目录
- 引子
- 自定义 Agent
- CountDownAgent
- ArithmeticAgent
- 在自定义 Agent 中使用自定义模型客户端
- 让自定义 Agent 声明式化
- Selector Group Chat
- 示例:网页搜索 / 数据分析
- 代理(Agents)
- Workflow
- 终止条件(Termination Conditions)
- 选择器提示词(Selector Prompt)
- 运行Team(Running the Team)
- 自定义选择器函数(Custom Selector Function)
- 自定义候选函数
- 用户反馈
- 使用推理模型
- Swarm
- 客服示例
- 工作流程
- 工具
- 代理
- 终止条件
- 运行逻辑
- 示例对话
- 股票研究示例
- 工作流程
- 工具
- Magentic-One
- 示例 1:使用 MagenticOneGroupChat
- 示例 2:在团队中使用 Magentic-One 智能体
- 示例 3:使用 MagenticOne 辅助类(打包所有智能体)
- Magentic-One 的本质
- 他和我们自己构建的多agent Team有什么区别?
- GraphFlow
- 创建并运行 Flow
- 顺序流
- 并行流
- 执行图 vs 消息图
- 🔁 高级货:条件循环 + 过滤总结
- 🔁 **高级货:带激活组的循环**
- 示例 1:多路径循环 —— “All” 激活 (A→B→C→B)
- 示例 2:多路径循环 —— “Any” 激活 (A→B→(C1,C2)→B)
- 示例 3:混合激活组
- 记忆与 RAG
- ListMemory 示例
- 自定义记忆存储(向量数据库等)
- Redis Memory
- RAG Agent: 综合应用
- 构建一个简单的 RAG Agent
- Mem0Memory 示例
- 日志记录
- 序列化组件
- 终止条件示例
- 代理示例
- 团队示例
- 跟踪与可观测性 (Tracing and Observability)
- 环境设置
- Telemetry Backend
- 跟踪 AgentChat 团队
- 扩展
- 结尾
引子
在上一章《AutoGen 快速入门》中,我们已经体验了如何用 AutoGen 快速搭建一个最基础的 Agent 对话流程。 但如果你想真正把 AutoGen 用到实际项目里,你会很快发现:默认的 Agent 能力有限,想要更智能、更贴合业务,就必须走向自定义 Agent。
自定义 Agent 是 AutoGen 的“进阶玩法”。它让你能够突破框架的预设边界,定义 Agent 的角色、行为逻辑、记忆方式,甚至与外部系统的交互方式。换句话说,这一步才是真正把 AutoGen 从“好玩”变成“好用”的关键。
自定义 Agent
有些场景下,Agent 的行为并不属于框架内置的预设类型。这时,你就需要自己构建 自定义 Agent。
在 AgentChat 中,所有的 Agent 都继承自 BaseChatAgent 类,并需要实现以下抽象方法和属性:
- on_messages():抽象方法,用来定义 Agent 在接收到消息时的响应逻辑。当
run()调用时,这个方法会被触发,并返回一个Response对象。 - on_reset():抽象方法,用来将 Agent 重置为初始状态。当需要 Agent 自我重置时调用。
- produced_message_types:该属性定义了 Agent 在响应中可能生成的
BaseChatMessage消息类型列表。
此外,你也可以选择性地实现 on_messages_stream() 方法,用来在消息生成过程中以流的方式输出内容。该方法由 run_stream() 调用。如果没有实现,Agent 会使用默认实现:即调用 on_messages() 并将结果中的所有消息依次输出。
CountDownAgent
下面的示例演示了如何创建一个简单的 Agent,它会从给定数字倒数到 0,并在过程中逐步输出当前计数:
from typing import AsyncGenerator, List, Sequencefrom autogen_agentchat.agents import BaseChatAgent
from autogen_agentchat.base import Response
from autogen_agentchat.messages import BaseAgentEvent, BaseChatMessage, TextMessage
from autogen_core import CancellationTokenclass CountDownAgent(BaseChatAgent):def __init__(self, name: str, count: int = 3):super().__init__(name, "A simple agent that counts down.")self._count = count@propertydef produced_message_types(self) -> Sequence[type[BaseChatMessage]]:return (TextMessage,)async def on_messages(self, messages: Sequence[BaseChatMessage], cancellation_token: CancellationToken) -> Response:# 调用 on_messages_streamresponse: Response | None = Noneasync for message in self.on_messages_stream(messages, cancellation_token):if isinstance(message, Response):response = messageassert response is not Nonereturn responseasync def on_messages_stream(self, messages: Sequence[BaseChatMessage], cancellation_token: CancellationToken) -> AsyncGenerator[BaseAgentEvent | BaseChatMessage | Response, None]:inner_messages: List[BaseAgentEvent | BaseChatMessage] = []for i in range(self._count, 0, -1):msg = TextMessage(content=f"{i}...", source=self.name)inner_messages.append(msg)yield msg# 在流的最后返回 Responseyield Response(chat_message=TextMessage(content="Done!", source=self.name), inner_messages=inner_messages)async def on_reset(self, cancellation_token: CancellationToken) -> None:passasync def run_countdown_agent() -> None:# 创建倒计时 Agentcountdown_agent = CountDownAgent("countdown")# 运行 Agent 并以流方式输出结果async for message in countdown_agent.on_messages_stream([], CancellationToken()):if isinstance(message, Response):print(message.chat_message)else:print(message)# 在脚本中运行时使用:
# asyncio.run(run_countdown_agent())await run_countdown_agent()
输出结果:
3...
2...
1...
Done!
在 CountDownAgent 的例子里,有两个容易混淆的点:
-
流式消息 (
yield msg)- 在
on_messages_stream里,for i in range...每次都会生成一个TextMessage(例如"3..."、"2...")。 - 这些消息通过
yield的方式被即时返回,类似“逐条输出”,因此你在运行时能看到倒计时的过程。
- 在
-
最终的 Response 对象
-
在循环结束后,Agent 会
yield Response(...)。 -
Response本质上是对这次对话的“最终产物”,它通常包含:- 一个主要的
chat_message(这里是"Done!"), - 以及一个
inner_messages列表(这里存放了所有"3..." → "2..." → "1..."的中间消息)。
- 一个主要的
-
-
是否保存为上下文?
- 框架并不会自动把
inner_messages存进长期内存或上下文(不像 LangChain 那样会有 Memory 管理对话历史)。 Response里的inner_messages更像是一次调用内的本地记录:它把这次流式生成过程中产生的所有消息都打包进来,方便调用者在需要时统一处理。- 如果你希望这些消息能“成为上下文”,需要在外部自己决定是否存储(比如把
inner_messagesappend 到对话历史,再在下一次run()时传入)。
- 框架并不会自动把
ArithmeticAgent
在这个示例中,我们将创建一个 ArithmeticAgent(算术代理)类,它可以对给定的整数执行简单的算术运算。随后,我们会在 SelectorGroupChat 中使用该类的不同实例,通过一系列算术操作,把一个整数转换为另一个整数。
ArithmeticAgent 类接收一个 operator_func,该函数接受一个整数,并在应用算术运算后返回一个整数。在 on_messages 方法中,Agent 会对输入消息中的整数应用 operator_func,并返回包含结果的响应。
from typing import Callable, Sequencefrom autogen_agentchat.agents import BaseChatAgent
from autogen_agentchat.base import Response
from autogen_agentchat.conditions import MaxMessageTermination
from autogen_agentchat.messages import BaseChatMessage, TextMessage
from autogen_agentchat.teams import SelectorGroupChat
from autogen_agentchat.ui import Console
from autogen_core import CancellationToken
from autogen_ext.models.openai import OpenAIChatCompletionClientclass ArithmeticAgent(BaseChatAgent):def __init__(self, name: str, description: str, operator_func: Callable[[int], int]) -> None:super().__init__(name, description=description)self._operator_func = operator_funcself._message_history: List[BaseChatMessage] = []@propertydef produced_message_types(self) -> Sequence[type[BaseChatMessage]]:return (TextMessage,)async def on_messages(self, messages: Sequence[BaseChatMessage], cancellation_token: CancellationToken) -> Response:# 更新消息历史# 注意:messages 可能为空,表示 Agent 曾经被选中过,现在再次被调用,但调用者没有提供新消息self._message_history.extend(messages)# 解析最后一条消息中的数字assert isinstance(self._message_history[-1], TextMessage)number = int(self._message_history[-1].content)# 对数字应用算术运算result = self._operator_func(number)# 构造结果消息response_message = TextMessage(content=str(result), source=self.name)# 更新历史self._message_history.append(response_message)# 返回 Responsereturn Response(chat_message=response_message)async def on_reset(self, cancellation_token: CancellationToken) -> None:pass
📌 注意
on_messages 方法可能会在 messages 为空时被调用。这种情况意味着该 Agent 曾经被调用过,现在再次被选中,但这次调用并没有收到新的外部输入。因此,维护一个 消息历史是非常重要的:Agent 需要依赖已有的历史来生成新的响应。
我们接下来创建一个包含 5 个 ArithmeticAgent 实例的 SelectorGroupChat:
- 一个将输入整数加 1;
- 一个将输入整数减 1;
- 一个将输入整数乘以 2;
- 一个将输入整数除以 2 并向下取整;
- 一个保持整数不变。
然后,我们通过 SelectorGroupChat 把这些 Agent 组织起来,并设置选择器参数:
- 允许同一个 Agent 连续被选中(以便进行重复操作);
- 自定义选择器提示词,让模型在做角色选择时更贴合当前任务。
async def run_number_agents() -> None:# 定义 5 个算术 Agentadd_agent = ArithmeticAgent("add_agent", "Adds 1 to the number.", lambda x: x + 1)multiply_agent = ArithmeticAgent("multiply_agent", "Multiplies the number by 2.", lambda x: x * 2)subtract_agent = ArithmeticAgent("subtract_agent", "Subtracts 1 from the number.", lambda x: x - 1)divide_agent = ArithmeticAgent("divide_agent", "Divides the number by 2 and rounds down.", lambda x: x // 2)identity_agent = ArithmeticAgent("identity_agent", "Returns the number as is.", lambda x: x)# 设置终止条件:最多运行 10 条消息termination_condition = MaxMessageTermination(10)# 创建 SelectorGroupChatselector_group_chat = SelectorGroupChat([add_agent, multiply_agent, subtract_agent, divide_agent, identity_agent],model_client=OpenAIChatCompletionClient(model="gpt-4o"),termination_condition=termination_condition,allow_repeated_speaker=True, # 允许同一个 Agent 连续说话selector_prompt=("Available roles:\n{roles}\nTheir job descriptions:\n{participants}\n""Current conversation history:\n{history}\n""Please select the most appropriate role for the next message, and only return the role name."),)# 定义任务:把数字 10 转换成 25task: List[BaseChatMessage] = [TextMessage(content="Apply the operations to turn the given number into 25.", source="user"),TextMessage(content="10", source="user"),]stream = selector_group_chat.run_stream(task=task)await Console(stream)# 在脚本中运行时使用:
# asyncio.run(run_number_agents())await run_number_agents()
输出结果
---------- user ----------
Apply the operations to turn the given number into 25.
---------- user ----------
10
---------- multiply_agent ----------
20
---------- add_agent ----------
21
---------- multiply_agent ----------
42
---------- divide_agent ----------
21
---------- add_agent ----------
22
---------- add_agent ----------
23
---------- add_agent ----------
24
---------- add_agent ----------
25
---------- Summary ----------
Number of messages: 10
Finish reason: Maximum number of messages 10 reached, current message count: 10
Total prompt tokens: 0
Total completion tokens: 0
Duration: 2.40 seconds
从结果可以看到,SelectorGroupChat 通过动态选择不同的 ArithmeticAgent,最终把输入数字 10 转换成了 25,整个过程中智能地调用了不同的算术操作。
这里有两点需要注意:
-
on_messages可能收到空列表的含义这句话的意思是:
- 在 SelectorGroupChat 场景下,多个 Agent 都在等待被调用。
- 当模型选择某个 Agent 执行时,它会调用该 Agent 的
on_messages()。 - 正常情况:会传递一些新消息(比如用户输入的数字
10)。 - 特殊情况:有时调用时传递的
messages=[],即空列表。
👉 为什么会这样?
因为 Agent 可能被重复选中。比如:- 第一次调用时
on_messages(["10"])→ Agent 返回"20"。 - 下一轮,模型又决定还是由同一个 Agent 来执行,但这次没有新的外部输入,所以传进来的就是
[]。 - 这时,Agent 必须依赖自己保存的 历史消息(_message_history) 来继续运算。
换句话说:
messages只包含“新增输入”;- 如果没有新增,就只能靠 Agent 自己维护的
_message_history。 - 所以必须在 Agent 内部保存历史,否则 Agent 在收到空输入时就“失忆”了。
为什么 被选中过的 Agent 再次执行时可能收到空列表:
SelectorGroupChat是一个“调度器”:- 它拿到任务后,每一轮都会调用大模型,让它从候选 Agent 里选一个名字。
- 选中的 Agent 会被执行一次
on_messages()。
messages参数的来源messages表示的是 新传递给 Agent 的消息。- 第一次调用某个 Agent 时,
messages里通常会包含用户的输入(比如"10")。 - 如果下一轮大模型又选择了同一个 Agent,而用户这时没有提供新的输入,那么框架传递的就是 空列表
[]。
👉 简单说:
messages≠ 整个上下文messages只是“新增输入”
为什么要这样设计?
如果每次调用都把完整上下文传给 Agent,历史消息会被一遍遍重复传递,既浪费性能,又让 Agent 难以区分“新输入”和“旧历史”。
所以框架的设计是:
- 只把“新输入”放进
messages - 历史对话需要 Agent 自己保存(比如用
_message_history)
假设任务是“把 10 变成 25”:
-
第一轮
- 模型选择
multiply_agent - 调用:
on_messages([TextMessage("10")]) - 输出:
20
- 模型选择
-
第二轮
- 模型又选择
multiply_agent - 但这次用户没输入新数字
- 调用:
on_messages([])← 空列表 - Agent 必须自己去看
_message_history里最后的结果(20),再继续运算。
- 模型又选择
-
SelectorGroupChat的选择逻辑由大模型驱动在
SelectorGroupChat里,存在多个候选 Agent(加法、减法、乘法、除法、不变)。
每一轮对话时,框架不会用硬编码的规则(比如固定先乘后加),而是把当前对话历史、所有 Agent 的描述、可选角色列表拼接成一个 Prompt,丢给大模型(例如 GPT-4o)。模型的任务是:
- 根据对话历史(例如“要把 10 变成 25”),
- 从所有 Agent 中挑一个最合适的角色,
- 并输出该 Agent 的名字。
这样:
SelectorGroupChat并不自己“决定”,- 选择权在大模型手里,框架只负责执行模型的选择结果。
👉 直观理解:
SelectorGroupChat= 调度器 + 执行器;- 大模型 = 智能“导演”,根据剧情(任务)决定谁上场。
在自定义 Agent 中使用自定义模型客户端
在 AgentChat 的 AssistantAgent 预设中,一个关键特性是它接收 model_client 参数,并可以用它来响应消息。
然而,在某些情况下,你可能希望你的 Agent 使用一个目前不被支持的自定义模型客户端,或者实现一些自定义的模型行为。
你可以通过编写一个实现你自定义模型客户端的 自定义 Agent 来做到这一点。
在下面的示例中,我们将演示一个使用 Google Gemini SDK 来直接响应消息的自定义 Agent。
注意:要运行此示例,你需要先安装 Google Gemini SDK,可以通过以下命令安装:
pip install google-genai
# !pip install google-genai
import os
from typing import AsyncGenerator, Sequencefrom autogen_agentchat.agents import BaseChatAgent
from autogen_agentchat.base import Response
from autogen_agentchat.messages import BaseAgentEvent, BaseChatMessage
from autogen_core import CancellationToken
from autogen_core.model_context import UnboundedChatCompletionContext
from autogen_core.models import AssistantMessage, RequestUsage, UserMessage
from google import genai
from google.genai import types
自定义 Gemini Agent 实现
class GeminiAssistantAgent(BaseChatAgent):def __init__(self,name: str,description: str = "An agent that provides assistance with ability to use tools.",model: str = "gemini-1.5-flash-002",api_key: str = os.environ["GEMINI_API_KEY"],system_message: str| None = "You are a helpful assistant that can respond to messages. Reply with TERMINATE when the task has been completed.",):super().__init__(name=name, description=description)self._model_context = UnboundedChatCompletionContext()self._model_client = genai.Client(api_key=api_key)self._system_message = system_messageself._model = model@propertydef produced_message_types(self) -> Sequence[type[BaseChatMessage]]:return (TextMessage,)async def on_messages(self, messages: Sequence[BaseChatMessage], cancellation_token: CancellationToken) -> Response:final_response = Noneasync for message in self.on_messages_stream(messages, cancellation_token):if isinstance(message, Response):final_response = messageif final_response is None:raise AssertionError("The stream should have returned the final result.")return final_responseasync def on_messages_stream(self, messages: Sequence[BaseChatMessage], cancellation_token: CancellationToken) -> AsyncGenerator[BaseAgentEvent | BaseChatMessage | Response, None]:# 将消息添加到上下文for msg in messages:await self._model_context.add_message(msg.to_model_message())# 获取对话历史history = [(msg.source if hasattr(msg, "source") else "system")+ ": "+ (msg.content if isinstance(msg.content, str) else "")+ "\n"for msg in await self._model_context.get_messages()]# 调用 Gemini 生成回复response = self._model_client.models.generate_content(model=self._model,contents=f"History: {history}\nGiven the history, please provide a response",config=types.GenerateContentConfig(system_instruction=self._system_message,temperature=0.3,),)# 使用元数据usage = RequestUsage(prompt_tokens=response.usage_metadata.prompt_token_count,completion_tokens=response.usage_metadata.candidates_token_count,)# 将响应加入上下文await self._model_context.add_message(AssistantMessage(content=response.text, source=self.name))# 返回最终响应yield Response(chat_message=TextMessage(content=response.text, source=self.name, models_usage=usage),inner_messages=[],)async def on_reset(self, cancellation_token: CancellationToken) -> None:"""重置助手,清空上下文。"""await self._model_context.clear()
使用示例:
gemini_assistant = GeminiAssistantAgent("gemini_assistant")
await Console(gemini_assistant.run_stream(task="What is the capital of New York?"))
