一,散列表查找定义
散列技术是在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使得每个关键字key对应一个存储位置f(key)。查找时,根据这个确定的对应关系找到给定值key的映射f(key),若查找集中存在这个记录,则必定在f(key)的位置。
这里我们把这种对应关系f称为散列函数,又称为哈希(Hash)函数。
采用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间称为散列表或哈希表(Hash table)。
那么关键字对应的记录存储位置称为散列地址。
二、核心组成部分
-
哈希函数(Hash Function)
-
作用:将任意大小的键(Key)转换为固定范围的整数(通常作为数组索引)。
-
设计要求:
-
确定性:同一键的哈希值必须相同。
-
均匀性:键的哈希值应尽可能均匀分布,减少冲突。
-
高效性:计算速度快。
-
-
常见哈希函数:
-
取模运算:
hash(key) = key % size(需注意size通常为质数)。 -
乘法哈希:利用浮点数运算和取模。
-
加密哈希(如MD5、SHA-1):用于分布式系统或安全性场景。
-
-
-
冲突解决(Collision Resolution)
-
冲突原因:不同键可能生成相同的哈希值。
-
解决方法:
-
开放寻址法(Open Addressing)
-
当冲突发生时,按某种规则寻找下一个可用位置。
-
探测方式:
-
线性探测:依次检查下一个位置(
index = (hash(key) + i) % size)。 -
二次探测:按平方跳跃(
index = (hash(key) + i²) % size)。 -
双重哈希:使用第二个哈希函数计算步长(
index = (hash1(key) + i * hash2(key)) % size)。
-
-
缺点:易产生聚集效应,删除操作需标记为“已删除”。
-
-
链地址法(Separate Chaining)
-
每个桶(Bucket)存储一个链表(或树),冲突元素追加到链表中。
-
优化:链表长度过长时转换为红黑树(如Java 8的
HashMap)。 -
优点:实现简单,适合频繁插入/删除的场景。
-
-
-
三、哈希表操作
-
插入(Insert)
-
计算键的哈希值,找到对应位置。
-
若位置为空,直接插入;若冲突,按冲突解决策略处理。
-
-
查找(Search)
-
计算哈希值定位桶,遍历链表(链地址法)或探测后续位置(开放寻址法),直到找到键或确认不存在。
-
-
删除(Delete)
-
类似查找操作,找到元素后标记删除(开放寻址法需特殊标记)或从链表中移除。
-
四,散列函数的构造方法
1.直接定址法
核心思想为:直接使用键的值作为哈希表的存储位置,无需复杂的哈希计算,因此可以完全避免冲突。
1.1 直接定址法的定义
-
基本思想:
hash(key)=key
当键的取值范围较小且连续时(例如键是整数,范围在[0, N-1]),可以直接使用键本身作为数组的索引。此时,哈希函数为:即直接将键映射到数组的对应位置。
-
适用条件:
键的取值必须满足以下两个条件:-
范围有限:键的取值范围不能过大,否则需要极大数组,浪费内存。
-
连续分布:键的取值是连续的(或接近连续),避免数组中出现大量未使用的空洞。
-
1.2 工作原理
-
初始化:创建一个大小为 𝑁N 的数组(𝑁N 为键的最大值加1)。
-
插入操作:将键 𝑘k 对应的值存储在数组的第 𝑘k 个位置。
array[key] = value -
查找操作:直接访问数组的第 𝑘k 个位置获取值。
value = array[key] -
删除操作:将数组的第 𝑘k 个位置标记为空或赋予特定值(如
None)。
1.3 适用场景
-
键为小范围整数:
-
如学号、员工编号、IP地址的最后8位(0-255)等。
-
-
内存充足且追求极致性能:
-
如实时系统中的关键数据查询。
-
-
无冲突要求的场景:
-
如某些硬件设计或嵌入式系统,需严格避免哈希冲突。
-
1.4 示例代码
#include <stdio.h>
#include <stdlib.h>typedef struct {int max_key;int* table;
} DirectAddressTable;DirectAddressTable* createTable(int max_key) {DirectAddressTable* da_table = (DirectAddressTable*)malloc(sizeof(DirectAddressTable));if (!da_table) return NULL;da_table->max_key = max_key;da_table->table = (int*)malloc(sizeof(int) * (max_key + 1));if (!da_table->table) {free(da_table);return NULL;}for (int i = 0; i <= max_key; i++) {da_table->table[i] = -1;}return da_table;
