一、RNN的长期依赖问题
 可以看到序列越长累乘项项数越多,项数越多就可能会让累乘结果越小,此时对于W 的更新就取决于第一项或者是前几项,也就是RNN模型会丢失很多较远时刻的信息而 更关注当前较近的几个时刻的信息,即没有很好的长期依赖。 通俗来说就是模型记不住以前的东西。但很多时候我们都希望模型记得更久的信息。
可以看到序列越长累乘项项数越多,项数越多就可能会让累乘结果越小,此时对于W 的更新就取决于第一项或者是前几项,也就是RNN模型会丢失很多较远时刻的信息而 更关注当前较近的几个时刻的信息,即没有很好的长期依赖。 通俗来说就是模型记不住以前的东西。但很多时候我们都希望模型记得更久的信息。
二、LSTM模型结构
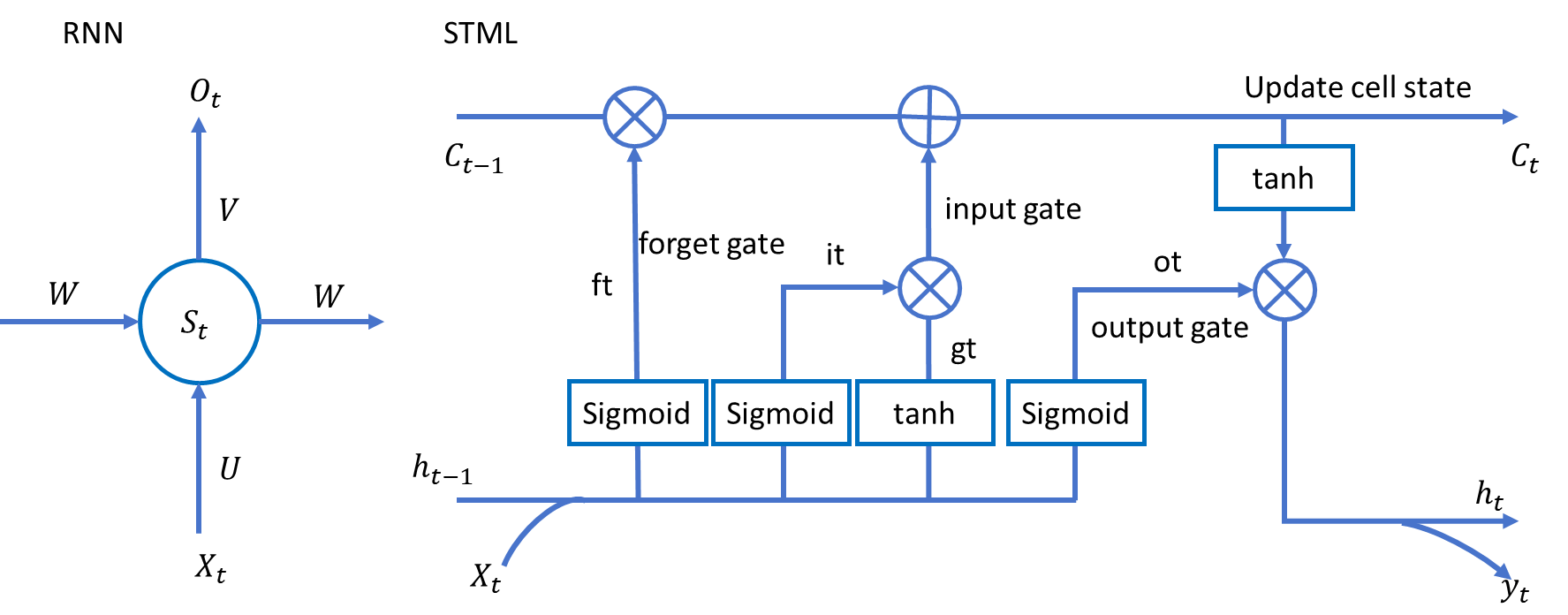
为了解决RNN的长期依赖问题,研究者对传统RNN的结构进行了优化,提出了 LSTM。
通俗来说,RNN就好比是一个给什么都想要的人, 而LSTM是一个给东西还得挑一挑,挑一些有用的人。 这就导致RNN东西越来越多,多到放不下,然后直接把以前的东西丢掉,而LSTM从 一开始就精挑细选把没用的丢掉,因此在容量一定的情况下LSTM可以装入更长时间 的信息,并且这些信息都是相对更有用的。
LSTM的这种特性是通过门结构来实现的。‘门’的作用就是控制信息保留或丢弃的程 度。
注意:
这里的“门”不是只有开关状态,即是否全部保留或者丢弃,而是保留或者 丢弃的程度。
2.1、输入门(input gate)
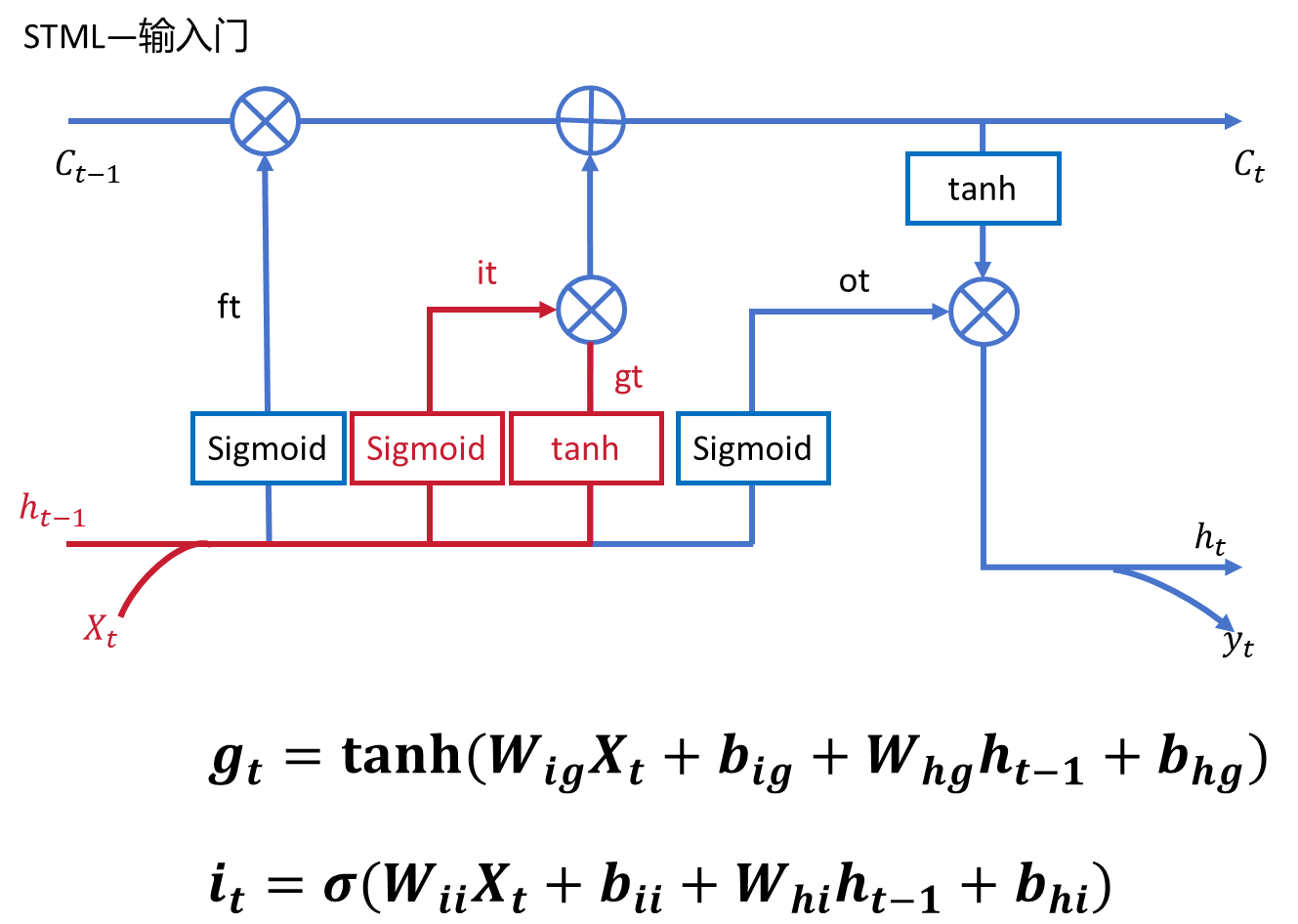
