'])由于本文是直接指定哪个视频为训练集哪个训练为验证集,故上方代码传递相对应的目录名,即可生成train.csv和val.csv。
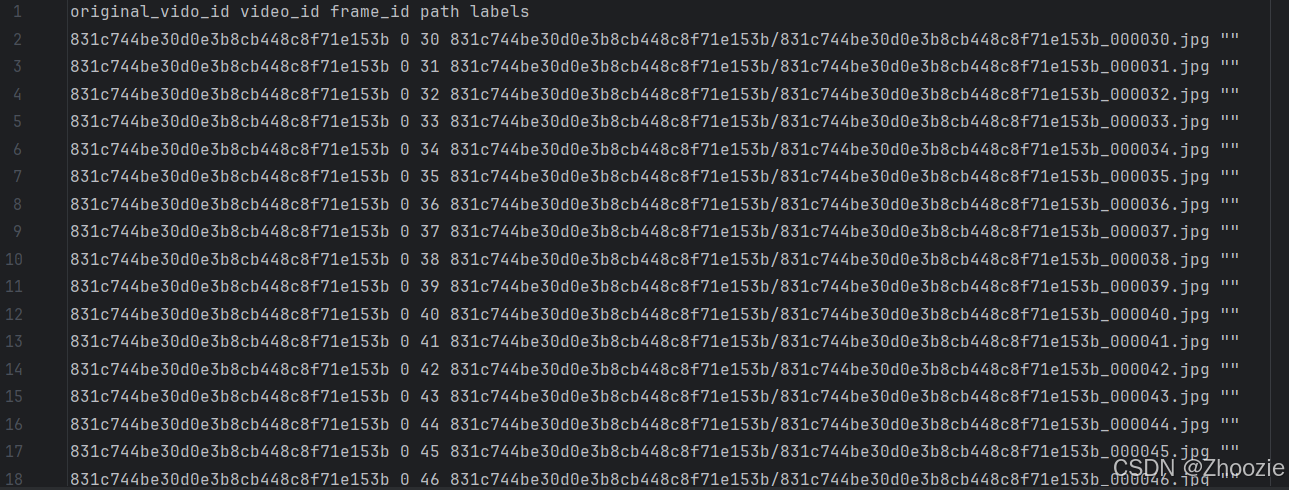
最终生成的结果如下
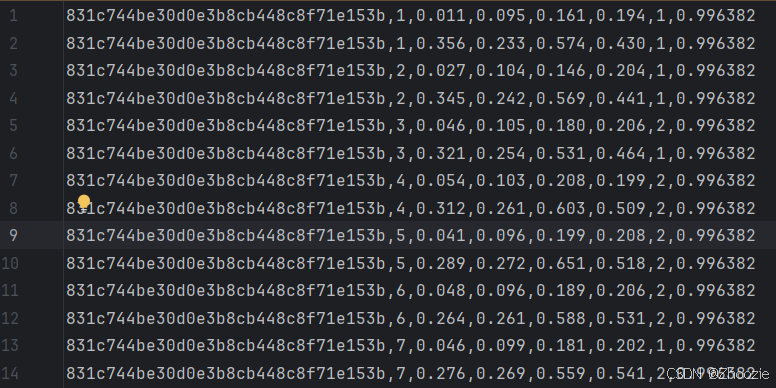
ava_detection_train_boxes_and_labels_include_negative_v2.2.csv
此文件直接对ava_train_v2.2.csv的前七列进行复制,最后一列使用置信度进行填充,置信度设置为0.996382.
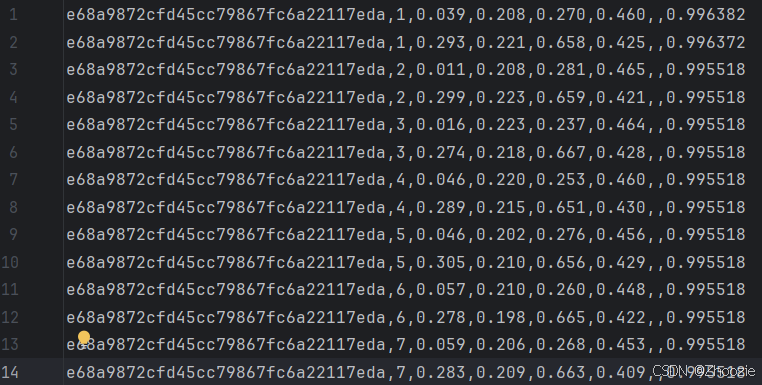
ava_detection_val_boxes_and_labels.csv
