文章目录
- 研究背景
- BLIP3-o 框架
- 3个关键问题
- BLIP3-o模型
- 总结
- paper link: https://arxiv.org/pdf/2505.09568
- from saleforce research
研究背景
随着gpt4o图像生成和编辑的应用火爆,如何构造能够同时处理图像理解和生成任务的统一多模态模型,成为研究的热点。
- 统一图像理解和生成的好处:
- 推理和指令跟随能力:将图像生成能力集成进MLLM模型中,可以继承MLLM的pretrain知识、推理能力和指令跟随能力(不再需要prompt rewriting步骤),这些是传统图像生成模型难以获得的知识和能力;
- in-context learning能力:在统一的模型中,历史生成的多模态输出就可以作为后续生成的context,模型可以无缝地支持迭代的图像编辑;
- 多模态AGI:随着人工智能向通用人工智能 (AGI) 迈进,未来的系统需要超越基于文本的能力,无缝地感知、解释和生成多模态内容。
- 关键的相关研究有:
- Janus和Janus-Pro:尝试在单一框架内整合图像理解和生成能力
- show-o:采用单一的transformer架构统一多模态理解和生成
- MetaMorph:通过指令调整实现多模态理解和生成的统一
- LMFusion:在freeze MLLM的基础上,添加transformer模块从而实现图像生成
- EMU2 Chat和EMU3:通过回归损失训练图像特征
- Chameleon:采用自回归离散标记预测范式处理图像生成
- Seed-X:提出具有统一多粒度理解和生成能力的多模态模型
- VILA-U:整合了视觉理解和生成的统一基础模型
- TokenFlow:提出用于多模态理解和生成的统一图像tokenizer
- DreamLLM 和Transfusion:利用扩散目标进行视觉生成
- LLaVAFusion:通过结合预训练的语言模型和扩散模型实现多模态生成
- WISE:提出基于世界知识的语义评估框架,用于评估文本到图像生成的对齐情况
- 本文的motivation: 尽管统一理解和生成能力的相关研究很多,但是实现这种统一能力的底层设计原则和训练策略仍未得到充分探索。本文基于类似于GPT-4o的自回归+扩散模型的混合架构进行探索。
- Blip3-o关注的关键问题:
- 图像表示:在统一框架中,如何表示图像?(低级的像素特征 or 高级的语义特征)
- 训练目标:训练图像生成模型时,应该采用均方误差(MSE)损失还是流匹配(Flow Matching)损失?(两种loss对训练效率和生成质量有什么影响)
- 训练策略:是采用联合训练策略(同时训练图像理解和生成任务),还是顺序训练(先训图像理解任务,再训图像生成任务)?
BLIP3-o 框架
- 采用混合架构(结合自回归和扩散模型)
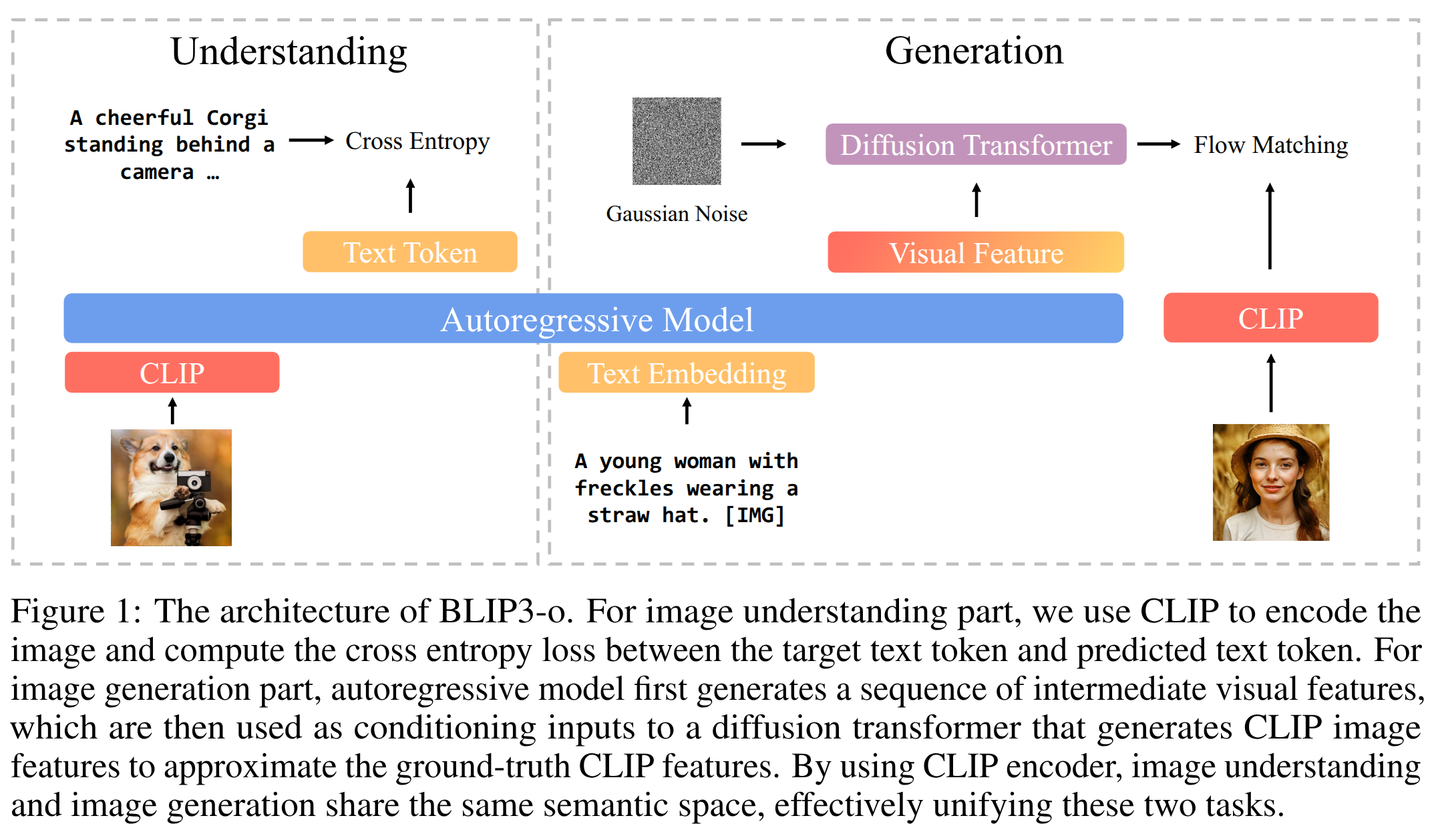