sigmoid函数的输出范围是0到1,这是一个很 好的性质,我们可以把它的输出理解为一个概率值或者是权重,即需要保留的程度, 当输出为1时为全保留,当输出为0时为全部不保留或者说全部遗忘(实际上, sigmoid函数不会就输出0或者1),当输出置于0和1之间时就是以一定程度保留。
我们可以看到输入依然是上一时间步的隐藏状态和当前时间 步的输入,也就是这个保留的程度是通过上一时间步的隐藏状态和当前时间步的输入 学习得到的,也就是说LSTM模型对新输入进行挑选的过程,而这种挑选又是基于以 前的经验进行的。 现在我们已经单独分析完输入门的两个分支了,它们结合就很简单了,之间进行,i_t表示的是保留的程度是一个0到1之间g_t是传统RNN 的部分表示原始的输出,那么将他们相乘就很容易理解了,就是选择一定程度的原始 输入作为输出。
2.2、遗忘门(forget gate)
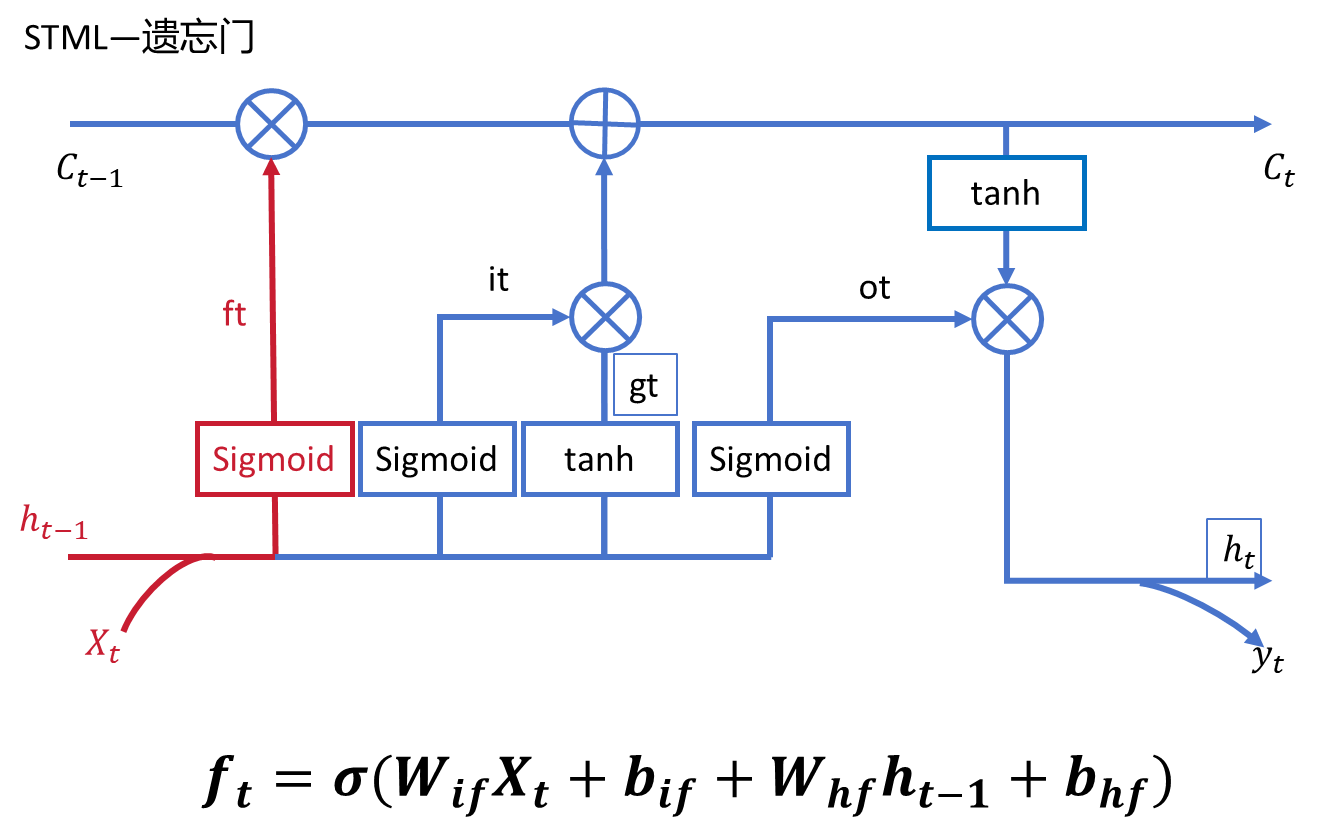
sigmoid的作用就很清晰了,充当的就是‘门’的结构,即程度。在组 件中点击LSTM下的forget gate 可以看到标红部分就是遗忘门的结构。依然是输入上 一时间步的隐藏状态和当前时间步的输入,经过sigmoid函数输出,输出的就是一个 介于0和1之间表示程度的值 。
说是‘遗忘’但本质上还是保留的程度
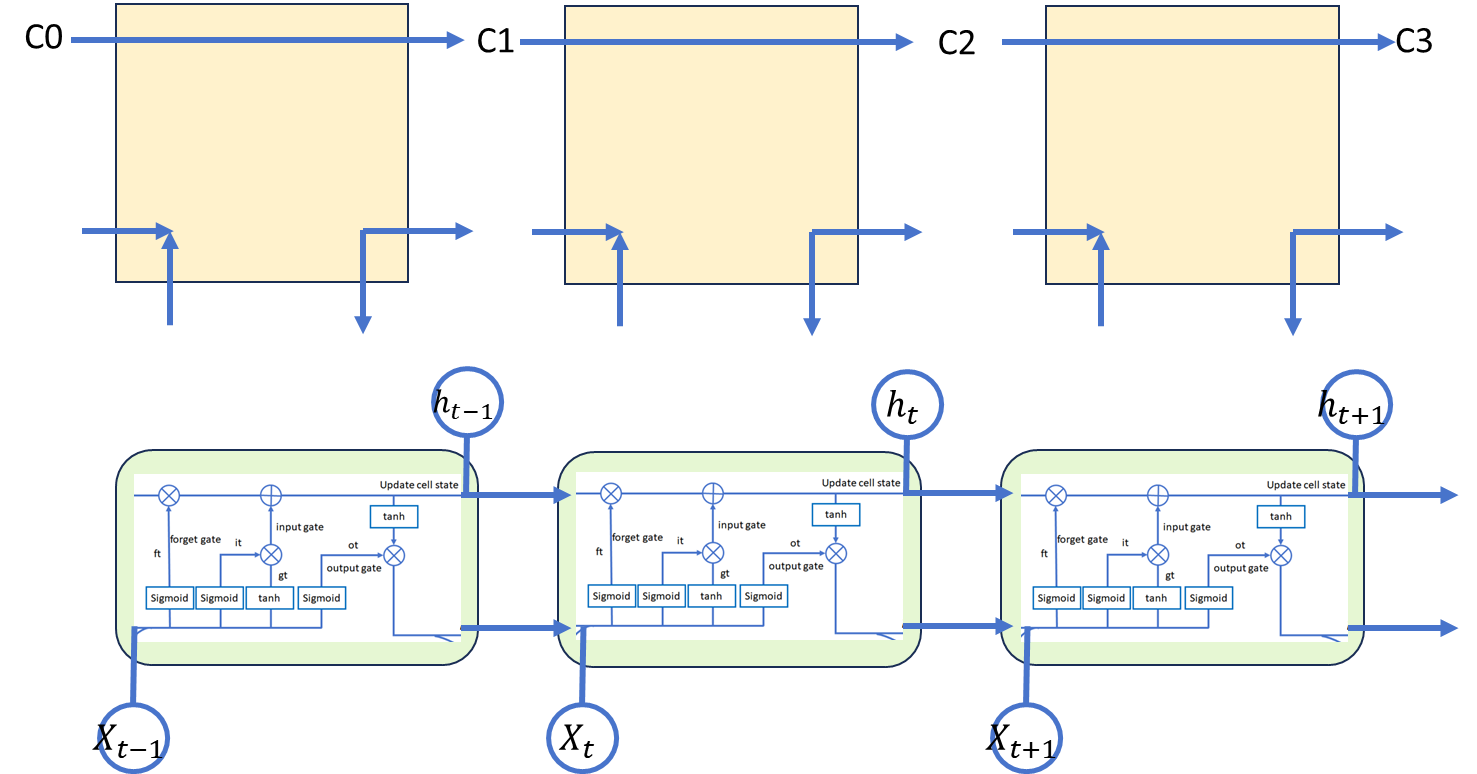
2.3、update cell state(细胞更新单元)
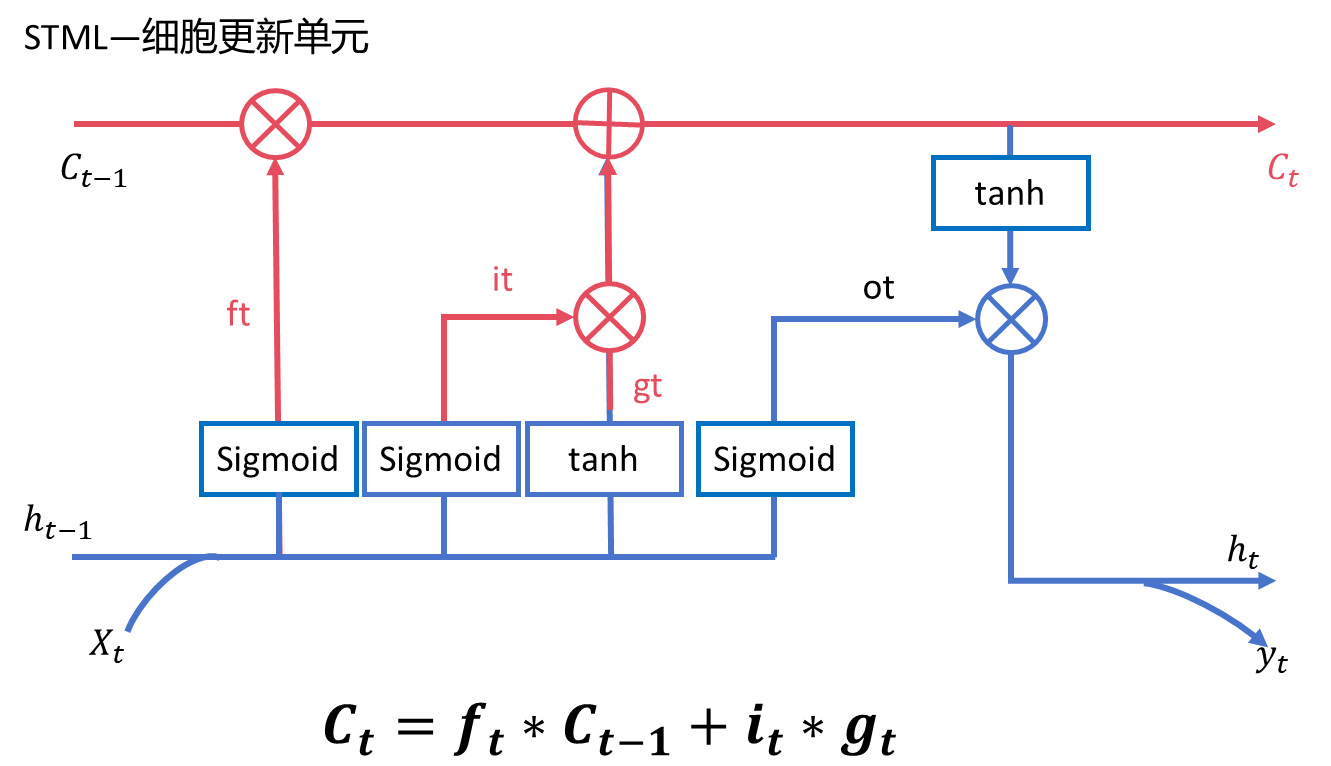
