

🔥个人主页: 中草药
🔥专栏:【Java】登神长阶 史诗般的Java成神之路
概念
性能测试是软件测试的重要分支,核心目标是通过模拟真实业务场景和负载压力,评估系统在不同条件下的性能表现,发现系统性能问题,验证其是否满足预期的性能指标(如响应速度、稳定性、并发能力等),并定位性能瓶颈以支撑优化。
关键指标
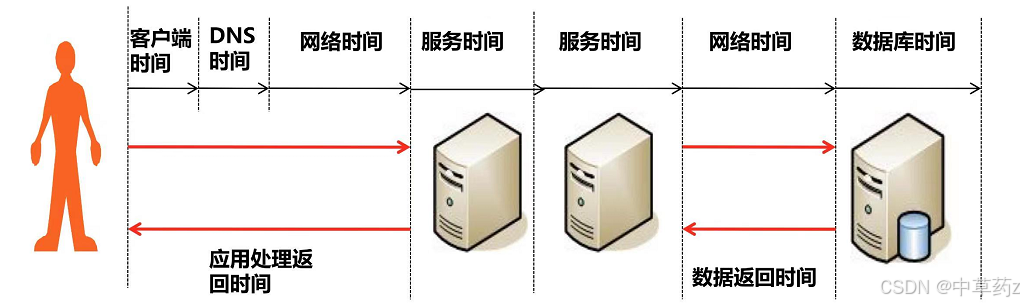
响应时间(Response Time):用户发起请求到系统返回结果的总时间(如接口响应时间、页面加载时间),直接影响用户体验。
对于Web应用而言,系统响应时间包括前端展现时间和系统响应时间
前端展现时间:页面渲染时间
系统响应时间:包括服务器,数据库,通讯网络等响应时间
吞吐量(Throughput):单位时间内系统处理的请求数 / 数据量(如 TPS 每秒事务数、QPS 每秒查询数),直接反映系统负载承受能力。
并发用户数(Concurrent Users):指的是Web服务器在一段时间内处理浏览器请求而建立http连接数或生成的处理线程数(注意:非 “在线用户数”,而是实际操作的活跃用户)。
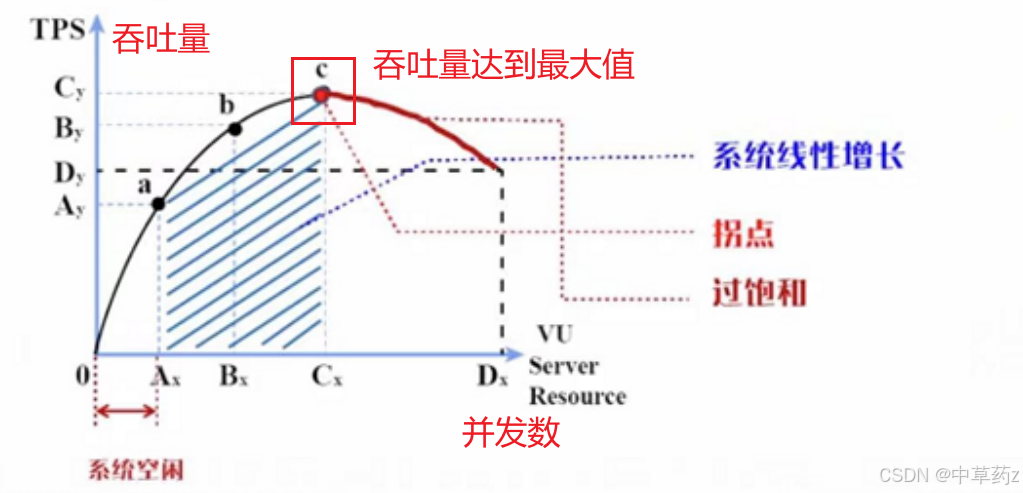
资源利用率:CPU、内存、磁盘 I/O、网络带宽等服务器资源的占用率,过高会导致性能下降。
稳定性:系统在长时间高负载下是否持续正常运行(无崩溃、无内存泄漏、响应时间稳定)。
TPS:每秒处理事务数,用于衡量系统在一定时间内能够处理的事务数
计算公式:总的事务数/总的运行时间
举例 1:某一系统 1 分钟处理 1000 个业务,那么 TPS = 1000 / 60 = 16.7
举例 2:2022 年最高的一天有 10 万笔交易,预测 2023 年 TPS 需要多少合格?认为每笔交易就是一个事务,理论 TPS = 100000 / 24*60*60 = 1.2(理想状态),然而实际上订单量会在某段时间内突然增加,并不是平均到每个时间段内,因此