3个关键问题
-
问题一(图像表示):在统一的多模态框架内构建图像生成模型,如何通过编码器-解码器架构将图像表示为连续嵌入,这对于学习效率和生成质量起着基础性的作用。
- 图像生成:
- 首先使用编码器将图像编码为连续的潜在嵌入;
- 然后使用解码器从该潜在嵌入重建图像。
- 这种编码-解码流程可以有效降低图像生成过程中输入空间的维数,从而提高训练效率。
- 两种广泛使用的编码器-解码器范式:VAE和CLIP-Diffusion
- 变分自编码器 (VAE) :它学习将图像编码到结构化的连续潜在空间中。
- 编码器根据输入图像近似计算潜在变量的后验分布
- 而解码器则根据从该潜在分布中抽取的样本重建图像。
- 潜在扩散模型建立在此框架之上,通过学习对压缩的潜在表示(而非原始图像像素)的分布进行建模。通过在 VAE 潜在空间中运行,这些模型显著降低了输出空间的维度,从而降低了计算成本并实现了更高效的训练。经过去噪步骤后,VAE 解码器将生成的潜伏嵌入映射到原始图像像素中。
- CLIP 编码器与扩散解码器:
- CLIP 模型已成为图像理解任务的基础编码器,这得益于其通过对大规模图文对进行对比训练,能够从图像中提取丰富的高级语义特征。
- 然而,利用这些特征进行图像生成仍然是一项艰巨的挑战,因为 CLIP 最初并非为重建任务而设计。
- Emu2 提出了一种实用的解决方案,将基于 CLIP 的编码器与基于扩散的解码器配对。
- 使用 EVA-CLIP 将图像编码为连续的视觉嵌入,并通过基于 SDXL-base 初始化的扩散模型对其进行重建。
- 在训练过程中,扩散解码器经过微调,使用来自 EVA-CLIP 的视觉嵌入作为条件,从高斯噪声中恢复原始图像,而 EVA-CLIP 保持冻结状态。
- 这个过程有效地将 CLIP 模型和扩散模型结合成一个图像自编码器:CLIP 编码器将图像压缩成语义丰富的潜在嵌入,而基于扩散的解码器则根据这些嵌入重建图像。值得注意的是,尽管解码器基于扩散架构,但它的训练目标是重建损失,而非概率采样目标。因此,在推理过程中,该模型执行确定性重建。
- 比较VAE 和 CLIP-Diffusion 图像编码重建范式:
- VAE 将图像编码为低级像素特征,并提供更好的重建质量。此外,VAE 作为现成的模型广泛可用,可以直接集成到图像生成训练流程中。
- CLIP-Diffusion 需要额外的训练才能使扩散模型适应各种 CLIP 编码器。然而,CLIP-Diffusion 架构在图像压缩率方面具有显著优势。
- 例如,在 Emu2 和我们的实验中,每幅图像无论其分辨率如何,都可以编码为固定长度的 64 个连续向量,从而提供紧凑且语义丰富的潜在嵌入。
- 相比之下, 基于 VAE 的编码器往往会为更高分辨率的输入生成更长的潜在嵌入序列, 这会增加训练过程中的计算负担。
- 图像生成:
-
问题二(训练目标):MSE Loss or Flow matching loss?