输出:
---------- user ----------
What is the capital of New York?
---------- gemini_assistant ----------
Albany
TERMINATE
在上面的示例中,我们选择将 model、api_key 和 system_message 作为参数传入 —— 你可以根据应用需求传入其他任何模型客户端所需的参数。
在 AgentChat 团队中使用自定义 Agent:
from autogen_agentchat.agents import AssistantAgent
from autogen_agentchat.conditions import TextMentionTermination
from autogen_agentchat.teams import RoundRobinGroupChat
from autogen_agentchat.ui import Consolemodel_client = OpenAIChatCompletionClient(model="gpt-4o-mini")# 创建主要 Agent
primary_agent = AssistantAgent("primary",model_client=model_client,system_message="You are a helpful AI assistant.",
)# 基于我们新的 GeminiAssistantAgent 创建一个评审 Agent
gemini_critic_agent = GeminiAssistantAgent("gemini_critic",system_message="Provide constructive feedback. Respond with 'APPROVE' to when your feedbacks are addressed.",
)# 定义终止条件:当评审通过或对话超过 10 条消息时结束
termination = TextMentionTermination("APPROVE") | MaxMessageTermination(10)# 创建一个包含 primary 和 critic 的团队
team = RoundRobinGroupChat([primary_agent, gemini_critic_agent], termination_condition=termination)await Console(team.run_stream(task="Write a Haiku poem with 4 lines about the fall season."))
await model_client.close()
---------- user ----------
Write a Haiku poem with 4 lines about the fall season.
---------- primary ----------
Crimson leaves cascade,
Whispering winds sing of change,
Chill wraps the fading,
Nature's quilt, rich and warm.
---------- gemini_critic ----------
The poem is good, but it has four lines instead of three. A haiku must have three lines with a 5-7-5 syllable structure. The content is evocative of autumn, but the form is incorrect. Please revise to adhere to the haiku's syllable structure.---------- primary ----------
Thank you for your feedback! Here’s a revised haiku that follows the 5-7-5 syllable structure:Crimson leaves drift down,
Chill winds whisper through the gold,
Autumn’s breath is near.
---------- gemini_critic ----------
The revised haiku is much improved. It correctly follows the 5-7-5 syllable structure and maintains the evocative imagery of autumn. APPROVE
TaskResult(messages=[TextMessage(source='user', models_usage=None, content='Write a Haiku poem with 4 lines about the fall season.', type='TextMessage'), TextMessage(source='primary', models_usage=RequestUsage(prompt_tokens=33, completion_tokens=31), content="Crimson leaves cascade, \nWhispering winds sing of change, \nChill wraps the fading, \nNature's quilt, rich and warm.", type='TextMessage'), TextMessage(source='gemini_critic', models_usage=RequestUsage(prompt_tokens=86, completion_tokens=60), content="The poem is good, but it has four lines instead of three. A haiku must have three lines with a 5-7-5 syllable structure. The content is evocative of autumn, but the form is incorrect. Please revise to adhere to the haiku's syllable structure.\n", type='TextMessage'), TextMessage(source='primary', models_usage=RequestUsage(prompt_tokens=141, completion_tokens=49), content='Thank you for your feedback! Here’s a revised haiku that follows the 5-7-5 syllable structure:\n\nCrimson leaves drift down, \nChill winds whisper through the gold, \nAutumn’s breath is near.', type='TextMessage'), TextMessage(source='gemini_critic', models_usage=RequestUsage(prompt_tokens=211, completion_tokens=32), content='The revised haiku is much improved. It correctly follows the 5-7-5 syllable structure and maintains the evocative imagery of autumn. APPROVE\n', type='TextMessage')], stop_reason="Text 'APPROVE' mentioned")
在上面的部分中,我们展示了几个非常重要的概念:
我们开发了一个使用 Google Gemini SDK 来响应消息的自定义代理。
我们展示了该自定义代理可以作为更广泛 AgentChat 生态系统的一部分来使用 —— 在这个例子中,只要它继承自 BaseChatAgent,它就能作为 RoundRobinGroupChat 的一个参与者。
让自定义 Agent 声明式化
Autogen 提供了一个 Component 接口,用于使组件的配置可以序列化为声明式格式。这对于保存和加载配置,以及与他人共享配置非常有用。
我们通过继承 Component 类并实现 _from_config 和 _to_config 方法来实现这一点。声明式类可以使用 dump_component 方法序列化为 JSON 格式,并使用 load_component 方法从 JSON 格式 反序列化。
import os
from typing import AsyncGenerator, Sequencefrom autogen_agentchat.agents import BaseChatAgent
from autogen_agentchat.base import Response
from autogen_agentchat.messages import BaseAgentEvent, BaseChatMessage
from autogen_core import CancellationToken, Component
from pydantic import BaseModel
from typing_extensions import Self
class GeminiAssistantAgentConfig(BaseModel):name: strdescription: str = "An agent that provides assistance with ability to use tools."model: str = "gemini-1.5-flash-002"system_message: str | None = None
class GeminiAssistantAgent(BaseChatAgent, Component[GeminiAssistantAgentConfig]): # type: ignore[no-redef]component_config_schema = GeminiAssistantAgentConfig# component_provider_override = "mypackage.agents.GeminiAssistantAgent"def __init__(self,name: str,description: str = "An agent that provides assistance with ability to use tools.",model: str = "gemini-1.5-flash-002",api_key: str = os.environ["GEMINI_API_KEY"],system_message: str| None = "You are a helpful assistant that can respond to messages. Reply with TERMINATE when the task has been completed.",):super().__init__(name=name, description=description)self._model_context = UnboundedChatCompletionContext()self._model_client = genai.Client(api_key=api_key)self._system_message = system_messageself._model = model@propertydef produced_message_types(self) -> Sequence[type[BaseChatMessage]]:return (TextMessage,)async def on_messages(self, messages: Sequence[BaseChatMessage], cancellation_token: CancellationToken) -> Response:final_response = Noneasync for message in self.on_messages_stream(messages, cancellation_token):if isinstance(message, Response):final_response = messageif final_response is None:raise AssertionError("The stream should have returned the final result.")return final_responseasync def on_messages_stream(self, messages: Sequence[BaseChatMessage], cancellation_token: CancellationToken) -> AsyncGenerator[BaseAgentEvent | BaseChatMessage | Response, None]:# 将消息加入模型上下文for msg in messages:await self._model_context.add_message(msg.to_model_message())# 获取对话历史history = [(msg.source if hasattr(msg, "source") else "system")+ ": "+ (msg.content if isinstance(msg.content, str) else "")+ "\n"for msg in await self._model_context.get_messages()]# 使用 Gemini 生成回复response = self._model_client.models.generate_content(model=self._model,contents=f"History: {history}\nGiven the history, please provide a response",config=types.GenerateContentConfig(system_instruction=self._system_message,temperature=0.3,),)# 创建使用情况元数据usage = RequestUsage(prompt_tokens=response.usage_metadata.prompt_token_count,completion_tokens=response.usage_metadata.candidates_token_count,)# 将回复加入模型上下文await self._model_context.add_message(AssistantMessage(content=response.text, source=self.name))# 返回最终响应yield Response(chat_message=TextMessage(content=response.text, source=self.name, models_usage=usage),inner_messages=[],)async def on_reset(self, cancellation_token: CancellationToken) -> None:"""通过清空模型上下文来重置助手。"""await self._model_context.clear()@classmethoddef _from_config(cls, config: GeminiAssistantAgentConfig) -> Self:return cls(name=config.name, description=config.description, model=config.model, system_message=config.system_message)def _to_config(self) -> GeminiAssistantAgentConfig:return GeminiAssistantAgentConfig(name=self.name,description=self.description,model=self._model,system_message=self._system_message,)
现在我们已经实现了所需的方法,就可以将自定义代理导出为 JSON 格式,再从 JSON 格式加载回来。
⚠️ 注意:你需要设置 component_provider_override 类变量为包含自定义代理类的模块完整路径,例如:
mypackage.agents.GeminiAssistantAgent。
load_component 方法会通过这个路径来确定如何实例化该类。
gemini_assistant = GeminiAssistantAgent("gemini_assistant")
config = gemini_assistant.dump_component()
print(config.model_dump_json(indent=2))
loaded_agent = GeminiAssistantAgent.load_component(config)
print(loaded_agent)
输出示例:
{"provider": "__main__.GeminiAssistantAgent","component_type": "agent","version": 1,"component_version": 1,"description": null,"label": "GeminiAssistantAgent","config": {"name": "gemini_assistant","description": "An agent that provides assistance with ability to use tools.","model": "gemini-1.5-flash-002","system_message": "You are a helpful assistant that can respond to messages. Reply with TERMINATE when the task has been completed."}
}
<__main__.GeminiAssistantAgent object at 0x11a5c5a90>
Selector Group Chat
SelectorGroupChat 实现了一个团队机制,其中参与者轮流向所有其他成员广播消息。一个生成式模型(例如 LLM)会基于共享上下文选择下一个发言者,从而实现动态、上下文感知的协作。
主要特性包括:
- 基于模型的发言者选择
- 可配置的参与者角色和描述
- 防止同一发言者连续发言(可选)
- 可自定义选择提示(selection prompting)
- 可自定义选择函数(selection function),以覆盖默认的基于模型的选择逻辑
- 可自定义候选函数(candidate function),用于通过模型缩小可选代理的范围
注意
SelectorGroupChat 是一个高级 API。若需要更强的控制和定制,请参考 Core API 文档中的 Group Chat Pattern,以实现你自己的群聊逻辑。
工作原理
SelectorGroupChat 与 RoundRobinGroupChat 类似,但采用基于模型的下一个发言者选择机制。
当团队通过 run() 或 run_stream() 接收任务时,将执行以下步骤:
-
选择发言者
团队会分析当前对话上下文,包括对话历史和参与者的name与description属性,使用模型来确定下一个发言者。- 默认情况下,团队不会连续选择同一个发言者,除非这是唯一可用的代理。
- 可以通过设置
allow_repeated_speaker=True来允许连续发言。 - 你也可以通过提供自定义的 选择函数(selection function)来覆盖模型的选择逻辑。
-
生成响应并广播
团队会提示被选中的代理发言,并将其响应广播给所有其他参与者。 -
检查终止条件
判断对话是否应当结束;若未结束,则从步骤 1 重新开始。 -
返回结果
当对话结束时,团队会返回一个 TaskResult,其中包含本次任务的完整对话历史。
此外:
- 当团队完成任务后,对话上下文会保留在团队和所有参与者中,因此下一个任务可以继续延续之前的上下文。
- 若需清空上下文,可调用
reset()。
示例:网页搜索 / 数据分析
from typing import List, Sequencefrom autogen_agentchat.agents import AssistantAgent, UserProxyAgent
from autogen_agentchat.conditions import MaxMessageTermination, TextMentionTermination
from autogen_agentchat.messages import BaseAgentEvent, BaseChatMessage
from autogen_agentchat.teams import SelectorGroupChat
from autogen_agentchat.ui import Console
from autogen_ext.models.openai import OpenAIChatCompletionClient
代理(Agents)
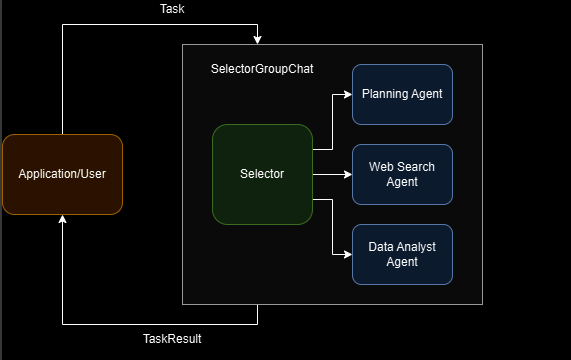
该系统使用三个专门的代理:
- Planning Agent:战略协调者,将复杂任务拆分为可管理的子任务。
- Web Search Agent:信息检索专家,调用
search_web_tool来执行搜索。 - Data Analyst Agent:数据分析专家,使用
percentage_change_tool执行计算。
工具 search_web_tool 和 percentage_change_tool 是外部工具,代理可以调用它们来完成任务。
⚠️ 注意:此示例使用的是模拟工具(mock tools),而非真实 API,仅用于演示目的。
def search_web_tool(query: str) -> str:if "2006-2007" in query:return """Here are the total points scored by Miami Heat players in the 2006-2007 season:Udonis Haslem: 844 pointsDwayne Wade: 1397 pointsJames Posey: 550 points..."""elif "2007-2008" in query:return "The number of total rebounds for Dwayne Wade in the Miami Heat season 2007-2008 is 214."elif "2008-2009" in query:return "The number of total rebounds for Dwayne Wade in the Miami Heat season 2008-2009 is 398."return "No data found."def percentage_change_tool(start: float, end: float) -> float:return ((end - start) / start) * 100
我们使用 AssistantAgent 类来创建这些专门的代理。
需要特别注意:代理的 name 和 description 属性会被模型用于选择下一个发言者,因此建议提供有意义的名称和描述。
model_client = OpenAIChatCompletionClient(model="gpt-4o")planning_agent = AssistantAgent("PlanningAgent",description="An agent for planning tasks, this agent should be the first to engage when given a new task.",model_client=model_client,system_message="""You are a planning agent.Your job is to break down complex tasks into smaller, manageable subtasks.Your team members are:WebSearchAgent: Searches for informationDataAnalystAgent: Performs calculationsYou only plan and delegate tasks - you do not execute them yourself.When assigning tasks, use this format:1. <agent> : <task>After all tasks are complete, summarize the findings and end with "TERMINATE".""",
)web_search_agent = AssistantAgent("WebSearchAgent",description="An agent for searching information on the web.",tools=[search_web_tool],model_client=model_client,system_message="""You are a web search agent.Your only tool is search_tool - use it to find information.You make only one search call at a time.Once you have the results, you never do calculations based on them.""",
)data_analyst_agent = AssistantAgent("DataAnalystAgent",description="An agent for performing calculations.",model_client=model_client,tools=[percentage_change_tool],system_message="""You are a data analyst.Given the tasks you have been assigned, you should analyze the data and provide results using the tools provided.If you have not seen the data, ask for it.""",
)
注意事项:
默认情况下,AssistantAgent 会将工具的输出作为响应返回。
如果你的工具输出不是自然语言格式的字符串,建议在创建代理时设置:
reflect_on_tool_use=True
这样代理会先对工具输出进行反思,然后再给出自然语言的响应。
Workflow
-
任务由 SelectorGroupChat 接收。它会根据代理的描述,选择最合适的代理来处理初始任务(通常是 Planning Agent)。
-
Planning Agent 分析任务,将其拆解为子任务,并使用格式
<agent> : <task>将子任务分配给最合适的代理。 -
基于对话上下文和代理描述,SelectorGroupChat 管理器会动态选择下一个代理来处理分配到的子任务。
-
Web Search Agent 每次执行一次搜索,并将结果存储在共享的对话历史中。
-
Data Analyst 在被选择时,使用可用的计算工具处理已收集的信息。
-
工作流会继续,代理会被动态选择,直到满足以下任一条件:
- Planning Agent 确定所有子任务完成,并发送
"TERMINATE" - 达到其他终止条件(例如消息数量上限)
- Planning Agent 确定所有子任务完成,并发送
⚠️ 在定义代理时,请务必提供清晰有用的 description,因为它会被用来决定下一个发言者是谁。
终止条件(Termination Conditions)
我们将使用两种终止条件:
- TextMentionTermination:当 Planning Agent 发送
"TERMINATE"时结束对话 - MaxMessageTermination:将对话限制在最多 25 条消息,以避免无限循环
text_mention_termination = TextMentionTermination("TERMINATE")
max_messages_termination = MaxMessageTermination(max_messages=25)
termination = text_mention_termination | max_messages_termination
选择器提示词(Selector Prompt)
SelectorGroupChat 使用模型根据对话上下文选择下一个发言者。
我们将定义一个自定义的选择器提示词,使其与工作流对齐:
selector_prompt = """Select an agent to perform task.{roles}Current conversation context:
{history}Read the above conversation, then select an agent from {participants} to perform the next task.
Make sure the planner agent has assigned tasks before other agents start working.
Only select one agent.
"""
提示词中的可用变量
- {participants}:候选代理的名称列表,格式为
["<name1>", "<name2>", ...] - {roles}:候选代理的名称和描述,每行一个,格式为
"<name> : <description>" - {history}:对话历史,使用双换行分隔,每条消息格式为
"<name> : <message content>"
小贴士(Tip)
不要在选择器提示词中塞入过多指令。
-
什么算“过多”?
这取决于你使用的模型能力。- 对于 GPT-4o 及同类模型,你可以在提示词中包含每个发言者的选择条件。
- 对于较小的模型(如 Phi-4),提示词应尽可能简单,就像本示例中的写法一样。
-
一般来说,如果你发现自己需要为每个代理编写多个条件,那么这可能是一个信号:
- 你应该考虑使用 自定义选择函数,
- 或者将任务拆解为更小的顺序子任务,让不同的代理或团队分别处理。
运行Team(Running the Team)
让我们使用代理、终止条件和自定义选择器提示来创建团队:
team = SelectorGroupChat([planning_agent, web_search_agent, data_analyst_agent],model_client=model_client,termination_condition=termination,selector_prompt=selector_prompt,allow_repeated_speaker=True, # 允许同一个代理连续多轮发言
)
现在,我们运行团队并下达一个任务,去查找某位 NBA 球员的信息:
task = "Who was the Miami Heat player with the highest points in the 2006-2007 season, and what was the percentage change in his total rebounds between the 2007-2008 and 2008-2009 seasons?"
# 如果在脚本中运行,请使用 asyncio.run(...)
await Console(team.run_stream(task=task))
运行结果节选(对话流程):
---------- user ----------
Who was the Miami Heat player with the highest points in the 2006-2007 season, and what was the percentage change in his total rebounds between the 2007-2008 and 2008-2009 seasons?
---------- PlanningAgent ----------
To complete this task, we need to perform the following subtasks:1. Find out which Miami Heat player had the highest points in the 2006-2007 season.
