磁盘的访问方式
- CHS(柱面,磁头,扇区) 法(磁盘硬件查找):
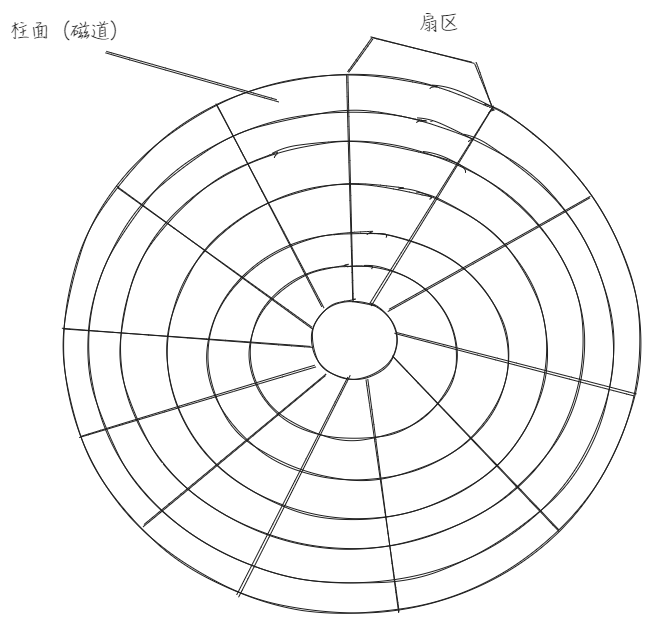
- 确定柱面(C)
磁头臂移动到对应的柱面位置。例如,柱面号为 5,则磁头移动到第 5 个磁道组 - 选择磁头(H)
激活对应的磁头(即选择具体的盘面)。例如,磁头号为 0 表示第一个盘面 - 定位扇区(S)
等待磁盘旋转,直到目标扇区转到磁头下方。例如,扇区号为 3 表示读取当前磁道的第 3 个扇区
操作系统拿到 CHS 地址之后,会将其转换成 LBA 地址,一般而言,操作系统和硬盘交互时,基本单位为 4KB,也就是 8 个连续的扇区,作为一个块,后续操作系统只需要提供块号,然后磁盘自动向后数 8 个就可以访问到一整个块了,如:提供的块号为 2,通过 2*8 得到第一个这个块的第一个扇区为 16,然后自动向后数 8 个这个就是整个块了
- LBA 法(操作系统抽象后):
LBA=(C×Hmax+H)×Smax+(S−1)
- Hmax:每个柱面的最大磁头数
- SmaxSmax:每个磁道的最大扇区数
- 扇区号 S 需减 1(因 LBA 从 0 开始,而 CHS 扇区从 1 开始)
对磁盘的管理就变成了对 LBA 地址的管理,然后通过将硬盘整个硬盘分成很多个分区进行更好的管理
文件系统是系统底层对文件进行管理的
常见文件系统:ext4 exfat fat32
VFS 虚拟文件系统是文件系统的抽象层,隐藏了底层文件系统的实现,用于对外提供接口用于文件管理,在操作系统中通常以一个内核软件层的形式存在,它位于操作系统内核和底层文件系统之间
磁盘文件系统
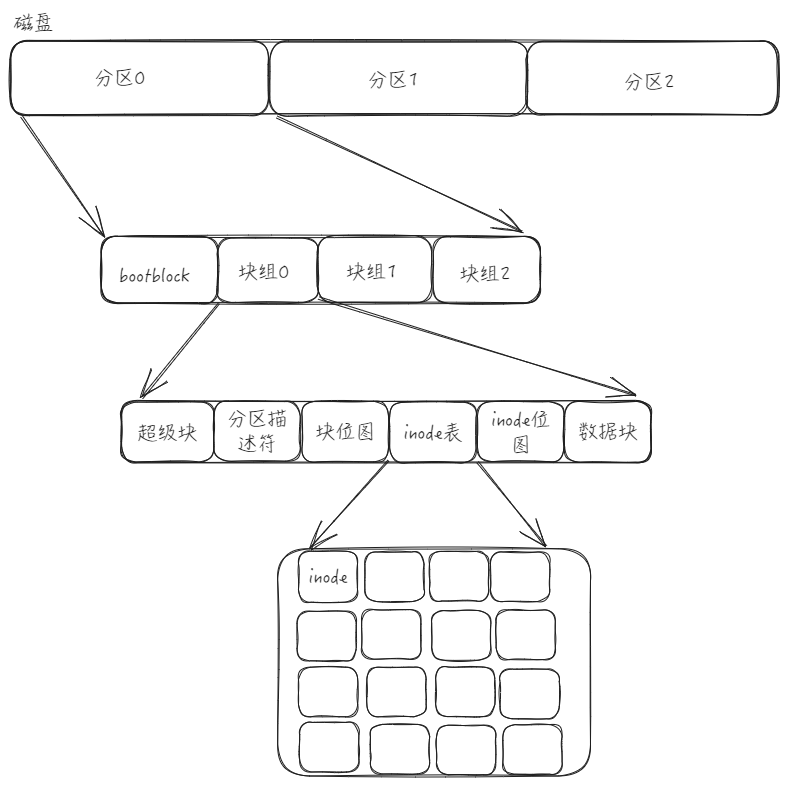
在硬盘中会存在多个分区,这些分区内部又被分成了多个组,每个分组内部都会有超级块、分区描述符、块位图、inode 表、inode 位图、数据块
在每个分区的内部分组,然后写入文件系统的管理数据的过程叫做格式化
bootblock
磁盘中用于引导操作系统加载和启动最小指令集或代码,同时也可能包含了磁盘分区表和磁盘状态信息
在 MBR 中,通常只有一个 Boot Block 位于整个磁盘的开始部分,而不是每个分区都有,而在 GPT 中,每个分区都有类似于 boot block 这样用于引导分区内容的分区引导记录(PBR),但 PBR 和传统的 boot block 有一定区别
超级块
超级块是存储对应整个分区的文件系统相关情况,它包含了文件系统的全局信息,记录的信息主要有:block 和 inode 的总量,未使用的 block 和 inode 的数量,一个 block 和 inode 的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。并不是所有块组都有超级块,由于超级块是全局性的,因此可以不用每个分区都设置超级块,通常为了确保数据的可靠性,会在文件系统的多个位置进行备份。Super Block的信息被破坏,可以说整个文件系统结构就被破坏了,整个分区就挂掉了
数据块
用于存放文件数据,文件的数据被打散分布在磁盘上,类似一个数组,数组里面可以直接存放数据,也可以存放指向下一个数组的指针,用来间接存储文件
GDT 块组描述符
描述的是一整个块组的具体属性,如块组起始位置、大小、包含的块数等,块组描述符还描述了块组内部的布局,包括inode表、数据块和空闲块的分布
块位图
用于记录数据块中哪些被占用,哪些没有