- 获得连续图像嵌入后,使用自回归架构对其进行建模。
- 给定一个user prompt(例如,“一位戴着草帽、长着雀斑的年轻女子”),首先使用自回归模型的输入embedding layer 将 prompt 编码为一个 embedding 向量序列 C,并将一个可学习的 query 向量 Q 附加到 C,其中 Q 在训练过程中随机初始化和优化。
- 当组合序列 [C; Q] 通过自回归transformer 进行处理时,Q 会学习关注并从提示 C 中提取相关的语义信息。得到的 Q 被解释为自回归模型生成的中间视觉特征或潜在表示,并被训练以近似真实图像特征 X(由 VAE 或 CLIP 获取)。
- 接下来,我们介绍两个训练目标:均方误差 (MSE) 和光流匹配,用于学习将 Q 与真实图像嵌入 X 对齐。
- 均方误差 (MSE) 损失是一个简单且广泛用于学习连续图像嵌入的目标 [7, 31]。给定由自回归模型生成的预测视觉特征 Q 和真实图像特征 X,我们首先应用一个可学习的线性投影, 将 Q 的维数与 X 的维数对齐。
- 流匹配:需要注意的是,使用 MSE 损失函数只能将预测的图像特征 Q 与目标分布的平均值对齐。理想的训练目标是对连续图像表示的概率分布进行建模。
- 我们建议使用流匹配,这是一个扩散框架,可以通过迭代传输来自先验分布(例如高斯分布)的样本来从目标连续分布中进行采样。
- 讨论:与离散标记(discrete token)不同,离散标记本身支持基于采样的策略来探索不同的生成路径,而连续表示则缺乏此特性。
- 具体而言,在基于 MSE 的训练目标下,预测的视觉特征 Q 对于给定的提示几乎是确定性的。因此,无论视觉解码器是基于 VAE 还是 CLIP + 扩散架构,输出图像在多次推理运行中几乎保持相同。
- 这种确定性凸显了 MSE 目标的一个关键限制:它限制模型为每个提示生成单一、固定的输出,从而限制了生成的多样性。
- 相比之下,流匹配框架使模型能够继承扩散过程的随机性。这使得模型能够以同一提示为条件生成不同的图像样本,从而促进对输出空间的更广泛探索。
- 然而,这种灵活性是以增加模型复杂度为代价的。与 MSE 相比,流匹配引入了额外的可学习参数。在我们的实现中,我们使用了扩散 transformer(DiT),并且经验发现,扩展其容量可以显著提高性能。
- 获得连续图像嵌入后,使用自回归架构对其进行建模。
-
