目录
一,对比式自监督学习
1.1 简介
1.2 常见算法
1.2.1 SimCLR (2020)
1.2.2 MoCo (2020)
1.2.3 BYOL (2021)
1.2.4 SimSiam (2021)
1.2.5 CLIP (2021)
1.2.6 DINO (2021)
1.2.7 SwAV (2020)
二,代码逻辑分析
2.1 整体目标与流程
2.2 数据增强:生成 “双胞胎” 图像
2.3 编码器:从图像到 “特征描述”
2.4 对比损失:让 “双胞胎” 特征靠近
2.5 训练过程:反复练习 “找不同”
2.6 线性评估:用学到的特征 “考试”
三,测试结果
3.1 对比学习结果
3.2 总结
四,完整代码
一,对比式自监督学习
1.1 简介
对比式自监督学习是一种通过构造 “正样本对”(同一数据的不同增强视图)和 “负样本对”(不同数据的视图)来迫使模型学习数据本质特征的无监督学习方法。其核心流程包括数据增强生成正样本、编码器提取特征、对比损失函数拉近正样本 / 推远负样本,最终将预训练特征迁移到下游任务。该方法无需人工标注,能有效利用海量无标注数据,学习到对视角、光照等变化鲁棒的通用特征,广泛应用于图像、文本等领域,代表算法有 SimCLR、MoCo、CLIP 等,为解决数据标注成本高、特征泛化性不足等问题提供了高效方案。
1.2 常见算法
1.2.1 SimCLR (2020)
核心思想:通过多样化数据增强和大规模对比学习学习图像特征。
(假设你在动物园观察动物,SimCLR 让你从不同角度(正面、侧面、背面)、不同光线(白天、黑夜)观察同一只动物,然后告诉你:“这些都是同一只动物,要记住它的本质特征!”同时,给你看其他动物的照片,告诉你:“这些和前面的不是同一种,要区分开来!”)
特点:
数据增强组合:随机裁剪、翻转、颜色抖动、高斯模糊等。(对同一张图片做各种 “变形”(裁剪、翻转、变色),生成很多版本。)
非线性投影头:使用 MLP 将特征映射到对比空间。
NT-Xent 损失:温度缩放的交叉熵损失,增大正负样本区分度。
大批量训练:需 8192 样本 /batch 才能达到最佳效果。(每次训练看大量图片,强行记住 “哪些是同类,哪些不是”。)
应用场景:图像分类、目标检测、语义分割的预训练。
1.2.2 MoCo (2020)
核心思想:通过动量编码器和动态负样本队列解决对比学习中的负样本数量限制。(你在动物园遇到一个 “记忆助手”,它会帮你记住之前看过的动物特征。当你看到新动物时,它会提醒你:“这只和之前看到的老虎很像吗?不像?那就是新物种!”)
特点:
动量更新:使用指数移动平均 (EMA) 缓慢更新编码器参数,保持负样本特征稳定性。
队列机制:维护一个固定大小的负样本特征队列,突破 batch size 限制。(维护一个 “动物特征库”,不断更新和比对。不需要一次性看所有图片,用 “老照片” 当负样本。)
端到端训练:无需多机并行即可处理大规模负样本。
应用场景:小批量训练、视频理解(利用时序信息构建队列)。算力有限,但想利用历史经验的情况。
1.2.3 BYOL (2021)
核心思想:无需负样本,通过 “自举” 机制学习特征。(你照镜子,镜子里的 “你” 就是目标。你需要调整自己的姿势、表情,让镜子里的 “你” 和真实的你越来越像。只关注 “自己和自己的一致性”,不关心别人长什么样。)
特点:
孪生网络架构:在线网络 (online network) 和目标网络 (target network)。
预测头:在线网络增加预测头,预测目标网络生成的特征。
无负样本:仅通过正样本对 (同一图像的不同视图) 训练,避免模型坍塌。
应用场景:计算资源有限场景、半监督学习。快速训练、资源紧张的场景。
1.2.4 SimSiam (2021)
核心思想:证明对比学习无需负样本,甚至无需孪生网络权重共享。(你有两个 “克隆人”,一个负责观察动物(编码器),另一个负责猜测观察结果(预测头)。两个克隆人互相学习,但不共享记忆。)
特点:
停止梯度:预测头的梯度不回传到编码器,防止模型坍塌。(两个克隆人独立学习,避免 “作弊”(模型坍塌)。)
极简架构:仅需一个编码器和预测头,训练速度快。(结构简单,训练高效,效果还不错。)
无需负样本队列:依赖 “预测 - 编码” 结构学习不变特征。
应用场景:轻量级预训练、快速迭代实验,快速实验、不想折腾复杂模型的情况。
1.2.5 CLIP (2021)
核心思想:跨模态对比学习,对齐图像与文本的语义空间。(你同时学习 “文字描述” 和 “图片”,比如看到 “一只猫在沙发上” 的文字,就去找对应的图片。时间久了,你能直接根据文字找到图片,或者根据图片写出描述。)
特点:
多模态输入:同时处理图像和文本,学习图文关联。(同时学习图像和文字,建立两者的联系。)
零样本学习:通过文本描述直接分类图像,无需训练数据。(没见过的东西也能分类,比如看到 “独角兽” 的描述,能从图片中找出独角兽(即使没见过)。)
大规模预训练:在 4 亿图文对上训练,泛化能力强。
