Linux进程概念
冯诺依曼体系
冯诺依曼体系结构(Von Neumann Architecture)是现代计算机设计的奠基石,由数学家约翰·冯·诺依曼于1945年提出。这一架构彻底改变了早期计算机“硬件即程序”的设计方式,使得计算机可以灵活地运行不同程序,开启了可编程计算时代。
🧠 核心思想:存储程序原理
冯诺依曼结构的最大创新是将程序和数据统一存储在同一个存储器中,并通过控制器逐条读取指令执行。这种设计使得程序可以像数据一样被修改、传输和存储。
🧱 五大组成部分
| 部件 | 功能说明 |
|---|---|
| 运算器(ALU) | 执行算术和逻辑运算,如加减乘除、与或非等操作 |
| 控制器(CU) | 负责指令的读取、译码和控制其他部件的操作流程 |
| 存储器 | 存储程序指令和数据,通常是 RAM(内存)和 ROM(只读存储器) |
| 输入设备 | 将外部信息输入计算机,如键盘、鼠标、摄像头等 |
| 输出设备 | 将计算结果输出到外部,如显示器、打印机、扬声器等 |
| 五大组成部分结构体系图 | |
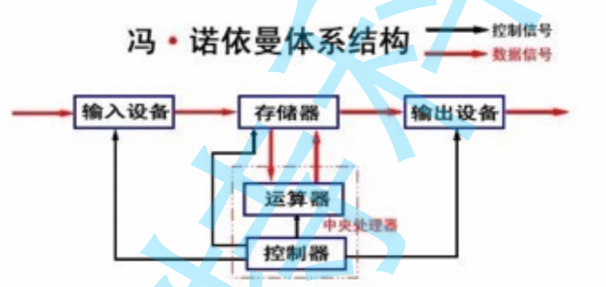 | 1. 这里的存储器指的是内存(具有掉电遗失的性质),而磁盘是外设是拥有永久性存储的能力 2. CPU是不会直接和外设进行交流,所有外设的输入输出数据只能写入到内存之中去 |
🔁 工作流程介绍
- 从存储器中取指令
- 控制器译码指令
- 根据指令操作数据
- 运算器执行运算
- 结果写回存储器或输出设备
操作系统
🧠 操作系统概念
操作系统(Operating System,简称 OS)是计算机系统中最基本、最核心的系统软件。它负责管理计算机的硬件资源,并为用户和应用程序提供运行环境。
✅ 简单定义:
操作系统是管理计算机硬件与软件资源的中间层,它协调各个组件的运行,使用户和程序能够高效、安全地使用计算机。
- 内核(进程管理,内存管理,文件管理,驱动管理)
- 其他程序(函数库,shell程序)
🎯 操作系统的设计目的
操作系统的设计目的可以从两个方向理解:
🔽 对下:管理硬件资源(手段)
- 管理 CPU:调度进程、分配时间片
- 管理内存:分配空间、提供虚拟内存
- 管理设备:通过驱动程序控制硬件
- 管理文件系统:组织数据、提供访问接口
操作系统屏蔽了底层硬件的复杂性,为上层应用提供统一的访问方式。
🔼 对上:服务用户和应用程序(目的)
- 提供程序运行环境
- 提供系统调用接口(如文件读写、进程创建)
- 提供图形界面或命令行交互方式
- 提供安全性、稳定性和资源隔离
就像银行柜员是用户与后台系统之间的桥梁,操作系统是用户程序与硬件之间的“服务窗口”。
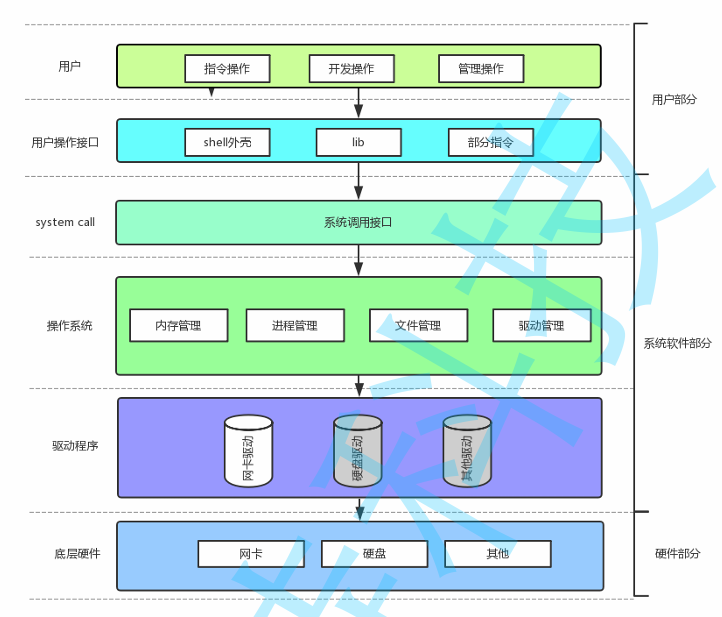
- 操作系统管理硬件的一个过程就是
- 先将其利用结构体进行描述
- 然后利用链表或者其他的更高效的数据结构进行管理组织
🧱 操作系统的定位
在整个计算机系统架构中,操作系统处于中间层:
用户程序↑
系统调用 / 库函数↑
操作系统(内核)↑
硬件(CPU、内存、设备)
🧩 小结
| 维度 | 内容说明 |
|---|---|
| 概念 | 管理软硬件资源的系统软件 |
| 设计目的 | 对下管理硬件,对上服务用户 |
| 定位 | 计算机系统的中间层,是用户与硬件之间的桥梁 |
| 核心功能 | 进程管理、内存管理、文件系统、设备驱动、安全性 |
接下来我们来了解进程的概念
- 基本概念:就是一个执行的实例,一个正在运行的程序
- 内核观点:担当分配系统资源的实体,在这里我的理解是内存资源
描述进程PCB(process control block)
task_struct-PCB的一种
- 在Linux中描述进程的结构体叫做task_struct。
- task_struct是Linux内核的一种数据结构,它会被装载到RAM(内存)里并且包含着进程的信息。
简单理解就是,当我写了一个小程序,此时执行,现在这个小程序是在内存之中被执行的,而他的可执行文件则在硬盘当中。
但是电脑内存当中肯定不止这一个执行的程序也就是进程,有太多的加载进来的程序,操作系统肯定要进行管理。
所以在这里使用task_struct,也就是先对其进行描述再进行管理
所谓的对进程进行管理,也就转变成了对PCB进行相关的管理
而对进程管理-> 也就转化成了对链表的增删查改- 简要介绍一下这个task_struct中存储了以下信息
🧱 task_struct 的核心字段
| 分类 | 字段示例 | 说明 |
|---|---|---|
| 🔖 标识信息 | pid, tgid, ppid | 进程号、线程组号、父进程号 |
| 📍 状态信息 | state, exit_code | 当前状态(运行、等待、僵死等) |
| 🎛️ 调度信息 | priority, policy, counter | 优先级、调度策略、时间片 |
| 🧠 内存信息 | mm, active_mm | 指向进程的内存描述结构 |
| 🧵 线程信息 | thread | 保存寄存器上下文、栈指针等 |
| 📂 文件系统信息 | files, fs | 打开的文件、文件系统上下文 |
| 🔗 链接信息 | parent, children, sibling | 父子进程关系 |
| 🔔 信号处理 | signal, blocked, sigpending | 信号处理相关字段 |
| 📊 统计信息 | utime, stime, start_time | 用户态/内核态时间、启动时间 |
查看进程
1 #include<stdio.h>2 #include<unistd.h>3 #include<sys/types.h>4 int main()5 {6 // 引入子进程的概念,观察进程现象7 pid_t id = fork();8 printf("我是一个进程,pid: %d, ppid:%d, id:%d\n",getpid(), getppid(), id);9 // 观察进程状态10 //while(1)11 //{12 // printf("我是一个进程,pid: %d, ppid:%d\n",getpid(), getppid());13 // sleep(1); 14 //}15 return 0;16 }在这里先忽略fork,可以看到执行的程序结果pid是16802,使用指令查看,在这张图片里显示的最后一个进程是我们使用了grep查找16802可以忽略

