目录
前言
一、概念与结构
二、双向链表的实现
2.1 头文件的准备
2.2 函数的实现
2.2.1 LTPushBack( )函数(尾插)
(1)LTBuyNode( )
(2)LTInit( )
(3)LTPrint( )
(4)LTPushBack( )
2.2.2 LTPushFront( )函数(头插)
2.2.3 LTPopBack( )函数(尾删)
2.2.4 LTPopFront( )函数(头删)
2.2.5 LTInsert( )函数(在pos位置之后插入数据)
2.2.6 LTErase( )函数(删除pos位置的结点)
2.2.7 LTFind( )函数(查找结点)
2.2.8 LTDestroy( )函数(销毁)
三、顺序表与链表的分析
总结
前言
数据结构作为计算机科学的核心基础之一,其高效性与灵活性直接影响程序性能。双向链表以其独特的双指针结构脱颖而出,既继承了单链表的动态内存管理优势,又通过前驱指针实现了逆向遍历与快速节点删除。这种结构在操作系统内核、数据库索引及LRU缓存淘汰算法等场景中展现关键价值。本文将深入剖析双向链表的实现原理、时间复杂度权衡及典型应用场景,下面就让我们正式开始吧!
一、概念与结构
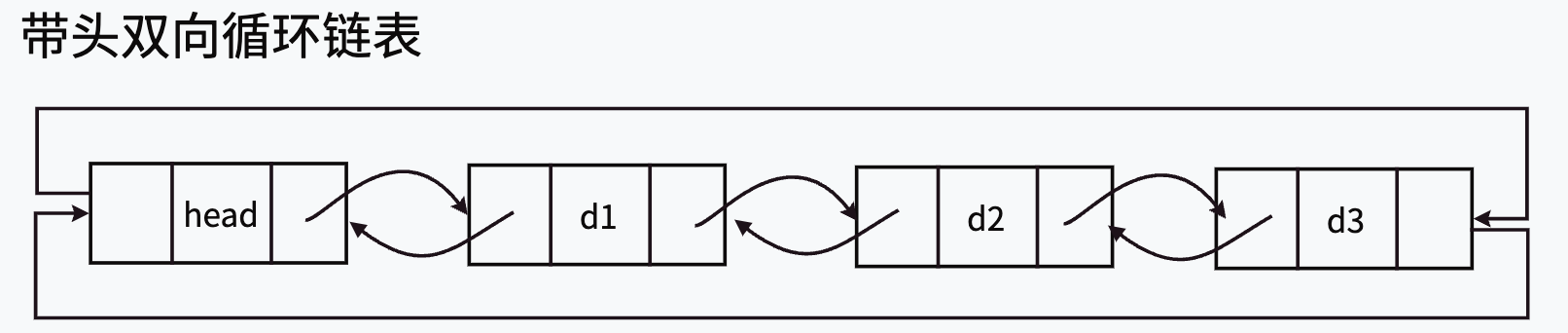
如上图所示,带头链表里的头结点,实际为“哨兵位”,哨兵位结点不存储任何有效元素,只是站在这里“放哨”的。
需要注意的是,这里的“带头”和前面博客中提到的“头结点”是两个概念,实际前面的在单链表阶段称呼是不严谨的,但是为了更好地帮助大家理解,我们才直接称为单链表的头结点。
二、双向链表的实现
2.1 头文件的准备
typedef int LTDataType;
typedef struct ListNode
{struct ListNode* next; //指针保存下⼀个结点的地址struct ListNode* prev; //指针保存前⼀个结点的地址LTDataType data;
}LTNode;//void LTInit(LTNode** pphead);
LTNode* LTInit();
void LTDestroy(LTNode* phead);
void LTPrint(LTNode* phead);
bool LTEmpty(LTNode* phead);void LTPushBack(LTNode* phead, LTDataType x);
void LTPopBack(LTNode* phead);void LTPushFront(LTNode* phead, LTDataType x);
void LTPopFront(LTNode* phead);
//在pos位置之后插⼊数据
void LTInsert(LTNode* pos, LTDataType x);
void LTErase(LTNode* pos);
LTNode *LTFind(LTNode* phead,LTDataType x);2.2 函数的实现
2.2.1 LTPushBack( )函数(尾插)
我们先来画图分析一下:

当然,在正式实现尾插函数之前,我们照旧还得先写一下双向链表的创建结点函数、链表初始化函数和链表打印函数 —— LTBuyNode( )、LTInit( )和LTPrint( ),如下所示:
(1)LTBuyNode( )
实现逻辑如下:
-
内存分配:为新节点分配内存空间
-
内存检查:检查内存分配是否成功
-
数据赋值:将数据存储到新节点
-