应用场景:图像检索、多模态生成、零样本任务迁移,多语言任务(文字描述可以是任何语言)
1.2.6 DINO (2021)
核心思想:通过自蒸馏学习视觉特征,无需标签或对比对。(你是一个美术生,老师给你一张 “半成品” 的动物画(教师网络),让你照着画完(学生网络)。通过不断模仿老师的风格,你学会了如何画动物的细节(如眼睛、毛发)。)
特点:
教师 - 学生架构:教师网络生成伪标签,指导学生网络学习。(用 “教师模型” 指导 “学生模型”,不需要标签。)
无监督注意力:自动发现图像中的语义区域(如物体轮廓)。(自动关注图像中的重要部分(如动物轮廓)。)
ViT 友好:特别适合 Vision Transformer 架构。
应用场景:目标检测、实例分割的预训练。基于 Transformer 的模型(如 ViT),擅长捕捉图像的局部细节。
1.2.7 SwAV (2020)
核心思想:将对比学习与聚类相结合,无需负样本队列。(你在整理照片,把相似的动物照片放在同一个相册(聚类)。然后,你用一个相册的照片去猜测另一个相册的分类,不断调整分类规则。)
特点:
对比聚类:动态分配样本到聚类中心,强制特征对齐。(先聚类,再对比,不需要显式的负样本。)
交换预测:用一个视图的特征预测另一个视图的聚类分配。(不需要维护大规模队列,适合处理高维数据。)
内存高效:无需维护大规模负样本队列。
应用场景:高维特征学习、大规模图像检索、高维特征分析(如图像的像素级特征)。
1.2.8 算法对比表
| 算法 | 负样本需求 | 关键创新点 | 计算效率 | 应用领域 |
|---|---|---|---|---|
| SimCLR | 显式需要 | 多样化增强 + NT-Xent 损失 | 低 | 图像基础任务 |
| MoCo | 队列机制 | 动量编码器 + 动态队列 | 中 | 小批量训练、视频 |
| BYOL | 无需 | 自举机制 + 孪生网络 | 高 | 资源受限场景 |
| SimSiam | 无需 | 停止梯度 + 极简架构 | 高 | 快速实验 |
| CLIP | 跨模态 | 图文对齐 + 零样本学习 | 极高 | 多模态任务 |
| DINO | 无对比对 | 自蒸馏 + 注意力机制 | 中 | 基于 ViT 的检测 / 分割 |
| SwAV | 隐式对比 | 对比聚类 + 交换预测 | 中 | 高维特征学习 |
计算资源充足:优先使用 SimCLR 或 MoCo,利用大规模负样本提升性能。
轻量级场景:选择 BYOL 或 SimSiam,无需负样本,训练更高效。
多模态任务:使用 CLIP,支持图文联合推理。
基于 ViT 的模型:考虑 DINO,专为 Transformer 设计。
高维特征需求:尝试 SwAV,结合聚类优化特征结构。
二,代码逻辑分析
2.1 整体目标与流程
通俗解释:
我们要让模型在没有标签的情况下学习图像的特征,就像小孩通过观察不同角度的玩具来理解 “这是同一个东西”。然后用学到的特征完成分类任务(如识别 FashionMNIST 中的衣服类型)。
def main():# 1. 加载数据(无需标签)train_loader = DataLoader(FashionMNIST(...))# 2. 预训练:通过对比学习提取特征encoder = train_contrastive(encoder, projection_head, train_loader, ...)# 3. 测试:用线性分类器验证特征质量linear_evaluation(encoder, train_loader, test_loader)2.2 数据增强:生成 “双胞胎” 图像
通俗解释:
对同一张图像做不同的 “变形”(裁剪、翻转、变色等),生成一对 “双胞胎”。模型需要学会:虽然外观不同,但它们本质是同一个东西。
def get_transform():return transforms.Compose([transforms.RandomResizedCrop(28), # 随机裁剪transforms.RandomHorizontalFlip(), # 随机翻转transforms.ColorJitter(0.4, 0.4, 0.4), # 颜色抖动transforms.GaussianBlur(3), # 模糊transforms.Normalize(...) # 归一化])# 训练时对每个图像生成两个视图
view1 = get_transform()(image)
view2 = get_transform()(image)2.3 编码器:从图像到 “特征描述”
通俗解释:
编码器就像一个 “翻译器”,把图像(像素矩阵)转化为计算机能理解的 “特征描述”(数字向量)。例如,把 “猫的图片” 转化为 “耳朵尖、眼睛圆、有胡须” 这样的描述。