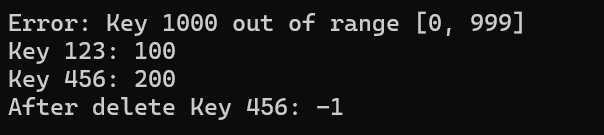
}void insert(DirectAddressTable* da_table, int key, int value) {if (key < 0 || key > da_table->max_key) {printf("Error: Key %d out of range [0, %d]\n", key, da_table->max_key);return;}da_table->table[key] = value;
}int search(DirectAddressTable* da_table, int key) {if (key < 0 || key > da_table->max_key) {printf("Error: Key %d out of range [0, %d]\n", key, da_table->max_key);return -1;}return da_table->table[key];
}// 修改函数名为 deleteKey
void deleteKey(DirectAddressTable* da_table, int key) {if (key < 0 || key > da_table->max_key) {printf("Error: Key %d out of range [0, %d]\n", key, da_table->max_key);return;}da_table->table[key] = -1;
}void destroyTable(DirectAddressTable* da_table) {if (da_table) {free(da_table->table);free(da_table);}
}int main() {DirectAddressTable* table = createTable(999);if (!table) {printf("Failed to create table!\n");return 1;}insert(table, 123, 100);insert(table, 456, 200);insert(table, 999, 300);insert(table, 1000, 400); // 触发越界错误printf("Key 123: %d\n", search(table, 123)); // 100printf("Key 456: %d\n", search(table, 456)); // 200deleteKey(table, 456); // 修改为 deleteKeyprintf("After delete Key 456: %d\n", search(table, 456)); // -1destroyTable(table);return 0;
} 
2.开放定址法
所谓的开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表组足够大,空的散列表地址总能找到,并将记录存入
2.1 核心思想
-
基本规则
-
当插入或查找时,若目标位置已被占用(发生冲突),则按预定的探测序列依次检查后续位置,直到找到空槽或目标键。
-
所有操作(插入、查找、删除)必须遵循相同的探测规则。
-
-
关键特点
-
内存紧凑:所有数据存储在数组中,无额外指针开销。
-
探测序列设计:探测方式直接影响性能,需避免聚集(Clustering)现象。
-
删除需标记:直接删除元素会导致探测链断裂,需用特殊标记(如
TOMBSTONE)占位。
-
2.2 探测方法
探测序列的设计是开放定址法的核心。以下是三种常见探测方式:
1. 线性探测(Linear Probing)
-
规则:
若位置hash(key)冲突,则依次检查(hash(key) + i) % size(i=1,2,3...)。 -
示例:
-
插入键
k1(哈希到位置 3),冲突后存入位置 4。 -
插入键
k2(哈希到位置 3),冲突后存入位置 5。
-
-
优点:
-
实现简单,缓存友好(连续内存访问)。
-
-
缺点:
-
易产生聚集(Clustering):连续冲突形成长链,降低效率。
-
2. 二次探测(Quadratic Probing)
-
规则:
冲突后检查(hash(key) + c1*i + c2*i²) % size(i=1,2,3...,通常取c1=1,c2=1)。 -
示例:
-
插入键
k1(哈希到位置 3),冲突后依次检查位置 4(3+1)、6(3+1+1²)、...
