引言:你其实早就 “玩转” 过机器学习?
提到 “机器学习”,你是不是第一时间联想到复杂的代码、密密麻麻的公式,还有那些让人头晕的 “算法”“模型”“训练” 术语?仿佛它是高高在上的技术,离我们的日常无比遥远?
但今天我要揭开一个小秘密:你可能早就在不知不觉中 “用过” 机器学习了!
想想看,你是否在 Excel 里处理过这样的数据:比如 “广告投入(x)与销售额(y)”,假设你有 10 组数据(如下表),先把数据输入 Excel 并插入散点图,然后右键点击图表,选择 “添加趋势线”,再从弹出的选项里挑 “线性” 类型 —— 很快,Excel 就会画出一条平滑的直线,旁边还标注出趋势线方程(比如 y=5.2x+18.6)和 R² 值(比如 0.92)。
广告投入(万元)x | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
销售额(万元)y | 25 | 30 | 38 | 42 | 48 | 55 | 62 | 68 | 75 | 80 |
别小看这个操作!当你完成这一系列步骤时,你已经亲手完成了一次最基础、最直观的机器学习任务。而今天,我们就从这个你熟悉到不能再熟悉的 Excel 功能出发,一点点拆解机器学习的核心框架,让那些看似高深的概念,都变得像 “添加趋势线” 一样简单易懂。
第一部分:机器学习到底在做什么?—— 它的终极目标
其实机器学习的核心目标特别朴素,一句话就能说清:从已有数据中自动找出规律,再用这个规律预测未来的结果。
它不像我们想象中那么 “玄乎”,本质上就是在解决 “根据已知推未知” 的问题。比如:
- 预测房价时,它会根据 “房屋面积、地段、房龄” 这些已知信息(输入),找出它们和 “房价”(输出)之间的关系,进而预测一套新房的价格;
- 识别垃圾邮件时,它会分析 “邮件标题、内容里的关键词、发件人信息”,总结出垃圾邮件的特征,然后判断一封新邮件是不是垃圾邮件;
- 电商 APP 给你推荐商品时,它会梳理你的 “浏览记录、购买历史、收藏列表”,找到你喜欢的商品类型,再推送你可能感兴趣的新品。
如果用更数学的语言来描述,机器学习的本质就是寻找一个合适的数学函数 y = f (x)。这里的 x 是我们能拿到的 “输入数据”(比如房屋信息、邮件内容),y 是我们想得到的 “输出结果”(比如房价、是否为垃圾邮件),而 f (x) 就是连接 x 和 y 的 “规律”—— 我们一开始并不知道 f (x) 具体长什么样,但机器学习能帮我们从海量数据中,把这个 “隐藏的函数” 给 “学” 出来。
第二部分:如何实现机器学习?—— 标准工作流程拆解
就像我们做任何事情都有步骤一样,机器学习也有一套固定的、经过无数实践验证的 “标准工作流程”。把这个流程理清,你就掌握了机器学习的 “骨架”。整个过程可通过以下流程图清晰展示,共分为 6 个关键步骤,每一步都有明确的目标:
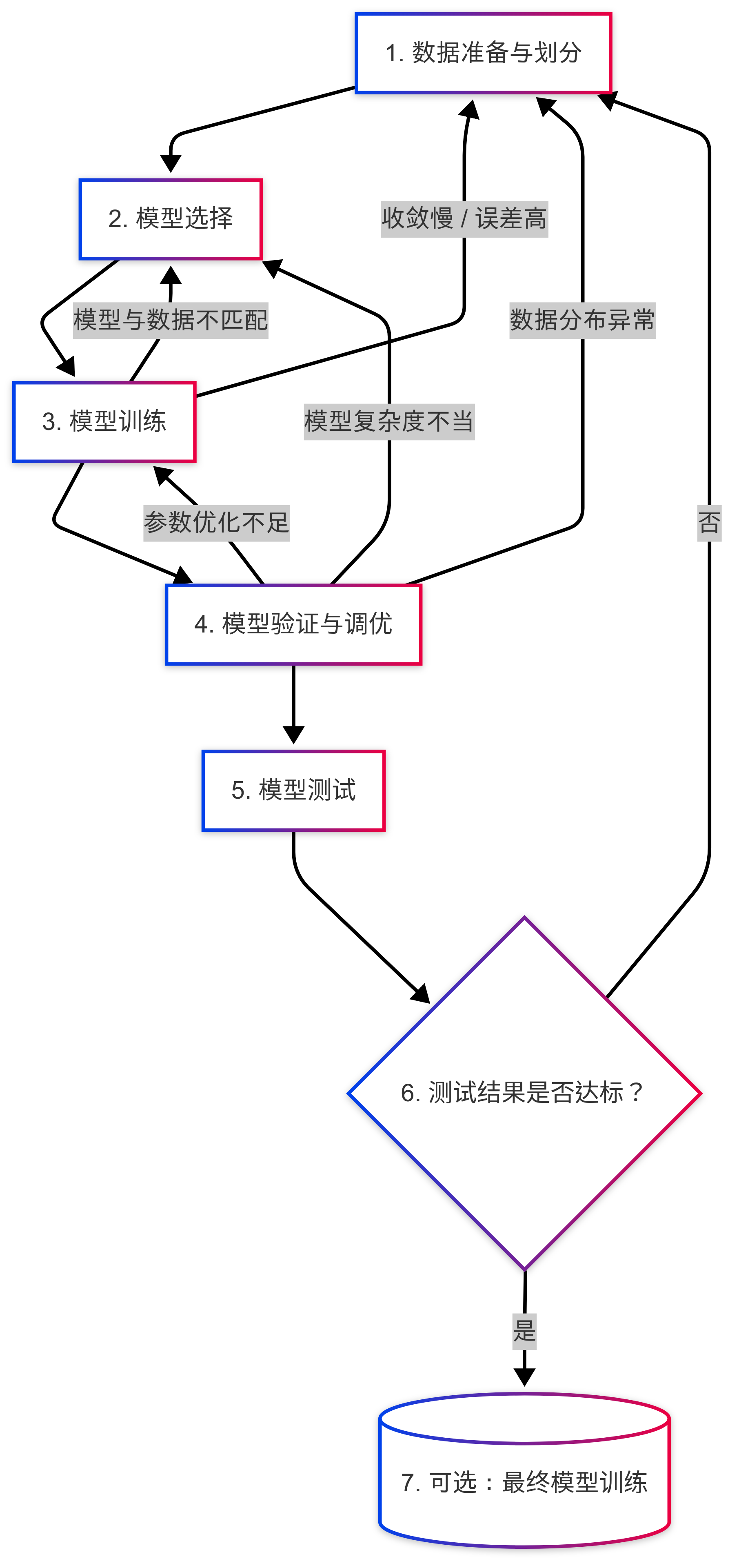
1. 数据准备与划分:打好 “地基”
