
目录
一、引言
二、PLE(Progressive Layered Extraction,渐进式分层提取模型)
2.1 技术原理
2.2 技术优缺点
2.3 业务代码实践
2.3.1 业务场景与建模
2.3.2 模型代码实现
2.3.3 模型训练与推理测试
2.3.4 打印模型结构
三、总结
一、引言
上一篇我们讲了PLE的前置模型CGC(Customized Gate Control)定制门控网络,核心思想是在MMoE基础上,为每一个任务tower定制独享专家,使用任务独享专家与共享专家共同决定任务Tower的输入,相比于MMoE仅用Gate门控表征任务Tower的方法,CGC引入独享专家,对任务表征更加全面,又通过共享专家保证关联性。
今天在CGC的基础上,重点讲解PLE(Progressive Layered Extraction)模型,可以理解PLE为CGC的多层堆叠,通过将独享专家、共享专家基于门控网络交叉学习,既能学习独有任务的特异性,又能学习共享信息。
二、PLE(Progressive Layered Extraction,渐进式分层提取模型)
2.1 技术原理
PLE(Progressive Layered Extraction)全称为渐进式分层提取模型,是一种改进的多任务学习模型,旨在解决多任务学习中的负迁移和跷跷板现象。PLE模型通过分层提取机制结合共享特征和任务特定特征,逐步优化多任务学习的性能。主要由多层CGC网络堆叠而成,每个CGC网络包含一组共享专家、若干组独立专家,通过对应的共享专家门控、独立专家门控对共享专家组、独立专家组内的多个MLP加权结果平均。
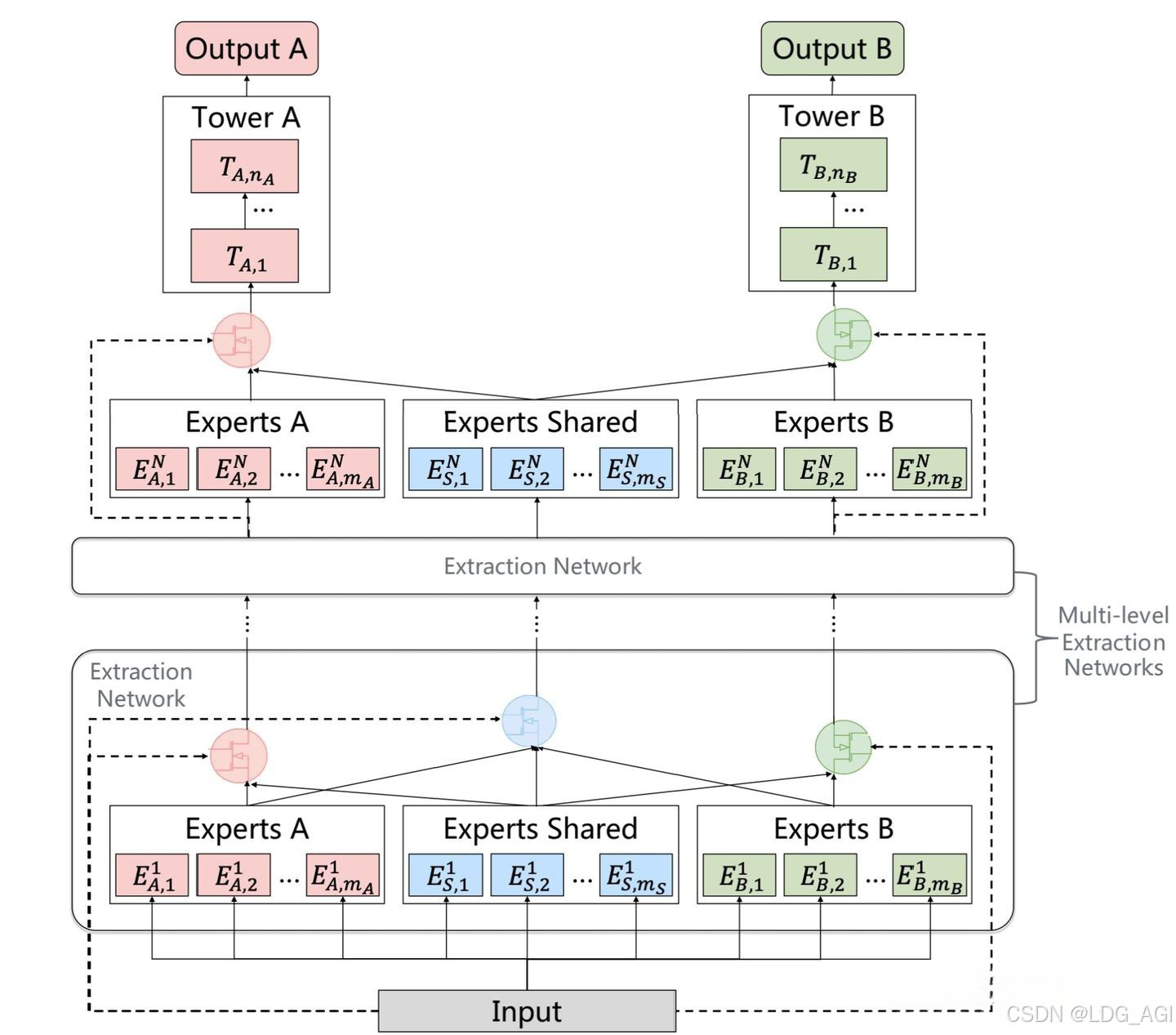
- 共享专家网络:样本数据分别输入num_shared_experts个专家网络进行推理,每个共享专家网络实际上是一个多层感知机(MLP),输入维度为x,输出维度为output_experts_dim。
- 独享专家网络:样本数据分别输入num_task_experts个专家网络进行推理,每个共享专家网络实际上是一个多层感知机(MLP),输入维度为x,输出维度为output_experts_dim。
- 门控网络:样本数据输出各自任务对应的门控网络,每个门控网络可以是一个多层感知机,也可以是一个双层的交叉,主要是为了输出专家网络的加权平均权重。
- 任务网络:对于每一个Task,将各自对应num_shared_experts个共享专家和num_task_experts个独立专家,基于对应gate门控网络的softmax加权平均,作为各自Task的输入,所有Task的输入统一维度均为output_experts_dim。
2.2 技术优缺点
相较于MMoE网络,CGC为每一个任务tower定制独享专家,实用任务独享专家与共享专家共同决定任务Tower的输入,相比于MMoE仅用Gate门控表征任务Tower的方法,CGC引入独享专家,对任务表征更加全面,又通过共享专家保证关联性。
优点:
- 分层提取结构:PLE通过多层提取机制逐步分离共享特征和任务特定特征,避免了传统多任务学习中的过度耦合问题。
- CGC(Customized Gate Control):每层包含共享专家和任务特定专家,通过门控机制动态分配特征,既保留了共享信息,又增强了任务特定性。
- 任务特定性增强:相比传统的多任务学习模型,PLE在每一层都为每个任务引入特定专家,增强了任务之间的解耦,提高了模型对不同任务的适应性。
- 多任务性能提升:通过分层结构和门控机制,PLE能在多任务场景中更好地平衡任务间冲突,提升整体性能。
缺点:
- 相较于DeepSeekMoE的路由方法,PLE专家组合不足。
2.3 业务代码实践
2.3.1 业务场景与建模
我们还是以小红书推荐场景为例,针对一个视频,用户可以点红心(互动),也可以点击视频进行播放(点击),针对互动和点击两个目标进行多目标建模

我们构建一个100维特征输入,2层CGC,第一层CGC包含1组共享专家网络(含2个共享专家),2组独享专家网络(各含2个独享专家),3个门控网络(1个共享门控,2个独立门控),第二层CGC包含1组共享专家网络(含2个共享专家),2组独享专家网络(各含2个独享专家),2个门控网络(2个独立门控),用于建模多目标学习问题,模型架构图如下:
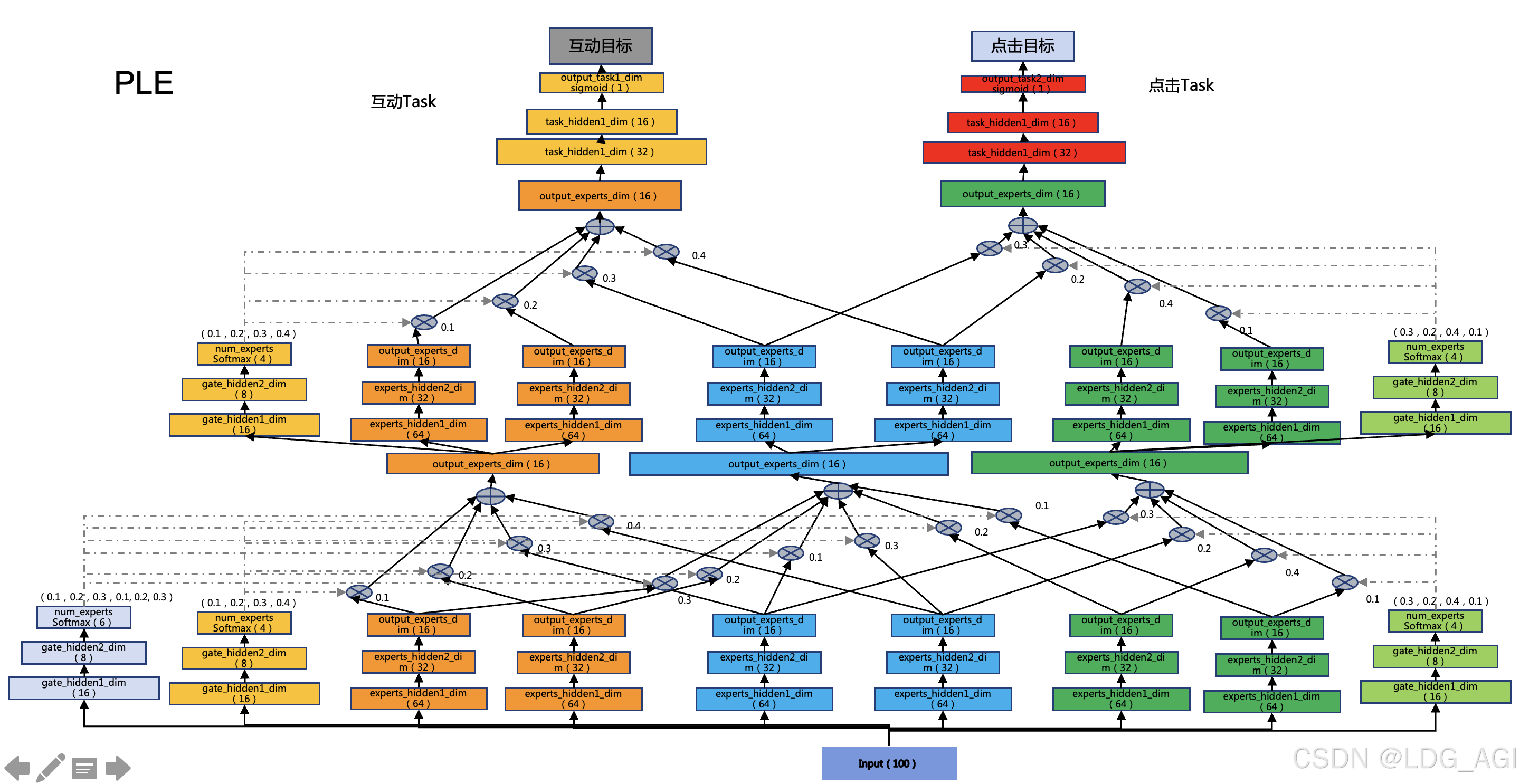
如架构图所示,其中有几个注意的点:
- num_shared_experts + num_task_experts:独立Gate的维度等于共享专家的维度(MLP个数,图中为2)加上任务独享专家的维度(MLP个数,图中为2)。
- num_shared_experts + num_task_experts + num_task_experts:共享Gate的维度等于共享专家的维度(MLP个数,图中为2)加上所有(图中为2组)任务独享专家的维度(MLP个数,图中为2)。
- output_experts_dim:共享专家、独享专家网络的输出维度和task网络的输入维度相同,task网络承接的是专家网络各维度的加权平均值,experts网络与task网络是直接对应关系。
- Softmax:Gate门控网络对共享专家和独享专家的偏好权重采用Softmax归一化,保证专家网络加权平均后值域相同
2.3.2 模型代码实现
基于pytorch,实现上述PLE网络架构,如下:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDatasetclass PLEModel(nn.Module):def __init__(self, input_dim, experts_hidden1_dim, experts_hidden2_dim, output_experts_dim, task_hidden1_dim, task_hidden2_dim, output_task1_dim, output_task2_dim, gate_hidden1_dim, gate_hidden2_dim, num_shared_experts, num_task_experts):super(PLEModel, self).__init__()# 初始化函数外使用初始化变量需要赋值,否则默认使用全局变量# 初始化函数内使用初始化变量不需要赋值 self.num_shared_experts = num_shared_expertsself.num_task_experts = num_task_expertsself.output_experts_dim = output_experts_dim# 初始化1层共享专家self.shared_experts_1 = nn.ModuleList([nn.Sequential(nn.Linear(input_dim, experts_hidden1_dim),nn.ReLU(),nn.Linear(experts_hidden1_dim, experts_hidden2_dim),nn.ReLU(),nn.Linear(experts_hidden2_dim, output_experts_dim),nn.ReLU()) for _ in range(num_shared_experts)])# 初始化1层任务1专家self.task1_experts_1 = nn.ModuleList([nn.Sequential(nn.Linear(input_dim, experts_hidden1_dim),nn.ReLU(),nn.Linear(experts_hidden1_dim, experts_hidden2_dim),nn.ReLU(),nn.Linear(experts_hidden2_dim, output_experts_dim),nn.ReLU()) for _ in range(num_task_experts)])# 初始化1层任务2专家self.task2_experts_1 = nn.ModuleList([nn.Sequential(nn.Linear(input_dim, experts_hidden1_dim),nn.ReLU(),nn.Linear(experts_hidden1_dim, experts_hidden2_dim),nn.ReLU(),nn.Linear(experts_hidden2_dim, output_experts_dim),nn.ReLU()) for _ in range(num_task_experts)])# 初始化2层共享专家self.shared_experts_2 = nn.ModuleList([nn.Sequential(nn.Linear(output_experts_dim, experts_hidden1_dim),nn.ReLU(),nn.Linear(experts_hidden1_dim, experts_hidden2_dim),nn.ReLU(),nn.Linear(experts_hidden2_dim, output_experts_dim),nn.ReLU()) for _ in range(num_shared_experts)])# 初始化2层任务1专家self.task1_experts_2 = nn.ModuleList([nn.Sequential(nn.Linear(output_experts_dim, experts_hidden1_dim),nn.ReLU(),nn.Linear(experts_hidden1_dim, experts_hidden2_dim),nn.ReLU(),nn.Linear(experts_hidden2_dim, output_experts_dim),nn.ReLU()) for _ in range(num_task_experts)])# 初始化2层任务2专家self.task2_experts_2 = nn.ModuleList([nn.Sequential(nn.Linear(output_experts_dim, experts_hidden1_dim),nn.ReLU(),nn.Linear(experts_hidden1_dim, experts_hidden2_dim),nn.ReLU(),nn.Linear(experts_hidden2_dim, output_experts_dim),nn.ReLU()) for _ in range(num_task_experts)])# 初始化门控网络1层任务1self.gating1_network_1 = nn.Sequential(nn.Linear(input_dim, gate_hidden1_dim),nn.ReLU(),nn.Linear(gate_hidden1_dim, gate_hidden2_dim),nn.ReLU(),nn.Linear(gate_hidden2_dim, num_shared_experts+num_task_experts),nn.Softmax(dim=1))# 初始化门控网络1层任务2self.gating2_network_1 = nn.Sequential(nn.Linear(input_dim, gate_hidden1_dim),nn.ReLU(),nn.Linear(gate_hidden1_dim, gate_hidden2_dim),nn.ReLU(),nn.Linear(gate_hidden2_dim, num_shared_experts+num_task_experts),nn.Softmax(dim=1))# 初始化1层共享门控self.gating_shared_network_1 = nn.Sequential(nn.Linear(input_dim, gate_hidden1_dim),nn.ReLU(),nn.Linear(gate_hidden1_dim, gate_hidden2_dim),nn.ReLU(),nn.Linear(gate_hidden2_dim, num_shared_experts + num_task_experts + num_task_experts),nn.Softmax(dim=1))# 初始化门控网络2层任务1self.gating1_network_2 = nn.Sequential(nn.Linear(output_experts_dim, gate_hidden1_dim),nn.ReLU(),nn.Linear(gate_hidden1_dim, gate_hidden2_dim),nn.ReLU(),nn.Linear(gate_hidden2_dim, num_shared_experts+num_task_experts),nn.Softmax(dim=1))# 初始化门控网络2层任务2self.gating2_network_2 = nn.Sequential(nn.Linear(output_experts_dim, gate_hidden1_dim),nn.ReLU(),nn.Linear(gate_hidden1_dim, gate_hidden2_dim),nn.ReLU(),nn.Linear(gate_hidden2_dim, num_shared_experts+num_task_experts),nn.Softmax(dim=1))# 定义任务1的输出层self.task1_head = nn.Sequential(nn.Linear(output_experts_dim, task_hidden1_dim),nn.ReLU(),nn.Linear(task_hidden1_dim, task_hidden2_dim),nn.ReLU(),nn.Linear(task_hidden2_dim, output_task1_dim),nn.Sigmoid()) # 定义任务2的输出层self.task2_head = nn.Sequential(nn.Linear(output_experts_dim, task_hidden1_dim),nn.ReLU(),nn.Linear(task_hidden1_dim, task_hidden2_dim),nn.ReLU(),nn.Linear(task_hidden2_dim, output_task2_dim),nn.Sigmoid()) def forward(self, x):#处理第一层#第一层门控gates1 = self.gating1_network_1(x)gates2 = self.gating2_network_1(x)gates_shared = self.gating_shared_network_1(x)#定义第一层输出batch_size, _ = x.shapetask1_expert_inputs = torch.zeros(batch_size, self.output_experts_dim)task2_expert_inputs = torch.zeros(batch_size, self.output_experts_dim)shared_expert_inputs = torch.zeros(batch_size, self.output_experts_dim)#第一层task1、shared、task2专家网络输出task1_experts_1_output_0 = self.task1_experts_1[0](x)task1_experts_1_output_1 = self.task1_experts_1[1](x)shared_experts_1_output_0 = self.shared_experts_1[0](x)shared_experts_1_output_1 = self.shared_experts_1[1](x)task2_experts_1_output_0 = self.task2_experts_1[0](x)task2_experts_1_output_1 = self.task2_experts_1[1](x)#第一层共享专家网络输出shared_expert_inputs += task1_experts_1_output_0 * gates_shared[:, 0].unsqueeze(1)shared_expert_inputs += task1_experts_1_output_1 * gates_shared[:, 1].unsqueeze(1)shared_expert_inputs += shared_experts_1_output_0 * gates_shared[:, 2].unsqueeze(1)shared_expert_inputs += shared_experts_1_output_1 * gates_shared[:, 3].unsqueeze(1)shared_expert_inputs += task2_experts_1_output_0 * gates_shared[:, 4].unsqueeze(1)shared_expert_inputs += task2_experts_1_output_1 * gates_shared[:, 5].unsqueeze(1)#第一层任务1网络输出task1_expert_inputs += task1_experts_1_output_0 * gates1[:, 0].unsqueeze(1)task1_expert_inputs += task1_experts_1_output_1 * gates1[:, 1].unsqueeze(1)task1_expert_inputs += shared_experts_1_output_0 * gates1[:, 2].unsqueeze(1)task1_expert_inputs += shared_experts_1_output_1 * gates1[:, 3].unsqueeze(1)#第一层任务2网络输出task2_expert_inputs += shared_experts_1_output_0 * gates2[:, 0].unsqueeze(1)task2_expert_inputs += shared_experts_1_output_1 * gates2[:, 1].unsqueeze(1)task2_expert_inputs += task2_experts_1_output_0 * gates2[:, 2].unsqueeze(1)task2_expert_inputs += task2_experts_1_output_1 * gates2[:, 3].unsqueeze(1)#处理第二层gates1 = self.gating1_network_2(task1_expert_inputs)gates2 = self.gating2_network_2(task2_expert_inputs)#定义第二层输出task1_inputs = torch.zeros(batch_size, self.output_experts_dim)task2_inputs = torch.zeros(batch_size, self.output_experts_dim)#第二层task1、shared、task2专家网络输出task1_experts_2_output_0 = self.task1_experts_2[0](task1_expert_inputs)task1_experts_2_output_1 = self.task1_experts_2[1](task1_expert_inputs)shared_experts_2_output_0 = self.shared_experts_2[0](shared_expert_inputs)shared_experts_2_output_1 = self.shared_experts_2[1](shared_expert_inputs)task2_experts_2_output_0 = self.task2_experts_2[0](task2_expert_inputs)task2_experts_2_output_1 = self.task2_experts_2[1](task2_expert_inputs)#第二层任务1网络输出task1_inputs += task1_experts_2_output_0 * gates1[:, 0].unsqueeze(1)task1_inputs += task1_experts_2_output_1 * gates1[:, 1].unsqueeze(1)task1_inputs += shared_experts_2_output_0 * gates1[:, 2].unsqueeze(1)task1_inputs += shared_experts_2_output_1 * gates1[:, 3].unsqueeze(1)#第二层任务2网络输出task2_inputs += shared_experts_2_output_0 * gates2[:, 0].unsqueeze(1)task2_inputs += shared_experts_2_output_1 * gates2[:, 1].unsqueeze(1)task2_inputs += task2_experts_2_output_0 * gates2[:, 2].unsqueeze(1)task2_inputs += task2_experts_2_output_1 * gates2[:, 3].unsqueeze(1)task1_outputs = self.task1_head(task1_inputs)task2_outputs = self.task2_head(task2_inputs)return task1_outputs, task2_outputs# 实例化模型对象
experts_hidden1_dim = 64
experts_hidden2_dim = 32
output_experts_dim = 16
gate_hidden1_dim = 16
gate_hidden2_dim = 8
task_hidden1_dim = 32
task_hidden2_dim = 16
output_task1_dim = 1