指针初始化:将前驱和后继指针都指向自己(循环链表特性)
完整代码如下:
LTNode* LTBuyNode(LTDataType x) {// 1. 内存分配LTNode* newnode = (LTNode*)malloc(sizeof(LTNode));// 2. 内存分配失败检查if (newnode == NULL) {perror("malloc fail!"); // 打印错误信息exit(1); // 退出程序}// 3. 数据赋值newnode->data = x;// 4. 指针初始化(双向循环链表的关键)newnode->next = newnode->prev = newnode;return newnode;
}(2)LTInit( )
该函数的实现逻辑如下:
-
创建哨兵节点:使用LTBuyNode函数创建特殊节点
-
返回链表头:返回指向哨兵节点的指针
-
建立空链表:初始化一个标准的空双向循环链表
完整代码如下:
// 初始化双向循环链表
LTNode* LTInit() {// 1. 创建哨兵节点,通常使用特殊值(如-1)标记LTNode* phead = LTBuyNode(-1);// 2. 返回哨兵节点作为链表头return phead;
}(3)LTPrint( )
该函数的实现逻辑如下:
-
遍历链表:从第一个有效节点开始遍历
-
打印数据:输出每个节点的数据值
-
循环检测:利用哨兵节点作为循环终止条件
-
格式化输出:使用箭头表示节点间的连接关系
完整代码如下:
void LTPrint(LTNode* phead) {// 1. 从第一个有效节点开始(跳过哨兵节点)LTNode* pcur = phead->next;// 2. 遍历链表,直到回到哨兵节点while (pcur != phead) {printf("%d -> ", pcur->data); // 打印当前节点数据pcur = pcur->next; // 移动到下一个节点}// 3. 打印换行,结束输出printf("\n");
}(4)LTPushBack( )
该函数的实现逻辑如下:
-
参数验证:确保头结点phead不为NULL。
assert(phead); -
创建新节点:使用LTBuyNode函数创建新结点,新结点包含数据x,prev和next指针初始化
LTNode* newnode = LTBuyNode(x); -
设置新结点的指针:
newnode->prev指向原来的尾节点(即phead->prev);newnode->next指向头节点phead。newnode->prev = phead->prev; newnode->next = phead; -
更新相邻结点的指针:将原来的尾结点的next指向新结点,将头结点的prev指向新结点(现在的新结点称为新的尾结点)。
phead->prev->next = newnode; phead->prev = newnode;
完整代码如下:
void LTPushBack(LTNode* phead, LTDataType x)
{assert(phead);LTNode* newnode = LTBuyNode(x);//phead phead->prev newnodenewnode->prev = phead->prev;newnode->next = phead;phead->prev->next = newnode;phead->prev = newnode;
}2.2.2 LTPushFront( )函数(头插)