-
-
优点:
-
减少聚集现象,分布更均匀。
-
-
缺点:
-
探测序列可能无法覆盖所有槽位(需哈希表大小为质数且负载因子≤0.5)。
-
3. 双重哈希(Double Hashing)
-
规则:
index=(hash1(𝑘𝑒𝑦)+𝑖×hash2(𝑘𝑒𝑦)) % sizeindex=(hash1(key)+i×hash2(key)) % size
使用第二个哈希函数计算步长:-
hash2(key)不能为0,通常设计为hash2(key) = R - (key % R)(R为小于表大小的质数)。
-
-
示例:
-
hash1(k)=3,hash2(k)=5,冲突后探测位置 8, 13, 18...
-
-
优点:
-
最接近理想均匀分布,冲突率最低。
-
-
缺点:
-
计算成本略高,需设计两个哈希函数。
-


2.3 代码示例
#include <stdio.h>
#include <stdlib.h>#define SIZE 10
#define TOMBSTONE -2typedef struct {int key;int value;
} Entry;typedef struct {Entry* table;int size;int count; // 有效元素数(不含TOMBSTONE)
} OpenAddressHashTable;OpenAddressHashTable* createHashTable() {OpenAddressHashTable* ht = (OpenAddressHashTable*)malloc(sizeof(OpenAddressHashTable));ht->size = SIZE;ht->count = 0;ht->table = (Entry*)malloc(sizeof(Entry) * SIZE);for (int i = 0; i < SIZE; i++) {ht->table[i].key = -1; // -1表示空位}return ht;
}int hash1(int key) {return key % SIZE;
}int hash2(int key) {return 7 - (key % 7); // 7为小于SIZE的质数
}int probe(int key, int i) {return (hash1(key) + i * hash2(key)) % SIZE;
}void insert(OpenAddressHashTable* ht, int key, int value) {if (ht->count >= ht->size * 0.7) {printf("Warning: Load factor exceeds 0.7, consider rehashing.\n");}for (int i = 0; i < ht->size; i++) {int index = probe(key, i);if (ht->table[index].key == -1 || ht->table[index].key == TOMBSTONE) {ht->table[index].key = key;ht->table[index].value = value;ht->count++;return;} else if (ht->table[index].key == key) {ht->table[index].value = value; // 更新现有键return;}}printf("Error: Hash table is full!\n");
}int search(OpenAddressHashTable* ht, int key) {for (int i = 0; i < ht->size; i++) {int index = probe(key, i);if (ht->table[index].key == key) {return ht->table[index].value;} else if (ht->table[index].key == -1) {return -1; // 未找到}}return -1;
}// 修改函数名为 deleteKey
void deleteKey(OpenAddressHashTable* ht, int key) {for (int i = 0; i < ht->size; i++) {int index = probe(key, i);if (ht->table[index].key == key) {ht->table[index].key = TOMBSTONE;ht->count--;return;} else if (ht->table[index].key == -1) {return; // 未找到}}
}void destroyHashTable(OpenAddressHashTable* ht) {free(ht->table);free(ht);
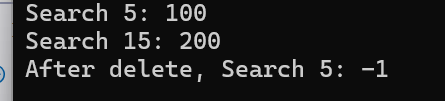