2. Gather data on this player's total rebounds for the 2007-2008 season.
3. Gather data on this player's total rebounds for the 2008-2009 season.
4. Calculate the percentage change in the player's total rebounds between the 2007-2008 and 2008-2009 seasons.I'll assign these tasks accordingly:1. WebSearchAgent: Search for the Miami Heat player with the highest points in the 2006-2007 NBA season.
2. WebSearchAgent: Find the total rebounds for this player in the 2007-2008 NBA season.
3. WebSearchAgent: Find the total rebounds for this player in the 2008-2009 NBA season.
4. DataAnalystAgent: Calculate the percentage change in total rebounds from the 2007-2008 season to the 2008-2009 season for this player.
---------- WebSearchAgent ----------
[FunctionCall(id='call_89tUNHaAM0kKQYPJLleGUKK7', arguments='{"query":"Miami Heat player highest points 2006-2007 season"}', name='search_web_tool')]
---------- WebSearchAgent ----------
[FunctionExecutionResult(content='Here are the total points scored by Miami Heat players in the 2006-2007 season:\n Udonis Haslem: 844 points\n Dwayne Wade: 1397 points\n James Posey: 550 points\n ...\n ', name='search_web_tool', call_id='call_89tUNHaAM0kKQYPJLleGUKK7', is_error=False)]
---------- WebSearchAgent ----------
Here are the total points scored by Miami Heat players in the 2006-2007 season:Udonis Haslem: 844 pointsDwayne Wade: 1397 pointsJames Posey: 550 points...---------- WebSearchAgent ----------
The Miami Heat player with the highest points in the 2006-2007 season was Dwyane Wade, with 1,397 points.Next, I will search for Dwyane Wade's total rebounds for the 2007-2008 season.
---------- WebSearchAgent ----------
[FunctionCall(id='call_RC55TkSjG3JXRuVOTPrcE1RL', arguments='{"query":"Dwyane Wade total rebounds 2007-2008 season"}', name='search_web_tool')]
---------- WebSearchAgent ----------
[FunctionExecutionResult(content='The number of total rebounds for Dwayne Wade in the Miami Heat season 2007-2008 is 214.', name='search_web_tool', call_id='call_RC55TkSjG3JXRuVOTPrcE1RL', is_error=False)]
---------- WebSearchAgent ----------
The number of total rebounds for Dwayne Wade in the Miami Heat season 2007-2008 is 214.
---------- WebSearchAgent ----------
[FunctionCall(id='call_pBXoABrErDow0rZjw3tjOZol', arguments='{"query":"Dwyane Wade total rebounds 2008-2009 season"}', name='search_web_tool')]
---------- WebSearchAgent ----------
[FunctionExecutionResult(content='The number of total rebounds for Dwayne Wade in the Miami Heat season 2008-2009 is 398.', name='search_web_tool', call_id='call_pBXoABrErDow0rZjw3tjOZol', is_error=False)]
---------- WebSearchAgent ----------
The number of total rebounds for Dwayne Wade in the Miami Heat season 2008-2009 is 398.
---------- DataAnalystAgent ----------
[FunctionCall(id='call_qMxxXtcJsiK8KFSSCx3zm0is', arguments='{"start":214,"end":398}', name='percentage_change_tool')]
---------- DataAnalystAgent ----------
[FunctionExecutionResult(content='85.98130841121495', name='percentage_change_tool', call_id='call_qMxxXtcJsiK8KFSSCx3zm0is', is_error=False)]
---------- DataAnalystAgent ----------
85.98130841121495
---------- PlanningAgent ----------
The player with the highest points for the Miami Heat in the 2006-2007 NBA season was Dwyane Wade, who scored 1,397 points. The percentage change in Dwyane Wade's total rebounds from 214 in the 2007-2008 season to 398 in the 2008-2009 season is approximately 85.98%.TERMINATE
TaskResult(messages=[TextMessage(source='user', models_usage=None, metadata={}, content='Who was the Miami Heat player with the highest points in the 2006-2007 season, and what was the percentage change in his total rebounds between the 2007-2008 and 2008-2009 seasons?', type='TextMessage'), TextMessage(source='PlanningAgent', models_usage=RequestUsage(prompt_tokens=161, completion_tokens=220), metadata={}, content="To complete this task, we need to perform the following subtasks:\n\n1. Find out which Miami Heat player had the highest points in the 2006-2007 season.\n2. Gather data on this player's total rebounds for the 2007-2008 season.\n3. Gather data on this player's total rebounds for the 2008-2009 season.\n4. Calculate the percentage change in the player's total rebounds between the 2007-2008 and 2008-2009 seasons.\n\nI'll assign these tasks accordingly:\n\n1. WebSearchAgent: Search for the Miami Heat player with the highest points in the 2006-2007 NBA season.\n2. WebSearchAgent: Find the total rebounds for this player in the 2007-2008 NBA season.\n3. WebSearchAgent: Find the total rebounds for this player in the 2008-2009 NBA season.\n4. DataAnalystAgent: Calculate the percentage change in total rebounds from the 2007-2008 season to the 2008-2009 season for this player.", type='TextMessage'), ToolCallRequestEvent(source='WebSearchAgent', models_usage=RequestUsage(prompt_tokens=368, completion_tokens=27), metadata={}, content=[FunctionCall(id='call_89tUNHaAM0kKQYPJLleGUKK7', arguments='{"query":"Miami Heat player highest points 2006-2007 season"}', name='search_web_tool')], type='ToolCallRequestEvent'), ToolCallExecutionEvent(source='WebSearchAgent', models_usage=None, metadata={}, content=[FunctionExecutionResult(content='Here are the total points scored by Miami Heat players in the 2006-2007 season:\n Udonis Haslem: 844 points\n Dwayne Wade: 1397 points\n James Posey: 550 points\n ...\n ', name='search_web_tool', call_id='call_89tUNHaAM0kKQYPJLleGUKK7', is_error=False)], type='ToolCallExecutionEvent'), ToolCallSummaryMessage(source='WebSearchAgent', models_usage=None, metadata={}, content='Here are the total points scored by Miami Heat players in the 2006-2007 season:\n Udonis Haslem: 844 points\n Dwayne Wade: 1397 points\n James Posey: 550 points\n ...\n ', type='ToolCallSummaryMessage'), ThoughtEvent(source='WebSearchAgent', models_usage=None, metadata={}, content="The Miami Heat player with the highest points in the 2006-2007 season was Dwyane Wade, with 1,397 points.\n\nNext, I will search for Dwyane Wade's total rebounds for the 2007-2008 season.", type='ThoughtEvent'), ToolCallRequestEvent(source='WebSearchAgent', models_usage=RequestUsage(prompt_tokens=460, completion_tokens=83), metadata={}, content=[FunctionCall(id='call_RC55TkSjG3JXRuVOTPrcE1RL', arguments='{"query":"Dwyane Wade total rebounds 2007-2008 season"}', name='search_web_tool')], type='ToolCallRequestEvent'), ToolCallExecutionEvent(source='WebSearchAgent', models_usage=None, metadata={}, content=[FunctionExecutionResult(content='The number of total rebounds for Dwayne Wade in the Miami Heat season 2007-2008 is 214.', name='search_web_tool', call_id='call_RC55TkSjG3JXRuVOTPrcE1RL', is_error=False)], type='ToolCallExecutionEvent'), ToolCallSummaryMessage(source='WebSearchAgent', models_usage=None, metadata={}, content='The number of total rebounds for Dwayne Wade in the Miami Heat season 2007-2008 is 214.', type='ToolCallSummaryMessage'), ToolCallRequestEvent(source='WebSearchAgent', models_usage=RequestUsage(prompt_tokens=585, completion_tokens=28), metadata={}, content=[FunctionCall(id='call_pBXoABrErDow0rZjw3tjOZol', arguments='{"query":"Dwyane Wade total rebounds 2008-2009 season"}', name='search_web_tool')], type='ToolCallRequestEvent'), ToolCallExecutionEvent(source='WebSearchAgent', models_usage=None, metadata={}, content=[FunctionExecutionResult(content='The number of total rebounds for Dwayne Wade in the Miami Heat season 2008-2009 is 398.', name='search_web_tool', call_id='call_pBXoABrErDow0rZjw3tjOZol', is_error=False)], type='ToolCallExecutionEvent'), ToolCallSummaryMessage(source='WebSearchAgent', models_usage=None, metadata={}, content='The number of total rebounds for Dwayne Wade in the Miami Heat season 2008-2009 is 398.', type='ToolCallSummaryMessage'), ToolCallRequestEvent(source='DataAnalystAgent', models_usage=RequestUsage(prompt_tokens=496, completion_tokens=21), metadata={}, content=[FunctionCall(id='call_qMxxXtcJsiK8KFSSCx3zm0is', arguments='{"start":214,"end":398}', name='percentage_change_tool')], type='ToolCallRequestEvent'), ToolCallExecutionEvent(source='DataAnalystAgent', models_usage=None, metadata={}, content=[FunctionExecutionResult(content='85.98130841121495', name='percentage_change_tool', call_id='call_qMxxXtcJsiK8KFSSCx3zm0is', is_error=False)], type='ToolCallExecutionEvent'), ToolCallSummaryMessage(source='DataAnalystAgent', models_usage=None, metadata={}, content='85.98130841121495', type='ToolCallSummaryMessage'), TextMessage(source='PlanningAgent', models_usage=RequestUsage(prompt_tokens=528, completion_tokens=80), metadata={}, content="The player with the highest points for the Miami Heat in the 2006-2007 NBA season was Dwyane Wade, who scored 1,397 points. The percentage change in Dwyane Wade's total rebounds from 214 in the 2007-2008 season to 398 in the 2008-2009 season is approximately 85.98%.\n\nTERMINATE", type='TextMessage')], stop_reason="Text 'TERMINATE' mentioned")
- 用户:谁是 2006-2007 赛季迈阿密热火队得分最高的球员?他在 2007-2008 和 2008-2009 赛季的总篮板数变化百分比是多少?
- PlanningAgent:将任务拆解为 4 个子任务,并分配给 WebSearchAgent 和 DataAnalystAgent。
- WebSearchAgent:依次搜索球员得分、2007-2008 赛季篮板数、2008-2009 赛季篮板数。
- DataAnalystAgent:计算 2007-2008 到 2008-2009 赛季篮板数的百分比变化。
- PlanningAgent:汇总结果并发送
"TERMINATE"。
最终结果:
- 2006-2007 赛季迈阿密热火队得分最高的球员是 德维恩·韦德(Dwyane Wade),得分 1,397 分。
- 他在 2007-2008 赛季的总篮板数为 214,2008-2009 赛季为 398。
- 这两季篮板数的百分比变化约为 85.98%。
自定义选择器函数(Custom Selector Function)
很多时候我们希望对选择过程有更好的控制。为此,可以通过设置 selector_func 参数为自定义选择器函数,来覆盖默认的基于模型的选择逻辑。这允许我们实现更复杂的选择逻辑和基于状态的转移。
例如:我们希望 Planning Agent 在任何专业代理(specialized agent)说完之后,立刻发言来检查进度。
注意
- 如果自定义选择器函数返回
None,则会回退到默认的基于模型的选择逻辑。- 当在
SelectorGroupChat团队上调用.dump_component()时,自定义选择器函数不会被序列化。如果你需要序列化包含自定义选择器函数的团队配置,应考虑实现自定义的工作流和序列化逻辑。
def selector_func(messages: Sequence[BaseAgentEvent | BaseChatMessage]) -> str | None:if messages[-1].source != planning_agent.name:return planning_agent.namereturn None# 重置之前的团队,并使用自定义选择器函数再次运行对话
await team.reset()
team = SelectorGroupChat([planning_agent, web_search_agent, data_analyst_agent],model_client=model_client,termination_condition=termination,selector_prompt=selector_prompt,allow_repeated_speaker=True,selector_func=selector_func,
)await Console(team.run_stream(task=task))
运行示例对话中可以看到:
- PlanningAgent 会在 WebSearchAgent 或 DataAnalystAgent 发言后立刻接入,检查并推进任务。
- 最终结果与之前相同,仍然得出德维恩·韦德(Dwyane Wade)是 2006-2007 赛季迈阿密热火队的最高得分者(1397 分),并且其篮板数在 2007-2008(214 个)到 2008-2009(398 个)赛季间的百分比变化约为 86%。
提示
每个参与代理在每一轮中只会执行一步操作(调用工具、生成回复等)。
如果你希望某个AssistantAgent在调用工具后能够“连续执行”,直到不再返回ToolCallSummaryMessage(表示所有工具都执行完毕),你可以通过检查最后一条消息是否为ToolCallSummaryMessage,然后决定是否继续返回该代理。
自定义候选函数
另一个可能的需求是:希望自动从经过筛选的代理列表中选择下一位发言者。为此,我们可以通过设置 candidate_func 参数并传入一个自定义候选函数,来在每一轮群聊中筛选潜在的发言代理。
这样我们就可以在某个代理发言后,将发言权限制在特定的一组代理中。
注意
- 只有当
selector_func未被设置时,candidate_func才会生效。- 如果自定义候选函数返回
None或空列表[],将会抛出ValueError。
def candidate_func(messages: Sequence[BaseAgentEvent | BaseChatMessage]) -> List[str]:# 第一步:确保 planning_agent 始终是第一个发言的代理,用于规划任务if messages[-1].source == "user":return [planning_agent.name]# 第二步:如果上一个发言者是 planning_agent,并且它明确要求调用# web_search_agent 或 data_analyst_agent(或两者,用于重新规划/重新分配任务),# 则只返回对应的代理last_message = messages[-1]if last_message.source == planning_agent.name:participants = []if web_search_agent.name in last_message.to_text():participants.append(web_search_agent.name)if data_analyst_agent.name in last_message.to_text():participants.append(data_analyst_agent.name)if participants:return participants # SelectorGroupChat 会在返回的代理中选择一位# 第三步:我们假设任务完成的标志是 web_search_agent 和 data_analyst_agent 都已发言# 此时将发言权交给 planning_agent,以便终止对话previous_set_of_agents = set(message.source for message in messages)if web_search_agent.name in previous_set_of_agents and data_analyst_agent.name in previous_set_of_agents:return [planning_agent.name]# 第四步:如果没有满足的条件,则返回所有代理return [planning_agent.name, web_search_agent.name, data_analyst_agent.name]
# 重置之前的团队,并使用自定义候选函数重新运行群聊
await team.reset()
team = SelectorGroupChat([planning_agent, web_search_agent, data_analyst_agent],model_client=model_client,termination_condition=termination,candidate_func=candidate_func,
)await Console(team.run_stream(task=task))
从对话日志中可以看到:
- 当 WebSearchAgent 和 DataAnalystAgent 都完成发言后,PlanningAgent 会再次接管对话;
- 在发现任务并未如预期完成时,它会再次调用 WebSearchAgent 获取篮板数据,随后调用 DataAnalystAgent 计算百分比变化。
用户反馈
我们可以在团队中添加 UserProxyAgent,以便在运行过程中提供用户反馈。
在 Web 搜索示例中使用 UserProxyAgent,只需将其加入团队,并更新选择器函数,使其在 PlanningAgent 发言后始终检查用户反馈。如果用户回复 “APPROVE”,对话继续进行;否则,PlanningAgent 会重新尝试,直到用户批准为止。
user_proxy_agent = UserProxyAgent("UserProxyAgent", description="A proxy for the user to approve or disapprove tasks.")def selector_func_with_user_proxy(messages: Sequence[BaseAgentEvent | BaseChatMessage]) -> str | None:if messages[-1].source != planning_agent.name and messages[-1].source != user_proxy_agent.name:# 在收到新任务或检查进度时,planning agent 应该是第一个发言的代理return planning_agent.nameif messages[-1].source == planning_agent.name:if messages[-2].source == user_proxy_agent.name and "APPROVE" in messages[-1].content.upper(): # type: ignore# 用户已批准计划,继续下一个代理return None# 使用 user proxy agent 请求用户批准后再继续return user_proxy_agent.nameif messages[-1].source == user_proxy_agent.name:# 如果用户没有批准,则返回到 planning agentif "APPROVE" not in messages[-1].content.upper(): # type: ignorereturn planning_agent.namereturn None
# 重置之前的代理,并使用带有用户代理和选择器函数的团队重新运行对话
await team.reset()
team = SelectorGroupChat([planning_agent, web_search_agent, data_analyst_agent, user_proxy_agent],model_client=model_client,termination_condition=termination,selector_prompt=selector_prompt,selector_func=selector_func_with_user_proxy,allow_repeated_speaker=True,
)await Console(team.run_stream(task=task))
在对话记录中可以看到:
- PlanningAgent 先提出任务分解;
- UserProxyAgent 向用户请求批准;
- 当用户回复 approve 时,WebSearchAgent 和 DataAnalystAgent 执行任务;
- 每一步操作前,PlanningAgent 都会再次请求用户批准,直到最终完成任务并 TERMINATE。
这样一来,用户的反馈就被纳入了整个对话流程中,用户可以批准或拒绝 PlanningAgent 的决策。
使用推理模型
到目前为止,在示例中我们使用的是 gpt-4o 模型。像 gpt-4o 和 gemini-1.5-flash 这样的模型非常擅长遵循指令,因此你可以在团队的选择器提示(selector prompt)和每个代理的系统消息中提供相对详细的说明,以引导它们的行为。
然而,如果你使用的是像 o3-mini 这样的推理模型,则需要尽量保持选择器提示和系统消息简洁明了。这是因为推理模型本身已经很擅长根据提供的上下文生成自己的指令。
这也意味着我们不再需要 PlanningAgent 来分解任务,因为使用推理模型的 SelectorGroupChat 可以自行完成任务分解。
在下面的示例中,我们将使用 o3-mini 作为代理和团队的模型,并且不使用 PlanningAgent。同时,选择器提示和系统消息尽量保持简单。
model_client = OpenAIChatCompletionClient(model="o3-mini")web_search_agent = AssistantAgent("WebSearchAgent",description="An agent for searching information on the web.",tools=[search_web_tool],model_client=model_client,system_message="""Use web search tool to find information.""",
)data_analyst_agent = AssistantAgent("DataAnalystAgent",description="An agent for performing calculations.",model_client=model_client,tools=[percentage_change_tool],system_message="""Use tool to perform calculation. If you have not seen the data, ask for it.""",
)user_proxy_agent = UserProxyAgent("UserProxyAgent",description="A user to approve or disapprove tasks.",
)selector_prompt = """Select an agent to perform task.{roles}Current conversation context:
{history}Read the above conversation, then select an agent from {participants} to perform the next task.