可以看到这个分支是随着时间步进行更新的,遗忘门就是控制模型记忆的, 控制保留多少以前的记忆。然后加上 i_t和g_t 相乘的结果,实际上就是加上输入门的输 入结果,也就是说将多少当前时间步的信息加入到记忆之中。总的来说, 分支的信 息走向就是:先选择性保留之前的记忆,再选择性加入当前的信息,得到新的记忆。
2.4、输出门(output gate)
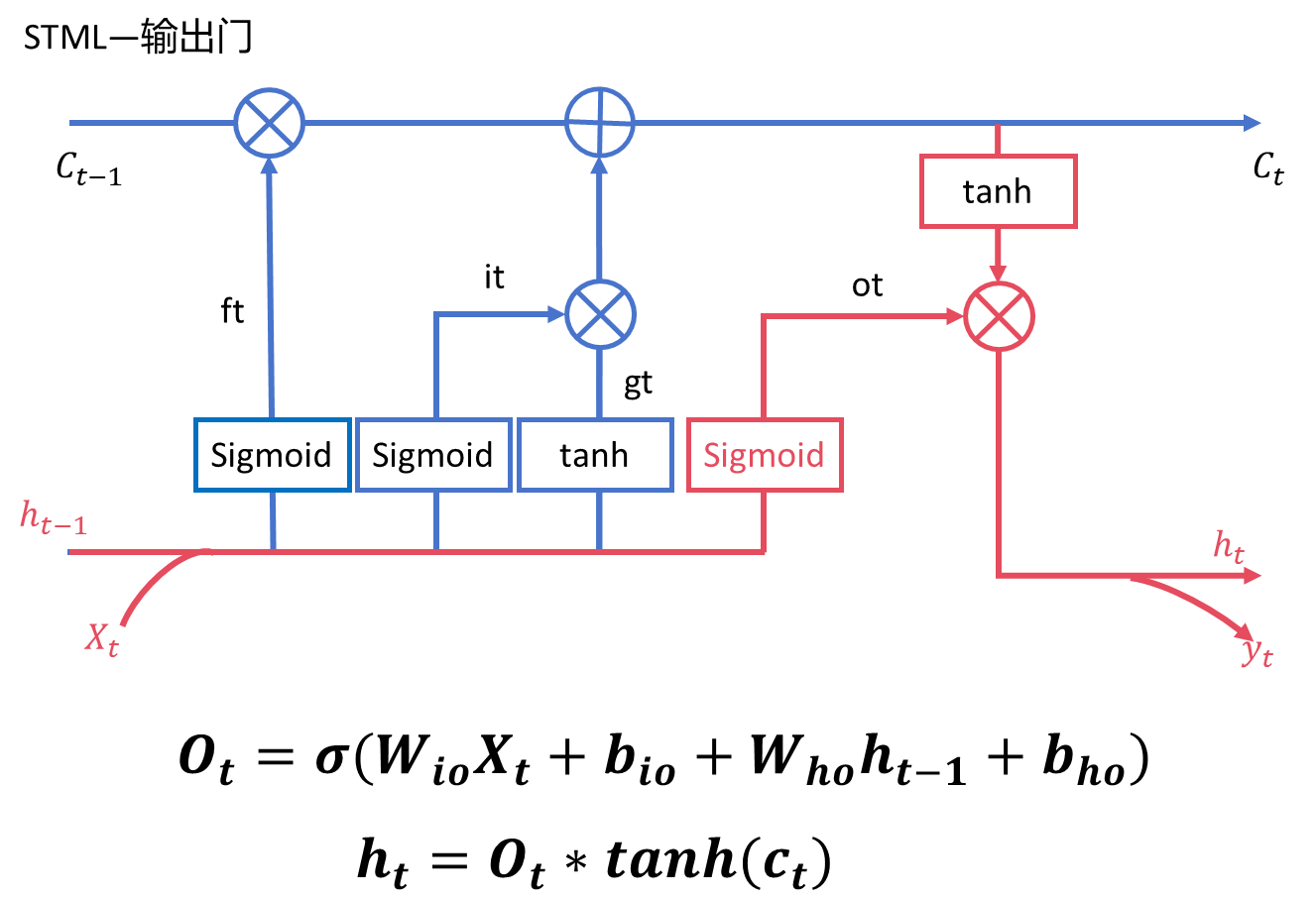
通过sigmoid函数控制输出的程度,然后当前时刻的记忆经过tanh激活,再将两者相乘得到了 即隐藏状态的输出。

import torch
import numpy as np
from torch import nn# 1. 字符输入
text = "In Beijing Sarah bought a basket of apples In Guangzhou Sarah bought a basket of bananas"# 设置随机种子,保证实验的可重复性
torch.manual_seed(1)# 3. 数据集划分
# input_seq 是输入序列,去掉了最后一个字符
input_seq = [text[:-1]]
# output_seq 是目标序列,去掉了第一个字符,与 input_seq 错开一位
output_seq = [text[1:]]
print("input_seq:", input_seq)
print("output_seq:", output_seq)# 4. 数据编码:one-hot 编码
# 获取文本中所有不重复的字符
chars = set(text)
# 将字符排序,保证编码的一致性
chars = sorted(list(chars))
print("chars:", chars)