1)没有更详细的数据:根据二八定律(80% 的事务在 20% 的时间内完成)
TPS = 100000 * 0.8 / 24*60*60*0.2 = 4.6
2)如果有详细的数据:5 万笔交易在晚上的 8~9 点完成的
TPS = 50000 / 60*60 = 13.9(实际还要参考往年业务的增长,假设每年业务增长 30%,则 TPS = 50000 + 50000*0.3 / 60*60 = 18)
QPS:每秒查询率,若一个事务中只有一个接口且是查询接口,则QPS=TPS
测试分类
| 测试类型 | 核心目的 | 典型场景举例 |
|---|---|---|
| 基准测试 | 又称单用户测试,在标准环境下执行特定场景,获取性能基准值(如响应时间、吞吐量),作为后续优化或版本对比的参考。 | 新功能上线前,测试核心支付接口在 50 并发下的平均响应时间,建立性能基线。 |
| 并发测试 | 模拟多个用户同时发起相同 / 不同操作,验证系统在并发场景下的资源竞争、数据一致性表现。 | 100 个用户同时抢购同一件限量商品,测试订单数据是否准确无重复。 |
| 负载测试 | 逐步增加负载(如用户数、请求量),观察性能指标变化,找到 “正常负载下的性能阈值”。 | 电商日常促销时,验证系统在 1000 并发用户下是否稳定。 |
| 压力测试 | 超过预期负载持续加压,找到系统 “极限瓶颈”(如崩溃、响应超时的临界点)。 | 模拟 2000 并发用户访问,测试系统最大承载能力。 |
| 耐久性测试 | 在预期负载下长时间运行(几小时到几天),验证系统稳定性(是否内存泄漏、资源耗尽)。 | 核心交易系统连续 72 小时运行,监控资源是否持续增长。 |
| 尖峰测试 | 突发高负载冲击(如瞬间用户数暴涨),验证系统抗突发能力。 | 秒杀活动开始瞬间,10 秒内用户从 100 突增至 5000。 |