不同的图像编码器-解码器架构和训练目标的组合,(如图 3 所示)显著影响着生成图像的质量和可控性。
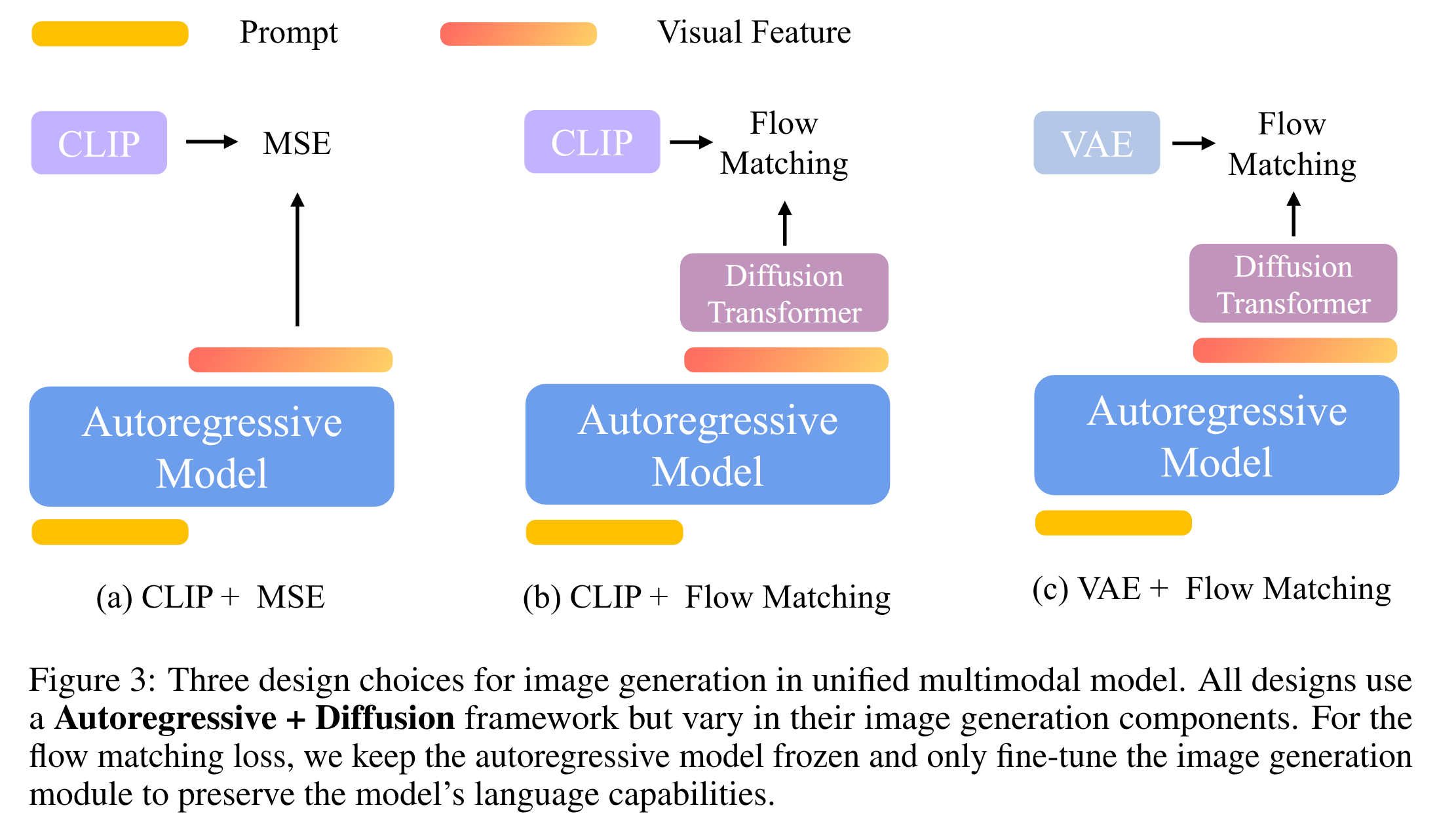
- 比较不同组合的优劣:
- CLIP + MSE: (Emu2 、Seed-X 和 Metamorph 采用的方式)
- 我们使用 CLIP 将图像编码为 64 个固定长度、语义丰富的视觉嵌入。
- 训练自回归模型,以最小化预测的视觉特征 Q 与真实 CLIP 嵌入 X 之间的均方误差 (MSE) 损失,如图 3(a) 所示。
- 在推理过程中,给定文本提示 C,自回归模型会预测潜在视觉特征 Q,随后将其传递给基于扩散的视觉解码器,以重建真实图像。
- CLIP + 流匹配:
- 我们采用流匹配损失来训练模型,使其能够预测真实的 CLIP 嵌入,如图 3(b) 所示。
- 给定文本提示 C,自回归模型会生成一系列视觉特征 Q。这些特征用作指导扩散过程的条件,从而生成预测的 CLIP 嵌入,以近似真实的 CLIP 特征。
- 本质上,推理流程包含两个扩散阶段:第一阶段使用条件视觉特征 Q 迭代去噪为 CLIP 嵌入。第二阶段通过基于扩散的视觉解码器将这些 CLIP 嵌入转换为真实图像。这种方法在第一阶段实现了随机采样,从而提高了图像生成的多样性。
- VAE + 流匹配:
- 我们还可以使用流匹配损失来预测图 3(c) 中所示的真实 VAE 特征,这与 MetaQuery 类似。
- 在推理时,给定提示 C, 自回归模型生成视觉特征 Q。然后,以 Q 为条件,并在每一步迭代地消除噪声,VAE 解码器生成真实图像。
- VAE + MSE:
- 由于我们的重点是自回归 + 扩散框架,因此我们排除了 VAE + MSE 方法,因为它们不包含任何扩散模块。
- 实现细节:为了比较各种设计选择,我们使用 Llama-3.2-1B-Instruct 作为自回归模型。我们的训练数据包括 CC12M 、SA-1B 和 JourneyDB , 总计约 2500 万个样本。对于 CC12M 和 SA-1B,我们使用 LLaVA 生成的详细字幕,而对于 JourneyDB,我们使用原始字幕。
-
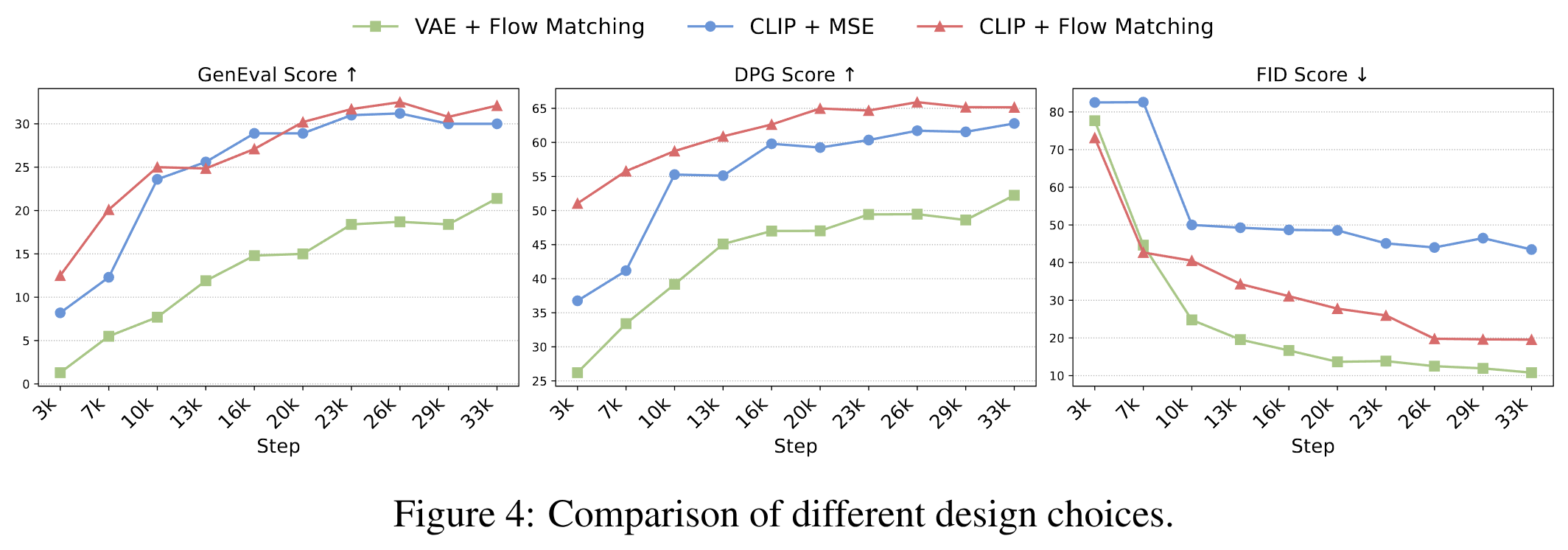
我们报告了 MJHQ-30k 上视觉美学质量的 FID 得分,以及 GenEval 和 DPG-Bench 用于评估prompt对齐的指标。我们大约每 3200 个训练步绘制一次每种设计选择的结果。