class ResNet18Encoder(nn.Module):def __init__(self, pretrained=False):super().__init__()# 加载预训练的ResNet18并修改输入通道resnet = models.resnet18(pretrained=pretrained)# 修改第一层卷积以适应单通道输入(原输入通道为3)resnet.conv1 = nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False)# 移除最后的全连接层,保留特征提取部分self.features = nn.Sequential(*list(resnet.children())[:-1])self.projection_dim = 512 # ResNet18的输出维度def forward(self, x):x = self.features(x)x = torch.flatten(x, 1)return x2.4 对比损失:让 “双胞胎” 特征靠近
通俗解释:
对比损失就像一个 “裁判”,它告诉模型:同一图像的两个视图(双胞胎)特征要相似,不同图像的特征要远离。
def contrastive_loss(z1, z2, temperature=0.1):# 计算所有样本对的相似度sim_matrix = torch.matmul(z1, z2.T) / temperature# 标签:正样本对是对角线上的元素labels = torch.arange(batch_size).to(device)# 目标:最大化正样本对的相似度,最小化负样本对的相似度loss = F.cross_entropy(sim_matrix, labels)return loss2.5 训练过程:反复练习 “找不同”
通俗解释:
模型反复看大量图像对,不断调整自己的 “特征提取方式”,直到能准确区分 “双胞胎” 和 “陌生人”。
def train_contrastive(encoder, projection_head, dataloader, optimizer, epochs=30):for epoch in range(epochs):for images, _ in dataloader: # 无需标签!# 生成两个视图view1 = torch.stack([get_transform()(img) for img in images])view2 = torch.stack([get_transform()(img) for img in images])# 提取特征并计算损失z1 = projection_head(encoder(view1))z2 = projection_head(encoder(view2))loss = contrastive_loss(z1, z2)# 优化模型:调整参数,让损失变小optimizer.zero_grad()loss.backward()optimizer.step()2.6 线性评估:用学到的特征 “考试”
通俗解释:
冻结训练好的编码器(固定 “特征提取方式”),只训练一个简单的线性分类器(类似 “填空题”)。如果分类准确率高,说明编码器学到的特征确实有用。
def linear_evaluation(encoder, train_loader, test_loader, epochs=15):encoder.eval() # 冻结编码器,不再更新classifier = nn.Linear(256, 10).to(device) # 简单线性分类器for epoch in range(epochs):for images, labels in train_loader:# 用编码器提取特征(固定不变)with torch.no_grad():features = encoder(images)# 仅训练分类器:将特征映射到类别logits = classifier(features)loss = F.cross_entropy(logits, labels)optimizer.zero_grad()loss.backward()optimizer.step()三,测试结果
3.1 对比学习结果
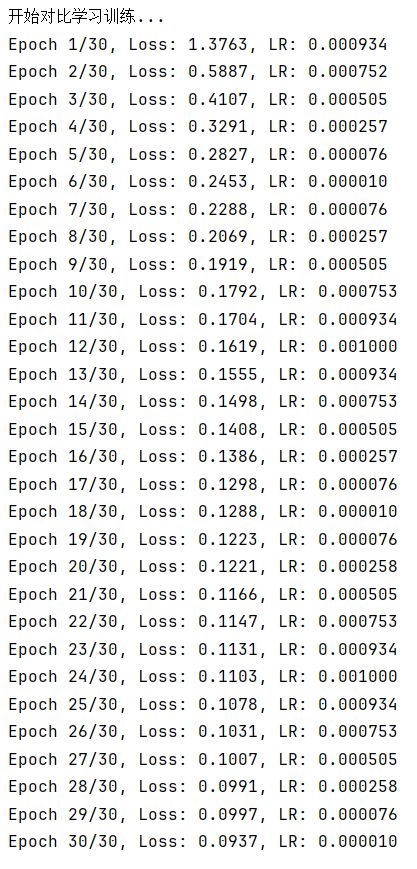
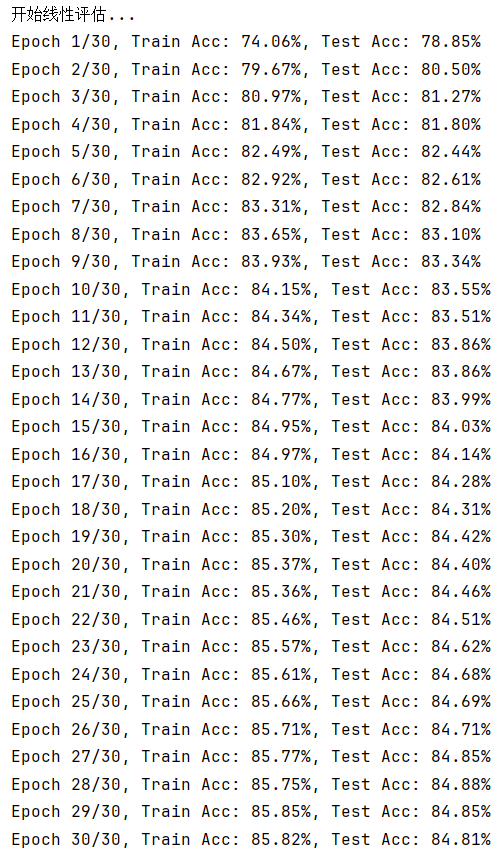
3.2 总结
相比使用更为简单的判别式自监督学习,更复杂的对比式自监督学习的准确度反而下降了,SimCLR 的对比训练就像是一场 “找相同与找不同” 的游戏。在这个游戏里,它先对同一张图片施展 “变形魔法”,通过裁剪、旋转、改变颜色等数据增强手段,变出多个 “长得不一样但本质相同” 的视图,把这些视图配成对,就是正样本对;而其他图片的视图,不管来自哪张图,都被当作负样本对。接着,对比损失函数就像一个 “裁判”,时刻盯着模型,要是模型把正样本对的特征分得太开,或者把负样本对的特征靠得太近,就要 “扣分”(增加损失值)。在不断 “扣分” 和调整的过程中,模型慢慢学会把正样本对的特征在 “特征空间” 里拉近,把负样本对的特征推远,最终掌握了提取通用特征的能力。