}int main() {OpenAddressHashTable* ht = createHashTable();insert(ht, 5, 100);insert(ht, 15, 200); // 冲突,使用双重哈希探测printf("Search 5: %d\n", search(ht, 5)); // 100printf("Search 15: %d\n", search(ht, 15)); // 200deleteKey(ht, 5); // 原 delete(ht, 5)printf("After delete, Search 5: %d\n", search(ht, 5)); // -1destroyHashTable(ht);return 0;
}
3.再散列函数法(Rehashing/双散列法)
核心思想
当哈希冲突发生时,通过第二个(或更多)哈希函数重新计算存储位置,直到找到空闲的槽位。属于开放定址法的一种。
工作流程
-
首次哈希:用第一个哈希函数 ℎ1(𝑘𝑒𝑦)h1(key) 计算初始位置。
-
冲突处理:若冲突,用第二个哈希函数 ℎ2(𝑘𝑒𝑦)h2(key) 计算偏移量,按公式 (ℎ1+𝑖×ℎ2)%表大小(h1+i×h2)%表大小 探测(𝑖i 为尝试次数)。
-
重复探测:直到找到空位或遍历全表。
示例
假设 ℎ1(𝑘)=𝑘%7h1(k)=k%7,ℎ2(𝑘)=5−(𝑘%5)h2(k)=5−(k%5),插入键 23 和 30:
-
23 → 23%7=223%7=2(直接插入位置2)
-
30 → 30%7=230%7=2(冲突),计算偏移 ℎ2(30)=5−0=5h2(30)=5−0=5,新位置 (2+1×5)%7=0(2+1×5)%7=0
优缺点
-
优点:减少聚集现象,探测序列分布均匀。
-
缺点:多次计算可能耗时,需合理设计哈希函数避免循环。
应用场景
-
内存受限环境(无需额外指针)。
-
预期冲突率较低的场景(如数据库索引)。
4.链地址法(拉链法/Separate Chaining)
4.1核心思想
每个哈希桶维护一个链表(或树),冲突元素直接追加到链表中。哈希表退化为“链表数组”。
4.2 工作流程
-
哈希计算:用 ℎ(𝑘𝑒𝑦)h(key) 找到桶位置。
-
链表操作:
-
插入:将新元素插入链表头部或尾部。
-
查找:遍历链表比对键值。
-
删除:找到节点后断开链接。
-
4.3 示例
哈希函数 ℎ(𝑘)=𝑘%3h(k)=k%3,插入 3, 6, 9:
-
桶0:3 → 9(插入到链表)
-
桶1:空
-
桶2:6
4.4 优化策略
-
链表转红黑树:当链表长度超过阈值(如Java HashMap的阈值8),转为树结构提升查询效率。
4.5 优缺点
-
优点:处理高冲突高效,实现简单,适合动态数据。
-
缺点:指针占用额外内存,链表过长影响性能。
4.6 应用场景
-
Java HashMap、C++ unordered_map。
-
频繁插入删除的场景。
5.公共溢出区法
5.1 核心思想
将哈希表分为主表和溢出区,冲突元素统一存放到独立的溢出区域。
5.2 工作流程
-
主表插入:通过 ℎ(𝑘𝑒𝑦)h(key) 找到主表位置。
-
溢出处理:若主表位置已占用,将元素存入溢出区(顺序存储或链表结构)。
-
查找逻辑:先查主表,未命中则遍历溢出区。
5.3 示例
主表大小5,溢出区大小3。插入键 5, 10, 15(假设 ℎ(𝑘)=𝑘%5h(k)=k%5):
-
主表位置0:5
-
主表位置0冲突,10和15存入溢出区。
5.4 管理策略
-
溢出区结构:可采用顺序表(简单但查询慢)或链表(需额外指针)。
-
合并整理:定期将溢出区数据迁移回主表(需重新哈希)。
5.5 优缺点
-
优点:实现简单,主表结构稳定。
-
缺点:溢出区可能成为性能瓶颈,需合理设计大小。
5.6 应用场景
-
嵌入式系统等内存布局固定的场景。
-
冲突较少或数据规模可预估的情况。
五,散列表查找实现
1.散列表查找算法实现
无论采用何种冲突解决方法,查找的核心步骤均为:
-
计算哈希值:用哈希函数计算键的初始位置。
-
定位元素:
-
若当前位置的键匹配 → 返回数据。
-
若位置为空 → 表示不存在该键。
-
若位置被占用但键不匹配 → 按冲突策略继续查找。
-
-
处理冲突:根据冲突解决策略(如开放定址法、链地址法)继续探测。
示例代码:
#include <stdio.h>
#include <stdlib.h>#define SUCCESS 1
#define UNSUCCESS 0
#define HASHSIZE 12 // 散列表长度
#define NULLKEY -32768 // 空标记
#define OK 1
#define ERROR 0typedef int Status;typedef struct {int *elem; // 数据存储基址int count; // 元素个数
} HashTable;int m = 0; // 全局表长/* 初始化散列表 */
Status InitHashTable(HashTable *H) {m = HASHSIZE;H->count = m;H->elem = (int *)malloc(m * sizeof(int));for (int i = 0; i < m; i++) {H->elem[i] = NULLKEY;}return OK;
}/* 散列函数(除留余数法) */
int Hash(int key) {return key % m;