| 配置测试 | 调整系统配置(如服务器数量、JVM 参数、数据库连接池),找到最优配置方案。 | 测试 “2 核 4G” vs “4 核 8G” 服务器的性能差异。 |
| 容量测试 | 验证系统在数据量增长下的性能(如数据库数据量从 10 万到 1000 万时的响应变化)。 | 社交平台用户数据达 1 亿时,好友列表查询是否延迟。 |
Jmeter
JMeter 是 Apache 基金会开发的一款开源性能测试工具,主要用于模拟多用户并发场景,测试软件(如 Web 应用、API、数据库等)的性能指标(如响应时间、吞吐量、并发能力等),广泛应用于负载测试、压力测试、接口测试等场景。它支持多种协议,操作灵活且扩展性强,是性能测试领域的主流工具之一。
核心组件
jmeter有着很多非常核心的组件,其中JMeter元件的作用域主要由测试计划的树形结构中的元件父子关系来确定

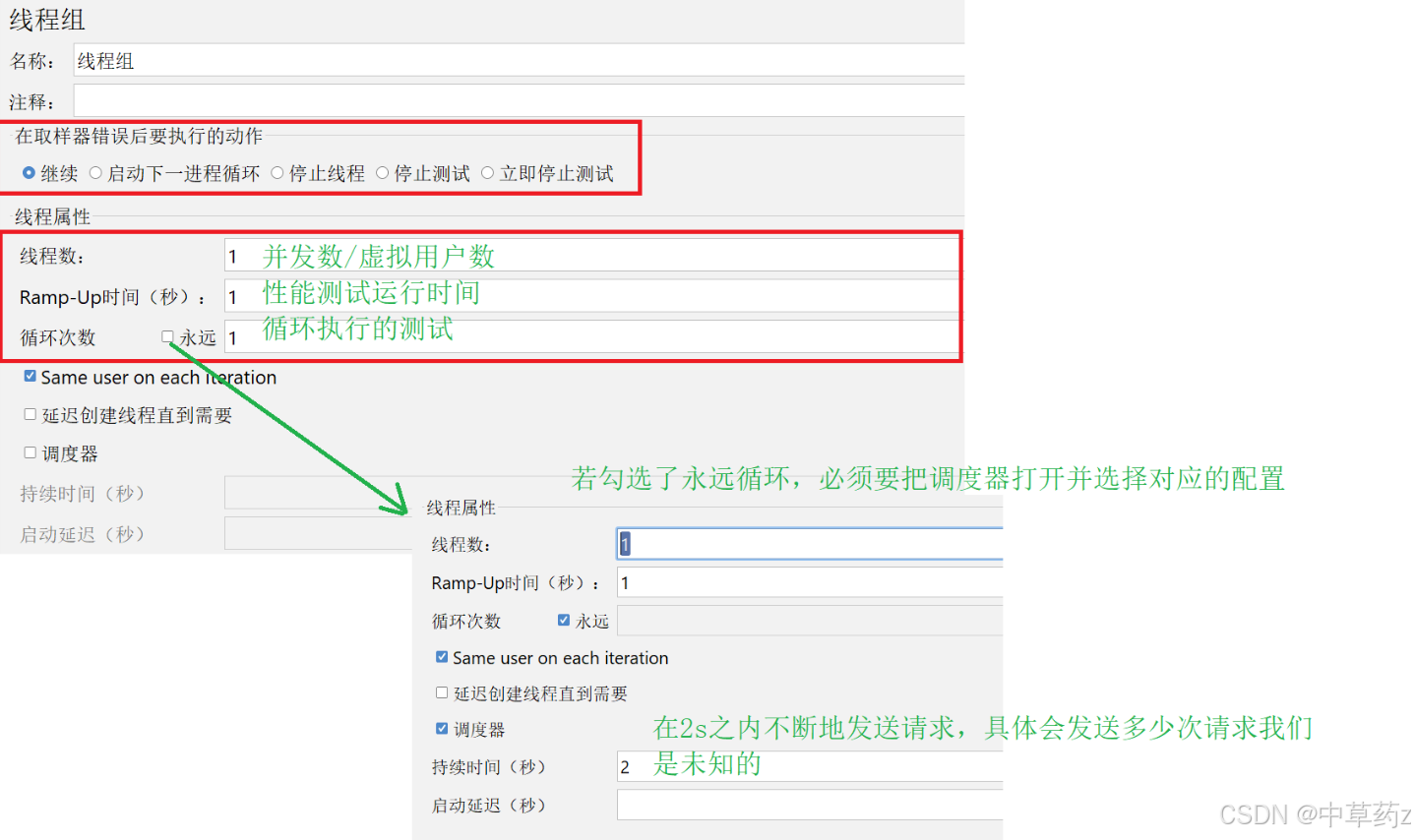
线程组(Thread Group)
性能测试的 “负载发生器”,定义并发用户数、测试持续时间、用户启动速度等。
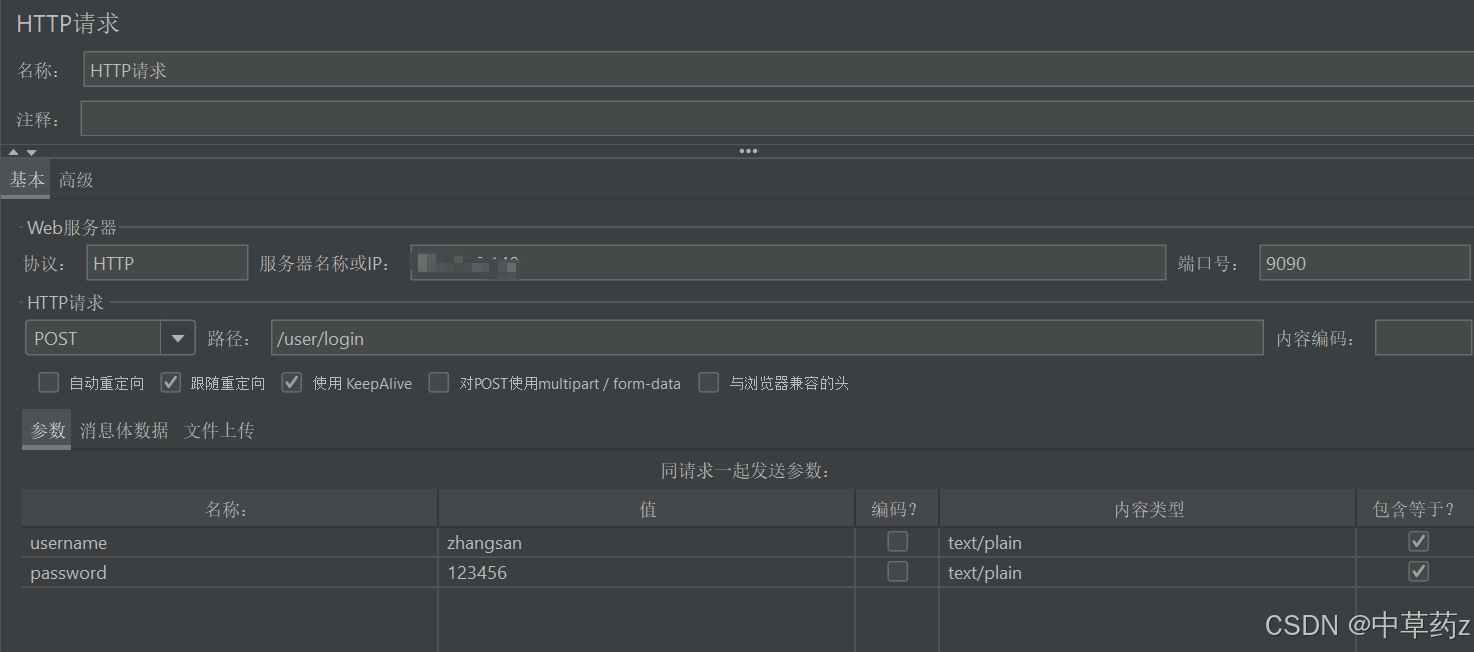
取样器(Sampler)
模拟用户具体操作,向目标系统发送请求(如 HTTP 请求、数据库查询)。比如HTTP请求取样器
监听器(Listener)
收集并展示测试结果,支持实时查看或事后分析。比如结果树
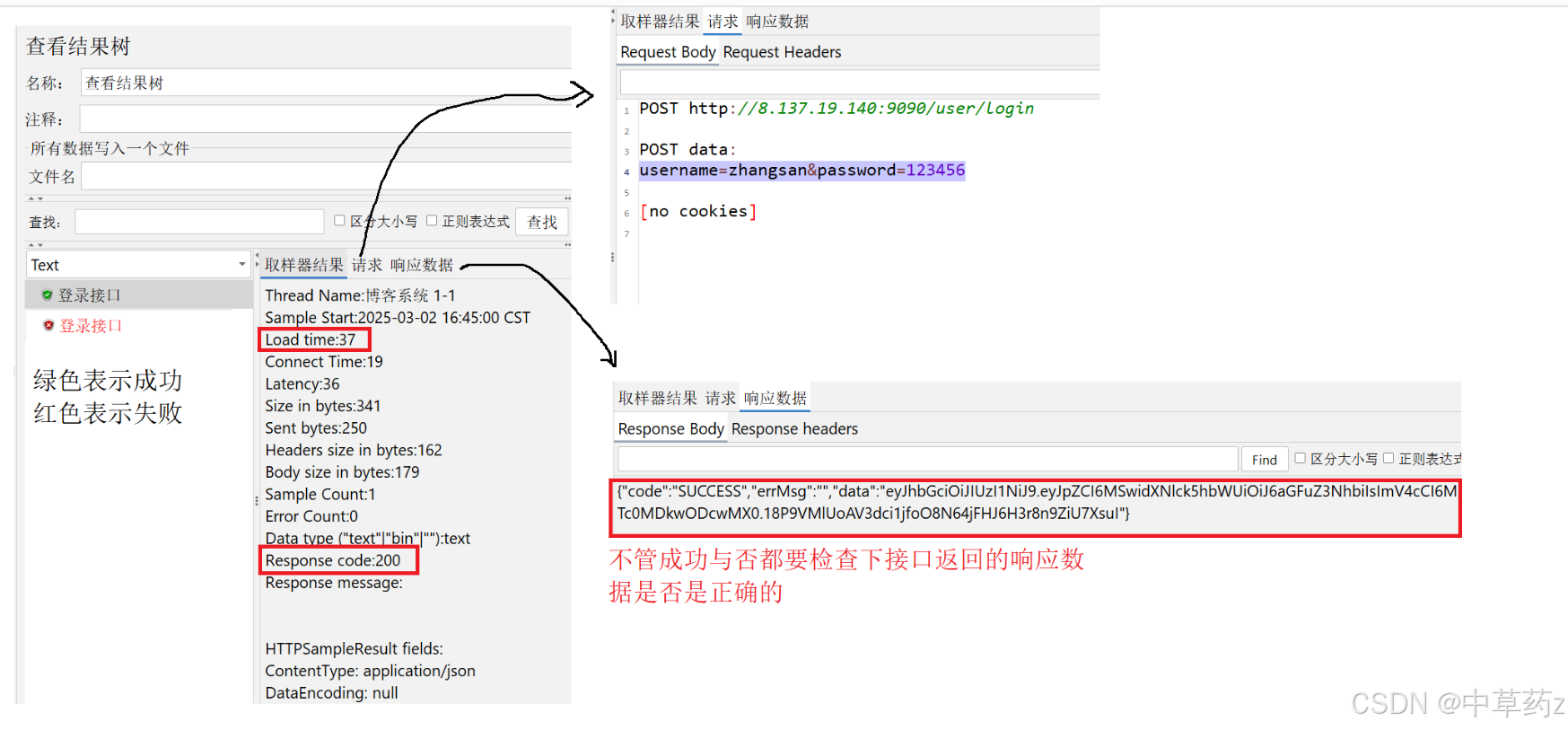
配置元件(Config Element)
为取样器提供默认配置(如请求头、数据库连接信息),减少重复设置。比如
HTTP请求默认值
用户定义的变量
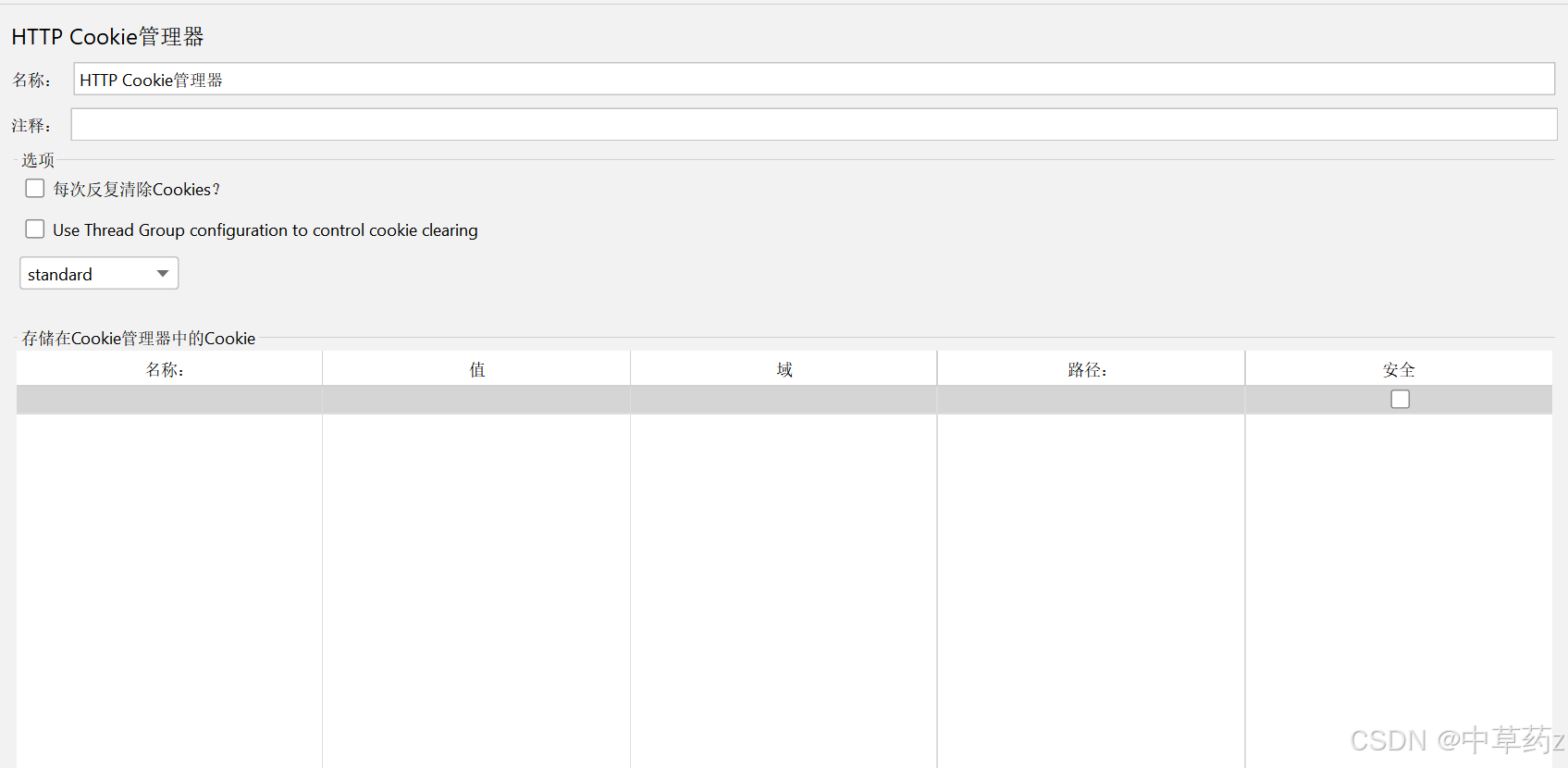
HTTP Cookie管理器
自动存储 Cookie:当服务器通过Set-Cookie响应头返回 Cookie 时,Cookie 管理器会自动捕获并保存这些 Cookie(包括名称、值、域名、路径、过期时间等属性)。