画图分析如下:
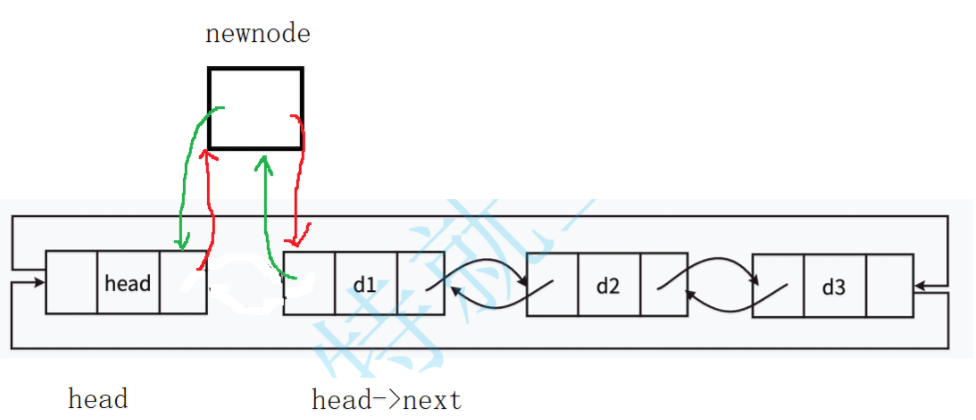
函数实现逻辑如下:
1.参数验证:确保头结点phead不为NULL。
2.创建新结点:调用LTBuyNode函数创建新结点。
3.设置新结点的指针:newnode->next 指向原来的第一个数据节点(即 phead->next);newnode->prev 指向头节点 phead。
newnode->next = phead->next;
newnode->prev = phead; 4.更新相邻结点的指针:将原来的第一个数据节点的 prev 指向新节点;将头节点的 next 指向新节点(现在新节点成为新的第一个数据节点)。
phead->next->prev = newnode;
phead->next = newnode;完整代码如下:
//头插
void LTPushFront(LTNode* phead, LTDataType x)
{assert(phead);LTNode* newnode = LTBuyNode(x);//phead newnode phead->nextnewnode->next = phead->next;newnode->prev = phead;phead->next->prev = newnode;phead->next = newnode;
}2.2.3 LTPopBack( )函数(尾删)
首先我们要先来实现一个判空函数LTEmpty():
bool LTEmpty(LTNode* phead)
{assert(phead);return phead->next == phead;
}下面来画图分析一下:
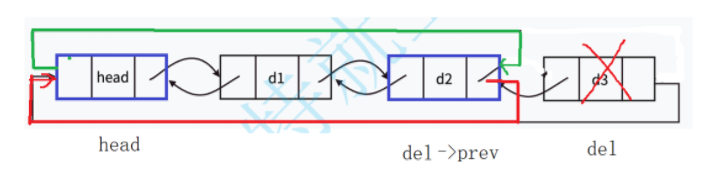
实现逻辑分析如下:
1.前置条件检查:使用LTEmpty 函数检查链表是否为空;如果链表为空(只有头节点),则断言失败,不能删除;确保链表至少有一个数据节点可删除。
assert(!LTEmpty(phead)); 2.定位要删除的结点:尾结点就是头结点的 prev 指向的节点;将尾节点保存到 del 变量中。
LTNode* del = phead->prev;3.更新指针连接:
-
del->prev->next = phead:将尾节点的前一个节点的next指向头节点 -
phead->prev = del->prev:将头节点的prev指向尾节点的前一个节点
del->prev->next = phead;
phead->prev = del->prev;4.释放内存:释放被删除结点的内存;将指针置为NULL,避免野指针。
free(del);
del = NULL;完整代码如下:
//尾删
void LTPopBack(LTNode* phead)
{assert(!LTEmpty(phead));LTNode* del = phead->prev;del->prev->next = phead;phead->prev = del->prev;free(del);del = NULL;
}2.2.4 LTPopFront( )函数(头删)
画图分析如下:
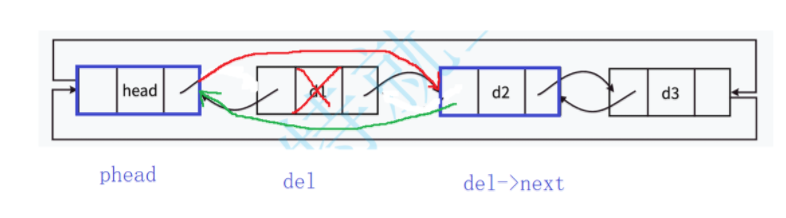
函数实现逻辑如下:
1.前置条件检查:使用 LTEmpty 函数检查链表是否为空。
2.定位要删除的结点:第一个数据节点就是头结点的next指向的结点;将该结点保存到 del 变量中。
LTNode* del = phead->next;3.更新指针连接:
