数据仓库详解
- 第一节 数据仓库构建方法论和实践
- 一、数据仓库与数据库的区别
- 二、数据仓库对于企业的价值
- 三、数据仓库的模型构建
- 1、数据仓库构建需要考虑的问题
- 2、什么是数仓的数据模型
- 3、如何构建数仓的数据模型
- (1)概念模型设计
- (2)逻辑模型设计
- (3)物理模型设计
- 四、案例:招标采购系统的数据仓库构建
- 1、概念模型设计
- 2、逻辑模型设计
- 3、物理模型设计
- 五、数据仓库产品
- 1、MPP还是Hadoop?
- 2、MPP数仓特性
- 第二节 数据仓库体系架构及建模
- 一、什么是数据仓库?
- 二、数据仓库系统体系结构
- 三、数仓建模
- 维度建模5步骤
第一节 数据仓库构建方法论和实践
本文主要讨论数据仓库的构建方法论,包括数据仓库的价值、选型、构建思路。随着数据规模膨胀和业务复杂度的提升,大型企业需要构建企业级的数据仓库(数据湖)来快速支撑业务的数据化需求,与传统的数据库构建不同,数据仓库即是OLAP(On-Line Analytical Processing,联机分析处理)场景,偏于历史数据的存储/分析,用冗余存储换取数据价值。
一、数据仓库与数据库的区别
所有的应用系统都会涉及到数据库,针对数据库归纳和存放,也就是数据库的常见操作:增、删、改、查,那么为什么想要对企业数据进行分析,不能直接查询数据库,非要大费力气的去创建所谓的数据仓库呢?
数据仓库主要是为了能够支持管理决策,而数据库是为了满足系统的及时性、一致性。
好比你去银行存钱,你希望刚把钱存进去就能够查询到余额增加,你不希望第二天才能够确认,但是若是银行想对你的流水和余额进行分析,这个时候希望知道你在不同时期的银行余额,那么从数据库里是查不到你的历史余额信息的,因为数据库在设计的时候就需要满足一定的范式,为的就是满足及时性和去冗余,一个客户对应的余额只有一个,你在存款的时候,新的余额就会覆盖掉老的余额,所以你的历史信息在数据库中是没有记录的。
如果银行希望查询客户的历史信息,比如说你需要查询个人客户信息,他可能在柜台交易系统中有记录,也可以在网上银行交易系统也有记录,而你希望查询客户柜台交易信息以及网银交易信息,这个时候需要跨系统查询,有可能两个系统所使用的数据库都不一样,各自权限负责人员也不一样,跨系统查询显得非常困难,这个时候需要一个系统能够将所有业务系统的数据汇总起来并能够跨系统查询,这个时候数据仓库定义中的集成的,反映历史变化的正好解决了此问题。
数据库和数据仓库的对比

其中 OLTP(On-Line Transaction Processing,联机事务处理) ,也称为面向交易的处理过程,指的是传统的关系型数据库,针对实时业务处理,面对的主要操作是随机读写,采用满足三范式的实体关系模型存储数据,从而在事务处理中解决数据的冗余和一致性问题。
而 OLAP(On-Line Analytical Processing,联机分析处理) 系统面向数据批量读写,OLAP不关注事务处理的一致性,主要在数据的整合,以及复杂大数据查询和处理性能,OLAP能够支持复杂的分析操作。

综上, 数据库的设计是为了完成交易而设计的,不是为了而查询和分析的便利设计的。而数据仓库是为了大量的查询和分析所设计的。
二、数据仓库对于企业的价值
数据仓库能实现跨业务条线、跨系统的数据整合,为管理分析和业务决策提供统一的数据支持,从根本上把运营数据转化成为高价值的可以获取的信息(或知识),并且在恰当的时候通过恰当的方式把恰当的信息传递给恰当的人。
数据仓库定义:面向主题的(Subject Oriented)、集成的(Integrate)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合。
- 面向主题:是指用户使用数据仓库进行决策时所关心的重点方面,如:收入、客户、销售渠道等;所谓面向主题,是指数据仓库内的信息是按主题进行组织的,而不是像业务支撑系统那样是按照业务功能进行组织的。
- 集成的:是指数据仓库中的信息不是从各个业务系统中简单抽取出来的,而是经过一系列加工、整理和汇总的过程,因此数据仓库中的信息是关于整个企业的一致的全局信息。
- 反映历史变化:数据仓库内的信息并不只是反映企业当前的状态,而是记录了从过去某一时点到当前各个阶段的信息。通过这些信息,可以对企业的发展历程和未来趋势做出定量分析和预测。
如下图,数据仓库并非是面向生产的数据系统,而是集成并加工了多个数据库系统数据,并面向各个业务条线构建的数据存储体系,能够提供快速的运营/决策支撑能力。