自动发送 Cookie:后续向同一服务器发送请求时,Cookie 管理器会根据 Cookie 的域名、路径规则,自动将匹配的 Cookie 通过Cookie请求头携带到请求中,模拟浏览器 “记住会话状态” 的行为。
前置 / 后置处理器(Pre/Post Processor)
处理请求前的参数(如动态获取 token)或响应后的结果(如提取返回值供后续请求使用)。比如后置处理器 Json提取器
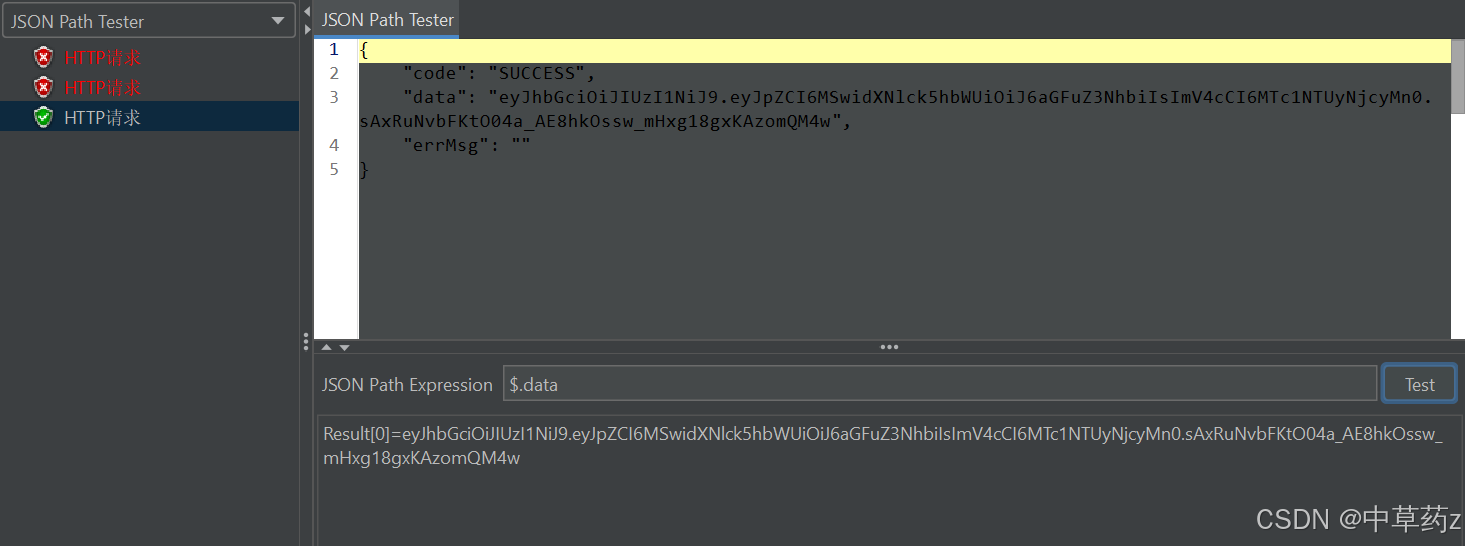
| 操作符 | 作用说明 | 语法示例 | 说明(结合 JSON 示例) |
|---|---|---|---|
$ | 表示 JSON 数据的 根节点,所有路径均从根节点开始。 | $.name | 从根节点开始,提取 name 字段的值。 |
. | 访问当前节点的 子节点(直接子节点)。 | $.user.name | 访问根节点下 user 子节点的 name 字段(适用于嵌套结构)。 |
.. | 递归匹配所有 子孙节点(跨层级查找,不局限于直接子节点)。 | $..email | 递归查找所有层级中名为 email 的字段,无论其在嵌套结构的第几层。 |
* | 通配符,匹配 所有子节点 或 数组元素。 | $.users[*].age | 匹配 users 数组中所有元素的 age 字段,提取所有用户的年龄。 |
[] | 访问数组元素,支持索引、范围或过滤。 | $.users[0]$.users[1:3] | - [0] 提取数组第 1 个元素(索引从 0 开始);- [1:3] 提取数组索引 1 到 2 的元素(左闭右开)。 |
?() | 过滤数组元素,通过条件表达式筛选符合条件的节点。 | $.users[?(@.age > 18)].name | 从 users 数组中筛选出 age > 18 的元素,提取其 name 字段。 |