-
图 4 显示,CLIP + Flow Matching 在 GenEval 和 DPG-Bench 上均获得了最佳的prompt对齐得分,而 VAE + Flow Matching 产生了最低(最佳)的 FID,表明其具有卓越的美学质量。
-
然而,FID 存在固有的局限性:它量化了与目标图像分布的风格偏差,并且经常忽略真正的生成质量和prompt对齐。事实上,我们在 MJHQ-30k 数据集上对 GPT-4o 的 FID 评估得分约为 30.0,这强调了 FID 在图像生成评估中可能具有误导性。
-
- CLIP + MSE: (Emu2 、Seed-X 和 Metamorph 采用的方式)
- 总体而言,我们的实验表明 CLIP + Flow Matching 是最有效的设计选择
- 当将图像生成集成到统一模型中时,自回归模型可以比像素级特征(VAE)更有效地学习语义级特征(CLIP)。
- 采用流匹配作为训练目标可以更好地捕捉底层图像分布,从而提高样本多样性和视觉质量
- 比较不同组合的优劣:
-
问题三(训练策略):联合训练与顺序训练
- 联合训练:图像理解和图像生成的联合训练已成为近期研究的常见做法,例如 Metamorph 、Janus-Pro 和 Show-o 。尽管这些方法采用了不同的图像生成架构,但都通过混合数据进行图像生成和理解,从而进行多任务学习。
- 顺序训练:我们采用两阶段方法,而不是同时训练图像理解和生成模块。
- 第一阶段,我们只训练图像理解模块。
- 第二阶段,我们冻结MLLM主干网络,只训练图像生成模块,例如LMFusion 和MetaQuery。
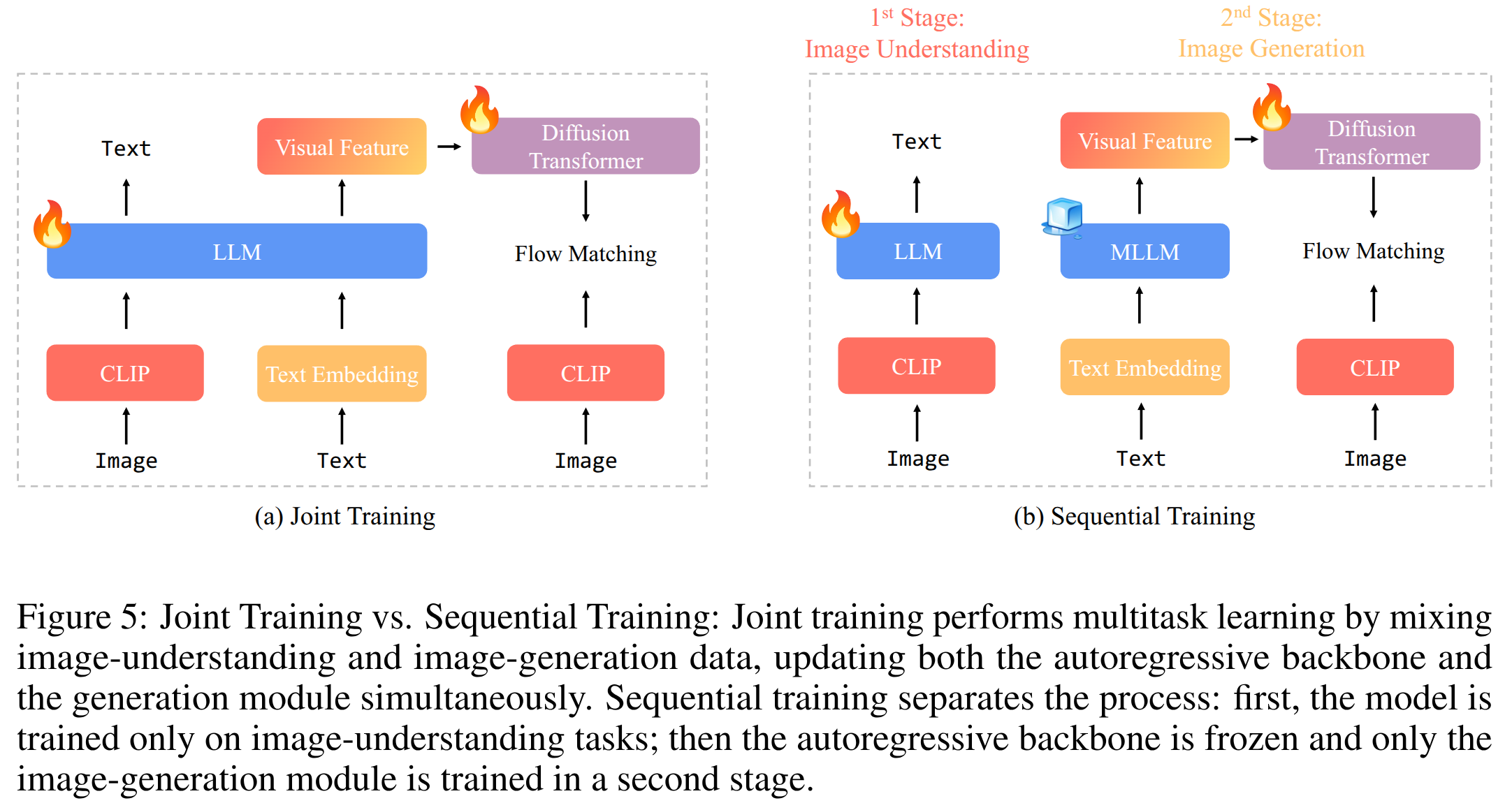
- 在联合训练中,尽管图像理解和生成任务可能互利互惠(正如 Metamorph 所证明的那样),但有两个关键因素会影响它们的协同效应: (i) 总数据量;(ii) 图像理解数据与生成数据之间的数据比率。
- 相比之下,顺序训练提供了更大的灵活性:它允许我们冻结自回归主干网络, 同时保持图像理解能力。
- 我们可以将所有训练能力用于图像生成, 从而避免联合训练中出现任何任务间效应。
- 同样受到 LMFusion 和 MetaQuery 的启发,我们将选择顺序训练来构建统一的多模态模型,并将联合训练推迟到未来的工作中。
BLIP3-o模型