这种对比训练在样本超级多的数据集里特别 “如鱼得水”。想象一下,如果数据集里只有寥寥几张图片,模型很容易被图片里一些偶然出现的相似点误导,比如两张不同类别的图片刚好都有一块红色区域,模型可能就错误地把它们归为相似的。但当数据集里有成千上万、甚至几十万上百万张图片时,同类图片的数量足够多,模型就能从大量同类样本里总结出真正的共性特征,比如从海量猫的图片里学到猫有尖耳朵、长胡须这些关键特点,而不是被某张图片里猫身上的装饰误导。同时,丰富的负样本也能让模型见识到各种各样不相似的情况,更好地区分不同类别,就像见过了所有动物,才能更准确地分辨出猫和狗。最终,模型构建出的特征空间,能让相似的样本自然地聚集在一起,不相似的样本远远分开,为后续的图像分类、检索等任务,打下了坚实又可靠的基础 。
对于fashionmnist数据集来说,其数据规模还远小于需要使用simCLR算法的程度,在实际使用中,这种不太合适的算法选择往往会事倍功半。
基于FashionMnist数据集的自监督学习(判别式自监督学习)-CSDN博客
四,完整代码
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import torch.nn.functional as F
from torch.optim.lr_scheduler import CosineAnnealingLR# 设置设备:优先使用GPU,否则使用CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# ----------------------
# 1. 数据增强(增强多样性)
# ----------------------
def get_transform():"""创建一系列随机变换,用于生成同一张图片的不同视图"""return transforms.Compose([transforms.RandomResizedCrop(28, scale=(0.7, 1.0)), # 随机裁剪并调整大小,模拟不同视角transforms.RandomHorizontalFlip(), # 随机水平翻转transforms.RandomApply([transforms.ColorJitter(0.4, 0.4, 0.4, 0.1)], p=0.8), # 随机改变颜色transforms.RandomGrayscale(p=0.2), # 20%概率转为灰度图transforms.GaussianBlur(kernel_size=3, sigma=(0.1, 2.0)), # 随机高斯模糊,模拟模糊场景transforms.Normalize((0.1307,), (0.3081,)) # 标准化,确保数据分布一致])# ----------------------
# 2. 简单编码器(卷积网络)
# ----------------------
class Encoder(nn.Module):"""将图片转换为特征向量的神经网络"""def __init__(self):super().__init__()# 三层卷积提取特征,逐步增加通道数self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1) # 输入通道1(灰度图),输出32self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1) # 通道从32增加到64self.conv3 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1) # 通道从64增加到128self.pool = nn.MaxPool2d(2, 2) # 最大池化层,降低空间尺寸self.fc = nn.Linear(128 * 3 * 3, 256) # 全连接层,将特征展平为256维向量def forward(self, x):# 卷积+激活+池化的三层处理x = self.pool(F.relu(self.conv1(x))) # 尺寸从28x28变为14x14x = self.pool(F.relu(self.conv2(x))) # 尺寸从14x14变为7x7x = self.pool(F.relu(self.conv3(x))) # 尺寸从7x7变为3x3x = x.view(-1, 128 * 3 * 3) # 将特征图展平为一维向量x = self.fc(x) # 最后通过全连接层生成256维特征向量return x# ----------------------