}/* 插入关键字 */
void InsertHash(HashTable *H, int key) {int addr = Hash(key);// 线性探测解决冲突while (H->elem[addr] != NULLKEY) {addr = (addr + 1) % m;}H->elem[addr] = key;
}/* 查找关键字 */
Status SearchHash(HashTable H, int key, int *addr) {*addr = Hash(key);// 记录初始探测位置int startAddr = *addr;while (H.elem[*addr] != key) {*addr = (*addr + 1) % m;// 遇到空位或回到起点说明不存在if (H.elem[*addr] == NULLKEY || *addr == startAddr) {return UNSUCCESS;}}return SUCCESS;
}int main() {HashTable H;int keys[] = {12, 67, 56, 16, 25, 37, 22, 29, 15, 47, 48, 34};int n = sizeof(keys)/sizeof(keys[0]);// 初始化散列表if (InitHashTable(&H) != OK) {printf("初始化失败!\n");return 1;}// 插入数据for (int i = 0; i < n; i++) {InsertHash(&H, keys[i]);}// 验证插入结果printf("散列表内容:");for (int i = 0; i < m; i++) {printf("%d ", H.elem[i]);}printf("\n");// 查找测试int target = 37;int addr;if (SearchHash(H, target, &addr) {printf("找到%d,位置:%d\n", target, addr);} else {printf("未找到%d\n", target);}free(H.elem);return 0;
}六、优缺点分析
-
优点:
-
平均时间复杂度O(1),适合高频查询场景。
-
灵活支持动态数据。
-
-
缺点:
-
哈希函数设计不当会导致冲突频繁,性能退化至O(n)。
-
内存预分配可能浪费空间。
-
无法保证元素顺序(有序哈希表需额外设计)。
-
七、应用场景
-
字典(Dictionary):如Python的
dict、C++的unordered_map。 -
缓存系统:如Redis、Memcached。
-
数据库索引:加速数据检索。
-
唯一性检查:快速判断元素是否存在(如布隆过滤器)。
八、优化与变种
-
完美哈希(Perfect Hashing):无冲突的哈希函数,适用于静态数据集。
-
一致性哈希(Consistent Hashing):用于分布式系统,减少节点增减时的数据迁移。
-
布隆过滤器(Bloom Filter):基于哈希的概率数据结构,用于高效判断元素是否存在。
九、代码实现示例(Python)
class HashTable:def __init__(self, size=10):self.size = sizeself.table = [[] for _ in range(size)] # 链地址法def _hash(self, key):return hash(key) % self.size # 使用内置哈希函数取模def insert(self, key, value):idx = self._hash(key)for item in self.table[idx]:if item[0] == key:item[1] = value # 更新现有键returnself.table[idx].append([key, value]) # 插入新键def get(self, key):idx = self._hash(key)for item in self.table[idx]:if item[0] == key:return item[1]raise KeyError(f"Key {key} not found")def delete(self, key):idx = self._hash(key)for i, item in enumerate(self.table[idx]):if item[0] == key:del self.table[idx][i]returnraise KeyError(f"Key {key} not found")十、总结
哈希表通过巧妙的哈希函数和冲突解决策略,在时间与空间之间实现高效平衡。理解其原理和实现细节,有助于在开发中选择合适的优化策略(如动态扩容、链与树的转换),应对不同场景的需求。




深度解析:国产分布式数据库的旗舰之作)
)


![【洛谷P9303题解】AC- [CCC 2023 J5] CCC Word Hunt](http://pic.xiahunao.cn/【洛谷P9303题解】AC- [CCC 2023 J5] CCC Word Hunt)






)



