目录
一、RAGFlow 框架
二、Dify 框架
三、两者集成
四、深度对比
1. 核心定位对比
2. 核心功能对比
3. 技术架构对比
4. 部署与成本
5. 适用场景推荐
总结
一、RAGFlow 框架
RAGFlow 是一个专注于深度文档理解和检索增强生成(RAG)技术的框架。它的核心优势在于结合了大规模检索系统和生成式模型(如 GPT 系列),能够从海量数据中快速定位相关信息,并生成符合上下文语义的自然语言回复。RAGFlow 支持多模态数据(如文本、图片、表格等),并通过混合检索技术(结合传统检索和深度学习模型)提高检索结果的准确性和相关性。
RAGFlow是一个专为深度文档理解和检索增强生成而设计的引擎,它结合了预训练的大型语言模型(LLMs)和高效的检索技术,为用户提供了一个强大的工具来处理复杂的问题和场景。RAGFlow的核心优势在于其混合检索能力,它能够从大规模知识库中检索相关文档,然后将这些信息与模型的生成能力相结合,生成更准确、更全面的答案。这种混合方法特别适用于处理需要深度理解和综合多个信息源的问题,如智能客服、搜索引擎和知识库应用。
RAGFlow的工作流程包括两个主要部分:检索和生成。在检索阶段,RAGFlow使用高效的检索算法从知识库中找到与用户查询最相关的文档片段;在生成阶段,这些片段被编码并输入到预训练的模型中,模型在生成文本时会考虑这些检索到的信息,从而生成更精确的答案。RAGFlow还支持多模态数据,如图像和表格,以提供更全面的文档理解和生成能力。
二、Dify 框架
Dify 是一个开源的 LLM(大型语言模型)应用开发平台,旨在简化生成式 AI 应用的创建和部署。它支持多种预训练模型(如 DeepSeek、Claude3 等),并提供可视化的工作流编排工具,帮助开发者快速构建生产级 AI 应用。
Dify是一个开源的LLM应用开发平台,它提供了一站式的解决方案,使得开发者能够快速地从原型设计到产品部署。Dify的核心是其对LLM(大型语言模型)的集成,它支持多种预训练模型,并且允许用户自定义模型的训练和微调。Dify的用户界面直观,功能全面,使得开发者无需具备深厚的技术背景,也能轻松地开发基于LLM的应用。
三、两者集成
在RAGFlow与Dify的集成中,Dify充分利用了RAGFlow的深度文档理解和检索增强生成能力,将其无缝地融入到其应用开发流程中。这使得Dify用户能够构建更智能、更高效的文档处理和知识检索应用。通过Dify,开发者可以轻松地将RAGFlow的检索结果与模型的生成能力相结合,实现对复杂文档的深度理解和精准回答,从而提升应用的用户体验和问题解决能力。Dify的API支持也让开发者能够灵活地定制和扩展其应用功能,以满足不同场景的需求。
四、深度对比
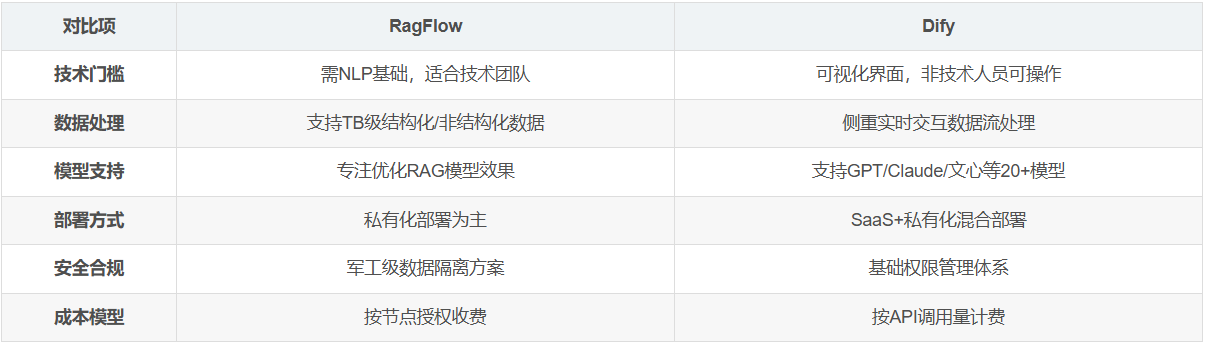
以下是 ragflow、Dify、FastGPT 的详细对比,从功能定位、技术特点到适用场景进行综合分析,帮助您根据需求选择最合适的工具:
1. 核心定位对比
| 工具 | 核心定位 | 适用对象 |
|---|---|---|
| Ragflow | 专注于 RAG(检索增强生成) 的引擎,强调复杂文档解析与高精度知识检索。 | 企业级用户、需处理多格式数据的开发者。 |
| Dify | 通用型AI应用开发平台,支持低代码构建多种AI应用(如聊天机器人、自动化流程)。 | 开发者、企业需快速迭代AI功能的场景。 |
| FastGPT | 轻量级 对话生成框架,基于大模型快速部署问答系统,侧重高效响应与简单集成。 | 中小项目、需快速上线对话功能的场景。 |
2. 核心功能对比
| 功能 | Ragflow | Dify | FastGPT |
|---|---|---|---|
| 文档处理 | ✔️ 多格式解析(PDF/Word/OCR/表格等) | ✔️ 基础文本解析 | ✔️ 文本/简单文件解析 |
| 检索能力 | ✔️ 多路召回+重排序,支持结构化数据 | ✔️ 基于向量检索,依赖外部模型 | ✔️ 基础向量检索 |
| 模型支持 | ❌ 固定RAG流程,依赖内置解析与检索模型 | ✔️ 支持多模型(OpenAI、Claude、开源LLM、商用模型) | ✔️ 主要支持ChatGLM系列,可有限接入其他开源模型(支持中转接口) |