- 高级管理进行业务分析和绩效考核的数据整合、分析和展现的工具。
- 主要用于历史性、综合性和深层次数据分析。
- 数据来源是ERP(例:SAP)系统或其他业务系统。
- 能够提供灵活、直观、简洁和易于操作的多维查询分析。
- 不是日常交易操作系统,不能直接产生交易数据。

三、数据仓库的模型构建
1、数据仓库构建需要考虑的问题
与数据库的单表基于ER模型构建思路不同,其面向特定业务分析的特性,决定了它的构建需要整合多套数据输入系统,并输出多业务条线的、集成的数据服务能力,需要考虑更全面的因素,包括:
- 业务需求:从了解业务需求着手分析业务特点和业务期望。
- 系统架构:从系统架构和数据分布、数据特性等角度,分析系统架构设计上是否有问题。
- 逻辑设计:从数据模型逻辑设计出发是否设计合理,是否符合数据库开发和设计规范等。
- 物理设计:从库表类型、库表分区、索引、主键设计等维度,主要针对性能,可扩展性进行物理模型设计审查。
2、什么是数仓的数据模型
数据仓库模型构建的宗旨能够直观地表达业务逻辑,能够使用实体、属性及其关系对企业运营和逻辑规则进行统一的定义、编码和命名,是业务人员和开发人员之间沟通的一套语言。数据仓库数据模型的作用:
- 统一企业的数据视图。
- 定义业务部门对于数据信息的需求。
- 构建数据仓库原子层的基础。
- 支持数据仓库的发展规划。
- 初始化业务数据的归属。
常用数据模型的是关系模型和维度模型。
关系模型从全企业的高度设计一个3NF模型的方法,用实体加关系描述的数据模型描述企业业务架构,在范式理论上符合3NF,其站在企业角度进行面向主题的抽象,而不是针对某个具体业务流程的,它更多是面向数据的整合和一致性治理。
维度建模以分析决策的需求为出发点构建模型,直接面向业务,典型的代表是我们比较熟知的星形模型,以及在一些特殊场景下适用的雪花模型,大多数据仓库均会采用维度模型建模。维度建模中的事实表客观反应整个业务的流程,比如一次购买行为我们就可以理解为是一个事实,订单表就是一个事实表,你可以理解他就是在现实中发生的一次操作型事件,我们每完成一个订单,就会在订单中增加一条记录,订单表存放一些维度表中的主键集合,这些ID分别能对应到维度表中的一条记录,用户表、商家表、时间表这些都属于维度表,这些表都有一个唯一的主键,然后在表中存放了详细的数据信息。

如果是采用ER模型,需要设计出一个大宽表,将订单-商家-地址-时间等信息囊括在内,比较直观、细粒度,但也存在设计冗余,如果数据量很大,对于查询和检索将是一个灾难。