机器学习的一切都依赖数据,所以第一步必须把数据处理好。首先要做的是 “数据收集”—— 从数据库、API 接口、Excel 表格等地方获取需要的原始数据;然后是 “数据清洗”—— 删除重复数据、填补缺失值、修正错误数据(比如把 “年龄 = 200” 这种明显不合理的值处理掉),确保数据的准确性。
这一步里有个至关重要的操作:把清洗好的数据分成三部分 —— 训练集、验证集和测试集。它们的作用就像学生学习时的 “教材”“练习题” 和 “期末考试卷”,各自承担不同的角色,缺一不可。比如上述 “广告投入与销售额” 数据,可按 7:2:1 的比例划分,7 组数据作为训练集,2 组作为验证集,1 组作为测试集。
2. 模型选择:选对 “工具”
数据准备好后,就要选择 “模型” 了。模型其实就是我们前面提到的 “函数形式”,比如想找线性关系,就选 “线性模型”;想处理更复杂的非线性关系,就选 “决策树”“神经网络” 等。
这一步就像你修桌子时选择工具:如果只是拧螺丝,用螺丝刀就够了;如果要锯木板,就得用锯子。选对模型,后续的工作才能事半功倍。比如 “广告投入与销售额” 数据从散点图看呈线性趋势,选择线性模型就很合适。
3. 模型训练:让模型 “学习” 规律
选好模型后,就进入 “训练” 阶段。我们会把 “训练集” 数据输入到模型里,让模型通过专门的 “优化算法”(比如梯度下降),自动调整内部的 “参数”(比如线性模型 y=wx+b 里的 w 和 b)。
这个过程就像学生看教材学习:模型会不断对比自己的 “预测结果” 和训练集中的 “真实结果”,然后一点点修正参数,直到预测结果和真实结果的差距(误差)越来越小 —— 就像学生通过看书,不断纠正自己对知识点的理解一样。比如用 “广告投入与销售额” 的 7 组训练数据训练线性模型,最终得到 w=5.2、b=18.6 的参数。
4. 模型验证与调优:帮模型 “查漏补缺”
训练完模型,不能直接用,得先 “检验” 一下它的水平。这时候 “验证集” 就派上用场了:我们把验证集数据输入到训练好的模型里,看它的预测效果如何(比如用准确率、误差值等指标评估)。
如果效果不好,就要进行 “调优”:比如调整 “超参数”(不是模型内部的参数,而是我们人为设定的配置,比如学习率、决策树的深度),或者换一个更合适的模型,然后重新训练、重新验证 —— 这个过程就像学生做练习题,发现哪里不会就回头复习,直到练习题的正确率达标。
5. 模型测试:给模型做 “最终考核”
当模型在验证集上表现足够好时,就该用 “测试集” 做最终评估了。这里有个关键原则:测试集的数据,模型在训练和验证阶段绝对不能见过。
因为测试集的作用是模拟 “真实的未知场景”,评估模型在没见过的数据上的表现 —— 就像期末考试的题目都是学生没做过的,只有这样才能真实反映学生的学习水平。如果测试集的结果达标,说明这个模型可以用了;如果不达标,就得回到前面的步骤,重新优化。
6. (可选)最终模型训练:让模型 “火力全开”
如果测试结果满意,还有一个可选步骤:把 “训练集 + 验证集” 合并成新的训练数据,用之前确定好的模型和超参数,重新训练一次,得到最终的部署模型。