- 进程id (PID)
- 父进程id(PPID)
🧠 fork()的概念
fork() 是 Linux 和类 Unix 系统中用于创建新进程的系统调用。它的核心作用是:
复制当前进程,生成一个几乎完全一样的子进程。
这个“复制”并不是简单的拷贝,而是通过一种叫做 写时复制(Copy-On-Write, COW) 的机制来优化性能。
🧱 基本语法
#include <unistd.h>pid_t fork(void);
- 返回值:
- > 0:父进程,返回的是子进程的 PID
- = 0:子进程
- < 0:创建失败,返回 -1,并设置
errno
🧪 示例代码
#include <stdio.h>
#include <unistd.h>int main() {pid_t pid = fork();if (pid < 0) {perror("fork failed");return 1;} else if (pid == 0) {// 子进程printf("Hello from child! PID = %d\n", getpid());} else {// 父进程printf("Hello from parent! Child PID = %d\n", pid);}return 0;
}
🧾 输出可能是:
Hello from parent! Child PID = 12345
Hello from child! PID = 12345
注意:父子进程的执行顺序不确定,由操作系统调度决定。
🔍 fork 的工作原理
- 复制进程上下文:包括代码段、数据段、堆、栈等
- 独立 PID:子进程拥有自己的进程号
- 共享文件描述符:初始时父子进程共享打开的文件
- 地址空间独立:虽然初始共享内存页,但修改时会触发复制(COW)
🧩 常见用途
- 创建后台任务或守护进程
- 实现并行计算
- 与
exec()结合,执行新程序(如 shell 命令) - 构建多进程服务器(如 Apache)
⚠️ 注意事项
- 必须处理返回值,否则容易逻辑混乱
- 避免僵尸进程:父进程应使用
wait()或waitpid()等待子进程结束 - 资源消耗:虽然 COW 优化了性能,但频繁 fork 仍可能影响系统稳定性




)
 算法原理)



)



——图像几何校正)