3、如何构建数仓的数据模型
概念模型设计(业务模型):界定系统边界;确定主要的主题域及其内容;
逻辑模型设计:维度建模方法(事实表、维度表);以星型和雪花型来组织数据;
物理模型设计:将数据仓库的逻辑模型物理化到数据库的过程。
(1)概念模型设计
数据仓库中数据模型设计顺序如上,数据仓库是为了辅助决策的,与业务流程(Business Process)息息相关,数据模型的首要任务便是选择业务流程,为数据仓库的建立提供指导方向,这样才能反过来为业务提供更好的决策数据支撑,让数据仓库价值的最大化,对于每个业务流程,都需要进行独立的数据建模,将业务系统中的 ER 模型转化为数据仓库中的维度数据模型,以便更好的查询与分析。
(2)逻辑模型设计
事实表一般由两部分组成,维度(Dimension)和度量(Measurement),事实表可以通俗的理解为「什么人在什么时间做了什么事」的事实记录或者场景上下文,拥有最大的数据量,它是业务流程的核心体现,比如电商场景中的订单表,其主键为一个联合主键,由各个维度的外键组成,外键不能为空值,事实表一般不包含非数字类型字段,虽然数据量大,但占用的空间并不大,保证更高的查询效率。
维度表用于对事实表的补充说明,描述和还原事实发生时的场景,如电商订单中定义用户、商品、地址、时间、促销5个维度,通过这5个维度还原订单发生时的场景,什么人在什么时间在什么地方购买了什么商品,以及购买该商品的促销方式。对于每一个维度而言,都有若干个属性来描述,比如用户有性别、年龄、所在地等信息。这些维度的属性就是之后数据统计的依据,比如我们可以统计不同性别,不同年龄,不同地区在订单中的差异,从向用户制定更精细的营销策略。
在关系型数据库三范式(3NF)设计极力避免数据的冗余,达到数据的高度一致性,但在数据仓库中3NF并不是最佳实践,反而让系统复杂不已,不利于理解和维护,所以在维度建模中,维度表一般采取反范式的设计,在一张维度表中扁平化存储维度的属性,尽量避免使用外键。
(3)物理模型设计
在完成数据仓库的概念模型和逻辑模型设计之后,物理模型设计就是落地实施环节,根据数据的粒度和对于业务支撑能力将数据进行分层存储,数据分层存储简化了数据清洗的过程,每一层的逻辑变得更加简单和易于理解,当发生错误或规则变化时,只需要进行局部调整。
- ODS层:全称是Operational Data Store,操作数据存储,又叫数据准备层,数据来源层,主要用于原始数据在数据仓库的落地,这些数据逻辑关系都与原始数据保持一致,在源数据装入这一层时,要进行诸如业务字段提取或去掉不用字段,脏数据处理等等。可以理解为是关系层的基础数据。
- DIM层:Dimension层,主要存放公共的信息数据,如国家代码和国家名,地理位置等信息就存在DIM层表中,对外开放,用于DWD,DWS和APP层的数据维度关联。
- DWD层:全称是Data Warehouse Detail,数据仓库详细信息,用于源系统数据在数据仓库中的永久存储,用以支撑DWS层和DM层无法覆盖的需求,该层的数据模型主要解决一些数据质量问题和数据的完整度问题,比如商场的会员信息来与不同表,某些会员的的和数据可能不完整等等问题。