@ | 在过滤表达式 ?() 中,代表 当前节点(用于引用当前元素的属性)。 | $.users[?(@.name == 'Alice')].id | @ 指代 users 数组中的每个元素,筛选 name 为 Alice 的元素,提取其 id。 |
['字段名'] | 通过属性名访问子节点(与 . 作用类似,支持特殊字符字段名,如含空格的字段)。 | $.user['full name'] | 访问 user 节点下名为 full name 的字段(字段名含空格时必须用此语法)。 |
length() | 数组长度函数,返回数组的元素数量(需配合过滤或数组操作)。 | $.users.length() | 返回 users 数组的长度(即用户总数)。 |
举例,我们有以下Json数据
{"name": "JMeter","user": {"id": 1001,"full name": "Test User","email": "test@example.com"},"users": [{"name": "Alice", "age": 20, "id": 1},{"name": "Bob", "age": 17, "id": 2},{"name": "Charlie", "age": 25, "id": 3}]
}$.name→ 提取结果:"JMeter"$.user.email→ 提取结果:"test@example.com"$..age→ 提取结果:[20, 17, 25](递归找到所有age字段)$.users[*].name→ 提取结果:["Alice", "Bob", "Charlie"]$.users[?(@.age > 18)].name→ 提取结果:["Alice", "Charlie"]$.users.length()→ 提取结果:3(数组长度为 3)
Json断言