为什么要这么做?因为验证集本来也是优质数据,把它加进来一起训练,能让模型学到更多规律,性能更稳定 —— 就像学生考完试后,把教材和练习题再复习一遍,巩固所有知识点,然后再去应对实际问题。
第三部分:核心概念速览:5 分钟搞懂关键术语
在继续往下聊之前,我们先把几个最核心的术语明确一下,避免后面出现理解偏差。这些术语就像机器学习的 “基础词汇”,记住它们,就能轻松看懂大部分内容:
- 模型 (Model):就是我们假设的 “函数形式”,比如线性模型 y=wx+b、决策树模型、神经网络模型等,它决定了我们用什么 “方式” 去寻找数据中的规律。
- 参数 (Parameters):模型内部可以自动学习的变量,比如线性模型里的 w(斜率)和 b(截距),训练的过程就是调整这些参数的过程。
- 超参数 (Hyperparameters):需要我们在训练前人为设定的 “配置项”,比如学习率(控制参数调整的速度)、决策树的最大深度(控制模型的复杂度),超参数不能靠模型自动学习,只能通过验证集调优。
- 训练集 (Training Set):用来 “教” 模型学习的数据集,相当于学生的 “教材”,模型主要靠它来学习规律。
- 验证集 (Validation Set):用来 “检验模型学习效果” 并 “调优” 的数据集,相当于学生的 “练习题”,帮助我们找到模型的最佳配置。
- 测试集 (Test Set):用来 “评估模型最终能力” 的数据集,相当于学生的 “期末考试卷”,是对模型真实性能的最终检验。
- 过拟合 (Overfitting):模型的 “致命问题” 之一。指模型把训练数据里的 “噪声”(比如数据记录时的偶然误差)都当成了 “规律”,导致在训练集上表现很好,但在新数据(比如测试集)上表现很差。就像学生死记硬背了练习题的答案,换一道新题就不会做了。
第四部分:类比强化:Excel 拟合曲线 vs. 机器学习
机器学习的核心目的是预测未知,即当遇到未在训练数据中出现的输入 x 时,能通过学到的规律(模型)计算出对应的输出 y。这一点在 Excel 拟合曲线操作中也有直观体现,我们结合 “广告投入与销售额” 的 Excel 实操例子,把 Excel 的 “趋势线” 操作和机器学习的标准流程完整对比:
Excel 拟合曲线实操示例
先将 “广告投入与销售额” 的 10 组数据输入 Excel,A 列是 x(广告投入),B 列是 y(销售额),插入散点图后,右键点击散点选择 “添加趋势线”:
- 选 “线性” 趋势线:Excel 自动生成趋势线方程 y=5.2x+18.6,R²=0.92,散点图上呈现一条穿过数据点中心的直线,能较好反映两者线性关系;
- 若选 “多项式” 且阶数设为 5:趋势线会扭曲地穿过几乎所有散点,但 R² 接近 1,此时若代入 x=11(未知广告投入),计算出的 y 值会与实际预期偏差极大,这就是过拟合。
流程对比表
机器学习步骤 | Excel 拟合曲线操作(以 “广告投入与销售额” 为例) | 类比说明 |
1. 数据准备 | 将 x(1-10)、y(25-80)分别输入 Excel A、B 列,整理成表格 | 无论是机器学习还是 Excel 拟合,“干净的原始数据” 都是基础,数据乱了,后续都白搭。 |