- DWS层:全称是Data Warehouse Service,数据仓库服务,主要包含两类汇总表:一是细粒度宽表,二是粗粒度汇总表。按照商场订单例子,包含基于订单、会员、商品、店铺等实体的细粒度宽表和基于维度组合(会员日进场汇总、会员消费汇总、商场销售日汇总、店铺销售日汇总等)的粗粒度汇总表。这层是对外开放的,用以支撑绝大部分的业务需求,汇总层是为了简化源系统复杂的逻辑关系以及质量问题等,这层是的业务结构容易理解,dws层的汇总数据目标是能满足80%的业务计算。
其上根据业务需求可以继续构建ADS层(Application Data Store)和面向指标和报表的高度汇总层。
四、案例:招标采购系统的数据仓库构建
按照数据仓库的构建思路,顺序是概念模型–>逻辑模型–>物理模型,最重要和复杂度较高的是概念模型的设计,需要结合业务,并根据业务特性设计事实表、维度表、顶层数据汇总表。
1、概念模型设计
概念模型需要结合生产系统的ER关系模型,梳理业务逻辑,当前生产交易系统使用的是ORACLE数据库,将数据分成多个库:业务库(包含招标采购项目流程)、主体+组织库(招标人、投标人、评标专家、代理机构)、财务库(标书费、平台服务费、招标保证金、CA办理费用等),项目表即是一个招标流程表,该表会记录关于招标过程中的,招标、投标、开标、评标、定标相关的数据。
- 招标:招标流程是招标人发起的,招标人将招标过程委托给代理机构,代理机构会发布招标公告,投标人在报名、响应阶段产生数据,响应后需要付投标保证金。
- 投标:投标人给代理机构缴纳标书费并下载招标文件,开标之前需要响应,并缴纳投标保证金;发售招标文件和投标人购买标书后,如果投标人对招标文件提出质疑,或招标人要修改招标文件,此时要在规定时间内发布一个澄清公告。
- 开标:开标一般是线下进行,代理机构把投标人召集到开标室,公开宣读投标人关于投标人报价、工期、质量、工程项目经理等投标人有实质要求的内容,此阶段拆封投标文件,解密电子的投标文件。
- 评标:评标一般是线下进行,代理机构把监督人、投标人、专家召集到评标室,专家对投标人资质及投标书打分,分为技术、商务、报价分。
- 定标:专家对投标人综合打分后,做一个总体排名,排名第1即为中标候选人,评标结束后需要发布预中标公告,将前3名公布,公告期间接受社会监督,期间产生的疑问、质疑需要代理机构/招标人澄清,澄清伴随着澄清公告,若质疑生效则可能废标和流标(评标成本高,一般不废标)。
- 合同:若预中标发布后,质疑期间对于预中标候选人无影响,在预中标发布xxx天后,招标人需要同中标候选人签订合同,同时招标人需要退还其他没有中标单位的保证金。
2、逻辑模型设计
逻辑模型采用上一篇博文提及的维度建模模型,雪花模型,项目ID、投标人ID、招标人ID、代理机构ID、专家ID分别是整个招、投、开、评、定标流程的主要参与主体,数据抽取工具使用kettle:
数据表命名规范:tb_模型层次_主题域_业务域_汇总粒度
kettle命名规范:kt_模型层次_主题域_业务域_汇总粒度
3、物理模型设计
构建ODS–>DWD–>DWS–>ADS的分层模型,这里ODS只抽取oracle库中源数据,不做任何清洗和变动,DWD层开始做数据的清洗和数据工程,DWS作轻度汇总,ADS面向应用查询提供更上层的汇总;以项目和供应商的汇总维度为例,项目流程是模型设计主体,供应商是类似维度表的数据,两者结合能够得到业务需要的一些投/中标相关的汇总维度(比如中标率排行、某个项目的投标人的注册金额相关统计、某投标人参与投标相关统计等)。