output_task2_dim = 1
num_shared_experts = 2
num_task_experts = 2# 构造虚拟样本数据
torch.manual_seed(42) # 设置随机种子以保证结果可重复
input_dim = 100
num_samples = 1024
X_train = torch.randint(0, 2, (num_samples, input_dim)).float()
y_train_task1 = torch.rand(num_samples, output_task1_dim) # 假设任务1的输出维度为1
y_train_task2 = torch.rand(num_samples, output_task2_dim) # 假设任务2的输出维度为1# 创建数据加载器
train_dataset = TensorDataset(X_train, y_train_task1, y_train_task2)
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True)model = PLEModel(input_dim, experts_hidden1_dim, experts_hidden2_dim, output_experts_dim, task_hidden1_dim, task_hidden2_dim, output_task1_dim, output_task2_dim, gate_hidden1_dim, gate_hidden2_dim, num_shared_experts, num_task_experts)# 定义损失函数和优化器
criterion_task1 = nn.MSELoss()
criterion_task2 = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练循环
num_epochs = 100
for epoch in range(num_epochs):model.train()running_loss = 0.0for batch_idx, (X_batch, y_task1_batch, y_task2_batch) in enumerate(train_loader):# 前向传播: 获取预测值#print(batch_idx, X_batch )#print(f'Epoch [{epoch+1}/{num_epochs}-{batch_idx}], Loss: {running_loss/len(train_loader):.4f}')outputs_task1, outputs_task2 = model(X_batch)# 计算每个任务的损失loss_task1 = criterion_task1(outputs_task1, y_task1_batch)loss_task2 = criterion_task2(outputs_task2, y_task2_batch)total_loss = loss_task1 + loss_task2# 反向传播和优化optimizer.zero_grad()total_loss.backward()optimizer.step()running_loss += total_loss.item()if epoch % 10 == 0:print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}')print(model)
#for param_tensor in model.state_dict():
# print(param_tensor, "\t", model.state_dict()[param_tensor].size())
# 模型预测
model.eval()
with torch.no_grad():test_input = torch.randint(0, 2, (1, input_dim)).float() # 构造一个测试样本pred_task1, pred_task2 = model(test_input)print(f'互动目标预测结果: {pred_task1}')print(f'点击目标预测结果: {pred_task2}')相比于上一篇CGC中的代码,PLE代码更加复杂,其中有很多地方可以复用与简化。
2.3.3 模型训练与推理测试