2. 数据划分 | (隐含操作)心里确定用前 7 组数据画趋势线(训练),留后 3 组检验(2 组验证、1 组测试) | Excel 没有明确的 “划分” 功能,但理想情况下,会留部分数据检验,也能对 x=11 这类未知值预测。 |
3. 模型选择 | 右键散点图→“添加趋势线”→选 “线性”(而非 “多项式”) | 选 “线性” 趋势线,就是机器学习里的 “模型选择”,为后续预测未知数据(如 x=11)打基础。 |
4. 训练与调参 | Excel 自动计算出趋势线斜率 5.2、截距 18.6,生成方程 y=5.2x+18.6 | Excel 将 “选模型” 和 “算参数” 合并;机器学习则分开,先选线性模型,再用训练集调参,最终都得到能预测未知的 “函数表达式”。 |
5. 模型评估 | 查看 R²=0.92(拟合优度高),且用第 8 组 x=8 验证,预测 y=5.2×8+18.6=59.2,接近真实 y=68(误差较小) | R² 越接近 1,对已知数据拟合越好,对未知数据预测越可靠,和机器学习用测试集验证逻辑一致。 |
6. 警惕过拟合 | 选 5 阶多项式,趋势线扭曲穿过所有散点,但用 x=10 测试,预测 y 与真实 80 偏差大 | 这就是 “过拟合”!曲线贴合现有数据,却丢失真实规律,导致未知 x 预测偏差大,机器学习需用验证集避免。 |
7. 预测未知(核心目的) | 代入未知 x=11(广告投入 11 万元),用方程算 y=5.2×11+18.6=75.8(预测销售额 75.8 万元) | 这是机器学习核心目标的体现!机器学习训练模型,就是为了对新输入 x 输出准确 y,Excel 算未知 y 同理。 |
这个类比的精髓,可总结成五句话,覆盖机器学习核心目的:
- Excel 的 “趋势线类型(如线性)” = 机器学习的 “模型选择”,都是找合适规律形式;
- Excel 的 “斜率 5.2、截距 18.6” = 机器学习的 “参数”,构成预测未知的 “函数核心”;
- Excel 的 “R²=0.92 + 验证集检验” = 机器学习的 “评估指标 + 测试集验证”,判断预测可靠性;
- Excel 的 “5 阶多项式扭曲曲线” = 机器学习的 “过拟合”,都让模型失去预测未知能力;
- Excel“x=11 算 y=75.8” = 机器学习 “用模型预测未知”,核心都是从已知推未知。
总结:从 Excel 到 AI,只差一套 “系统化流程”
看到这里,你应该能明白:机器学习不是什么 “魔法”,它和你在 Excel 里给 “广告投入与销售额” 数据画线性趋势线、算 x=11 对应 y 值的本质是一样的 —— 都是找数据背后的数学关系,都是 “从已知推未知”。
但两者的区别也很明显:Excel 的拟合是 “简单版”,适合少量、简单数据,预测靠手动代入;而机器学习是 “进阶版”,通过 “明确划分数据集”“分离模型选择与参数训练”“用验证集调优” 等系统机制,避免人为偏差,能处理百万级数据和复杂模型(如图像识别神经网络),还能自动化预测。
开箱状态预装OEM原厂Win11系统)
)




)