在申请空间时,文件系统先对位图进行检查,若有剩余空间,则将这些空间标记为已分配,一旦位图更新,文件系统将会实际将这些空间分配,最后文件系统把这些文件的头指针返回给请求者
inode 位图
记录 inode 中哪些被占用,哪些没有
分配 inode 位图的过程:
- 扫描inode位图,查找一个空闲的位(即值为0的位)
- 将找到的空闲位标记为已使用(即将该位设置为1)
- 将新文件的元数据信息写入对应的inode中
- 文件删除时先将元数据和 inode 位图的关联断开,然后将 inode 的相应位置标记为空闲
inode 表
用于存放文件的属性,如所有者,文件大小,修改时间等,inode 中不仅保存着文件的属性,还有一个 datablock 数组,数组中保存着文件占据了哪些块,数据块中也不仅仅只是数据,还有可能是指向实际数据位置的指针,或者指针的指针等,通过建立多级指针来间接映射来管理更大的空间,从而可以建立更大的文件。但是这种方式降低了磁盘的寻址效率
inode 内部并没有文件名,在内核层面,每个文件都有一个 inode number,通过这个来标识文件,可以通过 ls -i 命令来查看文件的 inode 号
inode 编号是以分区为单位的,而不是以分组为单位的,因为 inode 在分区内部不能重复,但是在另一个分区内可能会有与该分区重复的 inode,因此inode 不能跨分区访问
有多少文件就有多少个 inode,通常在 Linux 中 inode 大小为 128 字节或 256 字节
inode 表中有许多 inode 块,一个块大小通常为 4kb,一个块中有 4*1024/128=32 个 inode
查找文件 inode 的过程
当用户或程序请求访问一个文件时,文件系统会首先查找该文件所在的目录
目录本身也是一个文件,它包含了文件名和对应inode编号的映射关系(称为目录项)
文件系统会读取包含目标文件名的目录项,一旦找到与文件名匹配的目录项,文件系统就可以从中提取出inode编号
有了inode编号后,文件系统会使用这个编号和inode表的大小来计算inode在inode表中的位置
因此,当目录的 R 权限被取消后,由于无法读取到目录的文件属性和内容,也就无法获得对应的 inode,因此也就无法进行访问,当目录的 W 权限被取消后,由于无法向目录写入文件名和 inode 的映射关系,也就无法创建文件了
通过 inode 查找文件的过程
每一个分组都会有对应的 inode 范围,查找文件时,首先确定在哪个分区,然后通过 inode 的编号来确定文件是在哪个分组中的,再通过分组内的 inode 表找到具体的 inode,这样就找到了文件
目录
目录也是一个文件,也有自己的文件属性和文件内容,因此也会有 inode,目录的文件内容为文件名和 inode 编号的映射关系,目录本质上是一个存储文件名与文件元数据(如存储位置、大小、权限等)映射关系的数据库,inode 和文件名互为键值,彼此间能够找到对方,如果出现同名文件,就会导致两条相同的键(文件名)对应不同的值(inode 号)
可以通过目录来知道在哪个分区下的原因
当完成分区并且创建好文件系统后,此时由于并没有将其挂载到任何目录,因此操作系统无法访问,所以需要将其挂载到某一个目录中,此时访问该目录也就是在访问该分区了
进程的获得完整的文件路径是通过 CWD 获取的,CWD 存放在 task_struct 中
创建一个新文件的过程
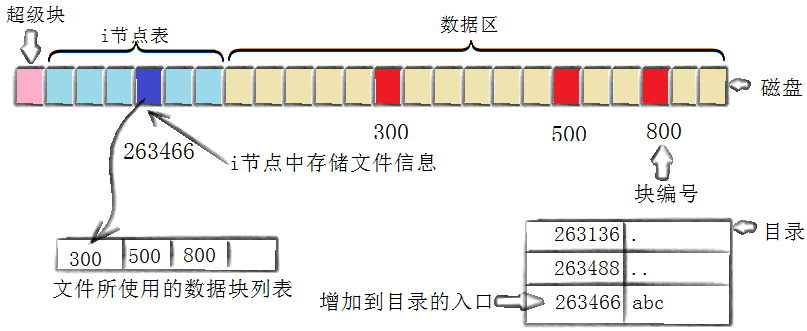