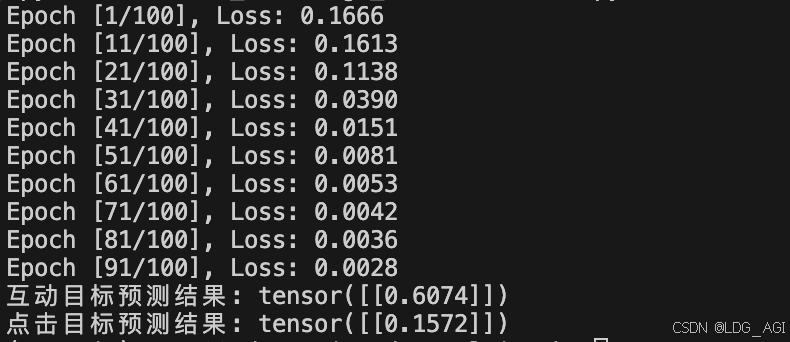
运行上述代码,模型启动训练,Loss逐渐收敛,测试结果如下:
2.3.4 打印模型结构
PLEModel((shared_experts_1): ModuleList((0-1): 2 x Sequential((0): Linear(in_features=100, out_features=64, bias=True)(1): ReLU()(2): Linear(in_features=64, out_features=32, bias=True)(3): ReLU()(4): Linear(in_features=32, out_features=16, bias=True)(5): ReLU()))(task1_experts_1): ModuleList((0-1): 2 x Sequential((0): Linear(in_features=100, out_features=64, bias=True)(1): ReLU()(2): Linear(in_features=64, out_features=32, bias=True)(3): ReLU()(4): Linear(in_features=32, out_features=16, bias=True)(5): ReLU()))(task2_experts_1): ModuleList((0-1): 2 x Sequential((0): Linear(in_features=100, out_features=64, bias=True)(1): ReLU()(2): Linear(in_features=64, out_features=32, bias=True)(3): ReLU()(4): Linear(in_features=32, out_features=16, bias=True)(5): ReLU()))(shared_experts_2): ModuleList((0-1): 2 x Sequential((0): Linear(in_features=16, out_features=64, bias=True)(1): ReLU()(2): Linear(in_features=64, out_features=32, bias=True)(3): ReLU()(4): Linear(in_features=32, out_features=16, bias=True)(5): ReLU()))(task1_experts_2): ModuleList((0-1): 2 x Sequential((0): Linear(in_features=16, out_features=64, bias=True)(1): ReLU()(2): Linear(in_features=64, out_features=32, bias=True)(3): ReLU()(4): Linear(in_features=32, out_features=16, bias=True)(5): ReLU()))(task2_experts_2): ModuleList((0-1): 2 x Sequential((0): Linear(in_features=16, out_features=64, bias=True)(1): ReLU()(2): Linear(in_features=64, out_features=32, bias=True)(3): ReLU()(4): Linear(in_features=32, out_features=16, bias=True)(5): ReLU()))(gating1_network_1): Sequential((0): Linear(in_features=100, out_features=16, bias=True)(1): ReLU()(2): Linear(in_features=16, out_features=8, bias=True)(3): ReLU()(4): Linear(in_features=8, out_features=4, bias=True)(5): Softmax(dim=1))(gating2_network_1): Sequential((0): Linear(in_features=100, out_features=16, bias=True