- 采用 CLIP + 流匹配和顺序训练来开发我们自己的最先进的统一多模态模型 BLIP3-o。
- 模型架构:
- 开发了两种不同大小的模型:基于专有数据训练的 8B 参数模型和仅使用开源数据的 4B 参数模型。
- 鉴于目前已有强大的开源图像理解模型,例如 Qwen 2.5 VL,我们跳过了图像理解训练阶段,直接在 Qwen 2.5 VL 上构建图像生成模块。
- 在 8B 模型中,我们冻结了 Qwen2.5-VL-7B-Instruct 主干网络并训练了扩散变换器,总共需要 1.4B 个可训练参数。
- 4B 模型遵循相同的图像生成架构,但使用 Qwen2.5-VL-3B-Instruct 作为主干网络。
- DIT架构:
- 我们利用 Lumina-Next 模型的架构来实现我们的扩散 transformer (DiT)。
- Lumina-Next 模型基于改进的 Next-DiT 架构构建,这是一款可扩展且高效的扩散transformer,专为文本转图像和通用多模态生成而设计。
- 它引入了 3D 旋转位置嵌入,无需依赖可学习的位置标记,即可对跨时间、高度和宽度的时空结构进行编码。
- 每个transformer block采用sandwich normalization(RMSNorm before and after attention/MLP)和GQA来增强稳定性和减少计算量
- 我们利用 Lumina-Next 模型的架构来实现我们的扩散 transformer (DiT)。
- 开发了两种不同大小的模型:基于专有数据训练的 8B 参数模型和仅使用开源数据的 4B 参数模型。
- 训练Recipe:2阶段训练
- 第一阶段:图像生成预训练。
- 对于 8B 模型,我们将大约 2500 万张开源数据(CC12M 、SA-1B 和 JourneyDB)与另外 3000 万张专有图像相结合。所有图像说明均由 Qwen2.5-VL-7B-Instruct 生成,生成平均长度为 120 个标记的详细描述。
- 为了提高对不同提示长度的泛化能力,我们还从 CC12M 中引入了约 10%(600 万)的较短说明,每个说明约有 20 个标记。
- 每个图像-说明对都使用以下提示进行格式化:“请根据以下说明生成图像:”。
- 对于完全开源的 4B 模型,我们使用了 2500 万张公开可用的图像,这些图像来自 CC12M 、SA-1B 和 JourneyDB ,每张图像都配有相同的详细说明。我们还混合了约 10%(300 万)来自 CC12M 的简短说明。