接口发送请求成功,并不完全意味着接口请求成功,我们更多的需要关注接口响应数据是否符合预期,JSON 断言的核心是JSON Path 表达式(类似 XML 的 XPath,用于定位 JSON 中的元素)。通过 JSON Path 定位到目标字段后,断言会对比该字段的实际值与预设的 “预期值”,判断是否匹配。
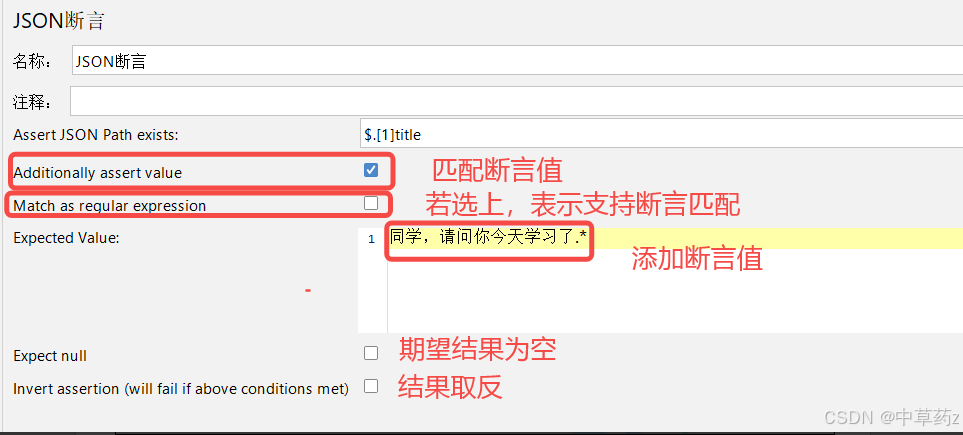
若不选Additionally assert value,表示添加断言值,则可用来判断字段是否存在
若选择Match as regularexpression正则匹配,则Expected Value可以仅写上部分关键词即可断
言成功
CSV数据文件设置
CSV数据文件设置辅助我们去模拟更真实的用户环境
CSV 数据文件(Comma-Separated Values,逗号分隔值文件)是一种纯文本格式的表格数据存储文件,主要用于存储结构化数据(如电子表格、数据库表等),并实现不同系统、工具之间的数据交换。
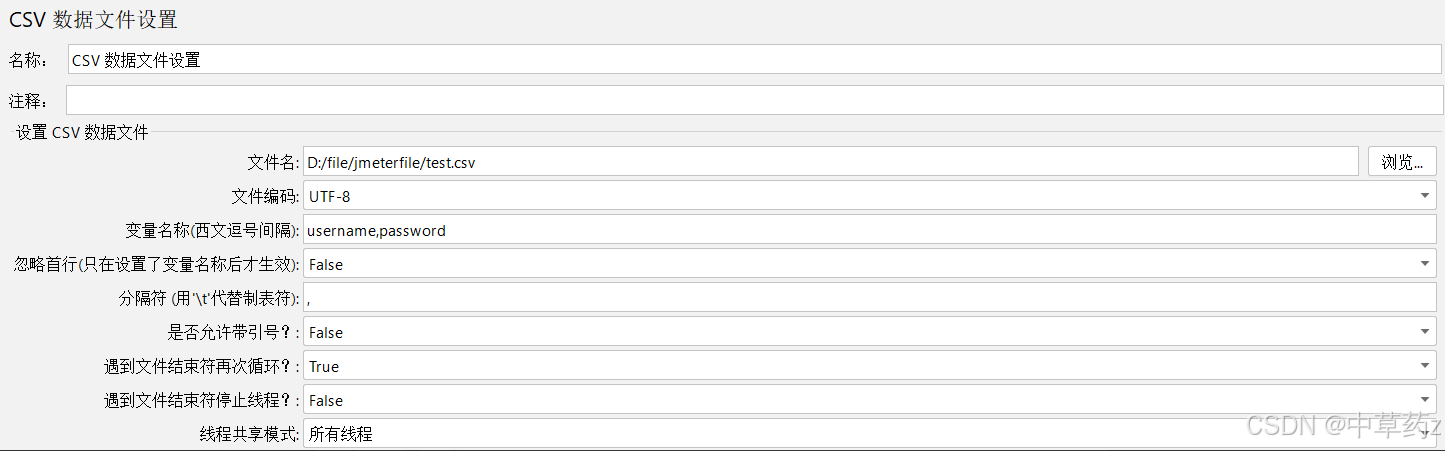
- 文件名:填写csv文件的路径。建议使用绝对路径。
- 文件编码:UTF-8
- 变量名称:从csv数据文件中读起的数据需要保存到的变量名。有多个变量时用逗号分隔
- 是否忽略首行:是否从csv数据文件第一行开始读取。
- 分隔符:要求与csv数据文件中多列的分隔符一致
- 遇到文件结束符再次循环:若选择为True当数据不够的时候会从头取。若选择False,则需要勾选下面的配置,遇到文件结束符停止线程,这里如果不勾选,请求将会报错。
定时器(Timer)
控制请求发送的间隔(如模拟用户思考时间),避免请求无间隔发送(非真实场景)。
为了达到并发的效果,我们需要添加同步定时器(集合点)
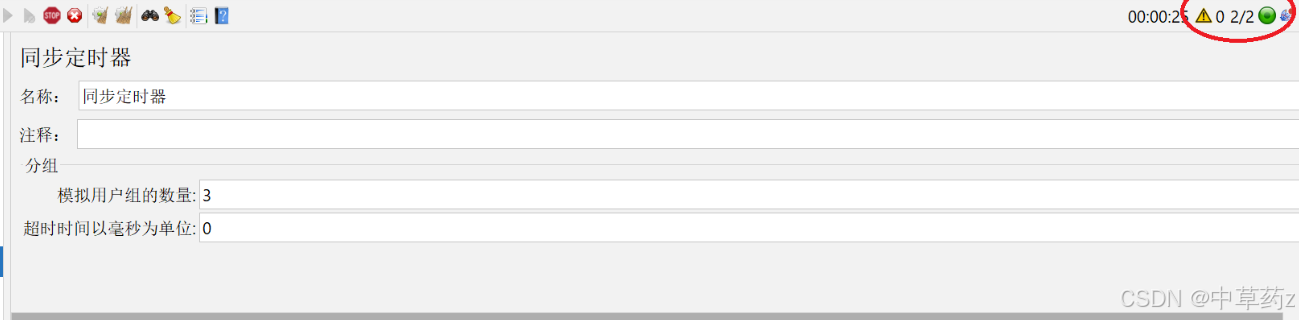
模拟用户组的数量(Number of simulated users to group by):
设定 “同时释放的用户数”(即并发阈值)。例如设为 100,表示当有 100 个用户被阻塞时,同时释放这 100 个用户执行后续操作。