-
del->next->prev = phead:将第二个数据节点的prev指向头节点 -
phead->next = del->next:将头节点的next指向第二个数据节点 -
这样就跳过了要删除的第一个数据节点
del->next->prev = phead; phead->next = del->next;4.释放内存:释放被删除节点的内存;将指针置为
NULL,避免野指针。
完整代码如下:
//头删
void LTPopFront(LTNode* phead)
{assert(!LTEmpty(phead));LTNode* del = phead->next;del->next->prev = phead;phead->next = del->next;free(del);del = NULL;
}2.2.5 LTInsert( )函数(在pos位置之后插入数据)
画图分析如下:
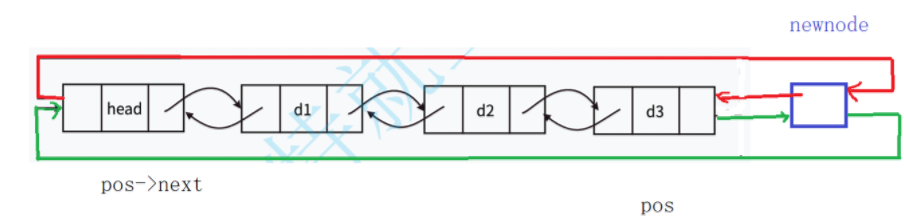
实现逻辑:
1. 参数验证:确保 pos 节点不为 NULL。
2.创建新结点:调用 LTBuyNode 函数创建新节点。
3.设置新结点的指针:
-
newnode->prev指向pos节点(前驱节点) -
newnode->next指向pos节点原来的下一个节点newnode->prev = pos; newnode->next = pos->next;4.更新相邻结点的指针:
-
将
pos节点原下一个节点的prev指向新节点 -
将
pos节点的next指向新节点
pos->next->prev = newnode;
pos->next = newnode;完整代码如下:
//在pos位置之后插⼊数据
void LTInsert(LTNode* pos, LTDataType x)
{assert(pos);LTNode* newnode = LTBuyNode(x);//pos newnode pos->nextnewnode->prev = pos;newnode->next = pos->next;pos->next->prev = newnode;pos->next = newnode;
}2.2.6 LTErase( )函数(删除pos位置的结点)
先画图分析一下:
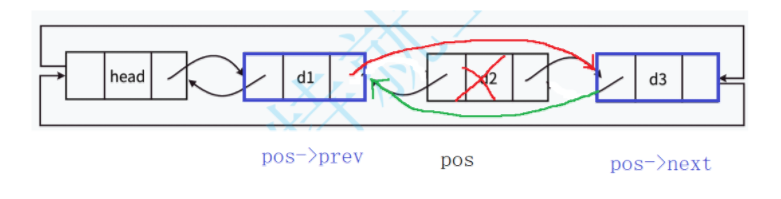
实现逻辑分析如下:
1.参数验证:确保 pos 节点不为 NULL。
2.更新指针连接(跳过要删除的节点):
-
pos->prev->next = pos->next:将前驱节点的next指向后继节点 -
pos->next->prev = pos->prev:将后继节点的prev指向前驱节点 -
这样就完全跳过了要删除的
pos节点pos->prev->next = pos->next; pos->next->prev = pos->prev;3.释放内存:释放被删除节点的内存。
free(pos); pos = NULL;完整代码如下所示:
//删除pos位置的节点 void LTErase(LTNode* pos) {assert(pos);//pos->prev pos pos->nextpos->prev->next = pos->next;pos->next->prev = pos->prev;free(pos);pos = NULL; }2.2.7 LTFind( )函数(查找结点)
实现逻辑如下:
1.参数验证:确保头节点 phead 不为 NULL