在项目流程表中(定标流程),将招标人的编号设计在内,定标流程的统计项从该类ADS汇总维度出结果。

五、数据仓库产品
前面讲了数据仓库的价值、构建思路、实例,完成数据仓库的概念、逻辑、物理模型设计后,数仓的产品选型也是需要考虑的部分,根据数据存储量、查询效率、并发能力可以选用MPP数仓和基于Hadoop的分布式数仓等。
1、MPP还是Hadoop?
数据仓库产品主要分为MPP架构和Hadoop架构两大类,具体选择需结合业务需求:
MPP架构数据仓库
Vertica:无中心架构,所有节点均可提供查询服务,列式存储支持高压缩比和快速查询,适用于实时分析。
Greenplum:基于PostgreSQL开发,采用master/slave模式,存在单点故障风险,适合结构化数据存储。
Teradata:传统MPP数据库,支持大规模数据仓库构建,侧重批量数据处理。
Hadoop架构数据仓库
Hive:基于Hadoop的分布式数据仓库,擅长处理海量历史数据,适合离线分析。
HBase:半结构化文档快速检索,与Hive结合实现冷热数据分离。
- 选型建议:
- 实时分析优先:选择Vertica或GBase 8a(无中心架构,高并发)。
- 离线分析为主:Hadoop+Hive更适合,成本更低且扩展性强。
- 结构化数据:Greenplum或Teradata(需评估单点故障风险)。
数据仓库的特性是处理温数据和冷数据,面向业务分析提供偏于离线分析能力,因此一般选用Hadoop+MPP数仓结合的解决方法,Hive能够提供大批量历史数据的存储计算能力,Hbase能够提供半结构化文档的快速检索能力,MPP能够提供强大高压缩比基础上的快速查询能力。
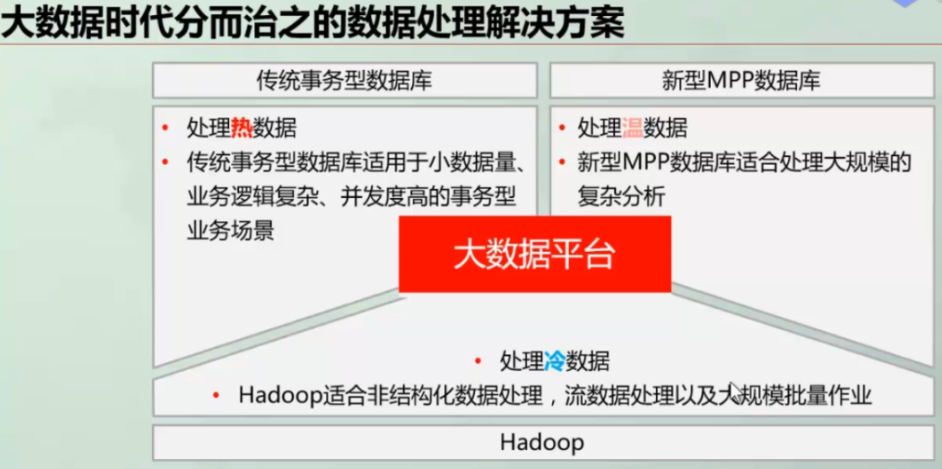
2、MPP数仓特性
数仓的特性是大批量的查询和索引,少量的改查工作,MPP (Massively Parallel Processing),即大规模并行处理数据库的一般特性。
① 列式存储意味着高压缩比、高IO能力、快速查询能力、智能索引(数据写入时)。
② shared nothing意味着节点的相互独立、数据的冗余备份。
③ 分布式存储/计算、存储/计算的高扩展性、高安全。
MPP的架构分为3种,GP是master/slave模式,具备统一的查询入口(master),vertica是无中心架构,所有节点都提供查询服务,gbase是存储/管理双中心架构。
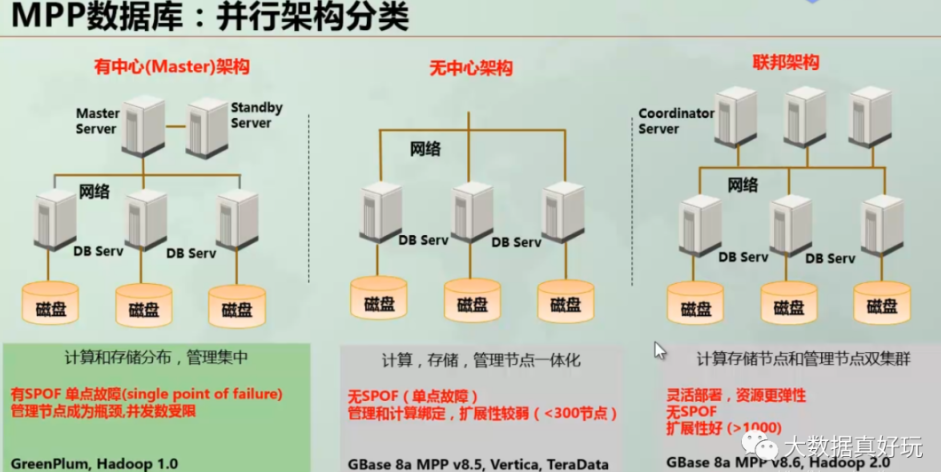
shared nothing 模式:x86机器构建计算/存储的高扩展集群,数据拆分多份并备份。
shared disk 模式:专用小型机,存储1份数据。
第二节 数据仓库体系架构及建模
一、什么是数据仓库?
数据仓库,最早由比尔·恩门(Bill Inmon)于1990年提出,主要功能是将组织或企业里面的联机事务处理(OLTP)所累积的大量数据,透过数据仓库理论所特有的储存架构,进行系统的分析整理,以利于各种分析方法如联机分析处理(OLAP)、数据挖掘(Data Mining)的进行,并进而支持如决策支持系统(DSS)、主管信息系统(EIS)的创建, 帮助决策者能快速有效的从大量数据中分析出有价值的信息。
目前, 被广泛接受的数据仓库的定义是由Bill Inmon在1991年出版的 "Building the Data Warehouse"一书中所提出的,其定义如下:
数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、反映历史变化(Time Variant)、相对稳定的(Non-Volatile)的数据集合,用于支持管理决策(Decision Making Support)。
其实,在大数据时代,随着机器学习和人工智能的兴起,这个定义需要做一些补充:数据仓库不只是用于构建支持管理决策的商业智能BI的基础, 也是大量的机器学习和人工智能算法的底层基础之一。
主要包括以下几个关键词:
- 面向主题