超时时间(Timeout in milliseconds):
若超过该时间仍未达到 “用户组数量”,则无论当前阻塞多少用户,都会强制释放(避免无限等待)。例如设为 5000(5 秒),若 5 秒内只有 80 个用户到达,则释放这 80 个用户。
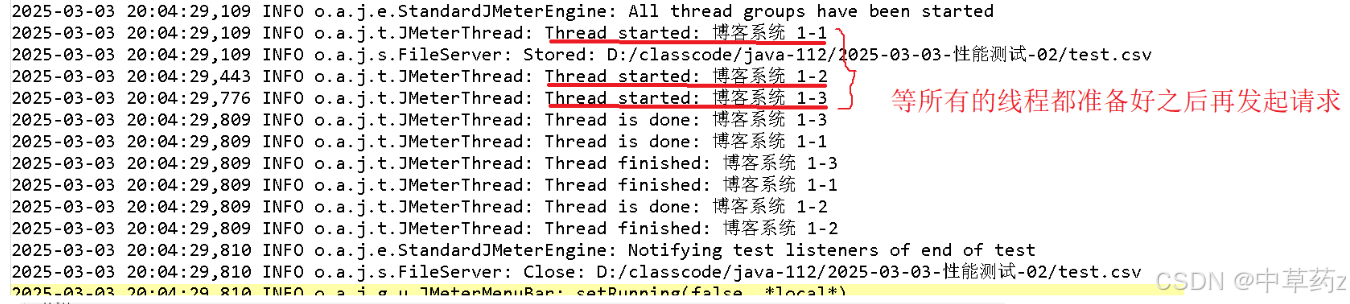
配置后的日志如下:
事务控制器
将一系列连续的操作(如请求、逻辑控制器等)“打包” 为一个 “事务”,用于统计该事务的整体响应时间、成功率等指标,更贴合真实业务场景中 “用户完成一个完整操作” 的概念。
压力测试
环境准备
1、先下载插件管理
Install :: JMeter-Plugins.org
并将插件添加至jmeter下的lib/ext文件夹下
安装成功右上角会出现一个蝴蝶的logo
2、下载所需插件,分别下载
监听器插件 Page Data Extractor
线程组插件
Custom Thread Groups
3 Basic Graphs
梯度压测线程组 Stepping Thread Group
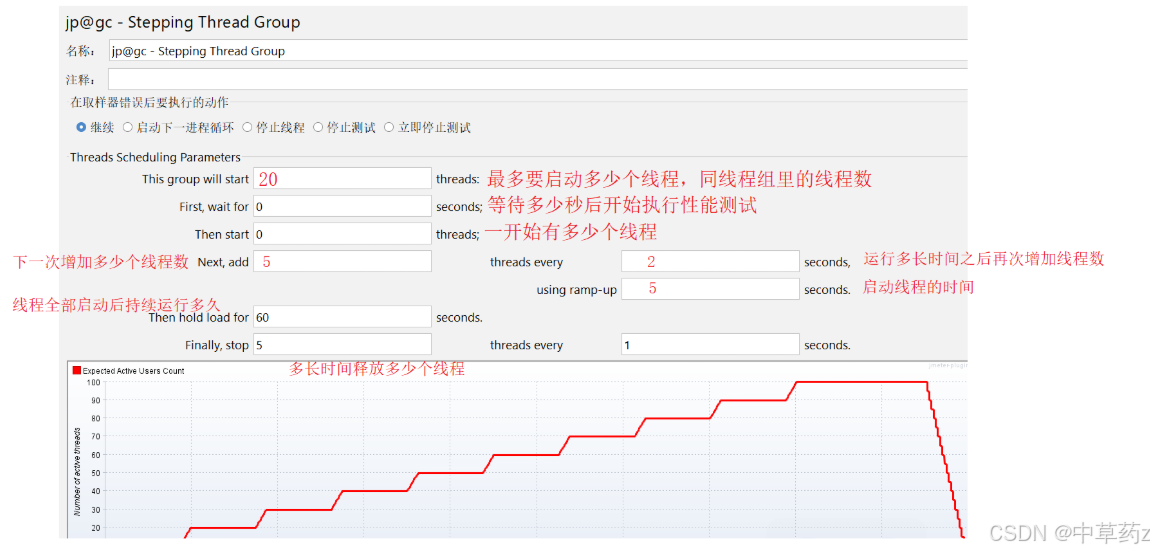
添加监听器-汇总报告,聚合报告,Response Times Over Time,Transaction pet second
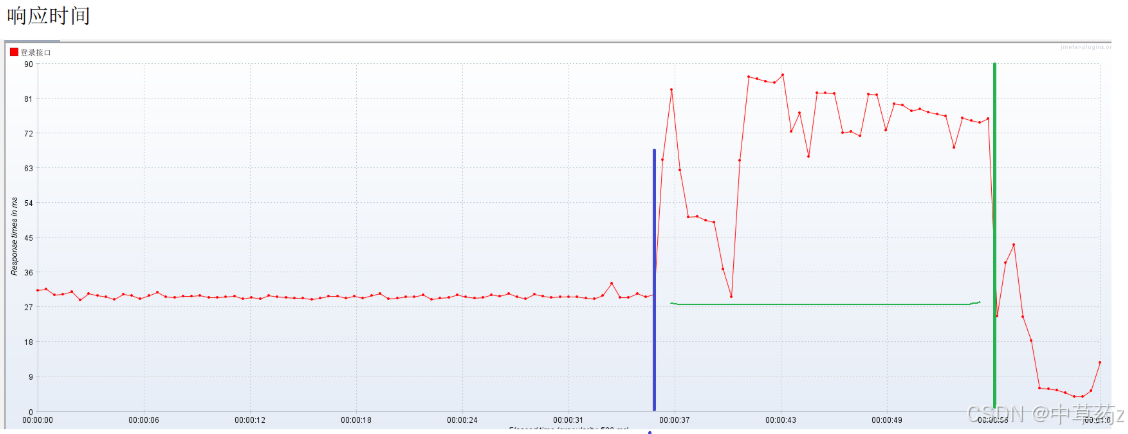
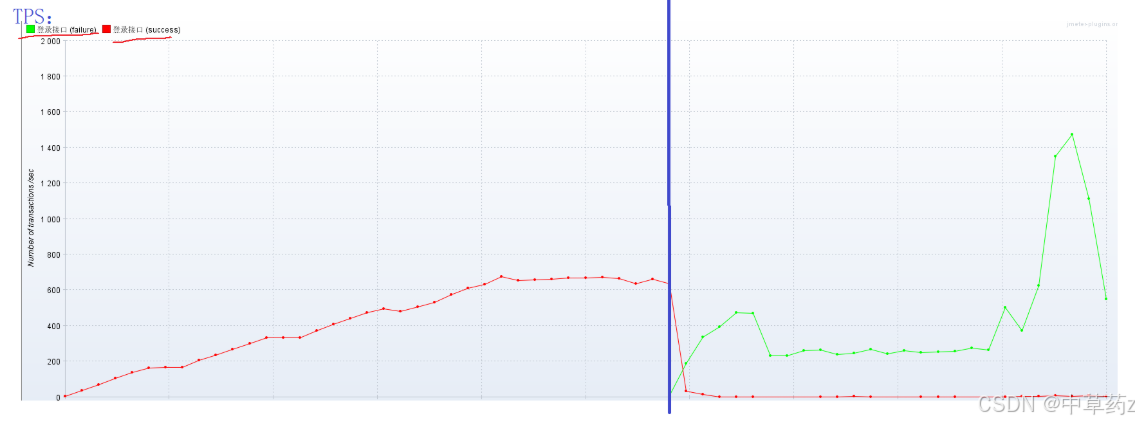
我们可以系统日志去更加详尽的分析此次测试过程
jmeter -n -t 脚本文件 -l 日志文件 -e -0 目录
-n 无图形化运行
-t 被运行的脚本
-l 将运行信息写入日志文件,后缀为jtl的日志文件
-e 生成测试报告
-o 指定报告输出目录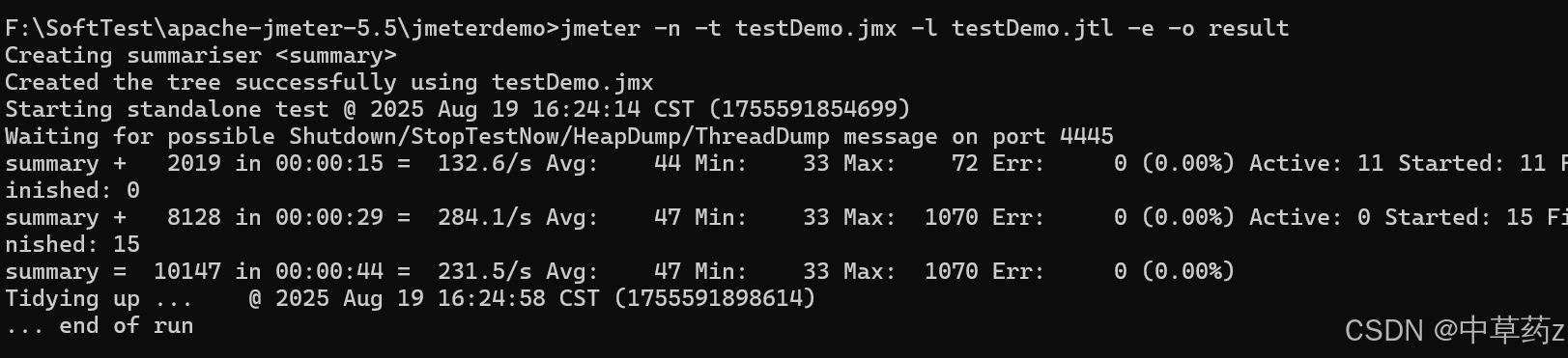