When the task is complete, let the user approve or disapprove the task.
"""team = SelectorGroupChat([web_search_agent, data_analyst_agent, user_proxy_agent],model_client=model_client,termination_condition=termination, # 使用之前相同的终止条件selector_prompt=selector_prompt,allow_repeated_speaker=True,
)await Console(team.run_stream(task=task))
在实际对话中可以看到:
- WebSearchAgent 找出 2006-2007 赛季得分最高的球员(Dwyane Wade)。
- DataAnalystAgent 请求用户提供该球员 2007-2008 和 2008-2009 赛季的总篮板数据。
- WebSearchAgent 返回总篮板数据:214(2007-2008)和 398(2008-2009)。
- DataAnalystAgent 计算总篮板的百分比变化,约为 85.98%。
- UserProxyAgent 最终批准任务,结束对话。
Swarm
Swarm 实现了一种团队机制,其中代理可以根据自身能力将任务交给其他代理。这是一种多代理设计模式,最早由 OpenAI 在 Swarm 中提出。其核心思想是让代理通过特殊的工具调用将任务委派给其他代理,同时所有代理共享相同的消息上下文。这使得代理可以在本地对任务规划做出决策,而不必依赖中央调度器(如 SelectorGroupChat)。
注意
Swarm 是一个高级 API。如果你需要更高的控制和自定义,而该 API 不支持,你可以参考 Core API 文档中的 Handoff Pattern 并自行实现 Swarm 模式。
工作原理
Swarm 团队本质上是一个群聊,代理轮流生成响应。与 SelectorGroupChat 和 RoundRobinGroupChat 类似,参与代理会广播它们的响应,使所有代理共享相同的消息上下文。
不同的是,在 Swarm 中,每一轮的发言代理是根据上下文中最近的 HandoffMessage 选择的。这意味着团队中的每个代理都必须能够生成 HandoffMessage,以指示它将任务交给哪些其他代理。
对于 AssistantAgent,你可以通过设置 handoffs 参数来指定它可以将任务交给哪些代理。同时,你可以使用 Handoff 自定义消息内容和交接行为。
整体流程可以总结如下:
- 每个代理都可以生成 HandoffMessage,以指示它可以将任务交给哪些其他代理。对于 AssistantAgent,这意味着需要设置 handoffs 参数。
- 当团队开始处理任务时,首个发言代理对任务进行操作,并根据情况做出本地决策:是否交接任务,以及交给谁。
- 当某个代理生成 HandoffMessage 时,接收代理将在相同消息上下文下接管任务。
- 该过程持续进行,直到满足终止条件。
注意
- AssistantAgent 使用模型的工具调用功能来生成任务交接(handoffs),因此模型必须支持工具调用。
- 如果模型支持并行工具调用,可能会同时生成多个交接消息,这可能导致意外行为。
- 为避免这种情况,可以通过配置模型客户端禁用并行工具调用。在 OpenAIChatCompletionClient 和 AzureOpenAIChatCompletionClient 中,可将
parallel_tool_calls=False。
客服示例
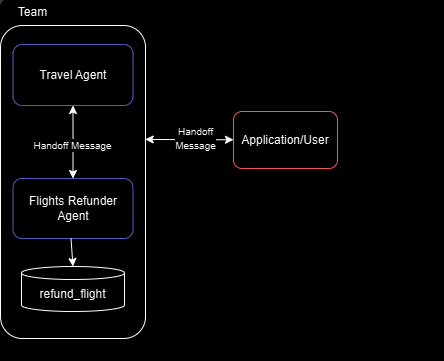
这个系统实现了一个航班退款场景,包含两个代理:
- Travel Agent(旅行代理):负责一般的旅行和退款协调。
- Flights Refunder(航班退款代理):专门处理航班退款,使用
refund_flight工具。
另外,我们还允许用户与代理交互,当代理将任务交接给 "user" 时,系统会等待用户输入。
工作流程
-
Travel Agent 发起对话并评估用户的请求。
-
根据请求内容:
- 对于退款相关任务,Travel Agent 将任务交接给 Flights Refunder。
- 对于需要客户信息的情况,任意代理都可以交接给
"user"。
-
Flights Refunder 在合适的情况下使用
refund_flight工具处理退款。 -
如果代理将任务交接给
"user",则团队执行会暂停,等待用户输入。 -
当用户提供输入时,会作为 HandoffMessage 返回团队,并发送给最初请求该输入的代理。
-
流程持续进行,直到 Travel Agent 判断任务完成,并终止工作流。
工具
def refund_flight(flight_id: str) -> str:"""Refund a flight"""return f"Flight {flight_id} refunded"
代理
model_client = OpenAIChatCompletionClient(model="gpt-4o",# api_key="YOUR_API_KEY",
)travel_agent = AssistantAgent("travel_agent",model_client=model_client,handoffs=["flights_refunder", "user"],system_message="""You are a travel agent.The flights_refunder is in charge of refunding flights.If you need information from the user, you must first send your message, then you can handoff to the user.Use TERMINATE when the travel planning is complete.""",
)flights_refunder = AssistantAgent("flights_refunder",model_client=model_client,handoffs=["travel_agent", "user"],tools=[refund_flight],system_message="""You are an agent specialized in refunding flights.You only need flight reference numbers to refund a flight.You have the ability to refund a flight using the refund_flight tool.If you need information from the user, you must first send your message, then you can handoff to the user.When the transaction is complete, handoff to the travel agent to finalize.""",
)
终止条件
termination = HandoffTermination(target="user") | TextMentionTermination("TERMINATE")
team = Swarm([travel_agent, flights_refunder], termination_condition=termination)
task = "I need to refund my flight."
运行逻辑
async def run_team_stream() -> None:task_result = await Console(team.run_stream(task=task))last_message = task_result.messages[-1]while isinstance(last_message, HandoffMessage) and last_message.target == "user":user_message = input("User: ")task_result = await Console(team.run_stream(task=HandoffMessage(source="user", target=last_message.source, content=user_message)))last_message = task_result.messages[-1]# 在脚本中可用 asyncio.run(...) 启动。
await run_team_stream()
await model_client.close()
示例对话
---------- user ----------
I need to refund my flight.---------- travel_agent ----------
[调用 transfer_to_flights_refunder 工具 → 将任务交接给 Flights Refunder]---------- flights_refunder ----------
Could you please provide me with the flight reference number so I can process the refund for you?---------- flights_refunder ----------
[调用 transfer_to_user → 等待用户输入]---------- user ----------
Sure, it's 507811---------- flights_refunder ----------
[调用 refund_flight 工具,结果:Flight 507811 refunded]---------- flights_refunder ----------
[调用 transfer_to_travel_agent → 将任务交回给 Travel Agent]---------- travel_agent ----------
Your flight with reference number 507811 has been successfully refunded.
If you need anything else, feel free to let me know. Safe travels! TERMINATE
✅ 整个流程中,任务从 Travel Agent → Flights Refunder → User → Flights Refunder → Travel Agent → TERMINATE,演示了 Swarm 模式下的任务交接。
股票研究示例
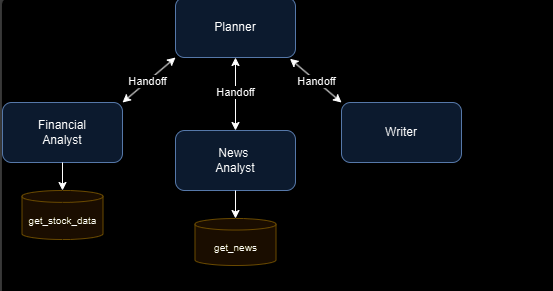
这个系统旨在通过四个智能体来执行股票研究任务:
- Planner(规划者):核心协调者,根据各智能体的专长分配具体任务。Planner 确保每个智能体都能高效发挥作用,并负责监督整个工作流程。
- Financial Analyst(财务分析师):专门负责使用
get_stock_data等工具分析财务指标和股票数据。 - News Analyst(新闻分析师):专门负责使用
get_news等工具收集和总结与股票相关的最新新闻。 - Writer(撰写者):负责编写最终研究报告,将财务和新闻分析的结果整合为完整的报告。
工作流程
- Planner 发起研究流程,并逐步将任务分配给合适的智能体。
- 每个智能体 独立完成任务,并将结果追加到共享的消息历史中,而不是直接返回给 Planner。
- 所有智能体都能访问这个共享的消息历史,这为它们提供上下文,并帮助跟踪整体研究进展。
- 当一个智能体完成任务后,会将控制权交还给 Planner。
- 这个过程会持续,直到 Planner 判断所有必要的任务已经完成,并决定终止工作流。
工具
async def get_stock_data(symbol: str) -> Dict[str, Any]:"""获取指定股票的市场数据"""return {"price": 180.25, "volume": 1000000, "pe_ratio": 65.4, "market_cap": "700B"}async def get_news(query: str) -> List[Dict[str, str]]:"""获取与公司相关的最新新闻"""return [{"title": "特斯拉扩展 Cybertruck 生产","date": "2024-03-20","summary": "特斯拉在德州超级工厂提升 Cybertruck 的产能,以满足强劲需求。",},{"title": "特斯拉 FSD 测试版展现潜力","date": "2024-03-19","summary": "最新的自动驾驶测试版在城市导航和安全功能上表现出显著提升。",},{"title": "Model Y 主导全球电动车销量","date": "2024-03-18","summary": "特斯拉 Model Y 成为全球最畅销电动车,占据了显著市场份额。",},]
后面是定义 Planner、Financial Analyst、News Analyst、Writer 以及终止条件(TERMINATE)的完整示例代码,以及一次运行 TSLA 股票研究任务的完整对话记录和执行过程。
model_client = OpenAIChatCompletionClient(model="gpt-4o",# api_key="YOUR_API_KEY",
)planner = AssistantAgent("planner",model_client=model_client,handoffs=["financial_analyst", "news_analyst", "writer"],system_message="""你是一名研究规划协调员。你的任务是协调市场研究工作,并把任务分配给专门的智能体:- 金融分析师(Financial Analyst):负责股票数据分析- 新闻分析师(News Analyst):负责新闻收集与分析- 报告撰写员(Writer):负责撰写最终报告始终先输出你的研究计划,然后再交接给合适的智能体。每次只交接给一个智能体。研究完成时使用 TERMINATE 结束。""",
)financial_analyst = AssistantAgent("financial_analyst",model_client=model_client,handoffs=["planner"],tools=[get_stock_data],system_message="""你是一名金融分析师。使用 get_stock_data 工具分析股票市场数据。提供关于财务指标的见解。分析完成后始终交接回 planner。""",
)news_analyst = AssistantAgent("news_analyst",model_client=model_client,handoffs=["planner"],tools=[get_news],system_message="""你是一名新闻分析师。使用 get_news 工具收集并分析相关新闻。总结新闻中的关键市场洞察。分析完成后始终交接回 planner。""",
)writer = AssistantAgent("writer",model_client=model_client,handoffs=["planner"],system_message="""你是一名金融报告撰写员。将研究结果整理为清晰、简明的报告。写作完成后始终交接回 planner。""",
)# 定义终止条件
text_termination = TextMentionTermination("TERMINATE")
termination = text_terminationresearch_team = Swarm(participants=[planner, financial_analyst, news_analyst, writer], termination_condition=termination
)task = "对特斯拉(TSLA)股票进行市场调研"
await Console(research_team.run_stream(task=task))
await model_client.close()
执行日志
---------- 用户 ----------
对特斯拉(TSLA)股票进行市场调研
---------- 规划员 ----------
[调用函数 transfer_to_financial_analyst]
---------- 规划员 ----------
已交接至金融分析师,切换为金融分析师角色。
---------- 金融分析师 ----------
[调用函数 get_stock_data({"symbol":"TSLA"})]
---------- 金融分析师 ----------
执行结果: {'price': 180.25, 'volume': 1000000, 'pe_ratio': 65.4, 'market_cap': '700B'}
---------- 金融分析师 ----------
工具调用:
get_stock_data({"symbol":"TSLA"}) = {'price': 180.25, 'volume': 1000000, 'pe_ratio': 65.4, 'market_cap': '700B'}
---------- 金融分析师 ----------
[调用函数 transfer_to_planner]
---------- 金融分析师 ----------
已交接回规划员角色。
---------- 规划员 ----------
[调用函数 transfer_to_news_analyst]
---------- 规划员 ----------
已交接至新闻分析师,切换为新闻分析师角色。
---------- 新闻分析师 ----------
[调用函数 get_news({"query":"Tesla market news"})]
---------- 新闻分析师 ----------
执行结果:
[{'title': '特斯拉扩大 Cybertruck 产能', 'date': '2024-03-20', 'summary': '特斯拉在德州超级工厂提升 Cybertruck 生产能力,以满足强劲需求。'},{'title': '特斯拉 FSD 测试版表现突出', 'date': '2024-03-19', 'summary': '最新的自动驾驶测试版在城市道路导航和安全功能方面显著改进。'},{'title': 'Model Y 主导全球电动车销量', 'date': '2024-03-18', 'summary': '特斯拉 Model Y 成为全球最畅销的电动车,占据了显著市场份额。'}
]
---------- 新闻分析师 ----------
工具调用:
get_news({"query":"Tesla market news"}) = [...]