# 创建字符到数字的映射字典
char2int = {char: ind for ind, char in enumerate(chars)}
print("char2int:", char2int)
# 创建数字到字符的映射字典
int2char = dict(enumerate(chars))
print("int2char:", int2char)
# 将输入序列中的字符转换为数字编码
input_seq = [[char2int[char] for char in seq] for seq in input_seq]
print("input_seq:", input_seq)
# 将输出序列中的字符转换为数字编码
output_seq = [[char2int[char] for char in seq] for seq in output_seq]
print("output_seq:", output_seq)# one-hot 编码函数,用于将数字编码转换为 one-hot 向量
def one_hot_encode(seq, bs, seq_len, size):# 创建一个形状为 (batch_size, seq_len, vocab_size) 的零矩阵features = np.zeros((bs, seq_len, size), dtype=np.float32)# 遍历 batch 中的每个序列for i in range(bs):# 遍历序列中的每个时间步for u in range(seq_len):# 将对应字符的索引位置设置为 1.0features[i, u, seq[i][u]] = 1.0# 将 numpy 数组转换为 PyTorch 张量return torch.tensor(features, dtype=torch.float32)# 对输入序列进行 one-hot 编码
input_seq = one_hot_encode(input_seq, 1, len(text) - 1, len(chars))
# 将输出序列转换为 PyTorch 长整型张量,并调整形状为 (seq_len * batch_size)
output_seq = torch.tensor(output_seq[0], dtype=torch.long).view(-1)
print("output_seq:", output_seq)# 5. 定义前向模型
class Model(nn.Module):def __init__(self, input_size, hidden_size, out_size):super(Model, self).__init__()self.hidden_size = hidden_size# 定义一个 LSTM 层,输入维度为 input_size,隐藏层维度为 hidden_size,层数为 1,batch_first=True 表示输入张量的第一个维度是 batch sizeself.lstm1 = nn.LSTM(input_size, hidden_size, num_layers=1, batch_first=True)# 定义一个全连接层,将 LSTM 的输出映射到词汇表大小self.fc1 = nn.Linear(hidden_size, out_size)def