)(1): ReLU()(2): Linear(in_features=16, out_features=8, bias=True)(3): ReLU()(4): Linear(in_features=8, out_features=4, bias=True)(5): Softmax(dim=1))(gating_shared_network_1): Sequential((0): Linear(in_features=100, out_features=16, bias=True)(1): ReLU()(2): Linear(in_features=16, out_features=8, bias=True)(3): ReLU()(4): Linear(in_features=8, out_features=6, bias=True)(5): Softmax(dim=1))(gating1_network_2): Sequential((0): Linear(in_features=16, out_features=16, bias=True)(1): ReLU()(2): Linear(in_features=16, out_features=8, bias=True)(3): ReLU()(4): Linear(in_features=8, out_features=4, bias=True)(5): Softmax(dim=1))(gating2_network_2): Sequential((0): Linear(in_features=16, out_features=16, bias=True)(1): ReLU()(2): Linear(in_features=16, out_features=8, bias=True)(3): ReLU()(4): Linear(in_features=8, out_features=4, bias=True)(5): Softmax(dim=1))(task1_head): Sequential((0): Linear(in_features=16, out_features=32, bias=True)(1): ReLU()(2): Linear(in_features=32, out_features=16, bias=True)(3): ReLU()(4): Linear(in_features=16, out_features=1, bias=True)(5): Sigmoid())(task2_head): Sequential((0): Linear(in_features=16, out_features=32, bias=True)(1): ReLU()(2): Linear(in_features=32, out_features=16, bias=True)(3): ReLU()(4): Linear(in_features=16, out_features=1, bias=True)(5): Sigmoid())
)三、总结
本文详细介绍了PLE多任务模型的算法原理、算法优势,并以小红书业务场景为例,构建PLE网络结构并使用pytorch代码实现对应的网络结构、训练流程。相比于CGC,PLE采用分层提取结构,每一层中采用共享门控、独享门控机制对共享专家组、独享专家组进行联合学习,增强了任务之间的解耦,提高了模型对不同任务的适应性,能在多任务场景中更好地平衡任务间冲突,提升多目标学习效果。
如果您还有时间,欢迎阅读本专栏的其他文章:
【深度学习】多目标融合算法(一):样本Loss加权(Sample Loss Reweight)
【深度学习】多目标融合算法(二):底部共享多任务模型(Shared-Bottom Multi-task Model)
【深度学习】多目标融合算法(三):混合专家网络MOE(Mixture-of-Experts)
【深度学习】多目标融合算法(四):多门混合专家网络MMOE(Multi-gate Mixture-of-Experts)
【深度学习】多目标融合算法(五):定制门控网络CGC(Customized Gate Control)






SVIn2声呐模块分析)




![[特殊字符] 使用增量同步+MQ机制将用户数据同步到Elasticsearch](http://pic.xiahunao.cn/[特殊字符] 使用增量同步+MQ机制将用户数据同步到Elasticsearch)







