大多数的 LLM 应用程序都会有一个会话接口,允许我们和 LLM 进行多轮的对话,并有一定的上下文记忆能力。但实际上,模型本身是不会记忆任何上下文的,只能依靠用户本身的输入去产生输出。而实现这个记忆功能,就需要额外的模块去保存我们和模型对话的上下文信息,然后在下一次请求时,把所有的历史信息都输入给模型,让模型输出最终结果。
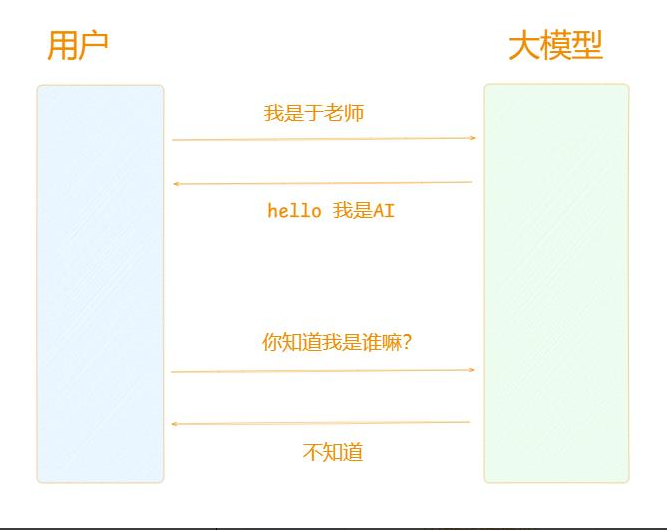
在没有使用Memory的的情况下,大模型记忆上一次的回答,每次的回答都不相干。如下图:
大多数的 LLM 应用程序都会有一个会话接口,允许我们和 LLM 进行多轮的对话,并有一定的上下文记忆能力。但实际上,模型本身是不会记忆任何上下文的,只能依靠用户本身的输入去产生输出。而实现这个记忆功能,就需要额外的模块去保存我们和模型对话的上下文信息,然后在下一次请求时,把所有的历史信息都输入给模型,让模型输出最终结果。
在没有使用Memory的的情况下,大模型记忆上一次的回答,每次的回答都不相干。如下图:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若转载,请注明出处:http://www.pswp.cn/web/81404.shtml 繁体地址,请注明出处:http://hk.pswp.cn/web/81404.shtml
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!




)

问题解决方法)

)
:字幕与标题生成的三大支柱-字幕与标题生成-优雅草卓伊凡)



)