---------- 新闻分析师 ----------
这里是关于特斯拉(TSLA)的关键市场洞察:1. **Cybertruck 扩产**:特斯拉在德州工厂提升了 Cybertruck 产能,以满足高需求。这将有助于收入增长。
2. **自动驾驶进展**:最新的 FSD 测试版在城市导航和安全上有显著进步,增强了特斯拉在自动驾驶领域的竞争力。
3. **Model Y 销量领先**:Model Y 成为全球最畅销的电动车,强化了特斯拉在电动车市场的领导地位。 这些发展显示了特斯拉持续创新和抓住市场需求的能力,可能对股价和市场地位产生积极影响。我现在交接回规划员。
---------- 新闻分析师 ----------
[调用函数 transfer_to_planner]
---------- 新闻分析师 ----------
已交接回规划员角色。
---------- 规划员 ----------
[调用函数 transfer_to_writer]
---------- 规划员 ----------
已交接至报告撰写员,切换为写作者角色。
---------- 报告撰写员 ----------
[调用函数 transfer_to_planner]
---------- 报告撰写员 ----------
已交接回规划员角色。
---------- 规划员 ----------
TERMINATE
Magentic-One
Magentic-One 是一个通用型多智能体系统,用于解决跨越多个领域的开放式网页与文件任务。它代表了多智能体系统向前迈出的重要一步,在多个智能体基准测试中取得了具有竞争力的表现(详见技术报告)。
Magentic-One 于 2024 年 11 月首次发布时,是直接基于 autogen-core 库实现的。我们现在已将 Magentic-One 移植到 autogen-agentchat,提供了更加模块化且易于使用的接口。
为此,Magentic-One 的编排器 MagenticOneGroupChat 现在只是一个 AgentChat 团队,支持所有标准的 AgentChat 智能体与功能。同样,Magentic-One 的 MultimodalWebSurfer、FileSurfer 和 MagenticOneCoderAgent 智能体也已作为 AgentChat 智能体广泛提供,可在任何 AgentChat 工作流中使用。
最后,AutoGen提供了一个辅助类 MagenticOne,它将上述功能打包在一起,只需最少的配置即可复现论文中的使用方式。

Autogen Magentic-One 示例
示例:上图展示了 Magentic-One 多智能体团队完成 GAIA 基准中的一个复杂任务的过程。Magentic-One 的 编排器智能体(Orchestrator) 负责创建计划,将任务分派给其他智能体,并跟踪目标的进展,必要时动态修订计划。编排器可以将任务分派给 FileSurfer 智能体 来读取和处理文件,WebSurfer 智能体 来操作网页浏览器,或分派给 Coder 或 终端智能体(Computer Terminal agent) 来编写或执行代码。
注意事项
使用 Magentic-One 涉及与为人类设计的数字世界交互,这本身具有一定风险。为了尽量降低这些风险,请考虑以下防范措施:
- 使用容器:在 Docker 容器中运行所有任务,以隔离智能体并防止直接的系统攻击。
- 虚拟环境:在虚拟环境中运行智能体,防止其访问敏感数据。
- 监控日志:在执行过程中及执行后密切监控日志,以发现和缓解风险行为。
- 人工监督:在人类监督的情况下运行示例,避免智能体产生意外后果。
- 限制访问:限制智能体对互联网和其他资源的访问,防止未授权的操作。
- 保护数据:确保智能体无法访问可能被泄露的敏感数据或资源。不要与智能体共享敏感信息。请注意,智能体有时可能尝试执行风险操作,例如招募人类帮助,或在无人参与的情况下接受 Cookie 协议。请务必保证智能体在受控环境中运行并处于监控之下,以防止意外后果。此外,要警惕 Magentic-One 可能受到网页 提示注入攻击(prompt injection) 的威胁。
安装所需依赖包:
pip install "autogen-agentchat" "autogen-ext[magentic-one,openai]"
如果使用 MultimodalWebSurfer,还需要安装 Playwright 依赖:
playwright install --with-deps chromium
示例 1:使用 MagenticOneGroupChat
import asyncio
from autogen_ext.models.openai import OpenAIChatCompletionClient
from autogen_agentchat.agents import AssistantAgent
from autogen_agentchat.teams import MagenticOneGroupChat
from autogen_agentchat.ui import Consoleasync def main() -> None:model_client = OpenAIChatCompletionClient(model="gpt-4o")assistant = AssistantAgent("Assistant",model_client=model_client,)team = MagenticOneGroupChat([assistant], model_client=model_client)await Console(team.run_stream(task="Provide a different proof for Fermat's Last Theorem"))await model_client.close()asyncio.run(main())
示例 2:在团队中使用 Magentic-One 智能体
⚠ 注意:以下示例代码可能会从互联网下载文件、执行代码,并与网页交互。请确保你在 安全的环境中运行 这些代码。
import asyncio
from autogen_ext.models.openai import OpenAIChatCompletionClient
from autogen_agentchat.teams import MagenticOneGroupChat
from autogen_agentchat.ui import Console
from autogen_ext.agents.web_surfer import MultimodalWebSurfer
# from autogen_ext.agents.file_surfer import FileSurfer
# from autogen_ext.agents.magentic_one import MagenticOneCoderAgent
# from autogen_agentchat.agents import CodeExecutorAgent
# from autogen_ext.code_executors.local import LocalCommandLineCodeExecutorasync def main() -> None:model_client = OpenAIChatCompletionClient(model="gpt-4o")surfer = MultimodalWebSurfer("WebSurfer",model_client=model_client,)team = MagenticOneGroupChat([surfer], model_client=model_client)await Console(team.run_stream(task="What is the UV index in Melbourne today?"))# # 注意:你也可以在团队中使用其他智能体# team = MagenticOneGroupChat([surfer, file_surfer, coder, terminal], model_client=model_client)# file_surfer = FileSurfer("FileSurfer", model_client=model_client)# coder = MagenticOneCoderAgent("Coder", model_client=model_client)# terminal = CodeExecutorAgent("ComputerTerminal", code_executor=LocalCommandLineCodeExecutor())asyncio.run(main())
示例 3:使用 MagenticOne 辅助类(打包所有智能体)
import asyncio
from autogen_ext.models.openai import OpenAIChatCompletionClient
from autogen_ext.teams.magentic_one import MagenticOne
from autogen_agentchat.ui import Console
from autogen_agentchat.agents import ApprovalRequest, ApprovalResponsedef approval_func(request: ApprovalRequest) -> ApprovalResponse:"""一个简单的审批函数,在代码执行前请求用户确认。"""print(f"待执行的代码:\n{request.code}")user_input = input("是否允许执行这段代码?(y/n): ").strip().lower()if user_input == 'y':return ApprovalResponse(approved=True, reason="用户已批准代码执行")else:return ApprovalResponse(approved=False, reason="用户拒绝代码执行")async def example_usage():client = OpenAIChatCompletionClient(model="gpt-4o")# 启用代码执行审批以提升安全性m1 = MagenticOne(client=client, approval_func=approval_func)task = "Write a Python script to fetch data from an API."result = await Console(m1.run_stream(task=task))print(result)if __name__ == "__main__":asyncio.run(example_usage())
Autogen Magentic-One 架构
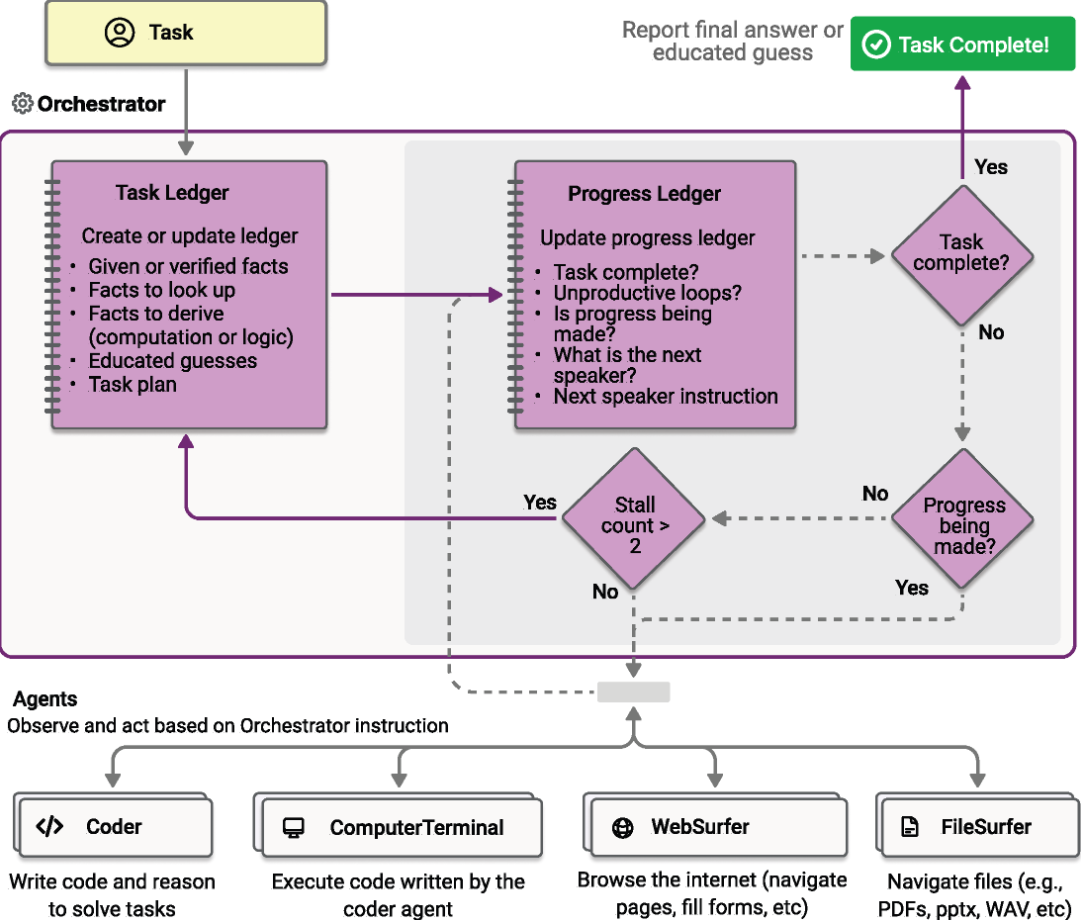
Magentic-One 的工作基于一种多智能体架构,其中主导的 Orchestrator 智能体负责高层规划、指挥其他智能体并跟踪任务进展。Orchestrator 会首先制定一个计划以处理任务,并在维护的 任务账本(Task Ledger) 中收集所需事实与合理的假设。在计划的每一步,Orchestrator 会创建一个 进度账本(Progress Ledger),在其中对任务进展进行自我反思并检查任务是否已完成。如果任务尚未完成,它会将某个子任务分派给 Magentic-One 的其他智能体之一。被分配的智能体完成其子任务后,Orchestrator 会更新进度账本,并以此方式循环直至任务完成。如果 Orchestrator 发现经过若干步骤仍无实质进展,它可以更新任务账本并制定新计划。如上图所示,Orchestrator 的工作因此被划分为:用于更新任务账本的外循环,以及用于更新进度账本的内循环。
总体上,Magentic-One 包含以下智能体:
- Orchestrator:主导智能体,负责任务分解与规划,指挥其他智能体执行子任务,跟踪总体进展,并在需要时采取纠正措施。
- WebSurfer:基于大语言模型(LLM)的智能体,擅长发出命令并管理基于 Chromium 的网页浏览器状态。对于每个输入请求,WebSurfer 会在浏览器上执行某个动作,然后报告网页的新状态。其动作空间包括导航(例如访问 URL、执行网页搜索)、网页操作(例如点击与输入)以及阅读类操作(例如摘要或回答问题)。WebSurfer 的执行依赖于浏览器的无障碍树(accessibility tree)以及基于“set-of-marks”的提示方式(set-of-marks prompting)。
- FileSurfer:基于 LLM 的智能体,用于驱动基于 Markdown 的文件预览应用以读取多种类型的本地文件。FileSurfer 还可执行常见的导航任务,例如列出目录内容和在文件夹结构中导航。
- Coder:通过系统提示(system prompt)进行专门化的 LLM 智能体,负责编写代码、分析由其他智能体收集的信息,以及创建新的产物(artifacts)。
- ComputerTerminal:为团队提供对控制台 shell 的访问,可在其中执行 Coder 所写的程序并安装新的编程库。
Magentic-One 的这些智能体为 Orchestrator 提供了解决各类开放式问题所需的工具与能力,同时能在动态且不断变化的网页与文件系统环境中自主适应与行动。
尽管我们为所有智能体默认使用的多模态 LLM 是 GPT-4o,Magentic-One 与具体模型无关(model-agnostic),可以整合异构模型以支持不同能力或满足不同的成本需求。例如,可以为不同智能体使用不同的 LLM 与 SLM 及其专门化版本。我们建议为 Orchestrator 配置一个推理能力强的模型(例如 GPT-4o)。在另一种 Magentic-One 配置中,我们也尝试将 OpenAI 的 o1-preview 用于 Orchestrator 的外循环和用于 Coder,而其他智能体则继续使用 GPT-4o。
Magentic-One 的本质
Magentic-One 是一个 多智能体系统 (multi-agent system)。
它不是一个单独的大模型,而是一个 “团队”,里面有多个不同的智能体(agents),每个智能体都有特定的技能,比如:
- Orchestrator:队长,负责制定计划、分工、检查任务进度。
- WebSurfer:浏览网页,执行点击、搜索、阅读网页内容。
- FileSurfer:读取和解析文件,浏览文件夹。
- Coder:写代码,分析数据,生成程序。
- ComputerTerminal:在命令行里运行代码、安装库。
这些智能体由 Orchestrator 调度,像一个项目经理带领团队一样。
它能解决什么问题?
Magentic-One 的目标是解决 开放式的、跨领域的复杂任务,比如:
-
跨网页和文件的任务
例如:“在某个学术网站上找到一篇论文,下载 PDF,然后总结内容。”- WebSurfer 打开网页并搜索论文
- FileSurfer 打开 PDF 文件
- Coder 把论文信息整理成结构化摘要
-
需要写代码并运行的任务
例如:“写一个 Python 脚本去某个 API 拉取天气数据并画图。”- Coder 写代码
- ComputerTerminal 运行代码
- Orchestrator 检查结果是否符合预期,不行就让 Coder 修改再运行
-
复杂推理的任务
例如 GAIA 基准测试里那种 “多步、多信息来源” 的问题,Orchestrator 会分解任务 → 分派 → 收集结果 → 动态调整计划。
它的特点
- 不是单个大模型,而是模型“团队”
各个 agent 可以用不同的模型(GPT-4o、轻量 SLM、专门化模型),互相配合。 - 自主规划和执行
Orchestrator 会不断反思任务进度(进度账本),如果失败就换新方案。 - 可扩展
你可以自己加新的 agent,比如 “数据库查询智能体”、“API 调用智能体”。 - 安全考虑
因为它可能真的会运行代码、打开网页,所以需要容器、沙箱和人工监督。
你可以把 Magentic-One 想象成一个 小型公司团队:
- Orchestrator = 项目经理
- WebSurfer = 网络调研员
- FileSurfer = 文档管理员
- Coder = 程序员
- ComputerTerminal = 运维人员
用户只需要对团队下达一个高层指令(比如“帮我查清楚东京天气趋势,并生成 Python 图表”),Orchestrator 就会分派任务给合适的“员工”,大家分工合作完成。
他和我们自己构建的多agent Team有什么区别?
-
架构成熟度
- 自己搭建
你需要手动写逻辑:怎么分工?怎么通信?怎么检查任务是否完成?失败怎么办?
→ 等于你在搭“框架”。 - Magentic-One
已经提供了一套 标准架构(Orchestrator + 多种专用 agent),而且内置了 任务账本(Task Ledger)和进度账本(Progress Ledger) 的循环机制。
→ 等于它帮你写好了“框架”,你只需组装和调用。
- 自己搭建
-
内置 Agent 能力
-
自己搭建
你可能需要自己封装浏览器(比如用 Playwright)、文件系统接口、代码执行沙箱。- 比如:写个 WebSurfer 需要处理 DOM、click、输入框,挺复杂。
-
Magentic-One
自带了这些能力:- WebSurfer(浏览网页)
- FileSurfer(读文件)
- Coder(写代码)
- ComputerTerminal(执行代码)
而且和 Orchestrator 紧密集成,拿来即用。
-
-
任务调度机制
-
自己搭建
可能只是几个 agent 并行/顺序运行,没有一个真正的“头脑”在动态检查和修改计划。 -
Magentic-One
Orchestrator 会:- 制定计划(Plan)
- 记录任务账本(Task Ledger)
- 自我反思(Progress Ledger)
- 动态调整计划(如果不顺利会重新规划)
→ 更接近人类项目经理的工作模式。
-
-
模型灵活性
-
自己搭建
你需要自己决定每个 agent 用哪个模型,通常不会考虑太多混搭。 -
Magentic-One
是 model-agnostic(模型无关):- 可以让 Orchestrator 用 GPT-4o(强推理)
- WebSurfer / FileSurfer 用小模型(省成本)
- Coder 用专门强化过的编程模型
→ 官方甚至试过让 Orchestrator 外循环跑在 o1-preview 上,内循环和其他 agent 继续用 GPT-4o。
-
-
安全性和工程化
-
自己搭建
你要自己考虑如何沙箱执行、限制网络访问、日志监控。 -
Magentic-One
官方已经明确了最佳实践:- 容器化(Docker)
- 虚拟环境隔离
- 审批机制(Approval Function)
- 人类监督
- 防 prompt injection
-
GraphFlow
AutoGen AgentChat 提供了一个用于有向图执行的团队:
- GraphFlow:这是一个遵循有向图(DiGraph)的团队,用于控制智能体之间的执行流程。它支持 顺序(sequential)、并行(parallel)、条件分支(conditional) 和 循环(looping) 行为。
何时使用 GraphFlow?
- 如果你需要严格控制智能体的执行顺序,或者不同的结果需要导致不同的后续步骤,就该使用 GraphFlow。
- 如果只是需要临时性的对话流,像 RoundRobinGroupChat 或 SelectorGroupChat 这样更简单的团队就足够了。
- 当你的任务需要确定性的控制、条件分支、或者处理包含循环的复杂多步骤流程时,就可以过渡到使用结构化工作流。
⚠️ 注意:GraphFlow 目前是实验性功能,它的 API、行为和功能在未来版本中可能会变化。
创建并运行 Flow
DiGraphBuilder 是一个流式(fluent)工具,可以轻松构建工作流的执行图。它支持构建:
- 顺序链(Sequential chains)
- 并行分支(Parallel fan-outs)
- 条件分支(Conditional branching)
- 带安全退出条件的循环(Loops with safe exit conditions)
在图中:
- 节点(node) 表示一个智能体
- 边(edge) 定义允许的执行路径
- 边还可以带有基于智能体消息的条件。
顺序流
我们先从一个简单的工作流开始:一个写作者(writer)撰写一段文字,然后一个审阅者(reviewer)提供反馈。当审阅者对写作者的内容做出评论后,这个图(workflow)就会终止。
注意:flow 会自动计算出图中的所有源节点(source nodes)和叶子节点(leaf nodes)。执行会从所有源节点开始,直到图中没有节点可以继续执行时,整个流程才会结束。
from autogen_agentchat.agents import AssistantAgent
from autogen_agentchat.teams import DiGraphBuilder, GraphFlow
from autogen_ext.models.openai import OpenAIChatCompletionClient# 创建 OpenAI 模型客户端
client = OpenAIChatCompletionClient(model="gpt-4.1-nano")# 创建写作者智能体
writer = AssistantAgent("writer", model_client=client, system_message="Draft a short paragraph on climate change.")# 创建审阅者智能体
reviewer = AssistantAgent("reviewer", model_client=client, system_message="Review the draft and suggest improvements.")# 构建图
builder = DiGraphBuilder()
builder.add_node(writer).add_node(reviewer)
builder.add_edge(writer, reviewer)# 构建并验证图
graph = builder.build()# 创建 flow
flow = GraphFlow([writer, reviewer], graph=graph)# 在脚本中运行时,用 asyncio.run(...) 包装,并放在 async 函数里
stream = flow.run_stream(task="Write a short paragraph about climate change.")
async for event in stream: # type: ignoreprint(event)# 在控制台使用 Console(flow.run_stream(...)) 可以得到更好的输出格式
执行过程输出示例:
source='user' models_usage=None metadata={} content='Write a short paragraph about climate change.' type='TextMessage'
source='writer' models_usage=RequestUsage(prompt_tokens=28, completion_tokens=95) metadata={} content='Climate change refers to long-term shifts in temperature, precipitation, and other atmospheric patterns, largely driven by human activities such as burning fossil fuels, deforestation, and industrial processes. These changes contribute to rising global temperatures, melting ice caps, more frequent and severe weather events, and adverse impacts on ecosystems and human communities. Addressing climate change requires global cooperation to reduce greenhouse gas emissions, transition to renewable energy sources, and implement sustainable practices to protect the planet for future generations.' type='TextMessage'
source='reviewer' models_usage=RequestUsage(prompt_tokens=127, completion_tokens=144) metadata={} content="The paragraph provides a clear overview of climate change, its causes, and its impacts. To enhance clarity and engagement, consider adding specific examples or emphasizing the urgency of action. Here's a revised version:\n\nClimate change is a long-term alteration of Earth's climate patterns caused primarily by human activities such as burning fossil fuels, deforestation, and industrial emissions. These actions increase greenhouse gases in the atmosphere, leading to rising global temperatures, melting ice caps, and more frequent extreme weather events like hurricanes and droughts. The effects threaten ecosystems, disrupt agriculture, and endanger communities worldwide. Addressing this crisis requires urgent, coordinated global efforts to reduce emissions, adopt renewable energy, and promote sustainable practices to safeguard the planet for future generations." type='TextMessage'
source='DiGraphStopAgent' models_usage=None metadata={} content='Digraph execution is complete' type='StopMessage'
messages=[TextMessage(source='user', models_usage=None, metadata={}, content='Write a short paragraph about climate change.', type='TextMessage'), TextMessage(source='writer', models_usage=RequestUsage(prompt_tokens=28, completion_tokens=95), metadata={}, content='Climate change refers to long-term shifts in temperature, precipitation, and other atmospheric patterns, largely driven by human activities such as burning fossil fuels, deforestation, and industrial processes. These changes contribute to rising global temperatures, melting ice caps, more frequent and severe weather events, and adverse impacts on ecosystems and human communities. Addressing climate change requires global cooperation to reduce greenhouse gas emissions, transition to renewable energy sources, and implement sustainable practices to protect the planet for future generations.', type='TextMessage'), TextMessage(source='reviewer', models_usage=RequestUsage(prompt_tokens=127, completion_tokens=144), metadata={}, content="The paragraph provides a clear overview of climate change, its causes, and its impacts. To enhance clarity and engagement, consider adding specific examples or emphasizing the urgency of action. Here's a revised version:\n\nClimate change is a long-term alteration of Earth's climate patterns caused primarily by human activities such as burning fossil fuels, deforestation, and industrial emissions. These actions increase greenhouse gases in the atmosphere, leading to rising global temperatures, melting ice caps, and more frequent extreme weather events like hurricanes and droughts. The effects threaten ecosystems, disrupt agriculture, and endanger communities worldwide. Addressing this crisis requires urgent, coordinated global efforts to reduce emissions, adopt renewable energy, and promote sustainable practices to safeguard the planet for future generations.", type='TextMessage'), StopMessage(source='DiGraphStopAgent', models_usage=None, metadata={}, content='Digraph execution is complete', type='StopMessage')] stop_reason='Stop message received'
user发出任务:“Write a short paragraph about climate change.”writer生成一段关于气候变化的短文reviewer对写作进行反馈和改进建议,并给出修改后的版本DiGraphStopAgent表示工作流执行完成
最终消息序列中包含了 用户输入、写作者输出、审阅者反馈、以及流程完成标志。
并行流
接下来我们创建一个稍微复杂一点的工作流:
- 写作者(writer) 撰写一段文字。
- 两个编辑(editor1 和 editor2) 分别对这段文字进行语法和风格上的修改(并行 fan-out)。
- 最终审阅者(final reviewer) 将这两份修改合并成最终版本(join)。
执行流程:从 writer 开始,结果会同时分发给 editor1 和 editor2,然后两者的输出再被送入 final reviewer。
from autogen_agentchat.agents import AssistantAgent
from autogen_agentchat.teams import DiGraphBuilder, GraphFlow
from autogen_agentchat.ui import Console
from autogen_ext.models.openai import OpenAIChatCompletionClient# 创建 OpenAI 模型客户端
client = OpenAIChatCompletionClient(model="gpt-4.1-nano")# 创建写作者
writer = AssistantAgent("writer", model_client=client, system_message="Draft a short paragraph on climate change.")# 创建两个编辑
editor1 = AssistantAgent("editor1", model_client=client, system_message="Edit the paragraph for grammar.")