# 3. 投影头(增加归一化)
# ----------------------
class ProjectionHead(nn.Module):"""将编码器输出的特征映射到对比学习的目标空间"""def __init__(self):super().__init__()self.fc1 = nn.Linear(256, 512) # 第一个全连接层,扩展到512维self.ln1 = nn.LayerNorm(512) # 层归一化,加速训练并提高稳定性self.relu = nn.ReLU() # 激活函数,引入非线性self.fc2 = nn.Linear(512, 128) # 第二个全连接层,压缩到128维self.ln2 = nn.LayerNorm(128) # 层归一化def forward(self, x):x = self.relu(self.ln1(self.fc1(x))) # 第一层处理x = self.ln2(self.fc2(x)) # 第二层处理,输出128维向量return x# ----------------------
# 4. 对比损失函数(InfoNCE)
# ----------------------
def contrastive_loss(z1, z2, temperature=0.07):"""计算两个特征向量之间的对比损失,使正样本对更接近,负样本对更远离"""batch_size = z1.shape[0]z1 = F.normalize(z1, dim=1) # 归一化特征向量,便于计算相似度z2 = F.normalize(z2, dim=1) # 归一化特征向量# 构建正样本对标签:每个z1的正样本是对应的z2,反之亦然positive = torch.cat([torch.arange(batch_size), torch.arange(batch_size)], dim=0).to(device)# 计算所有样本对之间的相似度(点积),并除以温度参数logits = torch.cat([torch.matmul(z1, z2.T), torch.matmul(z2, z1.T)], dim=0) / temperature# 使用交叉熵损失:目标是让正样本对的相似度得分最高loss = F.cross_entropy(logits, positive)return loss# ----------------------
# 5. 训练函数(对比学习)
# ----------------------
def train_contrastive(encoder, projection_head, dataloader, optimizer, scheduler, epochs=30):"""对比学习的训练主循环"""encoder.train()projection_head.train()for epoch in range(epochs):total_loss = 0for images, _ in dataloader: # 注意:这里只使用图片,不使用标签(自监督)images = images.to(device)# 对同一批图片应用两次不同的数据增强,生成两个视图view1 = torch.stack([get_transform()(img) for img in images])view2 = torch.stack([get_transform()(img) for img in images])view1, view2 = view1.to(device), view2.to(device)# 通过编码器和投影头处理两个视图h1 = encoder(view1) # 提取特征h2 = encoder(view2) # 提取特征z1 = projection_head(h1) # 投影到对比学习空间z2 = projection_head(h2) # 投影到对比学习空间# 计算对比损失loss = contrastive_loss(z1, z2)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()scheduler.step() # 更新学习率(余弦退火策略)total_loss += loss.item()# 打印每个epoch的平均损失和当前学习率avg_loss = total_loss / len(dataloader)print(f"Epoch {epoch + 1}/{epochs}, Loss: {avg_loss:.4f}, LR: {scheduler.get_last_lr()[0]:.6f}")return encoder# ----------------------