2.初始化遍历指针:创建当前指针 pcur 并初始化为第一个数据节点(phead->next);跳过哨兵头节点,从第一个数据节点开始遍历。
LTNode* pcur = phead->next; 3.遍历链表查找数据:循环条件 pcur != phead:当回到头节点时停止(完成一圈遍历);对每个数据节点检查其 data 是否等于目标值 x;如果找到匹配的节点,立即返回该节点的指针。
while (pcur != phead)
{if (pcur->data == x){return pcur;}pcur = pcur->next;
} 4.未找到的情况:如果遍历完所有数据节点都没有找到匹配的节点;返回 NULL 表示查找失败。
return NULL;完整代码如下:
LTNode* LTFind(LTNode* phead, LTDataType x)
{assert(phead);LTNode* pcur = phead->next;while (pcur != phead){if (pcur->data == x){return pcur;}pcur = pcur->next;}//未找到return NULL;
}2.2.8 LTDestroy( )函数(销毁)
画图分析如下:
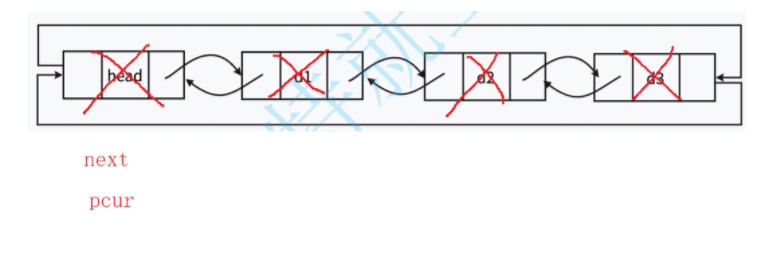
函数实现逻辑:
1.初始化遍历指针:创建当前指针 pcur 并初始化为第一个数据节点;从头节点的下一个节点开始遍历。
LTNode* pcur = phead->next;2.遍历并释放所有数据结点:
-
循环条件:
pcur != phead—— 当回到头节点时停止; -
保存下一个节点:在释放当前节点前,先保存下一个节点的指针;
-
释放当前节点:使用
free()释放当前数据节点的内存; -
移动到下一个节点:将
pcur指向之前保存的下一个节点。
while (pcur != phead)
{LTNode* next = pcur->next;free(pcur);pcur = next;
} 3.释放头结点:释放头节点(哨兵节点)的内存;将指针置为 NULL,避免野指针。
free(phead);
phead = NULL;完整代码如下:
//销毁
void LTDesTroy(LTNode* phead)
{LTNode* pcur = phead->next;while (pcur != phead){LTNode* next = pcur->next;free(pcur);pcur = next;}//销毁头结点free(phead);phead = NULL;
}三、顺序表与链表的分析
| 不同点 | 顺序表 | 链表(单链表) |
| 存储空间上 | 物理上⼀定连续 | 逻辑上连续,但物理上不⼀定连续 |
| 随机访问 | ⽀持O(1) | 不⽀持:O(N) |
| 任意位置插⼊或者删除元素 | 可能需要搬移元素,效率低O(N) | 只需修改指针指向 |
| 插⼊ | 动态顺序表,空间不够时需要扩 容和空间浪费 | 没有容量的概念,按需申请释放,不存在 空间浪费 |
| 应⽤场景 | 元素⾼效存储+频繁访问 | 任意位置⾼效插⼊和删除 |
总结
以上就是本期博客的全部内容啦!本期我为大家介绍了双向链表的实现逻辑以及顺序表与链表的对比分析,希望能够对大家学习数据结构有所帮助,谢谢大家的支持~!
重新找工作开始聊起)
八股小记)






读书笔记 25)




的充电桩调试平台)