此文件对ava_val_v2.2.csv的前六列进行复制,第七列是空值,第八列用置信度填充,然后同样设置置信度。
运行
python tools/run_net.py --cfg configs/AVA/SLOWFAST_32x2_R50_SHORT5.yaml问题解决
问题一
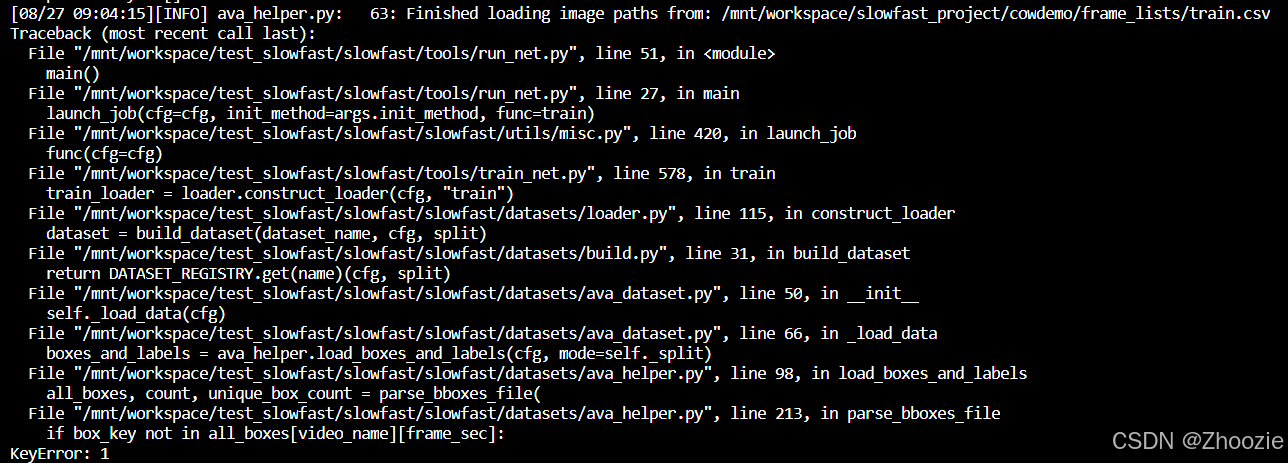
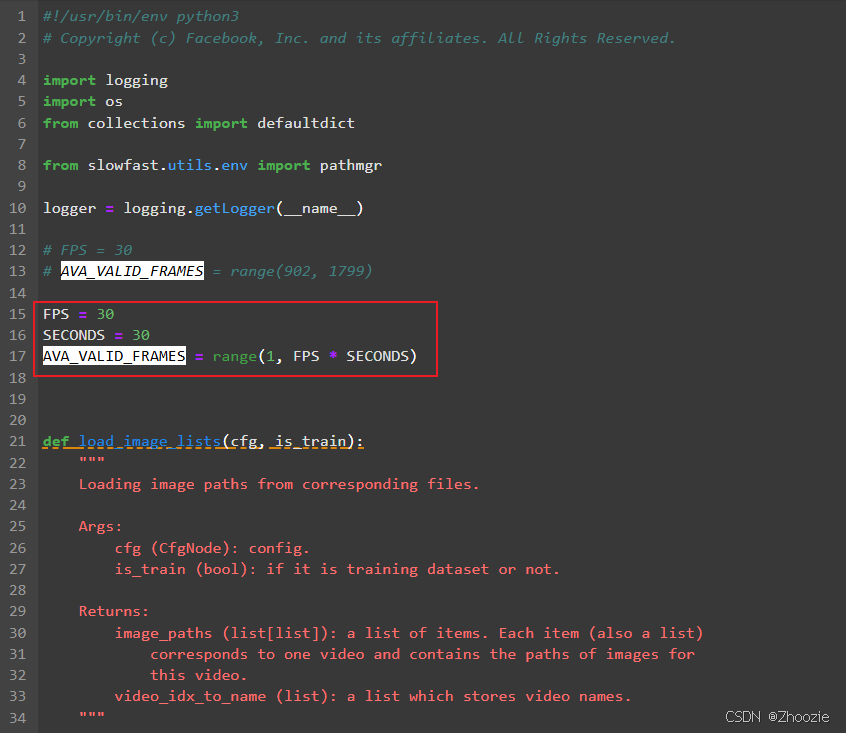
原csv文件是从902秒开始的,但是自己的视频是从第一秒开始的



)


与几个C++应用例子)
![[系统架构设计师]论文(二十三)](http://pic.xiahunao.cn/[系统架构设计师]论文(二十三))


)

实战指南:如何保护你的账号)