- 存储属性
内核先找到一个空闲的i节点(这里是263466)。内核把文件信息记录到其中 - 存储数据
该文件需要存储在三个磁盘块,内核找到了三个空闲块:300,500,800。将内核缓冲区的第一块数据
复制到300,下一块复制到500,以此类推 - 记录分配情况
文件内容按顺序300,500,800存放。内核在inode上的磁盘分布区记录了上述块列表 - 添加文件名到目录
当通过文件名访问文件时,系统先通过目录找到对应的 inode 号,再通过 inode 读取文件数据,如果存在同名文件,就会出现不确定到达访问哪个文件的 inode 的情况
删除文件的过程
通过文件名找到对应的 inode,然后找到 inode 在 inode bitmap 中的位置,将这个位置标记为空,然后遍历 inode table 中的映射关系,在 块位图中依次标记为空,这样就将一个文件删除了
软、硬链接
软链接
相当于生成一个快捷方式,是一个独立的文件,因为有自己独立的 inode,文件里面包含着目标文件所对应的路径字符串,软链接被删除后不会影响目标文件,但是删除目标文件后软链接就会失效
硬链接
就是一个文件名和 inode 的映射关系,建立硬链接,就是在指定目录下,添加一个新的文件名和 inode number 的映射关系
硬链接没有自己独立的 inode,用的 inode 是目标文件的
硬链接就是两个文件共享同一个数据块,可以认为是同一个文件的不同副本,但这些副本共享同一个空间,只要还存在一个硬链接的文件,文件内容就不会丢失
由于硬链接的两个文件共享一个 inode,因此当修改任意一个文件的权限时,其他文件也会跟着被修改
硬连接数:
有多少文件名字符通过 inode 指向目标文件,硬连接数就是多少
硬链接的作用:
- 硬链接可以构建 Linux 的相对文件结构,从而能够使用
.和..来进行路径定位 - 通过硬链接来备份文件
当前目录中即使没有文件,但也会有一个 . 和 .. ,其中 . 代表当前目录,使用的 inode 和当前目录相同,因此目录会有两个硬链接数,当在该目录中创建一个新的目录时,新创建的目录中 .. 会指向上一个目录的 inode,因此上一个目录的 inode 还会增加 1,变为 3
任何目录刚新建的时候引用计数一定是 2,因此一个目录内的目录数量引用计数-2
Linux 中不允许给目录建立硬链接,防止形成路径环绕
一般用硬链接来进行文件备份,节省空间
打开的文件和内核、内存有关,没有被打开的文件和硬盘、文件系统有关,当要修改文件时,首先会找到 inode,然后将 inode 和 task_struct 关联起来,然后获取文件的块号,从指定的分区分组中拿到数据块,将其加载到文件的内核缓冲区中,这样通过内核的方式将文件拷贝到用户缓冲区要修改文件时,将写入的数据写入语言的缓冲区,然后通过文件描述符将内容写入文件的内核缓冲区,最终将修改的内容写回 inode,如果内容少了,则释放空间,否则申请空间
文本写入和二进制写入:
- 文本写入:会把数据转换为文本字符串,并且按照特定的字符编码(像 UTF8、ASCII)来存储,语言通过将输入的数据转换成字符,存放在语言的缓冲区中,最后打印出来
- 二进制写入:直接存储数据的原始字节,不会进行编码转换
)


的简单介绍)


![[学习]浅谈C++异常处理(代码示例)](http://pic.xiahunao.cn/[学习]浅谈C++异常处理(代码示例))
)



)





:微服务的划分原则)