# 6. 线性评估函数
# ----------------------
def linear_evaluation(encoder, train_loader, test_loader, epochs=30):"""评估对比学习得到的编码器性能:固定编码器,训练一个线性分类器"""encoder.eval() # 冻结编码器,只训练线性分类器classifier = nn.Linear(256, 10).to(device) # 创建一个线性分类器(256维特征到10个类别)optimizer = optim.Adam(classifier.parameters(), lr=1e-3, weight_decay=1e-4)criterion = nn.CrossEntropyLoss()for epoch in range(epochs):# 训练阶段classifier.train()train_loss = 0correct = 0total = 0for images, labels in train_loader:images, labels = images.to(device), labels.to(device)with torch.no_grad():features = encoder(images) # 使用编码器提取特征(固定不变)outputs = classifier(features) # 通过线性分类器预测类别loss = criterion(outputs, labels)optimizer.zero_grad()loss.backward()optimizer.step()train_loss += loss.item()correct += (outputs.argmax(1) == labels).sum().item()total += labels.size(0)# 测试阶段classifier.eval()test_correct = 0test_total = 0with torch.no_grad():for images, labels in test_loader:images, labels = images.to(device), labels.to(device)features = encoder(images)test_correct += (classifier(features).argmax(1) == labels).sum().item()test_total += labels.size(0)# 打印训练和测试准确率train_acc = 100 * correct / totaltest_acc = 100 * test_correct / test_totalprint(f"Epoch {epoch + 1}/{epochs}, Train Acc: {train_acc:.2f}%, Test Acc: {test_acc:.2f}%")return test_acc# ----------------------
# 7. 主函数
# ----------------------
def main():"""程序入口:加载数据,训练模型,评估性能"""# 加载FashionMNIST数据集train_dataset = datasets.FashionMNIST(root='./data',train=True,download=True,transform=transforms.ToTensor() # 仅转换为张量,不使用其他增强(训练时单独处理))test_dataset = datasets.FashionMNIST(root='./data',train=False,download=True,transform=transforms.ToTensor())train_loader = DataLoader(train_dataset, batch_size=256, shuffle=True, num_workers=4) # 大批次加速训练test_loader = DataLoader(test_dataset, batch_size=256, shuffle=False, num_workers=4)# 初始化模型encoder = Encoder().to(device)projection_head = ProjectionHead().to(device)# 优化器与学习率调度器optimizer = optim.Adam(list(encoder.parameters()) + list(projection_head.parameters()),lr=1e-3, # 学习率weight_decay=1e-5 # 权重衰减,防止过拟合)# 余弦退火学习率调度:先增大后减小,帮助跳出局部最优scheduler = CosineAnnealingLR(optimizer, T_max=30, eta_min=1e-5)# 对比学习训练print("开始对比学习训练...")encoder = train_contrastive(encoder, projection_head, train_loader, optimizer, scheduler, epochs=30)# 线性评估:测试编码器学到的特征质量print("\n开始线性评估...")linear_evaluation(encoder, train_loader, test_loader, epochs=30)if __name__ == "__main__":main()与权限)
入门学习笔记)
)








)
)




深度解析:国产分布式数据库的旗舰之作)
)