- 为了支持研究社区,我们发布了 2500 万条详细说明和 300 万条简短说明。
- 对于 8B 模型,我们将大约 2500 万张开源数据(CC12M 、SA-1B 和 JourneyDB)与另外 3000 万张专有图像相结合。所有图像说明均由 Qwen2.5-VL-7B-Instruct 生成,生成平均长度为 120 个标记的详细描述。
- 第二阶段:图像生成指令调优
- 在图像生成预训练阶段之后,我们观察到模型存在以下几个不足:
- 生成复杂的人类手势,例如,一个人正在搭箭。
- 生成常见物体,例如,各种水果和蔬菜。
- 生成地标,例如,金门大桥。
- 生成简单文本,例如,写在街道路面上的“Salesforce”字样。
- 虽然这些类别原本计划在预训练阶段涵盖,但由于预训练语料库的规模有限,我们未能完全解决它们。为了解决这个问题,我们专门针对这些领域进行了指令调优。
- 对于每个类别,我们提示 GPT-4o 生成大约 1 万个提示-图像对,从而创建一个有针对性的数据集,以提高模型处理这些情况的能力。
- 为了提升视觉美学质量,我们还使用了来自 JourneyDB 和 DALL·E 3 的提示来扩展数据。
- 此过程生成了一个包含约 6 万个高质量提示-图像对的精选集。我们还发布了这个包含 6 万个指令调优数据集。
- 在图像生成预训练阶段之后,我们观察到模型存在以下几个不足:
- 第一阶段:图像生成预训练。
- 结果:
-
图像理解任务:
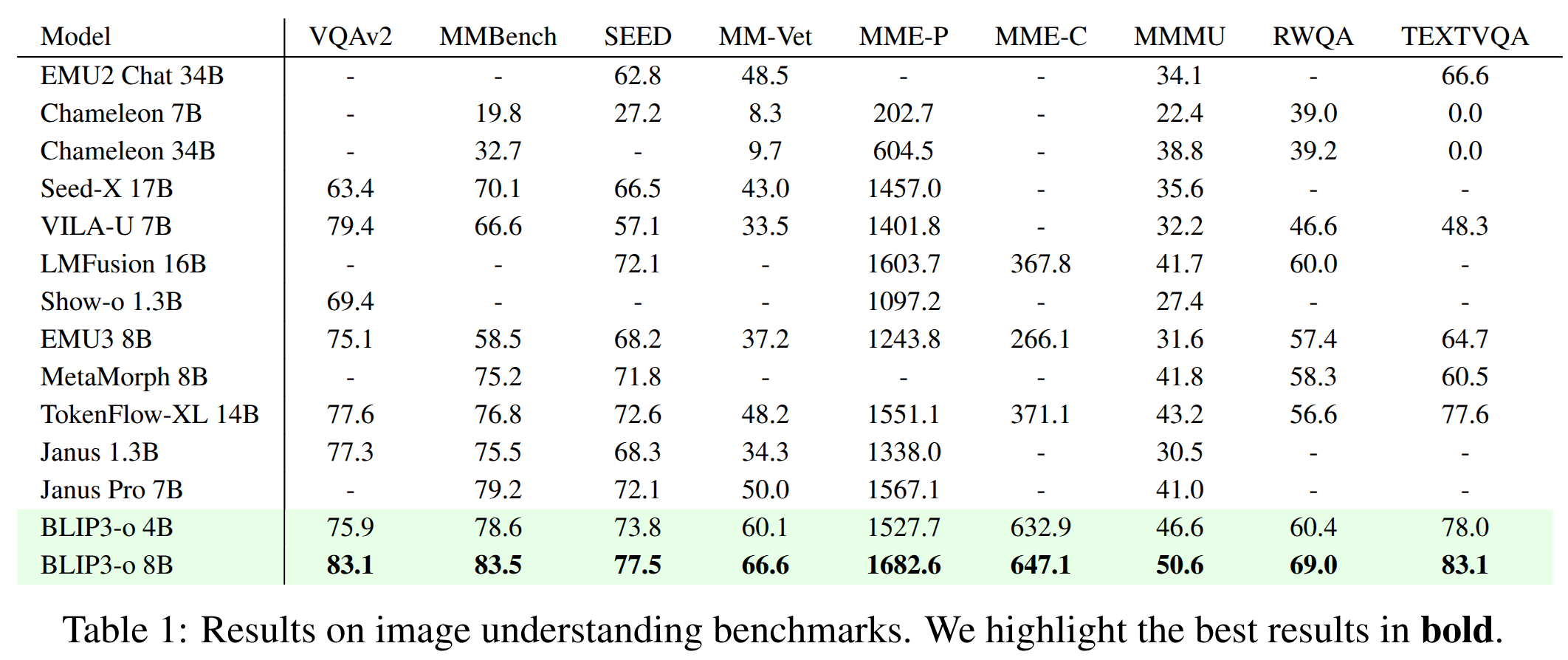
- 我们评估了 VQAv2 、MMBench 、SeedBench 、MM-Vet 、MME-Perception 和 MME-Cognition、MMMU、TextVQA 和 RealWorldQA 上的基准性能。
- 如表 1 所示, 我们的 BLIP3-o 8B 在大多数基准测试中均取得了最佳性能。
-
图像生成任务:
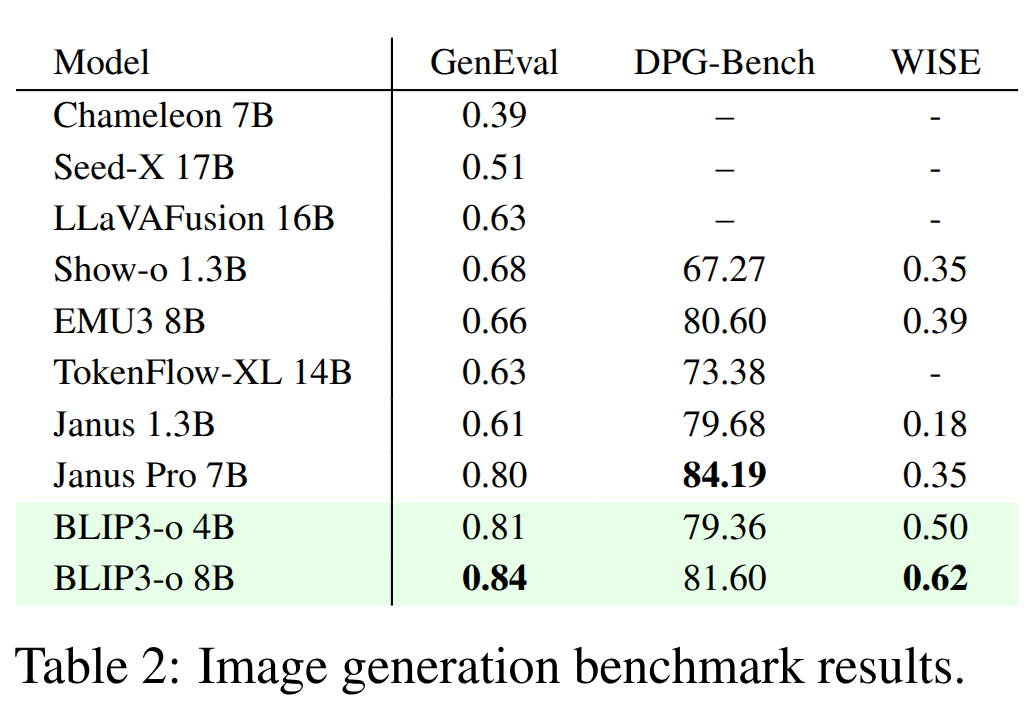
- 我们报告了 GenEval 和 DPG-Bench 来衡量prompt对齐,以及 WISE 来评估世界知识推理能力。