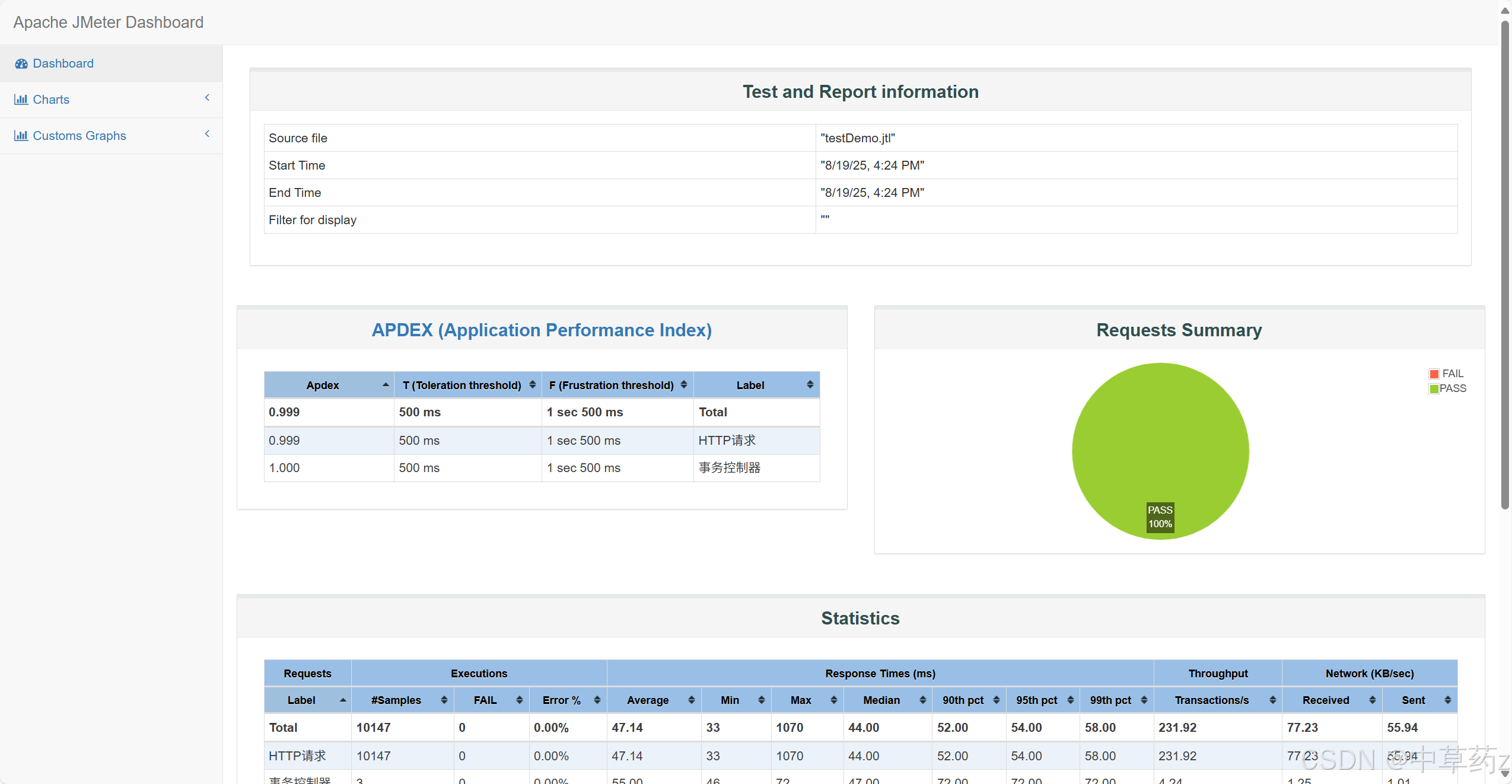
性能分析
可以通过三大性能指标去分析性能问题
响应时间
如果响应时间超过了要求,代表系统遇到了瓶颈,注意分析多少线程的情况下发生了超标,响应时间变化会受到系统稳定性影响,随着系统并发压力变大,响应时间会变高
吞吐量
吞吐量越大,性能越好;吞吐量相对稳定或者变低,可能系统达到了性能瓶颈
变化规律:
波动很大:代表系统性能不稳定
慢慢变高,再趋于稳定:和并发量强相关。如果并发量小于吞吐量,慢慢增大并发量,吞吐量也会随之增加
慢慢变低,并发量也减少了:要么说明性能测试要结束了,并发减少;也可能是系统变的卡顿,从而导致响应时间变慢,导致单个线程发起的并发量变少
错误率(Error Rate):异常请求数占总请求数的比例(单位:%),反映系统 “稳定性和容错能力”。错误类型包括 5xx(服务器错误,如超时、OOM)、4xx(客户端错误,如参数错误、权限不足)等。
一般要求可靠的成功率在99.9999%
错误率高的原因:
接口请求错误
服务器无法继续处理,达到了性能瓶颈(业务逻辑有问题,内存泄漏,硬件资源等等)
后端系统限流(系统配置了最大并发数的限制)实现了熔断,降级
熔断:防止系统因某个服务的故障而整体崩溃。当电商平台上用户支付时,收银台发现某个支付渠如微信支付失败率突增,超时严重,那么就可以临时把这个支付方式熔断掉道
降级:主动关闭一些非核心功能,以确保核心功能的正常运行。某次腾讯视频挂了的时候,用户名称默认显示腾讯用户,:这也是一种降级方式,用兜底名称做展示
在自己身上,克服这个时代。 ——尼采
🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀
以上,就是本期的全部内容啦,若有错误疏忽希望各位大佬及时指出💐
制作不易,希望能对各位提供微小的帮助,可否留下你免费的赞呢🌸

-sql约束/建表)

负载均衡集群介绍)

)



--基础知识点)
)




)


)