editor2 = AssistantAgent("editor2", model_client=client, system_message="Edit the paragraph for style.")# 创建最终审阅者
final_reviewer = AssistantAgent("final_reviewer",model_client=client,system_message="Consolidate the grammar and style edits into a final version.",
)# 构建工作流图
builder = DiGraphBuilder()
builder.add_node(writer).add_node(editor1).add_node(editor2).add_node(final_reviewer)# 从 writer fan-out 到两个编辑
builder.add_edge(writer, editor1)
builder.add_edge(writer, editor2)# 两个编辑 fan-in 到最终审阅者
builder.add_edge(editor1, final_reviewer)
builder.add_edge(editor2, final_reviewer)# 构建并验证图
graph = builder.build()# 创建 flow
flow = GraphFlow(participants=builder.get_participants(),graph=graph,
)# 运行工作流
await Console(flow.run_stream(task="Write a short paragraph about climate change."))
执行过程输出示例:
- 用户输入:Write a short paragraph about climate change.
- writer:写了一段关于气候变化的文字。
- editor1:对文字进行语法修改。
- editor2:对文字进行风格修改。
- final_reviewer:整合两个编辑的修改,输出最终版本。
- DiGraphStopAgent:表示整个工作流执行完成。
最终结果是 一段由 writer 撰写、经过两个不同维度编辑,并由 final reviewer 汇总后的段落。
执行图 vs 消息图
在 GraphFlow 里,有两种图:
-
执行图 (Execution Graph)
用DiGraph定义,控制 Agent 执行的顺序。 -
消息图 (Message Graph)
执行图 不控制 Agent 接收哪些消息,默认情况下,所有消息会广播给所有 Agent。
为了避免信息过载或干扰,需要用 消息过滤 (Message Filtering) 来控制 Agent 能接收到的消息。
消息过滤的作用
通过限制每个 Agent 的输入消息,可以:
- 减少幻觉(避免 Agent 读到不相关的上下文)
- 降低内存开销
- 让 Agent 专注于相关信息
这时,你可以用:
MessageFilterAgentMessageFilterConfigPerSourceFilter
来定义规则。
from autogen_agentchat.agents import AssistantAgent, MessageFilterAgent, MessageFilterConfig, PerSourceFilter
from autogen_agentchat.teams import DiGraphBuilder, GraphFlow
from autogen_agentchat.ui import Console
from autogen_ext.models.openai import OpenAIChatCompletionClient# 模型客户端
client = OpenAIChatCompletionClient(model="gpt-4.1-nano")# 创建代理
researcher = AssistantAgent("researcher", model_client=client, system_message="总结气候变化的关键事实。"
)
analyst = AssistantAgent("analyst", model_client=client, system_message="审查总结并提出改进意见。")
presenter = AssistantAgent("presenter", model_client=client, system_message="基于最终总结准备一页演示幻灯片。"
)# 应用消息过滤
filtered_analyst = MessageFilterAgent(name="analyst",wrapped_agent=analyst,filter=MessageFilterConfig(per_source=[PerSourceFilter(source="researcher", position="last", count=1)]),
)filtered_presenter = MessageFilterAgent(name="presenter",wrapped_agent=presenter,filter=MessageFilterConfig(per_source=[PerSourceFilter(source="analyst", position="last", count=1)]),
)# 构建流程
builder = DiGraphBuilder()
builder.add_node(researcher).add_node(filtered_analyst).add_node(filtered_presenter)
builder.add_edge(researcher, filtered_analyst).add_edge(filtered_analyst, filtered_presenter)# 创建流程
flow = GraphFlow(participants=builder.get_participants(),graph=builder.build(),
)# 运行流程
await Console(flow.run_stream(task="Summarize key facts about climate change."))
执行过程输出
#### 用户请总结气候变化的关键事实。#### 研究员 (researcher)好的!以下是关于气候变化的一些关键事实:1. **全球变暖**:过去一个世纪,地球的平均地表温度显著上升,主要由人类活动导致。
2. **温室气体排放**:二氧化碳(CO₂)、甲烷(CH₄)、一氧化二氮(N₂O)是主要来源,来自燃烧化石燃料、森林砍伐和工业过程。
3. **天气与气候影响**:气候变化导致更频繁、更严重的热浪、风暴、干旱和强降雨。
4. **海平面上升**:极地冰盖和冰川融化,加上海水热膨胀,导致海平面上升。
5. **生态系统影响**:栖息地改变威胁动植物物种,导致生物多样性丧失。
6. **人类健康与社会**:气候变化造成健康问题、食物与水资源不安全、人口流离失所。
7. **全球应对**:巴黎协定等国际努力旨在限制温度上升,推动可再生能源,减少排放。
8. **紧迫性**:应对气候变化需要立即和协同的行动,以减缓进一步破坏并适应变化。如需更详细的信息,请告诉我!#### 分析员 (analyst)你的总结很好,涵盖了气候变化的基本方面,并且表达清晰。以下是改进建议:1. 用小标题增强结构,例如(原因、影响、应对)。
2. 增加最新数据或事件,强调紧迫性。
3. 更突出解决方案,而不仅仅是国际协定。
4. 用更精准的语言,例如指出全球升温大约 **1.2°C**。
5. 强调个人行动的重要性。
6. 简单说明气候反馈循环,例如冰川融化会加速升温。改进后的版本:**气候变化概述****原因:*** 人类活动(燃烧化石燃料、森林砍伐、工业过程)导致温室气体增加(CO₂、CH₄、N₂O)。
* 自 19 世纪末以来,地球平均气温已上升约 **1.2°C**,过去十年是有记录以来最热的时期。**影响:*** 更频繁、更强烈的热浪、风暴、干旱和强降雨。
* 极地冰盖和冰川融化,海水热膨胀,导致海平面上升,威胁沿海社区。
* 生态系统迁移,栖息地丧失,物种面临灭绝。
* 人类健康受威胁(中暑、粮食/水资源不安全、灾害导致的流离失所)。**全球应对与解决方案:*** 巴黎协定等国际协议旨在将全球升温控制在 **2°C 以下**。
* 策略包括发展可再生能源、提高能效、重新造林、可持续土地利用。
* 社区和个人行动同样关键(减少碳足迹、支持可持续政策、提高公众意识)。**紧迫性与行动呼吁:*** 必须立即采取协调一致的努力,否则会造成不可逆的破坏。
* 各个层级(政府、企业、个人)都必须行动,共建可持续未来。需要更详细的数据或更深入的解释吗?#### 演讲者 (presenter)**幻灯片标题:**
**气候变化:原因、影响与解决方案****原因:*** 燃烧化石燃料、森林砍伐、工业活动
* 温室气体(CO₂、CH₄、N₂O)显著增加
* 全球气温自工业化前上升约 **1.2°C****影响:*** 更频繁的热浪、风暴、干旱和强降雨
* 冰盖融化、海平面上升,威胁沿海地区
* 栖息地丧失、生物多样性下降
* 健康风险与社会动荡**应对与解决方案:*** 巴黎协定等国际努力
* 可再生能源、能效提升、再造林
* 社区和个人行动:减少碳足迹、提升意识**紧迫性:*** 必须立即采取协调行动,避免不可逆转的破坏
* 人人都在建设可持续未来中扮演角色
例子里构建了一个研究-分析-展示的工作流:
- researcher:总结气候变化的关键事实
- analyst:审查并改进总结
- presenter:根据分析结果做演示幻灯片
👉 默认情况下,presenter 会收到 researcher 和 analyst 的消息。但通过 消息过滤,我们规定:
- analyst 只看 researcher 的最后一条消息
- presenter 只看 analyst 的最后一条消息
这样,数据流更“干净”,每个 Agent 都不会被额外的上下文干扰。
🔁 高级货:条件循环 + 过滤总结
该示例演示了:
- 在 生成器 和 审阅者 之间的循环(当审阅者说 “APPROVE” 时退出);
- 一个 总结器代理,它只会看到用户的第一次输入和审阅者的最后一条消息。
from autogen_agentchat.agents import AssistantAgent, MessageFilterAgent, MessageFilterConfig, PerSourceFilter
from autogen_agentchat.teams import (DiGraphBuilder,GraphFlow,
)
from autogen_agentchat.conditions import MaxMessageTermination
from autogen_agentchat.ui import Console
from autogen_ext.models.openai import OpenAIChatCompletionClientmodel_client = OpenAIChatCompletionClient(model="gpt-4o-mini")# 代理
generator = AssistantAgent("generator", model_client=model_client, system_message="生成一份创意点子清单。")
reviewer = AssistantAgent("reviewer",model_client=model_client,system_message="审阅点子并提供反馈,或仅回复 'APPROVE' 表示最终通过。"
)
summarizer_core = AssistantAgent("summary", model_client=model_client, system_message="总结用户请求和最终反馈。"
)# 过滤后的总结器
filtered_summarizer = MessageFilterAgent(name="summary",wrapped_agent=summarizer_core,filter=MessageFilterConfig(per_source=[PerSourceFilter(source="user", position="first", count=1),PerSourceFilter(source="reviewer", position="last", count=1),]),
)# 构建带条件循环的图
builder = DiGraphBuilder()
builder.add_node(generator).add_node(reviewer).add_node(filtered_summarizer)
builder.add_edge(generator, reviewer)
builder.add_edge(reviewer, filtered_summarizer, condition=lambda msg: "APPROVE" in msg.to_model_text())
builder.add_edge(reviewer, generator, condition=lambda msg: "APPROVE" not in msg.to_model_text())
builder.set_entry_point(generator) # 设置入口点为生成器。如果没有源节点这是必须的。
graph = builder.build()termination_condition = MaxMessageTermination(10)# 创建流程
flow = GraphFlow(participants=builder.get_participants(),graph=graph,termination_condition=termination_condition
)# 在控制台中运行流程并美观打印输出
await Console(flow.run_stream(task="头脑风暴如何减少塑料垃圾。"))
输出展示了:
- 用户请求(减少塑料垃圾的点子);
- 生成器输出 20 条创意建议;
- 审阅者逐条反馈并最终 APPROVE;
- 总结器输出一个简明总结,只结合了用户请求与审阅者的最终意见。
🔁 高级货:带激活组的循环
以下示例展示了如何使用 activation_group 和 activation_condition 来处理循环图中的复杂依赖关系模式,尤其是在多个路径指向同一个目标节点的情况下。
示例 1:多路径循环 —— “All” 激活 (A→B→C→B)
在此场景中,我们有 A → B → C → B,其中 B 有两个入边(来自 A 和 C)。
默认情况下,B 在执行前需要满足 所有依赖。
这个例子展示了一个审阅循环:在 B 再次执行之前,必须同时处理初始输入(A)和反馈(C)。
from autogen_agentchat.agents import AssistantAgent
from autogen_agentchat.teams import DiGraphBuilder, GraphFlow
from autogen_agentchat.conditions import MaxMessageTermination
from autogen_agentchat.ui import Console
from autogen_ext.models.openai import OpenAIChatCompletionClient# Model client
client = OpenAIChatCompletionClient(model="gpt-4o-mini")# Create agents for A→B→C→B→E scenario
agent_a = AssistantAgent("A", model_client=client, system_message="Start the process and provide initial input.")
agent_b = AssistantAgent("B",model_client=client,system_message="Process input from A or feedback from C. Say 'CONTINUE' if it's from A or 'STOP' if it's from C.",
)
agent_c = AssistantAgent("C", model_client=client, system_message="Review B's output and provide feedback.")
agent_e = AssistantAgent("E", model_client=client, system_message="Finalize the process.")# Build the graph with activation groups
builder = DiGraphBuilder()
builder.add_node(agent_a).add_node(agent_b).add_node(agent_c).add_node(agent_e)# A → B (initial path)
builder.add_edge(agent_a, agent_b, activation_group="initial")# B → C
builder.add_edge(agent_b, agent_c, condition="CONTINUE")# C → B (loop back - different activation group)
builder.add_edge(agent_c, agent_b, activation_group="feedback")# B → E (exit condition)
builder.add_edge(agent_b, agent_e, condition="STOP")termination_condition = MaxMessageTermination(10)
# Build and create flow
graph = builder.build()
flow = GraphFlow(participants=[agent_a, agent_b, agent_c, agent_e], graph=graph, termination_condition=termination_condition)print("=== Example 1: A→B→C→B with 'All' Activation ===")
print("B will exit when it receives a message from C")
# await Console(flow.run_stream(task="Start a review process for a document."))
👉 效果:B 会在收到 C 的反馈后才会再次执行,并最终在收到 "STOP" 时退出。
示例 2:多路径循环 —— “Any” 激活 (A→B→(C1,C2)→B)
在这个更复杂的场景中:
- B 同时分支到 C1 和 C2(并行);
- C1 和 C2 都会反馈到 B;
- B 使用 “any” 激活 —— 一旦 C1 或 C2 完成,就会立即触发 B 的执行。
这适用于你希望 最快的反馈 推动下一步的场景。
# Create agents for A→B→(C1,C2)→B scenario
agent_a2 = AssistantAgent("A", model_client=client, system_message="Initiate a task that needs parallel processing.")
agent_b2 = AssistantAgent("B",model_client=client,system_message="Coordinate parallel tasks. Say 'PROCESS' to start parallel work or 'DONE' to finish.",
)
agent_c1 = AssistantAgent("C1", model_client=client, system_message="Handle task type 1. Say 'C1_COMPLETE' when done.")
agent_c2 = AssistantAgent("C2", model_client=client, system_message="Handle task type 2. Say 'C2_COMPLETE' when done.")
agent_e = AssistantAgent("E", model_client=client, system_message="Finalize the process.")# Build the graph with "any" activation
builder2 = DiGraphBuilder()
builder2.add_node(agent_a2).add_node(agent_b2).add_node(agent_c1).add_node(agent_c2).add_node(agent_e)# A → B (initial)
builder2.add_edge(agent_a2, agent_b2)# B → C1 and B → C2 (parallel fan-out)
builder2.add_edge(agent_b2, agent_c1, condition="PROCESS")
builder2.add_edge(agent_b2, agent_c2, condition="PROCESS")# B → E (exit condition)
builder2.add_edge(agent_b2, agent_e, condition=lambda msg: "DONE" in msg.to_model_text())# C1 → B and C2 → B (both in same activation group with "any" condition)
builder2.add_edge(agent_c1, agent_b2, activation_group="loop_back_group", activation_condition="any", condition="C1_COMPLETE"
)builder2.add_edge(agent_c2, agent_b2, activation_group="loop_back_group", activation_condition="any", condition="C2_COMPLETE"
)# Build and create flow
graph2 = builder2.build()
flow2 = GraphFlow(participants=[agent_a2, agent_b2, agent_c1, agent_c2, agent_e], graph=graph2)print("=== Example 2: A→B→(C1,C2)→B with 'Any' Activation ===")
print("B will execute as soon as EITHER C1 OR C2 completes (whichever finishes first)")
# await Console(flow2.run_stream(task="Start a parallel processing task."))
👉 效果:B 会在 C1 或 C2 任意一个完成时立即执行。
示例 3:混合激活组
这个例子展示了 不同激活组可以共存:
- D 节点从多个来源接收输入;
- 某些依赖需要 “all” 激活(必须等待所有输入);
- 其他依赖使用 “any” 激活(任意一个输入即可继续)。
适用于 复杂工作流,其中不同类型的依赖具有不同的紧急程度。
# Create agents for mixed activation scenario
agent_a3 = AssistantAgent("A", model_client=client, system_message="Provide critical input that must be processed.")
agent_b3 = AssistantAgent("B", model_client=client, system_message="Provide secondary critical input.")
agent_c3 = AssistantAgent("C", model_client=client, system_message="Provide optional quick input.")
agent_d3 = AssistantAgent("D", model_client=client, system_message="Process inputs based on different priority levels.")# Build graph with mixed activation groups
builder3 = DiGraphBuilder()
builder3.add_node(agent_a3).add_node(agent_b3).add_node(agent_c3).add_node(agent_d3)# Critical inputs that must ALL be present (activation_group="critical", activation_condition="all")
builder3.add_edge(agent_a3, agent_d3, activation_group="critical", activation_condition="all")
builder3.add_edge(agent_b3, agent_d3, activation_group="critical", activation_condition="all")# Optional input that can trigger execution on its own (activation_group="optional", activation_condition="any")
builder3.add_edge(agent_c3, agent_d3, activation_group="optional", activation_condition="any")# Build and create flow
graph3 = builder3.build()
flow3 = GraphFlow(participants=[agent_a3, agent_b3, agent_c3, agent_d3], graph=graph3)print("=== Example 3: Mixed Activation Groups ===")
print("D will execute when:")
print("- BOTH A AND B complete (critical group with 'all' activation), OR")
print("- C completes (optional group with 'any' activation)")
print("This allows for both required dependencies and fast-path triggers.")