| 可视化界面 | ✔️ 配置化界面 | ✔️ 低代码工作流设计器 | ✔️ 简单配置面板 |
| 扩展性 | ✔️ 插件扩展(数据源/解析器) | ✔️ API + 插件系统 + 代码级自定义 | ❌ 仅支持基础配置,无深度扩展接口 |
| 自动化流程 | ✔️ 自动化文档解析→检索→生成流水线 | ✔️ 可视化工作流编排(多模型协作+业务逻辑) | ❌ 仅问答流程自动化,无复杂逻辑控制 |
3. 技术架构对比
| 工具 | 技术栈 | 核心优势 |
|---|---|---|
| Ragflow | Milvus + PostgreSQL + 自研解析算法,多路召回+LLM重排序。 | 高精度检索,复杂文档解析能力强,适合企业级场景。 |
| Dify | 微服务架构,支持云原生部署,集成LangChain等框架。 | 灵活可扩展,多模型支持,适合复杂业务流开发。 |
| FastGPT | 基于MongoDB + 向量数据库,轻量级API架构。 | 部署简单,响应快,资源占用低。 |
4. 部署与成本
| 工具 | 部署方式 | 开源情况 | 学习成本 |
|---|---|---|---|
| Ragflow | Docker/K8s,需较高配置资源。 | 开源(Apache 2.0) | 较高(需熟悉RAG流程) |
| Dify | 云服务/私有部署,支持Serverless。 | 核心开源,高级功能付费。 | 中等(可视化操作) |
| FastGPT | Docker一键部署,轻量级。 | 开源(MIT协议) | 低(配置简单) |
5. 适用场景推荐
- 选择 Ragflow:
需处理 PDF、扫描件、表格等复杂文档,且对检索精度要求高的场景,如法律合同分析、医疗报告处理。 - 选择 Dify:
需要快速构建 多模型协作的AI应用(如智能写作+数据分析),或需自定义复杂业务流程的企业。 - 选择 FastGPT:
追求 低成本快速部署对话系统,如教育问答、电商客服等轻量级场景。
总结
1. RAGFlow:企业级复杂文档处理专家
- 定位:专为高精度非结构化数据(PDF、扫描件、表格)检索设计,强调工业级准确率。
- 核心优势:
- 模型支持:内置多模态解析引擎(OCR、表格识别),检索层集成混合检索(关键词+向量+语义),但生成层依赖固定模型,灵活性低。
- 扩展性:可通过插件接入企业私有数据源(如内部数据库),或扩展文件解析器(如定制版式合同)。
- 自动化流程:从文档上传到答案生成全链路自动化,适合法律审查、金融报告分析等需严格流程控制的场景。
- 适用场景:医疗报告结构化、法律合同比对、学术论文解析。
2. Dify:低代码AI应用工厂
- 定位:以可视化编排为核心,支持快速构建复杂AI应用(如客服+工单系统+数据分析混合应用)。
- 核心优势:
- 模型支持:无绑定模型,可自由切换GPT-4、Claude、文心一言等,支持私有化部署开源模型(如LLaMA)。
- 扩展性:开放API与SDK,可集成外部服务(如CRM系统);支持自定义Python插件,满足开发级需求。
- 自动化流程:通过拖拽式工作流设计器,实现多模型接力处理(如先分类用户意图→调用不同模型生成响应→记录日志)。
- 适用场景:智能客服系统、自动化报表生成、多模型协作的营销工具。
3. FastGPT:轻量级问答部署利器
- 定位:专注快速搭建垂直领域问答机器人,强调“开箱即用”与低资源消耗。
- 核心优势:
- 模型支持:默认适配ChatGLM系列,轻量化微调(LoRA)支持领域知识快速注入,但对其他模型兼容性较差。
- 扩展性:仅提供基础配置选项(如调整问答模版、修改检索阈值),无法深度定制流程或集成外部系统。
- 自动化流程:问答链路自动化(用户输入→检索→生成),但缺乏分支逻辑、多步骤交互等高级控制。
- 适用场景:教育知识库问答、电商产品咨询、企业内部FAQ系统。
的类型详解)








)
 相关函数)
缓存穿透、缓存击穿、缓存雪崩)



安装教程详解:第二篇)


![[原创]X86C++反汇编01.IDA和提取签名](http://pic.xiahunao.cn/[原创]X86C++反汇编01.IDA和提取签名)