- 如表 2 所示,BLIP3-o 8B 的 GenEval 得分为 0.84,WISE 得分为 0.62,但在 DPG-Bench 上的得分较低。由于基于模型的 DPG-Bench 评估可能不可靠,我们将在下一节中对所有 DPG-Bench 任务进行人工研究,以补充这些结果。
- 此外,我们还发现,我们的指令调优数据集 BLIP3o-60k 带来了立竿见影的效果:仅使用 60k 个任务-图像对,即时对齐和视觉美感都得到了显著改善,并且许多生成伪影也迅速减少。虽然该指令调整数据集无法完全解决一些棘手的情况,例如复杂的人体手势生成,但它仍然显著提高了整体图像质量。
-
人工评估:
- 我们对从 DPG-Bench 中提取的约 1,000 个提示进行人工评估,比较 BLIP3-o 8B 和 Janus Pro 7B。对于每个提示,注释器都会根据以下两个指标并排比较图像对:
- 视觉质量:指令为“所有图像均使用不同的方法从相同的文本输入生成。请根据视觉吸引力(例如布局、清晰度、物体形状和整体整洁度)选择您最喜欢的最佳图像。”
- 提示对齐:指令为“所有图像均使用不同的方法从相同的文本输入生成。请选择图文内容对齐度最佳的图像。”
- 每个指标都经过两轮独立评估,每个标准大约有 3,000 个判断。
- 如图 6 所示,尽管 Janus Pro 在表 2 中获得了更高的 DPG 分数,但 BLIP3-o 在视觉质量和快速对齐方面均优于 Janus Pro。视觉质量和快速对齐的 p 值分别为 5.05e-06 和 1.16e-05,这表明我们的模型在统计置信度方面显著优于 Janus Pro。

- 我们对从 DPG-Bench 中提取的约 1,000 个提示进行人工评估,比较 BLIP3-o 8B 和 Janus Pro 7B。对于每个提示,注释器都会根据以下两个指标并排比较图像对:
-
总结
- 本文首次系统地探索了用于统一多模态建模的混合自回归和扩散架构,并评估了三个关键方面:图像表征(CLIP 与 VAE 特征)、训练目标(光流匹配与 MSE)以及训练策略(联合与顺序)。
- 实验表明,CLIP 嵌入与光流匹配损失相结合,能够提高训练效率并提升输出质量。
- 基于这些洞察,本文推出了 BLIP3-o,这是一系列最先进的统一模型,并基于 60k 指令集调整数据集 BLIP3o-60k 进行了增强,显著提升了快速对齐和视觉美感。
- 基于该统一模型,将会有一系列应用,包括迭代图像编辑、视觉对话和逐步视觉推理。











)






)