forward(self, x):# 通过 LSTM 层得到输出和隐藏状态# out 的形状为 (batch_size, seq_len, hidden_size)# hidden 是一个包含 (h_n, c_n) 的元组,每个的形状为 (num_layers, batch_size, hidden_size)out, hidden = self.lstm1(x)# 将 LSTM 的输出调整形状为 (seq_len * batch_size, hidden_size),以便输入到全连接层x = out.contiguous().view(-1, self.hidden_size)# 通过全连接层得到最终的输出x = self.fc1(x)return x, hidden# 实例化模型,输入大小为词汇表大小,隐藏层大小为 32,输出大小为词汇表大小
model = Model(len(chars), 32, len(chars))# 6. 定义损失函数和优化器
# 使用交叉熵损失函数,常用于多分类问题
cri = nn.CrossEntropyLoss()
# 使用 Adam 优化器,学习率为 0.01
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)# 7. 开始迭代训练
epochs = 1000
for epoch in range(1, epochs + 1):# 通过模型得到输出和隐藏状态output, hidden = model(input_seq)# 计算损失loss = cri(output, output_seq)# 清空梯度optimizer.zero_grad()# 反向传播计算梯度loss.backward()# 更新模型参数optimizer.step()# 8. 显示频率设置if epoch == 1 or epoch % 50 == 0:print(f"Epoch [{epoch}/{epochs}], Loss {loss:.4f}")# 预测接下来的几个字符
input_text = "I" # 初始输入字符
to_be_pre_len = 20 # 预测的长度# 进行预测
for i in range(to_be_pre_len):# 将当前输入文本转换为字符列表chars = [char for char in input_text]# 将字符列表转换为数字编码的 numpy 数组character = np.array([[char2int[c] for c in chars]])# 对数字编码进行 one-hot 编码character = one_hot_encode(character, 1, character.shape[1], len(chars))# 将 numpy 数组转换为 PyTorch 张量character = torch.tensor(character, dtype=torch.float32)# 将 one-hot 编码的输入送入模型进行预测out, hidden = model(character)# 获取最后一个时间步输出中概率最大的字符的索引char_index = torch.argmax(out[-1]).item()# 将预测的数字索引转换为字符,并添加到输入文本中input_text += int2char[char_index]