数据仓库是用来分析特定的主题域的,比如用户、交易、流量等等,主题域的划分也是构建数仓总线矩阵的基础。关于主题的划分,是建立在深入理解业务的基础之上的,并没有一个统一的标准,一个基本的原则是:主题域要尽量涵盖所有的表。可以将主题理解为业务的归纳,属于一个大的分类,有了明确的主题划分,数仓的建设才不至于混乱。 - 集成
我们知道,数据仓库之所以称之为仓库,是因为其集成了多种OLTP的数据源,将不同的数据源汇总至数仓的过程就是集成。数据源A和数据源B可能是识别某个产品的不同的方向,但是在数据仓库中,仅有一个方式来识别某个产品, 对于同一产品中分散在不同的数据源中的不同信息,数据仓库需要进行数据抽取、清洗、整合;对于分散在不同的数据源中的同一冗余信息则需要消除不同数据源的不一致性,以保证数据仓库内的信息是关于整个企业/业务/主题的一致的全局信息。 - 反应历史变化
这一点很好理解,简单讲就是包含历史的所有数据。这点是相对数据库而言, 因为后者通常保持是是最近一段时间的数据。例如:我们可以从数据仓库中获取3个月, 6个月,12个月甚至10年的订单数据; 而数据库里可能只能获取最近3年的订单数据。 - 相对稳定
一个数据一旦进入数据仓库,则不可改变。数据仓库的历史数据是不应该被更新的。这里需要强调的是:一是历史一旦形成,不可更改。几乎所有的数据仓库产品都不支持更新修改操作,但是是支持重载操作,所以是相对的,而非绝对不可更改。
二、数据仓库系统体系结构
数据源->ETL->数据仓库存储与管理->OLAP->BI工具
- 数据源:通常包括各种业务系统数据、日志数据、外部数据;
- ETL(extract/transformation/load):整合数据并将它们装入数据仓库的过程。将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将分散、零乱、标准不统一的数据整合到一起,为决策提供分析的依据;
- 数据的存储与管理:数据的存储和管理是整个数据仓库的关键。数据仓库的组织管理方式决定了它有别于传统数据库,同时也决定了其对外部数据的表现形式。数据仓库按照数据的覆盖范围可以分为企业级数据仓库和部门级数据仓库(通常称为数据集市);
- OLAP(On-Line Analysis Processing):从数据仓库中抽取详细数据的一个子集并经过必要的聚集存储到OLAP存储器中供前端分析工具读取。OLAP系统按照数据存储格式可以分为关系OLAP(RelationalOLAP,简称ROLAP)、多维OLAP(MultidimensionalOLAP,简称MOLAP)和混合型OLAP(HybridOLAP,简称HOLAP)三种类型;
- 前端工具:查询工具、数据分析工具、数据挖掘工具、种报表工具等。
三、数仓建模
维度建模5步骤
维度建模从分析决策的需求出发构建模型,为分析需求服务,因此 它重点关注用户如何更快速地完成需求分析,同时具有较好的大规模复 杂查询的响应性能。其典型的代表是星形模型,以及在一些特殊场景下 使用的雪花模型。其设计分为以下几个步骤。
- 选择需要进行分析决策的业务过程。
业务过程可以是单个业务事件,比如交易的支付、退款等;也可以是某个事件的状态,比如当前的账户余额等;还可以是一系列相关业务事件组成的业务流程,具体需要看我们分析的是某些事件发生情况,还是当前状态, 或是事件流转效率。 - 选择粒度。
在事件分析中,我们要预判所有分析需要细分的程度,从而决定选择的粒度。粒度是维度的 一个组合。值得注意的是,在一个事实表中不要混用多种不同的粒度。 - 识别维表。
选择好粒度之后,就需要基于此粒度设计维表,包括维度属性,用于分析时进行分组和筛选。从who、what、when、where、why、how等方面描述。 - 选择事实。
确定分析需要衡量的指标 。比如子订单商品的数量、金额等等。 - 冗余维度
)

网页读取电子秤数据——仙盟创梦IDE)






(错误日志实现))

)





与arm-linux-gcc、ARMGCC、ICCARM(IAR)、C51编译器的兼容性)