# await Console(flow3.run_stream(task="Process inputs with mixed priority levels."))
👉 效果:
- 当 A 和 B 都完成 时,D 执行;
- 或者当 C 完成 时,D 立即执行。
激活组要点
-
activation_group:把指向同一目标节点的边分组,以定义不同的依赖模式。
-
activation_condition:
"all"(默认):目标节点必须等待该组内 所有边 满足条件"any":目标节点在该组内 任意一条边 满足条件即可执行
适用场景
- 多入口循环:不同激活组避免依赖冲突
- 基于优先级的执行:不同紧急程度可混合使用 “all” 和 “any”
- 并行处理 + 快速返回:用 “any” 在最快结果完成时继续流程
最佳实践
- 使用有意义的组名(如
"critical"、"optional"、"feedback"等) - 同一组内保持激活条件一致
- 用不同执行路径测试图逻辑
这些模式可以在保持执行语义清晰可理解的同时,实现复杂工作流的精细化控制。
记忆与 RAG
在某些用例中,维护一个有用事实的存储库,并在某个特定步骤前智能地将其添加到代理的上下文中非常有价值。一个典型的用例是 RAG 模式,其中使用查询从数据库检索相关信息,然后将这些信息添加到代理的上下文中。
AgentChat 提供了一个 Memory 协议,它可以扩展以实现这种功能。核心方法包括:
- add:向记忆存储中添加新条目
- query:从记忆存储中检索相关信息
- update_context:通过添加检索到的信息来修改代理的
model_context(在AssistantAgent类中使用) - clear:清除记忆存储中的所有条目
- close:清理记忆存储所使用的任何资源
ListMemory 示例
ListMemory 是 Memory 协议的一个示例实现。
它是一个基于列表的简单记忆存储,按时间顺序保存记忆,并将最近的记忆追加到模型上下文中。
该实现被设计为 直观且可预测,易于理解和调试。
在以下示例中,我们使用 ListMemory 来维护一个用户偏好的记忆库,并演示它如何为代理提供持续一致的上下文,从而生成个性化的响应。
from autogen_agentchat.agents import AssistantAgent
from autogen_agentchat.ui import Console
from autogen_core.memory import ListMemory, MemoryContent, MemoryMimeType
from autogen_ext.models.openai import OpenAIChatCompletionClient# 初始化用户记忆
user_memory = ListMemory()# 添加用户偏好
await user_memory.add(MemoryContent(content="天气应使用公制单位", mime_type=MemoryMimeType.TEXT))
await user_memory.add(MemoryContent(content="菜谱必须是纯素食", mime_type=MemoryMimeType.TEXT))# 示例工具函数
async def get_weather(city: str, units: str = "imperial") -> str:if units == "imperial":return f"{city} 的天气是 73 °F,晴朗。"elif units == "metric":return f"{city} 的天气是 23 °C,晴朗。"else:return f"抱歉,我不知道 {city} 的天气。"# 初始化代理
assistant_agent = AssistantAgent(name="assistant_agent",model_client=OpenAIChatCompletionClient(model="gpt-4o-2024-08-06"),tools=[get_weather],memory=[user_memory],
)# 运行代理
stream = assistant_agent.run_stream(task="纽约的天气怎么样?")
await Console(stream)
运行过程:
---------- TextMessage (user) ----------
纽约的天气怎么样?---------- MemoryQueryEvent (assistant_agent) ----------
[记忆: 天气应使用公制单位, 记忆: 菜谱必须是纯素食]---------- ToolCallRequestEvent (assistant_agent) ----------
调用工具 get_weather(city="New York", units="metric")---------- ToolCallExecutionEvent (assistant_agent) ----------
结果: "纽约的天气是 23 °C,晴朗。"---------- ToolCallSummaryMessage (assistant_agent) ----------
纽约的天气是 23 °C,晴朗。
我们可以检查 assistant_agent 的 model_context 实际上被更新了:
await assistant_agent._model_context.get_messages()
[UserMessage(content='纽约的天气怎么样?'),SystemMessage(content='\n相关记忆(按时间顺序):\n1. 天气应使用公制单位\n2. 菜谱必须是纯素食\n'),AssistantMessage(content=[FunctionCall(..., arguments='{"city":"New York","units":"metric"}', name='get_weather')]),FunctionExecutionResultMessage(content=[FunctionExecutionResult(content='纽约的天气是 23 °C,晴朗。')])
]
由此可见,天气结果是以 摄氏度 返回的,符合用户的偏好。
第二个例子:菜谱生成
stream = assistant_agent.run_stream(task="写一个简短的汤底菜谱")
await Console(stream)
输出结果:
---------- TextMessage (user) ----------
写一个简短的汤底菜谱---------- MemoryQueryEvent (assistant_agent) ----------
[记忆: 天气应使用公制单位, 记忆: 菜谱必须是纯素食]---------- TextMessage (assistant_agent) ----------
这里有一个简短的纯素汤底菜谱:**纯素蔬菜汤底**配料:
- 橄榄油 1 大勺
- 洋葱 1 个,切碎
- 大蒜 3 瓣,切末
- 胡萝卜 2 根,切片
- 芹菜 2 根,切片
- 西葫芦 1 个,切块
- 蘑菇 1 杯,切片
- 羽衣甘蓝或菠菜 1 杯,切碎
- 番茄丁罐头 400g
- 蔬菜汤 4 杯
- 百里香 1 茶匙
- 盐和胡椒粉,适量
- 香菜碎,适量(装饰)步骤:
1. 中火加热橄榄油,炒洋葱和大蒜至变软。
2. 加入胡萝卜、芹菜、西葫芦和蘑菇,煮约 5 分钟。
3. 加入番茄丁、蔬菜汤和百里香,煮沸。
4. 调小火炖 20 分钟,直到蔬菜变软。
5. 加入羽衣甘蓝或菠菜,再煮 5 分钟。
6. 加盐和胡椒调味。
7. 撒上香菜后热食。 享受这碗暖心的纯素蔬菜汤吧!
✅ 可以看到,代理在回答时自动检索了 用户的饮食偏好(纯素食),并生成了符合要求的菜谱。
自定义记忆存储(向量数据库等)
你可以基于 Memory 协议 来实现更复杂的记忆存储。例如:
- 使用 向量数据库 来存储和检索信息;
- 使用 机器学习模型 来根据用户偏好生成个性化的响应。
要实现这种功能,需要重写以下方法:
- add:向记忆存储中添加条目
- query:从记忆存储中检索条目
- update_context:将检索到的内容更新到代理的
model_context中
并在初始化代理时传入自定义的记忆存储。
目前,在 autogen_ext 扩展包中提供了以下记忆存储实现:
-
autogen_ext.memory.chromadb.ChromaDBVectorMemory
使用 ChromaDB 向量数据库 存储和检索信息。 -
autogen_ext.memory.chromadb.SentenceTransformerEmbeddingFunctionConfig
配置类,用于指定ChromaDBVectorMemory的嵌入模型(如all-MiniLM-L6-v2)。
也可以替换为其他嵌入函数,例如autogen_ext.memory.openai.OpenAIEmbeddingFunctionConfig。 -
autogen_ext.memory.redis.RedisMemory
使用 Redis 向量数据库 存储和检索信息。
示例:使用 ChromaDBVectorMemory
import tempfilefrom autogen_agentchat.agents import AssistantAgent
from autogen_agentchat.ui import Console
from autogen_core.memory import MemoryContent, MemoryMimeType
from autogen_ext.memory.chromadb import (ChromaDBVectorMemory,PersistentChromaDBVectorMemoryConfig,SentenceTransformerEmbeddingFunctionConfig,
)
from autogen_ext.models.openai import OpenAIChatCompletionClient# 使用临时目录存储 ChromaDB 数据
with tempfile.TemporaryDirectory() as tmpdir:chroma_user_memory = ChromaDBVectorMemory(config=PersistentChromaDBVectorMemoryConfig(collection_name="preferences",persistence_path=tmpdir, # 临时存储目录k=2, # 返回相似度最高的前 2 条结果score_threshold=0.4, # 最小相似度阈值embedding_function_config=SentenceTransformerEmbeddingFunctionConfig(model_name="all-MiniLM-L6-v2" # 默认测试模型),))# 添加用户偏好await chroma_user_memory.add(MemoryContent(content="天气应使用公制单位",mime_type=MemoryMimeType.TEXT,metadata={"category": "preferences", "type": "units"},))await chroma_user_memory.add(MemoryContent(content="菜谱必须是纯素食",mime_type=MemoryMimeType.TEXT,metadata={"category": "preferences", "type": "dietary"},))# 初始化模型客户端model_client = OpenAIChatCompletionClient(model="gpt-4o")# 创建带有 ChromaDB 记忆的助手代理assistant_agent = AssistantAgent(name="assistant_agent",model_client=model_client,tools=[get_weather], # 示例工具函数memory=[chroma_user_memory], # 挂载 ChromaDB 记忆)# 运行任务stream = assistant_agent.run_stream(task="纽约的天气怎么样?")await Console(stream)await model_client.close()await chroma_user_memory.close()
示例运行输出
---------- TextMessage (user) ----------
纽约的天气怎么样?---------- MemoryQueryEvent (assistant_agent) ----------
[检索结果: '天气应使用公制单位' (相似度 0.43), '天气应使用公制单位' (相似度 0.43)]---------- ToolCallRequestEvent (assistant_agent) ----------
调用工具 get_weather(city="New York", units="metric")---------- ToolCallExecutionEvent (assistant_agent) ----------
结果: '纽约的天气是 23 °C,晴朗。'---------- ToolCallSummaryMessage (assistant_agent) ----------
纽约的天气是 23 °C,晴朗。
你还可以将 ChromaDBVectorMemory 序列化并保存到磁盘:
chroma_user_memory.dump_component().model_dump_json()
示例输出(部分):
{"provider": "autogen_ext.memory.chromadb.ChromaDBVectorMemory","component_type": "memory","version": 1,"label": "ChromaDBVectorMemory","config": {"client_type": "persistent","collection_name": "preferences","distance_metric": "cosine","k": 2,"score_threshold": 0.4,"persistence_path": "/path/to/.chromadb_autogen"}
}
Redis Memory
你也可以使用 Redis 来实现持久化记忆存储。
需要注意:你必须有一个正在运行的 Redis 实例才能连接使用。
示例代码
from logging import WARNING, getLoggerfrom autogen_agentchat.agents import AssistantAgent
from autogen_agentchat.ui import Console
from autogen_core.memory import MemoryContent, MemoryMimeType
from autogen_ext.memory.redis import RedisMemory, RedisMemoryConfig
from autogen_ext.models.openai import OpenAIChatCompletionClientlogger = getLogger()
logger.setLevel(WARNING)# 初始化 Redis 记忆存储
redis_memory = RedisMemory(config=RedisMemoryConfig(redis_url="redis://localhost:6379", # Redis 连接地址index_name="chat_history", # 索引名称prefix="memory", # 键名前缀)
)# 添加用户偏好
await redis_memory.add(MemoryContent(content="天气应使用公制单位",mime_type=MemoryMimeType.TEXT,metadata={"category": "preferences", "type": "units"},)
)await redis_memory.add(MemoryContent(content="菜谱必须是纯素食",mime_type=MemoryMimeType.TEXT,metadata={"category": "preferences", "type": "dietary"},)
)# 初始化模型客户端
model_client = OpenAIChatCompletionClient(model="gpt-4o")# 创建带有 Redis 记忆的助手代理
assistant_agent = AssistantAgent(name="assistant_agent",model_client=model_client,tools=[get_weather],memory=[redis_memory],
)# 执行任务
stream = assistant_agent.run_stream(task="纽约的天气怎么样?")
await Console(stream)# 关闭资源
await model_client.close()
await redis_memory.close()
示例运行输出
---------- TextMessage (user) ----------
纽约的天气怎么样?---------- MemoryQueryEvent (assistant_agent) ----------
[记忆检索结果: "天气应使用公制单位"]---------- ToolCallRequestEvent (assistant_agent) ----------
调用工具 get_weather(city="New York", units="metric")---------- ToolCallExecutionEvent (assistant_agent) ----------
结果: "纽约的天气是 23 °C,晴朗。"---------- ToolCallSummaryMessage (assistant_agent) ----------
纽约的天气是 23 °C,晴朗。
RedisMemory 的优势在于:
- 持久化:即使代理或服务重启,记忆依然保存;
- 可扩展性:支持多客户端共享同一记忆;
- 高性能:适合大规模、快速查询的场景。
RAG Agent: 综合应用
RAG(检索增强生成,Retrieval Augmented Generation) 模式在构建 AI 系统时非常常见,它包含两个明确的阶段:
- 索引阶段(Indexing):加载文档,对文档进行切分(chunking),并存储到向量数据库中。
- 检索阶段(Retrieval):在对话运行时找到并使用相关的文档片段。
在之前的示例中,我们是手动将条目加入记忆并传递给代理。在实际场景中,索引过程通常是自动化的,并且基于更大规模的文档来源(如产品文档、内部文件或知识库)。
⚠️ 注意:一个 RAG 系统的效果高度依赖于 chunking 与检索的质量(模型、embedding 等)。为了获得最佳效果,你可能需要尝试更高级的文本切分与检索模型。
构建一个简单的 RAG Agent
首先,我们创建一个简单的文档索引器,用来加载文档、切分文本,并将其存储到 ChromaDBVectorMemory 记忆存储中。
import re
from typing import Listimport aiofiles
import aiohttp
from autogen_core.memory import Memory, MemoryContent, MemoryMimeTypeclass SimpleDocumentIndexer:"""AutoGen Memory 的基础文档索引器"""def __init__(self, memory: Memory, chunk_size: int = 1500) -> None:self.memory = memoryself.chunk_size = chunk_sizeasync def _fetch_content(self, source: str) -> str:"""从 URL 或文件读取内容"""if source.startswith(("http://", "https://")):async with aiohttp.ClientSession() as session:async with session.get(source) as response:return await response.text()else:async with aiofiles.open(source, "r", encoding="utf-8") as f:return await f.read()def _strip_html(self, text: str) -> str:"""移除 HTML 标签并规范空白符"""text = re.sub(r"<[^>]*>", " ", text)text = re.sub(r"\s+", " ", text)return text.strip()def _split_text(self, text: str) -> List[str]:"""将文本按固定大小切分"""chunks: list[str] = []for i in range(0, len(text), self.chunk_size):chunk = text[i : i + self.chunk_size]chunks.append(chunk.strip())return chunksasync def index_documents(self, sources: List[str]) -> int:"""将文档索引到 memory"""total_chunks = 0for source in sources:try:content = await self._fetch_content(source)# 如果看起来是 HTML 文本,先清理标签if "<" in content and ">" in content:content = self._strip_html(content)chunks = self._split_text(content)for i, chunk in enumerate(chunks):await self.memory.add(MemoryContent(content=chunk,mime_type=MemoryMimeType.TEXT,metadata={"source": source, "chunk_index": i},))total_chunks += len(chunks)except Exception as e:print(f"索引 {source} 出错: {str(e)}")return total_chunks
使用 ChromaDBVectorMemory 构建完整的 RAG Agent
import os
from pathlib import Pathfrom autogen_agentchat.agents import AssistantAgent
from autogen_agentchat.ui import Console
from autogen_ext.memory.chromadb import (ChromaDBVectorMemory,PersistentChromaDBVectorMemoryConfig,
)
from autogen_ext.models.openai import OpenAIChatCompletionClient# 初始化向量记忆存储
rag_memory = ChromaDBVectorMemory(config=PersistentChromaDBVectorMemoryConfig(collection_name="autogen_docs",persistence_path=os.path.join(str(Path.home()), ".chromadb_autogen"),k=3, # 返回前 3 个结果score_threshold=0.4, # 相似度阈值)
)await rag_memory.clear() # 清空已有记忆# 索引 AutoGen 文档
async def index_autogen_docs() -> None:indexer = SimpleDocumentIndexer(memory=rag_memory)sources = ["https://raw.githubusercontent.com/microsoft/autogen/main/README.md","https://microsoft.github.io/autogen/dev/user-guide/agentchat-user-guide/tutorial/agents.html","https://microsoft.github.io/autogen/dev/user-guide/agentchat-user-guide/tutorial/teams.html","https://microsoft.github.io/autogen/dev/user-guide/agentchat-user-guide/tutorial/termination.html",]chunks: int = await indexer.index_documents(sources)print(f"已从 {len(sources)} 个 AutoGen 文档中索引 {chunks} 个片段")await index_autogen_docs()
# 输出: 已从 4 个 AutoGen 文档中索引 70 个片段# 创建 RAG 助手代理
rag_assistant = AssistantAgent(name="rag_assistant",model_client=OpenAIChatCompletionClient(model="gpt-4o"),memory=[rag_memory],
)# 向代理提问
stream = rag_assistant.run_stream(task="What is AgentChat?")
await Console(stream)# 完成后关闭 memory
await rag_memory.close()
示例运行输出
---------- TextMessage (user) ----------
What is AgentChat?---------- MemoryQueryEvent (rag_assistant) ----------
[检索到的文档片段……]---------- TextMessage (rag_assistant) ----------
AgentChat 是一个框架,提供一组预设代理(preset agents),
它们支持不同的对话和任务处理策略。
它还支持团队协作(multi-agent teams),用于处理复杂目标。
这个 RAG Agent 能够基于 AutoGen 文档回答问题。运行流程是:
- Memory 系统先检索相关文档片段
- 将片段加入上下文
- 代理基于检索到的知识生成回答
在生产系统中,你可能还需要:
- 实现更高级的 chunking 策略
- 增加 基于元数据的过滤
- 自定义 检索打分机制
- 优化 embedding 模型,以适应特定领域
Mem0Memory 示例
autogen_ext.memory.mem0.Mem0Memory 提供了与 Mem0.ai 记忆系统的集成。它支持 云端 和 本地 两种后端,并为代理提供了高级记忆能力。
该实现能够正确处理检索与上下文更新,非常适合生产环境。
下面的示例展示了如何使用 Mem0Memory 在多轮对话中保持持久化记忆:
from autogen_agentchat.agents import AssistantAgent
from autogen_agentchat.ui import Console
from autogen_core.memory import MemoryContent, MemoryMimeType
from autogen_ext.memory.mem0 import Mem0Memory
from autogen_ext.models.openai import OpenAIChatCompletionClient# 初始化 Mem0 云端记忆 (需要 API key)
# 本地部署时,可使用 is_cloud=False,并提供相应配置
mem0_memory = Mem0Memory(is_cloud=True,limit=5, # 最多检索 5 条记忆
)# 添加用户偏好
await mem0_memory.add(MemoryContent(content="天气应使用公制单位",mime_type=MemoryMimeType.TEXT,metadata={"category": "preferences", "type": "units"},)
)await mem0_memory.add(MemoryContent(content="菜谱必须是纯素食",mime_type=MemoryMimeType.TEXT,metadata={"category": "preferences", "type": "dietary"},)
)# 创建带有 Mem0 记忆的助手
assistant_agent = AssistantAgent(name="assistant_agent",model_client=OpenAIChatCompletionClient(model="gpt-4o-2024-08-06",),tools=[get_weather],memory=[mem0_memory],
)# 提问
stream = assistant_agent.run_stream(task="我的饮食偏好是什么?")
await Console(stream)
在上面的示例中,Mem0Memory 与助手代理结合,实现了以下特性:
- 所有与代理的交互都会被存储到 Mem0,供未来调用
- 相关记忆(如用户偏好)会被自动检索并加入上下文
- 代理能够基于存储的记忆维持一致的行为
Mem0Memory 特别适用的场景
- 长期运行的代理,需要持久化记忆
- 需要增强隐私控制的应用
- 团队协作,需要多个代理共享统一记忆
- 需要高级过滤与分析的记忆管理场景
与 ChromaDBVectorMemory 类似,你也可以序列化 Mem0Memory 配置:
# 序列化内存配置
config_json = mem0_memory.dump_component().model_dump_json()
print(f"Memory config JSON: {config_json[:100]}...")