# 打印预测结果
print("预测到的:", input_text)
三、LSTM“不会”梯度消失和梯度爆炸的原因
3.1、RNN的梯度消失和梯度爆炸
梯度消失和梯度爆炸是由于RNN的在时间维度上的权值 进行了共享,导致计算梯度时会进行连乘,连乘会导致梯度消失或者梯度爆炸,但是 需要注意的是:当时间步长的时候,连乘的负面效应才会显现的更加明显,即意味 着:近距离(近期记忆)并不会消失,但是远距离(连乘的多了)才会有梯度消失和 梯度爆炸的问题。也就是说:RNN 所谓梯度消失的真正含义是,梯度被近距离梯度 主导,导致模型难以学到远距离的依赖关系。这其实和传统的MLP结构的梯度消失和 梯度爆炸并不同,因为传统MLP在不同的层中并不会权值共享。
3.2、LSTM为什么“不会”梯度消失和梯度爆炸
LSTM也会梯度消失和梯度爆炸!

对于现在的LSTM有三种情况:
1、如果我们把让遗忘门的输出趋近于1,例如模型初始化时会把 forget bias 设置成 较大的正数,让遗忘门饱和),这时候远距离梯度不消失;
2、遗忘门接近 0,但这时模型是故意阻断梯度流的(例如情感分析任务中有一条样 本 “A,但是 B”,模型读到“但是”后选择把遗忘门设置成 0,遗忘掉内容 A,这是合理 的);
3、如果 f 介于 [0, 1] 之间的情况,在这种情况下只能说 LSTM 改善(而非解决)了 梯度消失的状况。




![[爬虫知识] Cookie与Session](http://pic.xiahunao.cn/[爬虫知识] Cookie与Session)




)


)

的类型详解)