Mem0Memory 是 一个内存(记忆)存储模块,来自 Mem0.ai 的生态。
具体来说:
-
Mem0.ai 是一家提供 记忆基础设施(Memory Infrastructure) 的公司/平台,目标是让 AI 代理具备类似人类的长期记忆能力。
-
Mem0Memory 是 AutoGen 里的一个适配器类(在
autogen_ext.memory.mem0里),它把代理的记忆读写功能对接到 Mem0.ai 的系统中。 -
它的特点是:
- 可以选择 云端模式(使用 Mem0.ai 托管的记忆服务,需要 API Key);
- 也可以选择 本地部署模式,在你自己的环境里运行 Mem0 服务;
- 支持检索、更新上下文、过滤、分析等高级功能;
- 特别适合 长时间运行的 AI 助手 / 团队协作的多代理系统。
日志记录
AutoGen 使用 Python 内置的 logging 模块。
要为 AgentChat 启用日志记录,可以使用以下代码:
import loggingfrom autogen_agentchat import EVENT_LOGGER_NAME, TRACE_LOGGER_NAMElogging.basicConfig(level=logging.WARNING)# 用于跟踪日志。
trace_logger = logging.getLogger(TRACE_LOGGER_NAME)
trace_logger.addHandler(logging.StreamHandler())
trace_logger.setLevel(logging.DEBUG)# 用于结构化消息日志,例如代理之间的底层消息。
event_logger = logging.getLogger(EVENT_LOGGER_NAME)
event_logger.addHandler(logging.StreamHandler())
event_logger.setLevel(logging.DEBUG)
序列化组件
AutoGen 提供了一个 Component 配置类,用于定义如何将组件序列化/反序列化为声明式规范。
我们可以分别通过 .dump_component() 和 .load_component() 来实现。
这种方式对 调试、可视化,甚至 与他人共享工作 都很有用。
⚠️ 警告
只从可信来源加载组件!
序列化的组件中,每个组件都实现了自己的序列化与反序列化逻辑:
- 如何生成声明式规范
- 如何从规范恢复为对象
在某些情况下,创建对象可能会涉及执行代码(例如:序列化的函数)。因此请务必 只从可信来源加载组件!
💡 注意
selector_func 不可序列化,在序列化和反序列化过程中会被忽略。
终止条件示例
下面的示例中,我们在 Python 中定义了终止条件(代理团队的一部分),
导出为字典/JSON,并展示了如何从字典/JSON 中重新加载对象。
from autogen_agentchat.conditions import MaxMessageTermination, StopMessageTerminationmax_termination = MaxMessageTermination(5)
stop_termination = StopMessageTermination()or_termination = max_termination | stop_terminationor_term_config = or_termination.dump_component()
print("Config: ", or_term_config.model_dump_json())new_or_termination = or_termination.load_component(or_term_config)
输出示例:
{"provider": "autogen_agentchat.base.OrTerminationCondition","component_type": "termination","version": 1,"component_version": 1,"description": null,"config": {"conditions": [{"provider": "autogen_agentchat.conditions.MaxMessageTermination","component_type": "termination","version": 1,"component_version": 1,"config": { "max_messages": 5 }},{"provider": "autogen_agentchat.conditions.StopMessageTermination","component_type": "termination","version": 1,"component_version": 1,"config": {}}]}
}
代理示例
下面的示例中,我们在 Python 中定义了一个代理,
导出为字典/JSON,并展示了如何从字典/JSON 中重新加载对象。
from autogen_agentchat.agents import AssistantAgent, UserProxyAgent
from autogen_ext.models.openai import OpenAIChatCompletionClient# 创建一个使用 OpenAI GPT-4o 模型的代理
model_client = OpenAIChatCompletionClient(model="gpt-4o",# api_key="YOUR_API_KEY",
)agent = AssistantAgent(name="assistant",model_client=model_client,handoffs=["flights_refunder", "user"],# tools=[], # 工具的序列化尚未支持system_message="Use tools to solve tasks.",
)user_proxy = UserProxyAgent(name="user")# 导出并加载 UserProxy 配置
user_proxy_config = user_proxy.dump_component()
print(user_proxy_config.model_dump_json())
up_new = user_proxy.load_component(user_proxy_config)# 导出并加载 Assistant 配置
agent_config = agent.dump_component()
print(agent_config.model_dump_json())
agent_new = agent.load_component(agent_config)
输出示例(部分):
{"provider": "autogen_agentchat.agents.UserProxyAgent","component_type": "agent","version": 1,"component_version": 1,"description": null,"config": {"name": "user","description": "A human user"}
}
{"provider": "autogen_agentchat.agents.AssistantAgent","component_type": "agent","version": 1,"component_version": 1,"description": null,"config": {"name": "assistant","model_client": {"provider": "autogen_ext.models.openai.OpenAIChatCompletionClient","component_type": "model","version": 1,"component_version": 1,"config": { "model": "gpt-4o" }},"handoffs": [...],"system_message": "Use tools to solve tasks."}
}
类似方法也可用于序列化 MultiModalWebSurfer 代理。
from autogen_ext.agents.web_surfer import MultimodalWebSurferagent = MultimodalWebSurfer(name="web_surfer",model_client=model_client,headless=False,
)web_surfer_config = agent.dump_component()
print(web_surfer_config.model_dump_json())
团队示例
下面的示例中,我们在 Python 中定义了一个团队,
导出为字典/JSON,并展示了如何从字典/JSON 中重新加载对象。
from autogen_agentchat.agents import AssistantAgent, UserProxyAgent
from autogen_agentchat.conditions import MaxMessageTermination
from autogen_agentchat.teams import RoundRobinGroupChat
from autogen_ext.models.openai import OpenAIChatCompletionClient# 创建一个使用 OpenAI GPT-4o 模型的代理
model_client = OpenAIChatCompletionClient(model="gpt-4o")agent = AssistantAgent(name="assistant",model_client=model_client,handoffs=["flights_refunder", "user"],system_message="Use tools to solve tasks.",
)team = RoundRobinGroupChat(participants=[agent],termination_condition=MaxMessageTermination(2)
)team_config = team.dump_component()
print(team_config.model_dump_json())await model_client.close()
输出示例(部分):
{"provider": "autogen_agentchat.teams.RoundRobinGroupChat","component_type": "team","version": 1,"component_version": 1,"config": {"participants": [...],"termination_condition": {"provider": "autogen_agentchat.conditions.MaxMessageTermination","config": { "max_messages": 2 }}}
}
跟踪与可观测性 (Tracing and Observability)
AutoGen 内置了 跟踪与可观测性支持,可以收集应用执行过程中的完整记录。
这一特性可用于 调试、性能分析,以及帮助理解应用的执行流程。
该能力由 OpenTelemetry 库驱动,这意味着你可以使用任何兼容 OpenTelemetry 的后端来收集和分析追踪数据。
AutoGen 遵循 OpenTelemetry 语义约定 (Semantic Conventions) 来对代理与工具进行追踪;同时也遵循了目前正在制定中的 生成式 AI 系统语义约定 (GenAI Systems Semantic Conventions)。
环境设置
首先,需要安装 OpenTelemetry Python 包,可以通过 pip 安装:
pip install opentelemetry-sdk opentelemetry-exporter-otlp-proto-grpc opentelemetry-instrumentation-openai
安装完成后,启用 AutoGen 的跟踪功能的最简方式是:
- 配置一个 OpenTelemetry Tracer Provider
- 设置一个 Exporter,将追踪数据发送到后端
- 将 Tracer Provider 连接到 AutoGen 运行时
Telemetry Backend
为了收集和查看追踪数据,你需要搭建一个遥测后端。
有多个开源选项可供选择,例如 Jaeger、Zipkin。
在本示例中,我们使用 Jaeger 作为遥测后端。
快速开始:你可以通过 Docker 在本地运行 Jaeger:
docker run -d --name jaeger \-e COLLECTOR_OTLP_ENABLED=true \-p 16686:16686 \-p 4317:4317 \-p 4318:4318 \jaegertracing/all-in-one:latest
该命令会启动一个 Jaeger 实例:
- 16686 端口 提供 Jaeger UI
- 4317 端口 提供 OpenTelemetry collector
你可以通过浏览器访问 Jaeger UI:
👉 http://localhost:16686
跟踪 AgentChat 团队
在下面的部分中,我们将回顾如何在 AutoGen GroupChat 团队中启用追踪。AutoGen 运行时已经支持 OpenTelemetry(会自动记录消息元数据)。首先,我们将创建一个追踪服务,用于对 AutoGen 运行时进行监测。
from opentelemetry import trace
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.instrumentation.openai import OpenAIInstrumentor
from opentelemetry.sdk.resources import Resource
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor# 设置 telemetry span 导出器
otel_exporter = OTLPSpanExporter(endpoint="http://localhost:4317", insecure=True)
span_processor = BatchSpanProcessor(otel_exporter)# 设置 telemetry trace 提供器
tracer_provider = TracerProvider(resource=Resource({"service.name": "autogen-test-agentchat"}))
tracer_provider.add_span_processor(span_processor)
trace.set_tracer_provider(tracer_provider)# 对 OpenAI Python 库进行埋点
OpenAIInstrumentor().instrument()# 我们稍后会通过其服务名引用这个 tracer
# tracer = trace.get_tracer("autogen-test-agentchat")
⚠️ 提示
- 不允许覆盖当前的
TracerProvider。- 已经被埋点的情况下,再次尝试埋点会报错。
注意
- AgentChat 团队是通过 AutoGen Core 的代理运行时来运行的。运行时已经自带追踪埋点,参见 Core Telemetry Guide。
- 如果你想禁用运行时追踪,可以在运行时构造函数中将
trace_provider设置为opentelemetry.trace.NoOpTracerProvider。 - 如果你无法访问运行时构造函数(例如使用
ComponentConfig),可以设置环境变量AUTOGEN_DISABLE_RUNTIME_TRACING=true来禁用运行时追踪。
示例代码
from autogen_agentchat.agents import AssistantAgent
from autogen_agentchat.conditions import MaxMessageTermination, TextMentionTermination
from autogen_agentchat.teams import SelectorGroupChat
from autogen_agentchat.ui import Console
from autogen_core import SingleThreadedAgentRuntime
from autogen_ext.models.openai import OpenAIChatCompletionClientdef search_web_tool(query: str) -> str:if "2006-2007" in query:return """以下是迈阿密热火队球员在 2006-2007 赛季的总得分:Udonis Haslem: 844 分Dwayne Wade: 1397 分James Posey: 550 分..."""elif "2007-2008" in query:return "Dwayne Wade 在 2007-2008 赛季的总篮板数是 214。"elif "2008-2009" in query:return "Dwayne Wade 在 2008-2009 赛季的总篮板数是 398。"return "未找到数据。"def percentage_change_tool(start: float, end: float) -> float:return ((end - start) / start) * 100async def main() -> None:model_client = OpenAIChatCompletionClient(model="gpt-4o")# 使用默认的 TracerProvider 获取一个 tracer。tracer = trace.get_tracer("tracing-autogen-agentchat")# 使用 tracer 为主函数创建一个 span。with tracer.start_as_current_span("run_team"):planning_agent = AssistantAgent("PlanningAgent",description="一个用于规划任务的智能体,当接收到新任务时,应由它优先启动。",model_client=model_client,system_message="""你是一个规划智能体。你的工作是把复杂任务分解成更小、更易管理的子任务。你的团队成员包括:WebSearchAgent: 负责信息搜索DataAnalystAgent: 负责数据计算你只负责规划和分配任务 —— 你不会亲自执行任务。在分配任务时,请使用以下格式:1. <agent> : <task>当所有任务完成后,总结结果并以 "TERMINATE" 结束。""",)web_search_agent = AssistantAgent("WebSearchAgent",description="一个负责在网络上搜索信息的智能体。",tools=[search_web_tool],model_client=model_client,system_message="""你是一个网络搜索智能体。你的唯一工具是 search_tool —— 使用它来查找信息。你每次只能调用一次搜索。在获得结果后,你绝不会基于这些结果进行计算。""",)data_analyst_agent = AssistantAgent("DataAnalystAgent",description="一个负责执行计算的智能体。",model_client=model_client,tools=[percentage_change_tool],system_message="""你是一名数据分析师。根据分配给你的任务,你需要分析数据并使用提供的工具得出结果。如果你还没有拿到数据,请先询问。""",)text_mention_termination = TextMentionTermination("TERMINATE")max_messages_termination = MaxMessageTermination(max_messages=25)termination = text_mention_termination | max_messages_terminationselector_prompt = """选择一个智能体来执行任务。{roles}当前对话上下文:{history}阅读上述对话,然后从 {participants} 中选择一个智能体执行下一个任务。确保规划智能体在其他智能体开始工作之前已分配任务。每次只能选择一个智能体。"""task = "谁是迈阿密热火队在 2006-2007 赛季得分最高的球员?并计算他在 2007-2008 与 2008-2009 赛季总篮板数的百分比变化?"runtime = SingleThreadedAgentRuntime(tracer_provider=trace.NoOpTracerProvider(), # 禁用运行时追踪)runtime.start()team = SelectorGroupChat([planning_agent, web_search_agent, data_analyst_agent],model_client=model_client,termination_condition=termination,selector_prompt=selector_prompt,allow_repeated_speaker=True,runtime=runtime,)await Console(team.run_stream(task=task))await runtime.stop()await model_client.close()# asyncio.run(main())
运行后,你可以在 Jaeger UI 中查看收集到的追踪数据。
扩展
AutoGen 的设计目标是 可扩展。
autogen-ext 包中包含了由 AutoGen 项目维护的内置组件实现。
组件示例包括:
autogen_ext.agents.*—— 代理实现,例如MultimodalWebSurferautogen_ext.models.*—— 模型客户端,例如OpenAIChatCompletionClient和SKChatCompletionAdapter(用于连接托管或本地模型)autogen_ext.tools.*—— 工具,例如GraphRAG、LocalSearchTool和mcp_server_tools()autogen_ext.executors.*—— 执行器,例如DockerCommandLineCodeExecutor和ACADynamicSessionsCodeExecutorautogen_ext.runtimes.*—— 代理运行时,例如GrpcWorkerAgentRuntime
完整的组件及其 API,请参见 API 参考。
由官方维护的第一方扩展包含在 autogen-ext 包中。
pip install "autogen-ext"
可选依赖(Extras):
langchain—— 用于LangChainToolAdapterazure—— 用于ACADynamicSessionsCodeExecutordocker—— 用于DockerCommandLineCodeExecutoropenai—— 用于OpenAIChatCompletionClient
比如:
pip install "autogen-ext[openai]"
结尾
整体学下来,AutoGen-AgentChat 这一套东西说实话并不难理解,核心机制也比较直白。再往下的 AutoGen-Core,大致能想到的设计思路无非就是 runtime、telemetry、可扩展的组件机制等等,算是意料之中。相比之下,我个人更偏爱 LangChain 系列 —— 日常写一些脚本时,一个简单的管道把 prompt | model | output parser 串起来就能跑,够轻量;而在需要构建稍微复杂的 Agent 流程时,LangGraph 又能补上编排能力,图式化的运行逻辑非常直观。
再加上,LangSmith 虽然收费,但社区已经有 Langfuse 这样的替代方案把观测和评测补齐了,整个生态算是相当完善,几乎能覆盖我日常工作里的各种需求。相比之下,AutoGen 的玩法更像是“多 Agent 沙盘”,更适合对复杂团队协作、可追踪性有要求的场景。
所以我的结论是:AutoGen 绝对值得推荐,尤其是如果你对多智能体系统有兴趣、项目体量也比较大,那它能提供的框架化支持会很有帮助;但就我自己的情况而言,项目规模小,LangChain + LangGraph + Langfuse 的组合已经非常顺手了,也更符合我日常的工作习惯。换句话说,你要用 AutoGen 我会推荐,但我自己嘛,暂时不会切过去。





实战十八——图像透视转换)


:(十三)堆的应用)










